
基于PF-LSTM的云资源预测
2021-11-01 13:26谢晓兰梁荣华
计算机工程与设计 2021年10期
谢晓兰,梁荣华
(桂林理工大学 信息科学与工程学院,广西 桂林 541006)
0 引 言
进入移动互联网时代后,移动设备的爆发性增长,导致互联网直播、视频和其它多媒体服务的随之增长,数据量的增长也对云资源的工作负载能力提出了更高的要求[1,2]。
容器是一种轻量级的虚拟化技术,它具有封装粒度小、部署效率高等优势,它在负载均衡、高并发计算等领域也具有广阔的应用前景,对于容器的负载研究也成为了近年来的一个研究热点[3,4]。但是在容器云研究领域,对于容器的资源负载研究还比较少,如果能够对提前对容器的资源使用量进行预测,那么就可以提前对资源进行管理,提前预留可用资源、回收多余资源和重新分配资源,提高资源的利用效率,降低运营成本,提高经济效益。
事实表明,容器中的负载压力往往来源于极端状况下的突发负载[5,6]。突发负载会在短时间内索取或者释放大量资源,造成容器的抖动,因此,对突发负载进行合理的预测,提前对容器资源进行调整,保证满足服务质量QoS(quality of service)和服务水平协议SLA(service level agreement)的要求,减少容器的频繁抖动就成为了容器云资源计算的一个研究重点。
本文结合了文献[16]提出的概率预测(probabilistic forecast)方法和改进的长短时记忆网络模型(long short-term memory)提出PF-LSTM模型来对容器云工作负载预测进行研究,PF-LSTM基于改进的LSTM模型,结合了概率预测理论来预测突发负载状况,同时引入额外的协变量降低预测误差。实验结果表明,本文方法相比传统预测方法,可以提高预测的准确性,降低预测误差。
1 相关工作
在云计算领域,云资源预测是一个重要的研究领域,通过对云计算资源进行预测,可以减少资源抖动和避免产生SLA违约,提高QoS质量,长期以来就受到研究学者的广泛重视。但由于现实情况复杂多变,并且突发负载也导致了预测结果不够准确,如何对资源进行准确预测尤其是突发负载进行预测就是目前面临的一大挑战。
目前的常用预测方法有隐马尔可夫、贝叶斯、支持向量机和神经网络等方法。Balaji M等[7]根据隐马尔可夫提出了云资源负载均衡算法,但是隐马尔可夫存在着不能考虑到上下文的特征,特征选择过于单一的缺点。Shyam G K等[8]提出了一种贝叶斯模型,用来解决CPU和内存密集型的应用资源预测问题,虽然能够识别出变量之间的依赖关系,但是没有能够考虑到几种应用程序之间的组合问题。Zhang W等[9]提出了一种基于动态的布谷鸟算法的BP神经网络模型,优化了BP神经网络模型的搜索效率和收敛精度,但是神经网络的预测稳定性较差,不能够较好适应结构不同的云计算资源数据。
有研究表明预测云计算资源与时间序列密切相关[10]。因此,就出现了基于时间序列的云资源预测方法。这种方法是利用过去一段时间的历史数据,建立一个预测模型,对未来的趋势与走向进行分析,已经广泛利用于金融分析、天气预测、实时交通等领域。
常用的传统时间序列预测方法有自回归模型(auto regressive model,AR)、滑动平均算法(moving average model,MA)、指数平滑法(exponential smoothing,ES)和自回归移动平均算法(auto regressive integrated moving average,ARIMA)等。AR模型属于线性回归模型,通过观测点前若干时刻的变量的线性组合来描述观测点后若干时刻变量的值。ES算法通过使用指数平滑的方法,使用最近的一组实际值,并通过参数的交叉验证来预测未来值。MA模型通过最近一段时间的数据进行加权计算,得出预测结果。ARIMA模型由AR和MA两者叠加,具有两个模型的特点,但是模型参数比较多,因此实现起来较为复杂。
文献[11]使用加入了多个二次指数平滑模型的指数平滑算法对弹性云服务器进行预测,但是模型需要进行多次构造,实现较为复杂。文献[12]提出了一种自适应的AR模型并且使用新的权值计算方法,实验结果表明,该算法提高了集群中的负载均衡预测效果,但是该算法会增加集群中的服务器负担,提高了服务器的能源消耗。文献[13]使用了基于ARIMA和CART的联合模型,通过加权最小二乘法改进的ARIMA预测线性部分,使用了边界判定优化的CART预测非线性部分,并结合两者获得综合预测结果。但是,上述研究都没有涉及到突发负载的研究,并且使用的是单一的目标时间序列,难以获取额外的特征信息。不能够保证研究出突发负载下的预测精度。
一直以来,循环神经网络(recurrent neural network,RNN)和它的变体算法长短时记忆网络(long short-term memory,LSTM)被认为是时间序列数据预测的优良算法。文献[14]使用果蝇算法优化LSTM算法,通过对时序数据进行分析,并提高了果蝇算法的寻优能力和局部收敛能力,但是存在着对于突发负载时段的数据不能较好的拟合的问题。文献[15]对非线性的时间序列数据进行分析,并且使用粒子群算法进行调优,对互联网的传播行为进行了预测分析,但是在面临突发负载数据时的准确性较低。
本文将基于概率预测方法和LSTM模型相结合来对容器云工作负载进行研究预测,将概率预测方法与改进的多层LSTM模型结合来提高在突发负载状况下的预测精度,同时引入额外的协变量序列特征降低模型预测误差。
2 PF-LSTM模型
2.1 模型概述
从统计学角度来说,云资源负载请求中的大部分负担来源于极端突发事件。突发的高负载需求会导致资源不足,高低负载的落差会导致资源浪费,频繁的资源请求会造成云资源的抖动。因此,正确估计此类突发事件的概率对于平衡资源分配与负载服务质量尤其重要。
本文将概率预测与改进的多层LSTM模型相结合提出了PF-LSTM模型,概率预测对需求并不只是简单的估计,而是估计未来每一种情况的概率。它会评估需要0个单位的概率,需要一个单位的概率,需要两个单位的概率,以此类推。每个需求级别都会进行概率估算。
本文PF-LSTM模型结构如图1所示,它与传统方法不同,传统的单值预测往往会衡量时间序列数据处于平均数权重或中位数权重的状态,但无法准确反映突发时刻的负载情况。但是,关键不在预测结果的准确性上,而在于中位数预测并不能解决极端事件的问题。传统方法上在负载中是通过预设基础的需求来解决这个问题的。但是,这种方法通常基于事实假设,例如需求呈正态分布,但是这在预测领域中是不够准确的。

图1 PF-LSTM模型结构
PF-LSTM和传统的单一值预测模型相反,它通过概率预测结合LSTM模型的训练,在训练过程中不断降低分位数预测的误差,把预测结果区间化,降低误差。因此,该策略要优于大部分传统策略,因为此类策略采用了基于未来需求概率估算的准确结构。所以,概率需求预测与传统的方法相比,预测效果要更好。
2.2 模型训练
本文模型目标是通过时间序列z和协变量x得出模型的预测结果,如下所示
p(zi,t0∶T|zi,1∶t0-1,xi,1∶T)
(1)
其中,时间序列数据i在时间t的目标值表示为zi,t,t0表示
预测开始时刻,t0-1表示预测开始时刻的前一个时刻。从t0到T时间序列表示为
[zi,t0,zi,t0+1…,zi,T]∶=zi,t0∶T
(2)
从1到t0-1的时间序列表示为
[zi,1,…,zi,t0-2,zi,t0-1]∶=zi,t0-1
(3)
而xi,t表示的是与目标时间序列相关的协变量,模型的训练过程如图2所示。

图2 模型的训练过程
模型在输入层中接收到时间序列zi,t-1,以及协变量xi,t,然后传递给LSTM网络的隐函数L中。本文的LSTM模型为改进的多层LSTM模型,如图3所示。LSTM模型在训练过程中对浅层LSTM单元进行训练,收敛后保留了原有LSTM模型参数,而且在LSTM模型前加入多层神经网络模型,增加了训练深度,提高了LSTM模型的预测准确率,模型的最后还加入了随机丢弃层(Dropout),可以一定概率让部分神经元不参与训练,减少过拟合现象。

图3 改进的LSTM模型
在计算得出中间输出Li,t后,将结果传递给似然函数Lh。LSTM网络的隐函数L和似然函数Lh的计算公式如下所示
Li,t=L(Li,t-1,zi,t-1,xi,t,Θ)
(4)
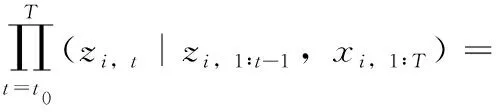
(5)
图2中的L是LSTM神经网络的内部函数,Li,t是LSTM在时间步t的中间输出,通过式(4)计算得出。将上一个时间步t-1的中间输出Li,t-1,时间序列zi,t-1,协变量xi,t和LSTM的内部参数Θ代入到式(4)中求出当前时间步t的中间输出Li,t,求出中间输出Li,t后,代入到式(5)中,就可以得出当前时间步t上的分布结果。
在模型训练完成之后就可以进行预测。如图4所示,将时间序列zi-1以及协变量xi,t-1输入到模型中,此时,在每个时间步t上的预测结果都是分布,而不是单个值。

图4 模型的预测过程
从输出分布中抽取一个样本值,通过式(5)计算得出模型对于时间序列的极大似然估计的条件概率,将该样本值作为第二步的输入,也就是通过式(4)计算出网络的初始状态输出Li,t0-1,然后依此类推,直到预测区间的值都被取到,条件区间zi,1∶t0-1的值经过Li,t0-1就转化为预测区间的值zi,t0∶T。
2.3 似然函数
似然函数对模型的预测效果起着非常重要的作用,因为模型通过对时间序列上的条件区间进行极大似然估计,从而得出预测区间的预测结果,所以应该根据时间负载序列数据的类型选择合适的似然函数。本文使用了两种似然函数:高斯似然(Gaussian likelihood)和负二项式似然(negative-binomial likelihood)。
(1)高斯似然
通过数学期望(mean)和标准差(standard deviation)来计算高斯分布,其中数学期望μ由LSTM网络的仿射变换得出,而标准差σ由LSTM网络的softplus激活函数通过仿射变换计算得出,即θ=(μ,σ),其中高斯似然的计算公式如下所示
(6)
(7)
(8)
(2)负二项式似然
负二项式分布计算公式如下所示
(9)
(10)
(11)
式(9)~式(11)中所有的参数μ和参数α都是通过具有softplus激活函数的多层LSTM模型网络的全连接层计算得出的。
2.4 协变量
在统计学中,协变量(covariate)是可能影响统计结果的量。它与自变量相似,会对统计结果产生影响。但是协变量与自变量又不完全相同,只要是能够对统计结果有所影响的变量,都能将其作为协变量考虑。协变量xi,t可以是变量相关的,也可以是与时间相关的,或者两者皆有。它们可以为模型提供额外的信息,例如,在云资源负载预测中,目标服务器的归属,额外的网络流量特征,机器内存负载,数据是否具有周期性规律都可以纳入协变量特征考虑。
如图5所示,有3条曲线,第一条曲线zi,t是云负载时间序列数据,还有两条曲线xi1,t和xi2,t。xi1,t和xi2,t是zi,t对应的协变量曲线,分别表示服务器上的磁盘负载和网络流量。通过将协变量曲线纳入预测模型之中,对于模型分析云负载的时间序列数据时起到重要作用,可以提高预测结果的准确性。

图5 目标特征数据与协变量曲线
除了直接引入与预测目标有关的协变量特征外,还可以对预测目标的数据进行归纳分析,派生出相关的时间特征,将时间特征作为协变量进行分析。如图6所示,zi,t是一个记录周期为30天的云负载数据,通过对zi,t进行分析,得出了两条由zi,t派生出的时间序列特征曲线ui1,t和ui2,t,ui1,t中的峰值对应一天中的小时,ui2,t对应一周中的日期。也就是说,可以通过时序分析得出zi,t的负载峰值的到来时刻和日期,将分析出的特征作为协变量。

图6 派生出的时间特征模式
3 实 验
3.1 实验数据
为了验证和评估本文提出算法的预测结果,本文使用了阿里巴巴公司的2018年的公开集群数据集(cluster_trace_V2018)[17]作为训练和测试数据进行实验。该数据集记录的机器的参数信息见表1。

表1 数据集机器参数
3.2 实验环境
使用Python语言实现了本文模型,在物理服务器下进行了实验,实验环境配置见表2。

表2 实验环境配置
3.3 评价指标
为了量化模型的预测效果,实验使用均方根误差(RMSE)、平均绝对百分比误差(MAPE)和加权分位数损失(weighted quantile loss,wQL)作为评价指标。这3种指标是用来评价时间序列预测模型的常用指标,它们的计算公式表示如下
(12)
(13)

(14)

3.4 实验结果
该数据集中的机器每隔1 s到60 s记录一次机器工作负载数据,但是,由于预测时间序列数据需要保证数据的完整性和准确性,时间序列数据需要按照一定的时间间隔排列,因此这种时间间隔不同的时间序列数据不能直接用于实验,需要对时间进行归一化处理。因此,在本实验中,对数据集中的数据的采样频率归一化为5 min和60 min,并且使用插值法对空值和异常值进行处理。
从实验数据集中选了两条机器编号分别为M_1022和M_1149的数据,所选择的实验数据的详细指标见表3。选取80%的数据作为训练集,选取20%的数据作为测试集,并且各预留了100个采样点的数据作为验证预测结果。

表3 实验数据指标
本实验所选择的预测指标是机器的CPU利用率。根据相关研究,机器的网络流量与CPU利用率密切相关[18],因此在本实验中选择机器当前的网络流量作为预测CPU利用率的额外协变量。
在对表3中的数据进行模型训练后,使用了3种不同的预测算法AR、EST和未经改进的LSTM与本文算法PF-LSTM进行了预测误差对比,它们的RMSE、MAPE和wQL[0.1]和wQL[0.9]的值见表4和表5。

表4 机器M_1022的4种算法预测误差对比结果

表5 机器M_1149的4种算法预测误差对比结果
分析了表4和表5两个数据集的实验结果,PF-LSTM和单一的未经改进的LSTM算法对比,RMSE和MAPE都要比LSTM低,说明PF-LSTM的预测误差上要比LSTM更低。同时,再和传统的预测算法AR和EST对比,PF-LSTM的预测误差也是要比传统的单一算法更低,说明引入概率预测的LSTM模型在云负载时间序列数据的预测要比传统的预测算法更准确。然后再对比wql[0.1]和wql[0.9],PF-LSTM也是要比LSTM和传统的预测算法AR和EST更低,说明在分位数损失的概率分布的预测上,PF-LSTM也要比其它算法更为准确。
为了更加清晰地显示预测结果,使用训练好的PF-LSTM模型来对未来趋势进行预测,预测结果如图7和图8所示。

图7 PF-LSTM对机器M_1022数据的预测结果

图8 PF-LSTM对机器M_1149数据的预测结果
从图7、图8中可知,除了一些负载波峰的地方预测结果有所偏差,其它数据段的结果重合程度还是比较高的,并且真实值数据基本都处于90%的置信区间,这表明本文模型的预测效果还是比较高的。
4 结束语
本文提出了一种将概率预测方法与改进的多层LSTM模型相结合的PF-LSTM模型,用来对云负载的时间序列数据进行预测,提高了在突发负载时的预测精度,并且通过协变量的引入,降低了模型的预测误差。同时,通过改进似然函数使得随机丢弃中间输出,减少模型的过拟合现象。
为了验证PF-LSTM模型的预测效果,与其它3种预测算法进行了对比实验,实验结果表明,PF-LSTM模型对云资源负载时间序列数据进行训练学习,可以对其未来趋势做出有效预测,除了一些波动较为频繁的区间外,PF-LSTM模型的预测效果更好,与其它算法相比,PF-LSTM的预测精度更高,并且预测误差也要更低。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
