
基于改进YOLOv4算法的零件识别与定位*
2021-11-03 07:26陈赛旋崔国华朱新龙
组合机床与自动化加工技术 2021年10期
杨 琳,陈赛旋,崔国华,朱新龙
(上海工程技术大学机械与汽车工程学院,上海 201620)
0 引言
深度学习凭借着计算机硬件技术的不断革新已成为机器视觉中热门的研究方向,其中基于深度学习的零件识别与定位是备受关注的研究内容之一。传统零件识别与定位主要是基于模板匹配(Template Matching)算法[1],待识别零件必须以固定大小和角度等要求摆放在相对简单的环境之中,无法满足在相对复杂环境中对零件进行实时且精准的识别与定位要求。而深度学习相比传统算法有更优的识别能力、计算速度和检测精度[2]。
近年来,各国研究者致力于降低目标检测算法的训练成本,提高算法精度并缩减推理时间,如2015年,Girshick等人受何恺明提出的空间金字塔池化网络(Spatial Pyramid Pooling Networks:SPPnet)[3]启发,将计算速度慢且内存占用大的R-CNN(Region-based Convolutional Neural Networks)[4]改进为结构更精巧的Fast R-CNN[5],大幅提高了计算速度;2016年,Redmon J等提出了YOLO目标检测算法[6],将检测问题视为回归问题,网络框架简单,识别速度快;同年, Liu W等提出了比YOLO精度更高的SSD(Single shot detection)[7],但这个精度优势很快就被YOLOv2[8]打破。
为了提高工业生产中多角度无序零件识别准确率和定位精准性,在原有YOLOv4[9]基础上设计了一种针对性的零件识别与定位高效网络,首先,在优化算法上使用AdaBelief[10]代替原有SGDM[11];其次,在预测边界框计算方法中加入Canny边缘检测[12]和Sklansky算法[13],使用凸包和最小外接矩形框代替原有预测边界框;最后,在制作的零件数据集上进行基于改进YOLOv4的零件识别与定位实验。实验结果表明,该基于改进YOLOv4算法的零件识别与定位方法提高了收敛速度和识别精度,可提供精准的零件凸包和最小外接矩形框,以及最小外接矩形框四个角点的坐标,可为工业智能制造中诸如分拣机器人的抓取检测等工序提供更精准的定位依据。
1 YOLOv4目标检测算法
2020年4月, Redmon J等接棒YOLOv3[14],在原有基础上,通过排列组合各种先进卷积神经网络优化技巧的方式进行优化验证实验,总结出了在帕累托曲线上达到速度与精度最优平衡的YOLOv4,相比YOLOv3,在MS COCO数据集上平均精度(Average Precision:AP)提高了10%,检测帧率(Frames Per Second:FPS)提高了12%,是目前最强大的目标检测算法之一。
其中,YOLOv4的骨干网络采用CSP Dark-net53,显著地增强了感受域的大小,使用PANet(Path Aggregation Network)特征融合网络,且连接方式修改为更优的相乘,头部则仍延续了YOLOv3的一步法(One-Stage),无需生成候选区域。另外,YOLOv4还使用了许多优化技巧,如马赛克(Mosaic)数据增强,自对抗训练数据增强(SAT),随机丢弃特征图特征块(DropBlock)正则化法,跨阶段局部网络(CSPNet)等。
2 改进的YOLOv4目标检测算法
2.1 改进优化算法
YOLOv4使用的优化算法为较为传统的带动量梯度下降法(SGDM),改进自1951年Herbert Robbins提出的随机梯度下降法(SGD)[15],收敛速度较慢,容易陷入局部最小点,但近年发展迅速的自适应学习率法如Adam[16]等相比梯度下降法仍存在泛化能力较差,检测精度不稳定等问题。
针对以上问题,对YOLOv4进行优化算法改进对比实验,实验中,分别使用AdaBelief、Adam和前期Adam[16]后期SGDM三种方法,并与原始SGDM进行对比。其中,AdaBelief为可根据当前梯度与其指数移动平均值(EMA)的差值来调整步长的高效自适应学习率法。
优化算法对比实验中,统一在VOC2007标准数据集上进行训练和检测,并根据训练时的收敛速度和检测时的识别精度对实验进行评价。VOC2007是衡量目标检测算法识别能力的小规模标准数据集,共包含20个种类,共计9963张图像,训练集5011张图像,测试集4952张图像,其中训练集在训练时会按9:1的比例分为训练数据和验证数据,在训练数据上可得到训练损失(tain loss),体现训练的拟合能力,loss值越低表示训练拟合能力越好,反之越差,在验证数据上可得到验证损失(val loss),体现未知数据的拟合能力,即算法的泛化能力,loss值越低表示泛化能力越好,反之越差。
实验参数设置为:学习率(Learning_rate)为0.001,每批次送入网络的图像数量(Batch_size)为64,训练期数(epoch)为100,输入图片分辨率(Input_shape)为416×416,不同优化算法的参数为:SGDM的动量(Momentum)为0.9,Adam的权重衰减 (Weight_decay)为0.000 5,AdaBelief的指数衰减率(Betas1,2)分别为0.9和0.999。
具体实验过程为:首先在VOC2007训练集上分4次训练使用原始SGDM、Adam、SGDM切换Adam和AdaBelief优化算法的YOLOv4,其中Adam切换SGDM为前期使用Adam迭代至50epoch,加快loss下降速度,然后切换为SGDM对网络参数进行数值调优;其次在每次训练结束后,保存训练过程的数据,并从数据中分别提取出tain loss和val loss在训练时每个epoch的数值;最后,将提出来的数据进行整合,分别绘制成tain loss和val loss随epoch下降的曲线图。
如图1所示,使用AdaBelief的YOLOv4在训练时loss下降速度和最终收敛效果均有所提升,表明选择AdaBelief作为优化算法可以提升网络的拟合能力和泛化能力。

(a) tain loss

(b) val loss图1 loss下降图
将训练好的权重载入网络,在VOC2007测试集上使用训练好的网络进行测试,并采用通用的目标检测评价指标平均精确度均值(mAP:Mean Average Precision)评价4种不同优化算法对YOLOv4识别精度的影响。mAP为各类别AP(Average Precision)的平均值,表示网络在测试集上的综合识别能力,AP为以准确率(Precision)为纵轴,召回率(Recall)为横轴的“P-R图”中“P-R曲线”下的面积,表示网络在测试集中某一种类别的识别精度。
优化算法对比实验的具体测试结果如表1所示。

表1 优化算法识别精度表
如表1所示,在VOC2007测试集上使用SGDM的测试mAP为80.06%,而使用AdaBelief的测试mAP达84.23%,相比SGDM提高了4.17%,且比使用Adam和Adam切换SGDM的mAP均更高。实验结果表明,使用AdaBelief的YOLOv4在VOC2007标准数据集上收敛速度更快,收敛效果更好,mAP更高。
2.2 改进预测边界框
YOLOv4的预测边界框计算方法为:先通过交并比(Intersection-over-Union: IoU)阈值,一般设置为0.5,筛选掉置信度低的边界框,得到置信度最高的预测边界框中心坐标(bx,by)和边界框的宽bw和长bh,然后根据中心坐标和边界框长宽计算出预测边界框左上和右下两个点的坐标,具体公式如下:
(1)
当要定位的零件形状较长,如不同角度的轴类零件,YOLOv4所得的预测边界框无法很好的表示部分零件实际形状,仅仅使用预测边界框左上和右下两个点的坐标作为零件定位,可能会导致后续要求定位精准性的工序出现较大的误差。
针对以上问题,在不影响零件检测速度的前提下,选择使用Canny边缘检测和Sklansky算法对YOLOv4预测边界框计算方法进行改进。
图2为齿轮轴检测示例图,图2a为YOLOv4检测原始检测结果图,图中有与齿轮轴实际形状重合率较低且无法精准表示齿轮轴实际形状的正矩形预测边界框,齿轮轴的分类标签gear-shaft和相应的置信度0.99,输出的定位坐标为预测边界框左上点A(87,108)和右下点B(451,380),图2b为改进YOLOv4检测结果图,图中有齿轮轴的凸包、最小外接矩形框以及齿轮轴的分类标签gear-shaft,凸包为可以表示齿轮轴真实形状的凸多边形,同时可以得到凸包上每个角点的坐标,但通常凸包的角点有几十个,最小外接矩形框为更加通用的定位结果,且与齿轮轴的重合率远高于原始预测边界框,同时可以得到最小外接矩形框4个角点的坐标,输出的坐标分别为A′(119,382),B′(60,281),C′(393,85),和D′(453,186)。

(a) 改进前 (b) 改进后图2 齿轮轴检测示例图
图3为具体改进过程示例图。①根据原始预测边界框将图像裁剪为单独的零件图,如图3a所示,简化后续图像分割的计算量,以保持YOLOv4实时检测速度的优势;②使用高斯模糊对零件图进行图像预处理,通过计算每个像素点与邻近像素点的加权和,并使用加权和作为新的像素点来降低零件图中的噪声,取点范围为高斯核尺寸,尺寸越大,高斯模糊的效果越强,但会因此增加计算量,经过实验对比,如图3b所示,选择9×9大小的高斯核函数零件预处理效果最佳;③使用Canny边缘检测对预处理后的零件图进行轮廓提取,该方法是基于边缘梯度方向的非极大值抑制对零件图进行分割,其中双阈值的选取系数Th和Tl分别选取90和30,并将低于Tl的点置零,高于Th的点标记为边缘点,处于中间的点根据邻近的像素点状态估计该点是否属于边缘,最终得到的轮廓如图3c所示;④由于Canny边缘检测所得轮廓的轮廓点不连续,存在大量短轮廓,为解决上述问题需对轮廓图进行图像膨胀与腐蚀处理,其中图像膨胀是对每个像素点邻近范围内的像素点置为该范围内的像素最大值,以此填补轮廓中的间断部分,并将短轮廓与大轮廓相连,图像腐蚀的原理则与膨胀相反,是将每个像素点邻近范围内的像素点置为该范围内的像素最小值,以此去除因图像膨胀产生的多余部分,经过试验对比,如图3d所示,选择17×17的卷积核对零件轮廓图进行膨胀与腐蚀效果最佳;⑤计算经过图像处理后的轮廓所包含的坐标数量,取坐标数量最多的轮廓为主轮廓,根据主轮廓点集,使用Sklansky算法计算凸包,如图3e所示,得到包含零件几何形状的凸多边形;⑥根据多边形与其最小外接矩形必有一条共线边的几何原理和旋转卡尺算法(Rotating Calipers),枚举凸多边形(即凸包)每一条边组成的外接矩形框,计算外接矩形框的面积,其中面积最小的外接矩形框,如图3f所示,为零件的最小外接矩形框;最终,使用凸包和最小外接矩形框代替原始预测边界框,作为改进的零件定位结果。

(a)裁剪(b)预处理 (c)分割

(d)膨胀腐蚀 (e)凸包 (f)最小外接矩形框图3 预测边界框改进过程示例图
3 实验与分析
设计的实验步骤流程如图4所示。

图4 实验流程图
3.1 实验环境
所有实验在同一工作站中进行,具体配置如表2所示。

表2 实验环境
3.2 实验参数
为充分利用工作站硬件,加快训练速度,根据数据集和实验环境的情况,实验参数设置为:每批次送入网络的图像数量(Batch_size)为64,输入图片分辨率(Input_shape)为416×416,训练期数(epoch)为100,学习率(Learning_rate)为0.001,AdaBelief的指数衰减率(Betas1,2)分别为0.9和0.999。
3.3 零件数据集
零件数据集制作过程为:①使用相机采集螺母、螺丝、齿轮、齿轮轴等共6种常见零件,共计1224张,采集过程中各种零件通过不同角度且杂乱无序的方式摆放;②使用OpenCV对采集的1224张零件图像进行图像压缩,并使用旋转、平移、缩放、翻转等方式对进行图像增强,扩充数据,再将处理后的图像根据质量进行筛选,得到共计2448张图像的零件图像集;③使用“labelImg”图像标注工具对零件图像集进行人工标注,根据自定义的零件标签,对图像集中所有零件手动标注矩形标注框;最终,制作成包含6种类别,共计2448张图像的零件数据集,并根据8:2的比例将零件数据集分为零件训练集1958张和零件测试集490张,表3为数据集中零件种类与数量的详细情况。

表3 零件数据集种类与数量表
3.4 评价指标
使用常用的目标检测评价指标对改进YOLOv4的零件识别与定位方法进行评价:准确率(Precision)、召回率(Recall)以及准确率与召回率综合指标(Precision和Recall 的加权调和平均F-Measure,α=1时:F1-Measure),具体公式如下:
(2)
(3)
(4)
样例总数TP+FP+TN+FN
(5)
其中,TP表示真正例(True Positive),FP表示假正例(False Positive),TN表示真负例(True Negative),FN表示假负例(False Negative),Precision是真正例(TP)在所有预测正例(TP+FP)中的比例,Recall是真正例(TP)在所有真实正例(TP+FN)中的比例,F1-Measure是Precision和Recall权重参数α=1时的综合评价指标,F1越大,所评价的网络分类能力越强,反之,F1越小,分类能力越弱。
3.5 零件识别与定位实验
零件识别与定位实验中,首先在零件训练集上训练优化算法改进为AdaBelief,定位结果改进为凸包和最小外接矩形框的YOLOv4,然后使用训练得到的权重文件配置网络,并在零件测试集上使用训练好的网络进行零件识别与定位实验。
图5为检测过程示例图。

(a)零件测试图 (b)YOLOv4原始检测图

(c)Canny边缘检测 (d)图像膨胀与腐蚀

(e)凸包 (f)最小外接矩形框图5 检测过程示例图
将基于改进YOLOv4的零件识别与定位实验结果与未改进的实验结果进行对比,图6为改进前后零件检测示例图,相比图6a中未改进的YOLOv4检测所得的预测边界框,图6b中改进YOLOv4检测所得的零件凸包和最小外接矩形框与零件实际形状重合度更高,更能表示零件实际形状,同时可以输出相应零件最小外接矩形框的4个角点坐标,其中图6c和图6d是侧视角度的零件识别与定位对比示例图,改进的网络仍能有效的对零件进行识别与定位。

(a)改进前 (b)改进后

(c)改进前 (d)改进后图6 检测结果示例图
图7为改进前后6种类别零件,共计490张测试图像的具体检测结果,经过计算,改进前真正例(TP)为1353个,改进后为1352个,数量几乎不变,但齿轮轴(gear-shaft)、齿轮(gear1和gear2)、螺母(Nut)和螺丝(Screw)这4类零件的假正例(FP)数量均有不同程度的降低,且假正例(FP)的总数也由152个降至96个。

(a) 改进前
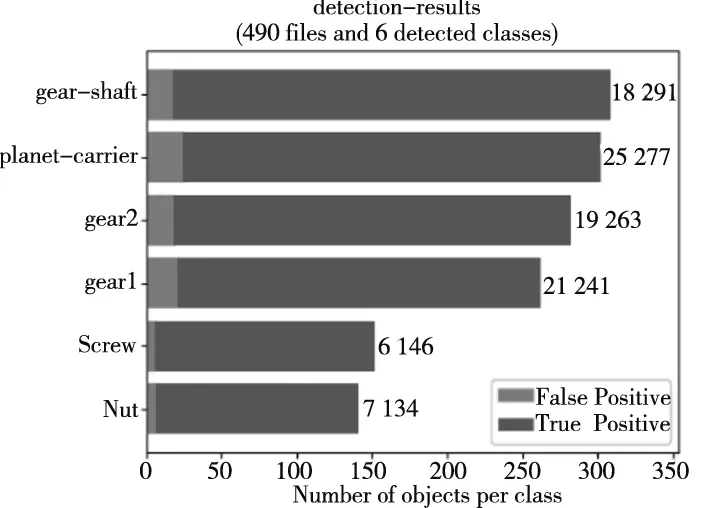
(b) 改进后图7 检测结果数据图
如表4所示,训练好的改进网络在零件测试集上的测试Precision达93.37%,相比改进前Precision 为89.90%,提高了3.47%,改进前后Recall变化不大,Precision和Recall的综合指标F1由94.32%提升至96.16%。

表4 检测数据表
最终,通过在零件数据集上的零件识别与定位实验表明,改进后的YOLOv4在零件识别准确率和零件定位精准性上相比于原始YOLOv4有较大的提高,针对常见种类的多角度无序零件具有较强的综合识别能力。
4 结束语
针对多角度无序零件识别与定位这一任务,提出了基于改进YOLOv4的零件识别与定位方法。改进内容包括优化算法和预测边界框两方面,首先使用AdaBelief优化算法代替原有的SGDM优化算法,提高网络收敛速度和识别精度;其次在预测边界框计算方法中加入Canny边缘检测和Sklansky算法,使用Canny边缘检测进行图像分割得到零件轮廓点,根据轮廓点使用Sklansky算法计算凸包,再根据凸包计算最小外接矩形框,将正矩形定位框改进为更能表示零件实际形状的凸包和最小外接矩形框,提高网络定位精确性。
根据多种联合评价指标对实验结果进行分析,改进YOLOv4在零件数据集上零件识别准确率与定位精准性均有所提升,最小外接矩形框的角点坐标可为工业制造领域中零件自动化分拣、上下料等后续工序提供依据,但设计的网络存在对密集堆叠的小零件识别能力较弱的缺点,后续研究可针对这一问题进一步改进。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
现代装饰(2020年4期)2020-05-20
数学物理学报(2019年6期)2020-01-13
沈阳理工大学学报(2019年4期)2019-09-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
科学与技术(2019年3期)2019-03-05
证券法律评论(2018年0期)2018-08-31
今日农业(2017年4期)2017-12-22
外语学刊(2014年6期)2014-04-18
