
一种融合图结构的阅读理解答案预测方法*
2021-11-01 07:54谭红叶屈保兴
测试技术学报 2021年5期
谭红叶,屈保兴,李 茹
(山西大学 计算机与信息技术学院,山西 太原 030006)
0 引 言
机器阅读理解(Machine Reading Comprehension,MRC),简称阅读理解,是自然语言处理(Natural Language Processing, NLP)领域的一项重要任务,该任务需要机器理解文本语义并回答相关问题. 近几年,阅读理解技术受到学术界和企业界的广泛关注,并且在公开发布的众多数据集的推动下取得了一系列进展. 目前的阅读理解方法主要基于深度学习框架. 如:Attentive Reader[1],Attention Sum Reader[2],BiDAF[3],R-Net[4],QANet[5]等模型都是利用多层神经网络体系架构以迭代方式不断加深对文章和问题的理解,并借助注意力机制使模型专注于文档与问题相关的部分. 还有一些模型基于大规模预训练语言模型构建,如基于BERT或XLNet的阅读理解模型[6,7]. 预训练语言模型利用迁移学习的思想,在相关任务的大数据中预训练有效的模型,然后再迁移到目标任务进一步优化,可大大提高模型的准确率. 上述基于深度学习的模型在一些阅读理解数据集上(如SQuAD[8])取得了很好的性能,但是,这些模型不能有效整合句子的句法结构、句子间长距离的语义关系等信息,从而引起模型对问题和篇章理解不够充分的局限. 图 1 为一个机器阅读理解示例,可以看出,机器需要基于句内结构对句子内容进行理解,同时还需理解句间关系才能对问题与篇章进行建模,进而正确回答所给问题.

图 1 阅读理解任务示例
受图神经网络模型在计算机视觉、自然语言处理等领域获得成功的启发,本文提出一种新的阅读理解答案预测方法,该方法使用图结构建模句子内部的句法结构信息与句子之间的语义关系,同时与基于注意力机制获得的问题与篇章的表示结合形成对篇章与问题更好的理解与表示. 同时,本文还结合阅读理解任务涉及不同类型问题的特点(表1 所示为常见的3种问题类型),在模型中引入问题分类任务,与问答任务形成多任务学习模型框架,进一步优化问题与文本表示. 本文在相关数据集上对所提模型进行了实验,结果表明本文系统的性能超过了所有基线模型.

表1 阅读理解任务常见问题类型示例
1 相关工作
1.1 阅读理解
阅读理解方法的发展变化与数据集的发展紧密相关,主要经历了以下阶段:
1) 基于规则方法的阶段. 20世纪70年代,研究学者开始阅读理解相关研究. 如:1977年,Lehnert[9]针对故事理解设计了基于手工编码脚本的QUALM系统. 90年代末,基于Hirschman发布的Remedia阅读理解数据集,一些基于规则方法的系统被提出,如Deep Read系统[10]、Quarc系统[11],但这类模型仅可以处理浅层语言信息,且难以推广到其他领域.
2) 基于传统机器学习方法的阶段. 2013年后,在MCTest[12]与PROCESSBANK[13]数据集的支持下,一些基于传统机器学习的模型被提出[14,15],它们大多基于最大间隔准则来学习一个线性打分函数计算问题、选项与原文的相似度. 模型需要手工设计大量语言特征,如句法依存、共指消解、篇章关系、句子相似度等特征[16,17]. 但当答案证据散布在整个文本时,从文本中构建有效特征非常困难.
3) 基于深度学习方法的阶段. 2015年后,随着CNN/DailyMail[1]与SQuAD大规模阅读理解数据集发布,以及深度学习领域的不断创新与突破,阅读理解方法开始转为以深度学习技术为主. 如:Hermann等[1]提出基于注意力的LSTM模型Attentive Reader,Kadlec等[2]提出基于双向GRU与Attention的模型Attention Sum Reader,Seo等[3]利用双向注意力流网络对问题和段落进行编码的阅读理解模型BiDAF,Wang等[4]利用门控自匹配网络获得问题感知的整个文章的表示R-Net,Yu等[5]利用卷积和自我注意机制作为编码器的构造块来表示问题和段落QANet,以及基于预训练语言模型BERT与XLNet的阅读理解方法[6,7]. 基于深度学习的模型不需要手工构建特征,避免了获取语言特征带来的噪声;同时利用多层神经网络体系架构以迭代方式不断加深对文章和问题的理解,并借助注意力机制使模型专注于文档中与问题相关的部分,因此在一些数据集上取得了很好的表现,甚至接近或超过了人的预期表现. 但研究表明,这些模型的语言理解与推理能力与人的预期还存在很大距离.
1.2 图神经网络
图神经网络(Graph Neural Networks,GNNs)最早由Scarselli等[18]提出,它扩展了现有的神经网络来处理图表示的数据. 原始GNN只能处理最简单的图,该图由带有标签信息的结点和无向边学习隐藏层表示来编码图的局部结构和结点特征. 后来,不断有一些GNN变体被提出,主要用于对不同类型的图(如有向图和异构图)进行建模,以扩展原始模型的表示能力解决不同领域问题. 如,Kipf等[19]在2017年提出图卷积网络(Graph Convolutional Networks,GCN),采用卷积操作进行信息传播运算,实现对引文网络和知识图数据集的分类. Velickovic等[20]提出一种将注意机制融入信息传播步骤的图注意网络(Graph Attention Networks,GAT),通过一种自注意机制关注节点邻居来计算每个节点的隐藏状态.
图神经网络用于自然语言处理中的许多任务,如语义角色标注[21]、句子关系提取[22]、文本分类[19,20]等. 还有学者将图神经网络用于阅读理解任务. 如Ran等[23]提出一个阅读理解模型NumNet,利用数字感知的图神经网络比较信息,实现对问题和文章中的数字进行数字推理;Ding等[24]提出一个多跳阅读理解框架CogQA,该框架以认知科学中的双过程理论为基础,通过协同隐式提取模块和显式推理模块,在迭代过程中逐步构建认知图,并在认知图基础上解答问题,该框架具体基于BERT和图神经网络实现.
与模型NumNet、CogQA类似的是,本文也将图神经网络用于阅读理解任务,但与它们的不同之处在于:(1)任务类型不同. 模型NumNet、CogQA分别面向数字推理、多跳推理任务,而本文面向的是更加通用的问题. (2)构图方式不同. 模型NumNet在构图中,将结点对应问题与篇章中的数字、结点之间的边反映数字之间的两种关系:大于(>)、小于等于(≤). 模型CogQA构建有向图来对应认知图,其中结点表示问题或篇章的实体,有向边表示由前一结点到后一结点的联想关系. 本文构图中,用结点对应问题或篇章的实体,边包括依存关系边与词性复现边,反映句法结构信息与句子间的语义关系.
2 本文方法
本文所提方法的模型框架如图 2 所示,主要包括4个模块:文本编码与问题分类模块、图结构模块、交互模块和答案预测模块. 各模块主要功能为:

图 2 本文所提模型框架示意图
1) 文本编码与问题分类模块:对输入的问题和篇章进行语义表示,并对问题进行分类.
2) 图结构模块:基于图结构对句法结构与句子间的关系进行建模,并形成图表示.
3) 交互融合模块:对图表示与基于注意机制的表示进行融合.
4) 答案预测模块:预测所给问题的答案.
2.1 编码与问题分类模块
2.1.1 文本编码模块
该模块对输入文本进行编码,通过预训练模型BERT和Bi-direction 注意力机制来实现.
模型采用预训练模型BERT的输入方式:input=[CLS]+Q+[SEP]+D+[SEP],其中Q为问题,D为篇章,[SEP]为分隔符,[CLS]为整个输入的聚合表示. 具体计算如式(1)所示
U=Bert(input),
(1)

为了加强模型对问题与篇章的理解,本文采用了类似于Seo 等[3]提出的双向注意流模型来捕获问题与篇章不同粒度的相关性,并更新问题与篇章的表示. 具体计算如式(2)所示

(2)
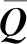
2.1.2 问题分类模块

c=Concat(MeanPool(U),MaxPool(U)),
(3)

(4)
式中:wc、bc分别为权重与偏置,为可训练参数.
2.2 图结构模块
2.2.1 图的构建与初始化
构建的图可表示为G(E,A),其中E为图的结点集合,k为图结点的个数,A为图的边集合.如果两个结点之间有关系,则二者之间具有边.


(5)

(6)

(7)
图中的边. 本任务涉及的边有两种:①句法关系边. 当一个句子中的两个词之间存在依存句法关系时,则两个词之间建立边. 为了简单,本文采用无向边. ②共同词性边. 当文本中的两个词具有相同词性时,则两词之间建立连边. 其中,句法关系边依据依存关系对句子内部结构进行建模,共同词性边通过词性复现在句子之间建立关联. 词汇复现是篇章中实现主题推进与主题衔接的重要手段之一. 但由于机器阅读理解任务中有时篇章比较短,重复词比较少,因此,本文引入词性关系边,通过词性的重复将不同句子关联起来,同时也克服了图稀疏的缺陷. 为了进一步克服图稀疏问题,我们还对依存关系进行扩展,将子节点仅依赖于父节点扩展为子节点还依赖于父节点的父节点,即两层依存关系. 类似地,还可扩展到三层、四层等多层依存关系.
当两个结点间有连边时,其权重初始化为1. 图中边的确立过程如式(8)~式(10)所示
A=Adp∪Apos,
(8)
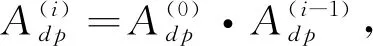
(9)

(10)
式中:Adp为依存关系边集合,可以通过多层依存关系矩阵相乘得到;Apos为词性关系边集合.
2.2.2 图注意神经网络
本文采用图注意神经网络(GAT)来更新图结点的表示. 首先,对图结点做线性变换,通过加性注意力机制计算图结点之间的注意力分数,并用LeakReLU做激活函数,然后对每个图结点所有边的原始注意力分数实现归一化操作,得到注意力权重α,最后对所有相邻节点的特征做基于注意力的加权求和来更新图结点. 具体计算为

(11)

(12)

(13)

(14)

2.3 交互融合模块
该模块对更新后的图结点向量和文本表示向量进行融合,具体采用Transformer[25]机制实现:将向量表示映射为q、k、v,用缩放点积模型计算注意力得分,并基于多头注意力机制将得到的结果进行拼接,然后与最初的表示进行残差连接并进行层归一化. 具体实现为

(15)
H=Transformer(q,k,v),
(16)
式中:wq、wv、wv为线性变换矩阵;H∈Rl×d为融合图结点和文本表示后得到的结果.
2.4 答案预测模块
该模块根据编码模块和交互模块得到文本表示U与H进行问题答案预测. 首先对两部分表示进行残差连接,避免在多次迭代后梯度消失,然后进行层归一化[26],最后通过Softmax函数来预测文本作为答案的概率. 具体计算为

(17)

(18)
式中:Wa和ba分别为线性变换矩阵和偏置向量,为可训练参数.
2.5 优化函数
本文所提阅读理解模型包括问题类型预测和答案预测两部分,因此,损失函数包含两部分
L=La+Lc,
(19)
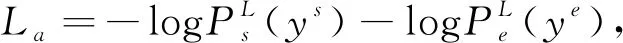
(20)
Lc=-logPc(yc),
(21)

3 实 验
3.1 数据集与实验设置
数据集. 为了验证本文所提模型的有效性,选取更具挑战性的“2020语言智能与智能技术评测”数据集DuReader-robust[27]作为实验数据. 该数据集共包含15 K个样本,其中的问题均为百度搜索中的真实用户问题,文档来自百度搜索结果中的普通网页或百度知道中的问答页面,涉及教育、交通、游戏、医疗等多个领域. 表2 给出了其中的3个示例. 示例1的问题为:“孕妇缺铁对胎儿有什么影响?”,对应的篇章为多个(每一段代表一个篇章),问题答案为2个,分别来自给定的前2个篇章中的片段,评测时模型只需给出其中一个答案即可. 示例2的问题为“喜欢你的票房?”,其中“喜欢你”是电影名,所给篇章包含多个数字,需要模型理解每个数字的意义才能正确答题. 示例3的问题为“漂洋过海来看你唐明和谁在一起?”,其中“漂洋过海来看你”为电视剧名,“唐明”为剧中人物名字,所给篇章包括多个人名,模型需要理解人名关系才能正确回答问题. 可以看出,DuReader-robust数据集比“2018阅读理解技术竞赛”中的DuReader数据集[28]更为复杂.

表2 Dureader-robust数据集示例
预处理. 实验中采用斯坦福发布的自然语言处理工具stanza[29]对数据进行分词、词性标注、依存句法分析等预处理.
参数设置. 模型实现时采用带有权重衰减的自适应动量估计算法(Adam Weight Decay Optimizer)作为优化器来加快收敛. 主要参数设置:初始学习率为5e-5. 为防止过拟合,在模型多处添加了dropout网络,隐藏维度为768,最大输入长度为384,doc_stride为128,图结点数量为160. 实验训练批次大小为6,一共训练5轮.
3.2 实验结果
3.2.1 对比实验
实验中选取目前主流的阅读理解模型作为基线模型与本文所提模型进行对比. 选取的基线模型主要有:
BERT模型:这是由谷歌发布的预训练语言模型,该模型基于Transformer框架中的Encoder部分实现,同时采用多个双向转换层和自注意机制来学习文本中词之间的上下文关系. BERT在许多NLP任务(包括SQuAD阅读理解任务)上都有很好的表现. 本文具体采用的是BERT-Base中文模型.
BERT_wwm模型[30]:该模型是对BERT模型的改进,将其中预训练任务中的掩码语言模型(Masked LM)中的字掩盖变成全词掩盖.
Roberta模型[31]:相比于BERT模型,该模型进行了更长时间、更大批量、更多数据的训练,而且没有采用下一句子预测的预训练任务,动态改变应用于训练数据的掩码模式.
Albert模型[32]:该模型对BERT模型进行压缩,通过矩阵分解和跨层参数共享减少了参数量,加快了模型的训练速度.
Ernie模型(1.0)[33]:该模型是中文预训练语言模型. 实现时对预训练掩码语言模型的任务进行了改进,除了字掩盖,还对词、实体等语义单元进行掩盖,使模型可以学习完整概念的语义表示.
XLNet模型[7]:该模型为排列语言模型,综合了自回归模型和自编码模型的优点,基于 transformer_xl 框架实现. 该模型在20项任务上优于BERT.
实验中采用的评价指标为F1和EM(Exact Match),其中EM表示系统预测与真实答案之间的精确匹配度;F1表示单词准确率和召回率的调和平均值.
除了与baseline模型进行对比,我们还对本文所提模型中图结构与问题分类任务对模型的影响做了研究. 实验结果如表3 所示.

表3 模型实验结果
表3 中,本文模型-DepEdge表示模型在图中没有考虑句法依存边;本文模型-PosEdge表示模型在图中没有考虑词性边;本文模型-QClassification表示模型没有引入问题分类任务;本文模型-Graph表示模型中没有融合图结构;本文模型-QClassification-grgph表示模型既没有融合图结构也没有引入问题分类任务. 从表3结果可以看出,本文所提方法在DuReader-robust数据集上取得了最好的结果,同时可以看出图结构与问题分类任务对模型性能的提升都有帮助. 其中,图结构对性能提升的帮助比问题分类模块更大;图结构中,句法依存边要比词性边的共现更大. 还可以看出,在所有baseline中,XLNet基线模型表现最好,说明模型中采用的自回归与自编码模型具有一定优势.
3.2.2 图结构消融实验
此外,还深入分析了对句法依存边进行不同扩展以及不同词性边对系统性能的影响.
句法依存扩展层数对性能的影响. 正如3.2节所述,为了缓解图稀疏问题,我们对依存关系进行扩展,还分析了依存层数对实验结果的影响. 实验结果如图 3 与表4 所示, 其中i_tu表示i层依存关系,可以看出,随着依存关系层数的增加,系统性能提升,表明系统通过更多层的依存关系获得更多词汇之间的关系,对句子形成了更好的理解. 系统获取6层依存关系构图时,F1值最高,系统获取5层依存关系构图时,EM值最高. 结果说明,在一定依存关系层数后,模型已经充分学习到了词汇之间的依存关系.

(a) F1

(b) EM

表4 句法依存边对系统性能的影响
词性边对系统性能的影响. 本文分析了不同词性边对系统性能的影响,具体实验结果如表5 所示,其中,Noun为名词,Pnoun为专有名词,Verb为动词,Adj为形容词,Pron为代词,Num为数词. 表5中,模型在名词(包含专有名词)边的基础上分别添加其他词性边进行实验,可以看出,当系统中考虑所有词性边后,F1与EM均获得最佳分值;系统添加不同词性边后,系统EM值都增加,但F1值有时会稍有下降(如添加代词边或动词边).

表5 词性边对系统性能的影响
表6 给出部分示例,这些示例本文模型可以正确回答,而BERT模型回答错误. 可以看出,通过不同的词性边,系统加强了句子之间的关联,形成了对句子语义与篇章更好的理解,因此模型给出了正确答案.

表6 结果示例
4 结 论
为了在阅读理解模型中有效整合句法结构、句子间长距离语义信息,本文尝试利用图结构对句子内部的句法结构与句子间的语义关系进行建模,然后与基于注意力机制的表示进行融合,最终形成对篇章与问题更好的理解与表示. 同时,本文还引入问题分类任务,与阅读理解问答任务形成多任务学习框架,进一步优化问题与文本的表示,使系统获得了更好的答案预测准确率. 相关数据集上的实验结果表明,本文所提方法取得了比基线模型更好的效果.
猜你喜欢
电子制作(2021年14期)2021-08-21
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
制造技术与机床(2019年10期)2019-10-26
山东冶金(2019年1期)2019-03-30
电子制作(2018年18期)2018-11-14
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
数学物理学报(2018年1期)2018-03-26
小学教学参考(2015年20期)2016-01-15
语文知识(2014年1期)2014-02-28
