
基于二阶统计量的小样本学习算法研究
2021-11-17 11:14麻永田齐晶张秋实罗大为方建军
北京联合大学学报 2021年4期
麻永田 齐晶 张秋实 罗大为 方建军

[摘 要] 为了提高小样本学习的准确率和抗干扰能力,提出了一种基于二阶统计量的小样本学习模型,以CNN最后一层卷积输出的一阶特征向量为输入,通过计算协方差矩阵和二阶池化获得具有较高区分度的二阶统计量,采用奇异值(SVD)分解将二阶特征映射到低维仿射子空间并据此分类。本算法在Omniglot和minilmageNet数据集上进行了测试,实验结果表明,在minilmageNet上的5-way 5-shot模型准确率达到了73.6%,比Prototypical Networks高出5.4%,在Omniglot上的20-way 1-shot模型准确率则获得了2.4%的提升,本算法性能优于Prototypical Networks等算法。在异常值测试中,本算法也展现出比Matching Networks和Prototypical Networks算法更强的鲁棒性。
[关键词] 小样本学习;协方差矩阵;二阶统计量;低维仿射;SVD分解
[中图分类号] TP 391.1 [文献标志码] A [文章编号] 1005-0310(2021)04-0073-06
Research on Few-shot Learning Algorithm Based on
Second-order Statistics
MA Yongtian1, QI Jing2, ZHANG Qiushi 1, LUO Dawei 1, FANG Jianjun
(1.College of Urban Rail Transit and Logistics, Beijing Union University, Beijing 100101, China;2.Tourism College,
Beijing Union University, Beijing 100101, China)
Abstract: To improve the accuracy and anti-interference ability of few-shot learning, this paper proposes a few-shot learning model based on second-order statistics. In the model, CNN is used to extract features and its output of the last convolutional layer is obtained to compute high-resolution second-order features by means of covariance matrix and second-order pooling operation. Meanwhile, the obtained second-order features are mapped to low-dimensional affine subspace by operating singular value decomposition (SVD) for classification. The proposed model is tested on Omniglot and minilmageNet datasets. The results reveal that the performance of the proposed model is better than other models including Prototypical Networks. The accuracy of the 5-way 5-shot model on minilmageNet dataset reaches up to 73.6%, which is 5.4% higher than Prototypical Networks. The 20-way 1-shot model on Omniglot dataset gets 2.4% accuracy improvement. As for outlier test, the proposed model also shows stronger robustness than those of Matching Networks and Prototypical Networks.
Keywords: Few-shot learning;Covariance matrix;Second-order statistics;Low-dimensional affine;Singular value decomposition
0 引言
機器学习是一种需要大量数据驱动的科学方法,其相关研究已取得了很大成功。但是,对于小数据集或者弱标注的应用场景,例如缺陷检测、故障检测等,深度学习就显得捉襟见肘。近年来,小样本学习作为一种新的机器学习方法被提出来,成为机器学习研究领域的热点问题之一[1]。
与一阶统计量相比,二阶统计量能够获得更加丰富的特征表达。文献[2]证明了在大规模目标识别中,使用二阶统计量所表现出的性能要优于使用一阶统计量。文献[3]在动作识别中使用高阶特征量获得更丰富的动作特征及其高阶相关性,更好地区分动作属性,一阶特征则作为噪声而被忽略。文献[4]将二阶统计量拓展到注意力机制中,研究表明二阶统计量可以获得层间特征的内在相关性,这使得网络能够专注于更多的信息特征,增强分类学习能力。文献[5]在词袋模型中分别对一阶、二阶和三阶统计量的性能进行评估,证明高阶统计量具有更丰富的特征表达能力。二阶统计量在语义分割[6]、物体检测[7]及动作识别[8]等计算机视觉领域的研究中都表现出显著的效果。
与常见的一维向量特征相比,协方差二阶矩阵拥有行和列两个方向的数据关联性,比只有一个方向的一维向量特征蕴含更丰富的信息。因此,本文提出在小样本学习模型中采用二阶特征矩阵作为分类依据。在小样本学习的相似匹配部分,一些模型直接将各类别的均值作为它们的原型表示[9],这种策略容易受到异常值的干扰。为了降低噪声干扰,本文采用低维仿射子空间的策略对分类器进行建模。
1 基于二阶统计量的小样本学习
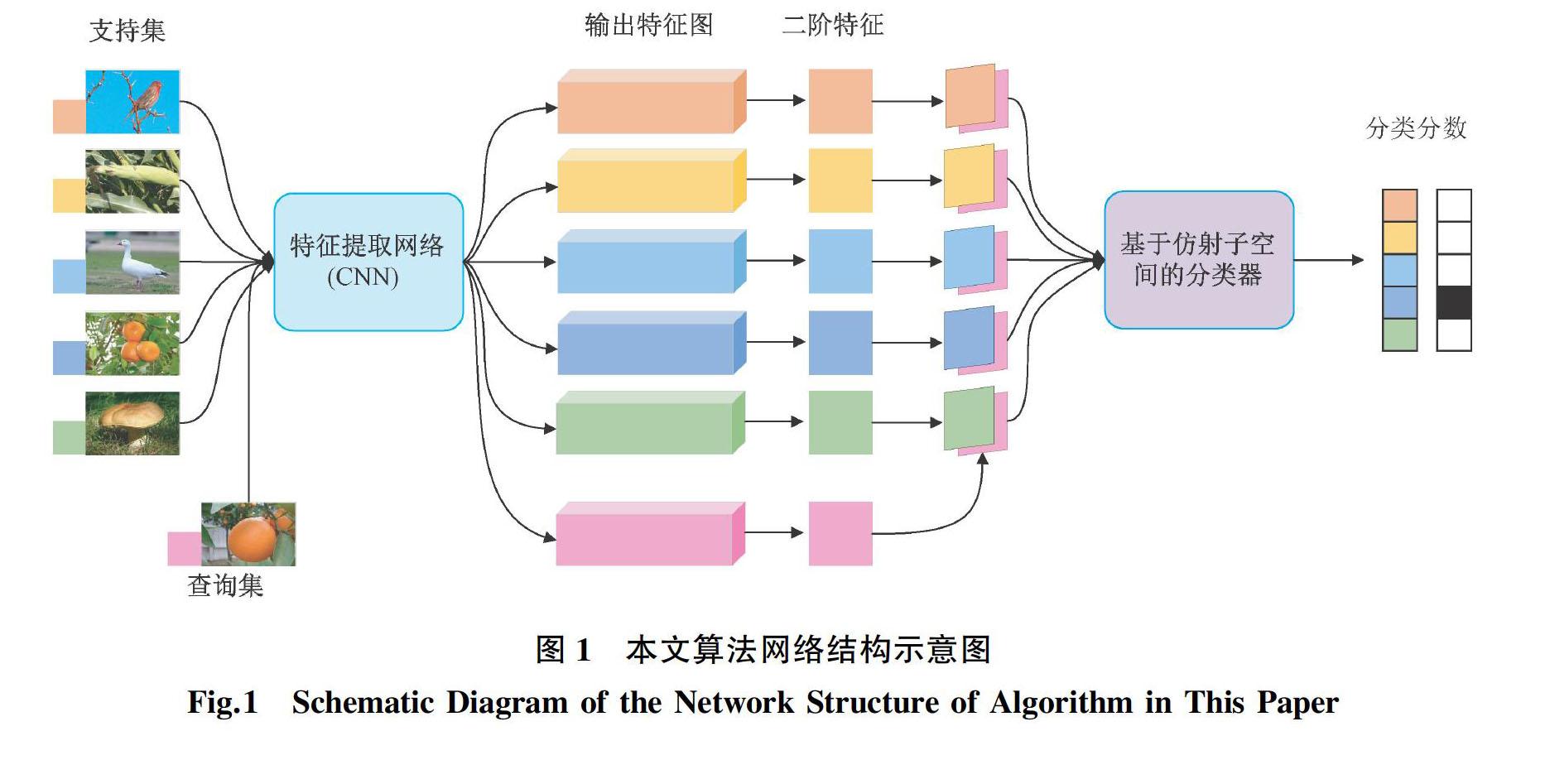
图1是本文设计的网络结构,它由特征提取和相似匹配两部分组成。以卷积神经网络(Convolutional Neural Network, CNN)为主干网络,将其最后一层卷积输出的特征图进行协方差计算,获取二阶矩阵特征。在相似匹配部分,将特征映射到低维子空间进行处理,以增强模型的鲁棒性,学习同类图像之间的关系,实现图像分类。
1.1 特征提取网络
CNN被广泛应用在计算机视觉研究任务中,并不断取得突破。研究表明,基于CNN的特征提取网络能够较好地提取图像特征,并进行端到端的分类。本文采用图2所示的特征提取网络,它是一个4阶段的CNN网络:将输入图像喂入CNN网络,经过4个卷积块(每个卷积块由核数为64的3×3卷积和一个2×2的Max Pooling组成,每次卷积前都进行BatchNorm处理,采用ReLU激活函数)的下采样处理,输出特征图。
1.2 二阶统计量
把CNN的最后一层卷积输出特征展开成一维向量作为输入,通过协方差池获取二阶特征分布,捕获了比一阶更高的特征统计量,这种二阶特征包含层间特征分布及其相关性,具有较强的类别区分能力。基于二阶统计量的特征提取示意图如图3所示。
令xn∈RD表示图像中的数据点,RD表示图像,D表示图像的维度,则图像经CNN最后一层卷积层输出的特征图可表示为式(1)。
其中,f(xn)表示CNN特征提取,即RD→RK,K表示特征图的维度。φn表示特征图上的第n个特征向量。N表示输出特征图上特征向量的数量,且满足式(2)。
1.3 基于低维仿射子空间的分类器
Softmax凭借其优异的性能被广泛应用于机器学习中。本文拟采用Softmax作为小样本学习的分类器,如式(5)所示。
式(5)中,c表示support集的样本类别,q表示query集的样本类别。
由于小样本学习的训练样本数量有限,若用每类样本的特征向量均值作为类原型,使用直接度量计算进行匹配,会对异常点和噪声过于敏感,如图4(a)所示。因此,本文将二阶特征映射到一个低维仿射子空间,然后与原二阶特征做欧氏距离计算来进行匹配,如图4(b)所示。
其中,Wc表示c类样本的线性子空间,主要是通过奇异值分解(Singular Value Decomposition, SVD)[10]将c类样本的二阶特征矩阵进行分解,左奇异矩阵是原特征矩阵的线性子空间正交基,因此本文将其视为原特征矩阵映射的低维子空间,并借此求得fΘ(q)。
1.4 算法流程
令S表示支撑集(support sets),X表示支撑集中的一个图像样本,c1表示类别1,C表示类别数量。M表示查询集(query sets)中每类图像的数量。基于二阶统计量的小样本学习的算法流程如图5所示。
2 实验
为了测試基于二阶统计量的小样本学习算法的准确性和鲁棒性,本文在不同的公开图像数据集上对算法进行了对比实验。
2.1 实验设置
2.1.1 实验环境
本文所有实验均在Ubuntu 16.04系统下进行,选择Pytorch深度学习框架,采用Python 3.5语言编译,CPU型号为英特尔i7-9700,GPU型号为GeForce RTX 2080 Ti。
2.1.2 实验数据集
为验证基于二阶统计量的小样本学习算法的性能,本文选择Omniglot和minilmageNet两个数据集进行实验[11-12]。
Omniglot是一个手写字符识别的数据集,是最常用的小样本数据集之一,该数据集包含5 050个字母,共计16 231 623个手写字符。实验将Omniglot数据集中图像的大小调整到28×28并以90度的倍数旋转来增加字符类,训练episode设置为60个类别,每个类别包括5个query查询样本。
minilmageNet是大型图像数据库lmageNet的简化版,相比于Omniglot,它具有更丰富的图像信息。minilmageNet数据集包含60 000张84×84大小的彩色图像,分为100个类别,每个类别中有600张图像。实验将minilmageNet数据集的100个类别进行了拆分,选择其中的64个类别数据作为训练集,16个类别作为验证集,20个类别作为测试集。
2.1.3 实验样本
小样本学习训练集中包含了很多的类别,每个
类别中有多个样本。在训练阶段,从训练集中随机抽取C种类别,每个类别K个样本(共C×K个)作为支撑集;再从这C种类别剩余的数据中抽取一批(batch)样本作为查询集。
2.2 实验结果分析
2.2.1 模型准确率分析
基于二阶统计量的小样本学习算法与Matching Networks、Prototypical Networks算法在Omniglot数据集上的分类任务的对比实验结果见表1。
从实验结果可看出,基于二阶统计量的网络(Second-order Networks)通过协方差池获取二阶特征分布,捕获了图像更高维的特征理解,通过在低维仿射子空间进行匹配计算的方法,充分利用了图像的高维特征来扩大类间差异的优点,具有较高的准确率。相比于Prototypical Networks算法,本文算法在20-way 1-shot中的准确率达到了98.4%,获得了2.4%的提升;20-way 5-shot的准确率达到了99.7%,提升了0.8%。但是5-way 1-shot的准确率仅提升了0.5%,5-way 5-shot几乎没有得到提升。据分析认为,Omniglot是一个手写字符数据集,图像相对简单,Prototypical Networks等算法已经达到了一个较高的识别率,因此提升不明显。
为了充分证明Second-order Networks在复杂图像上的分类效果,本文还在minilmageNet数据集上进行了对比实验,实验结果如表2所示。基于二阶统计量的算法在5-way 1-shot和5-shot中的准确率分别达到了52.3%和72.1%,相比于Prototypical Networks算法,分别提升了2.9%和3.9%,说明二阶统计量在复杂图像的分类任务中仍然可以有效提升小样本学习的准确率。
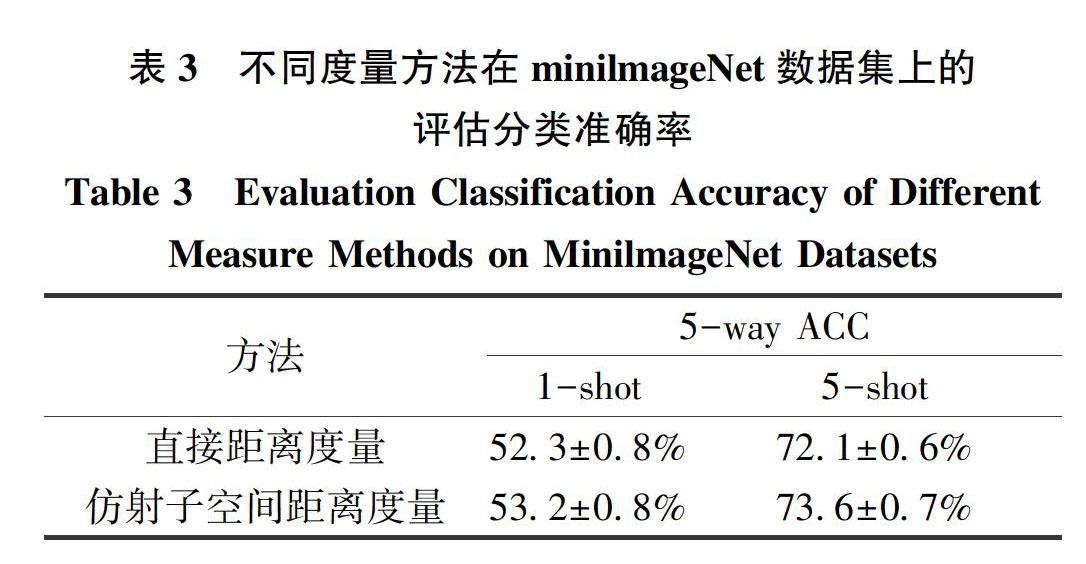
为了证明加入低维仿射子空间进行匹配计算的有效性,本文还在minilmageNet数据集上进行了直接距离度量和通过仿射子空间进行距离度量的对比实验,如表3所示。从实验结果可知,加入仿射子空间后,模型的准确率在1-shot和5-shot中
分别获得0.9%和1.5%的提升。这表明,相比利用欧氏距离计算方法的直接距离度量进行匹配,本文通过SVD将图像特征映射到一个子空间,然后求得图像特征间的相关关系并据此进行图像匹配,能
2.2.2 鲁棒性测试
深度學习方法的有效性依赖于高质量的训练数据集,当训练集呈现显著复杂噪声、异常点入侵及类别不均衡等问题时,其有效性往往无法得以保证。为评估本文算法对于异常值的鲁棒性,本实验从数据集外随机选取几张图像作为异常值插入支
持集中,对异常值图像的选取和处理须遵循以下两条规则:异常值的图像数量不得超过标记类别的样本数量;异常值图像不属于支持集中任何类别,但在训练时将其随机标记为支持集的某一类别。
本文采用5-shot对不同异常值进行测试,并以异常值数量为横轴、模型准确率为纵轴将测试结果可视化,如图6所示。从图6中可看出,随着插入异常值数量的增加,3种算法的准确率均出现了不同程度的下降,这说明3种算法都不可避免会受到异常值的干扰。但从下降幅度可知,本文算法的下降幅度比Matching Networks和Prototypical Networks算法要小,这是由于二阶统计量具有较强的类别区分能力,为分类计算能够提供更多的匹配计算的维度。因此,本文算法对于异常值干扰的鲁棒性方面要强于Matching Networks和Prototypical Networks算法。
3 结束语
本文提出在小样本学习算法中引入二阶统计量,基于此方法,可以在深度神经网络学习的表示空间中充分利用每一类支持集中图像的高阶深度特征表示类别,并通过迭代训练,使其在少量样本的情况下获得更好的分类效果。本文提出的方法在Omniglot和minilmageNet数据集上进行测试,其准确率均比Matching Networks和Prototypical Networks等算法要高,在minilmageNet数据集测试中的5-way 5-shot模型准确率达到了73.6%,比Prototypical Networks高出5.4%,在Omniglot数据集测试中的20-way 1-shot模型准确率则获得了2.4%的提升。实验结果表明,通过低维仿射子空间处理方法进一步提高了模型准确率;同时,基于二阶统计量的小样本学习算法具有更好的分类效果,且应对异常值等噪声的能力更强。
[参考文献]
[1] 汪荣贵,郑岩,杨娟,等.代表特征网络的小样本学习方法[J].中国图象图形学报, 2019, 24(9):1514-1527.
[2] LI P H, XIE J T, WANG Q L, et al. Is second-order information helpful for large-scale visual recognition? [C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice:IEEE, 2017: 2070-2078.
[3] CHERIAN A, KONIUSZ P, GOULD S. Higher-order pooling of CNN features via kernel linearization for action recognition[C]// 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). Santa Rosa:IEEE, 2017: 130-138.
[4] DAI T, CAI J, ZHANG Y B, et al. Second-order attention network for single image super-resolution[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach:IEEE, 2019: 11065-11074.
[5] KONIUSZ P, YAN F, GOSSELIN P, et al. Higher-order occurrence pooling for Bags-of-Words: visual concept detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(2): 313-326.
[6] BAO L C, WU B Y, LIU W, et al. CNN in MRF: video object segmentation via inference in a CNN-based higher-order spatio-temporal MRF[C] //2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Salt Lake City:IEEE, 2018: 5977-5986.
[7] KIM T, JEONG M, KIM S, et al. Diversify and match: a domain adaptive representation learning paradigm for object detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach:IEEE, 2019: 12456-12465.
[8] CHOUTAS V, WEINZAEPFEL P, REVAUD J, et al. PoTion: pose motion representation for action recognition[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Salt Lake City:IEEE, 2018: 7024-7033.
[9] SNELL J, SWERSKY K, ZEMEL R S, et al. Prototypical networks for few-shot learning[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach:NIPS, 2017: 4077-4087.
[10] DADKHAH S, MANAF A A, HORI Y, et al. An effective SVD-based image tampering detection and self-recovery using active watermarking[J]. Signal Processing:Image Communication, 2014, 29(10): 1197-1210.
[11] LAKE B M, SALAKHUTDINOV R, TENENBAUM J B, et al. The Omniglot challenge: a 3-year progress report[J]. Current Opinion in Behavioral Sciences, 2019,29: 97-104.
[12] QIAO S Y, LIU C X, SHEN W, et al. Few-shot image recognition by predicting parameters from activations[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Salt Lake City:IEEE, 2018: 7229-7238.
(責任编辑 白丽媛)
