
Tesseract-OCR的文档扫描识别系统
2021-11-17 07:01深圳技师学院杨思怡付相祥吴晓华
电子世界 2021年20期
深圳技师学院 杨思怡 付相祥 吴晓华 夏 清
在高速信息化的时代,针对海量文档数据处理效率低下的问题,提出了一种基于OCR技术的识别系统,首先利用OpenCV对文档数据进行预处理滤波,边缘计算,灰度化等一系列预处理,然后使用Canny算子找到图片边缘信息后应用一个透视的转换去获取一个文档的自顶向下的正图,最后完成了一个基于Tesseract-OCR的文档扫描识别项目,该实验表明此方法具有准确的识别率,提供多种语言开发调用,以及具备高可用性;可以有效提升数据录入的效率,大大减轻人工的消耗。
随着信息技术的快速发展,数字化时代已然来临。人们不再满足传统的纸质办公而是将需求投放在了电子文稿上,在现如今的商业事务中,资金的往来以及员工的报销将会产生大量的纸质票据,而将纸质的票据进行保存及录入成为了一大难题。在传统的票据录入中往往需要耗费大量人工进行手动录入,但其却存在效率低下,差错率高,成本昂贵等弊端。为了有效提高票据录入的效率,本项目将提出Tesseract-OCR引擎所给出的一套自适应识别方法。利用OpenCV函数库对图像进行滤波,灰度化,阈值化处理后得到二值图像。再通过透视变换对图像进行摆正,应用一个透视的转换去获取一个票据的自顶而下的正图,最后再通过OCR技术对票据进行识别。具体过程如图1所示。
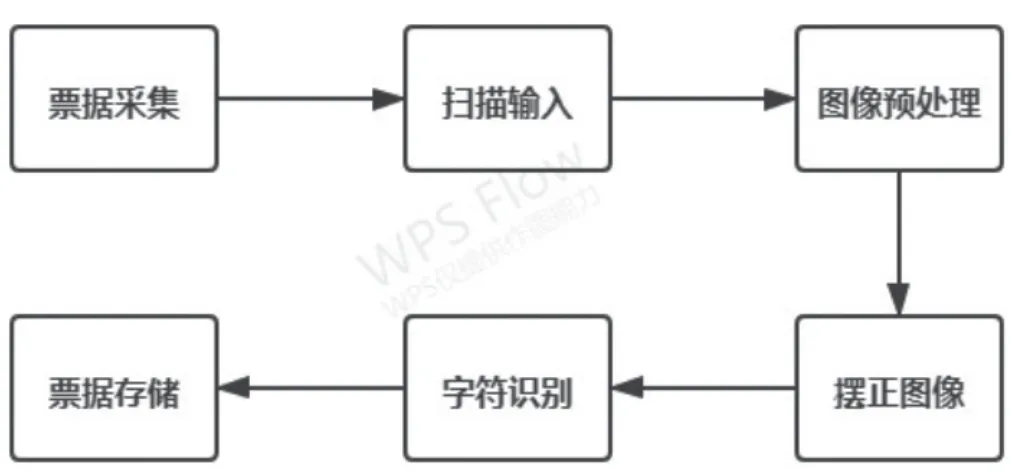
图1 文档扫描识别具体过程图
1 OpenCV和Tesseract-OCR识别
1.1 OpenCV
OpenCV是一个跨平台计算机视觉和机器学习的软件库,它可以运行在各大操作系统上,并且能提供多种语言的接口。例如Python语言就是其中之一,它的应用领域非常的广泛,比如物体识别、人机互动、图像分割、等各种领域,因此被大量使用。
1.2 Tesseract-OCR识别
Tesseract的OCR引擎是由惠普实验室于1985年到1955年进行研发的,自2006年开始谷歌改进了其算法,通过消除bug,优化其相关工作。它可以获取图像并将它们转译成多种语言(包括中文)的文本,并支持用户能不断的训练字库,使用图像转换文本的能力不断增强。Tesseract在本项目中的作用是进行字符识别。
2 透视变换-摆正图像
透视变换也可以称作投影映射,它是将成像投影到另一个视频里,它是二维(x, y)到三维(X, Y, Z),再到另一个二维(x', y' )空间的映射。校正对畸变图像,它需要获取图像的一组4个点的坐标,和目标图像的一组4个点的坐标,再利用两组坐标点则可以计算出透视变换的变换矩阵,最后对原始图像执行变换矩阵,就可以实现图像校正功能。
如图2所示的公式可以看出变换之前的点是z值为1的点,它在三维平面上的值是x, y,1,在二维平面上的投影是x, y,通过矩阵变换成三维中的点X, Y, Z,再通过除以三维中Z轴的值,从而转换为二维中的点x', y',代码如下:

图2 透视变换公式

3 图像二值化
OpenCV图像处理模块中常用的阈值化处理有三种:普通阈值化,自适应阈值,和Otsu二值化。
光影环境对效果的影响非常大,当同一幅图像上的不同地方具有不同的亮度时,应用局部阈值的处理方法会出现一块黑,一块白的情况,并且黑的区域下无法对特征进行提取。在这种情况下我们将采用自适应阈值的处理方法,它是根据图像上的每一个小区域计算与其对应的阈值,所以在一幅图像上不同的区域将会采用不同的阈值,极大降低了阴影对于图片本身的影响,从而我们在亮度不同的情况能获取到更好的结果。
本项目将在OpenCV中运用thresh3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
函数进行自适应阈值的处理。
4 Canny算子边缘检测
获取图片的边缘信息是图像处理当中的基本任务之一。主要应用于一些数据信息的处理,从中提取想要的目标,剔除一些干扰及不相关的信息,通过精简的数据去获得更准确的信息。Canny于1986年开发的一个多级边缘检测算法,被许多人们认为时边缘检测的最优算法,不容易受噪声干扰是它的一大优点,能够真正的检测到软边缘。
Canny边缘检测算法包含以下四个步骤。
4.1 高斯滤波
滤波的主要作用是降噪,防止噪声引起的错误检测。将使用高斯滤波与图像进行卷积,平滑图像,减少边缘检测器上噪声的影响。
4.2 计算梯度的幅值以及梯度的方向
图像中的边缘将指向各个方向,因此用Canny算法中的四个算子去检测图像中的水平,垂直,和对脚边缘。它的集合包含的都是灰度值变化较大的像素点,白边和黑边的中间就是它的边缘。检测的算子将会返回Gx和Gy的一阶导数值,这样就可以知道像素点的G和theta。
4.3 非极大值抑制
非极大值抑制是一种边缘稀疏的技术,它的处理方法就是找到局部中的最大值像素点,再把非极大值所对应的灰度值设为0再将非极大值点对应的灰度值设置为0,就可以将非边缘的点剔除掉一大部分。完成操作后将会得到一个二值图像,结果会包含大量的噪声和一些外界因素所造成的假边缘。所以我们还要对图像做进一步的处理。
4.4 双阈值检测
对图像处理之后,余下的像素将更准确的表示出图像中的实际边缘,但还是会存在因为颜色及噪声所引起变化的一些边缘像素。双阈值的处理方法是设置一个maxval,以及minval。例如一个像素点的位置的超过了它的高阈值,这个像素点就会保留为边缘像素;但如果某一个像素点小于低阈值,这个像素点就会被排除;但如果某一个的像素点位置的幅度在两个阈值的中,像素只连接到一个高于高阈值的像素时会被保留。
本文在python语言的基础上对字符识别算法进行了初步的研究,在基于Tesseract-OCR开源引擎和OpenCV库对文档进行扫描与识别。但仍然存在很多不足的地方,还有待之后的进一步该进。
项目只能对在普通环境下的文档进行扫描,对清晰的图像进行识别且只能是英文字符,对其它语种的字符还有待考究。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
信息安全研究(2016年4期)2016-12-01
光学精密工程(2016年1期)2016-11-07
