
基于集成聚类和XGBoost 的短期光伏发电功率预测
2021-11-18 02:51常俊晓金之榆吴思圆
浙江电力 2021年10期
常俊晓,金之榆,卢 姬,吴思圆
(1.国网浙江省电力有限公司台州供电公司,浙江 台州 318000;2.国网浙江省电力有限公司临海市供电公司,浙江 临海 317000)
0 引言
为实现能源转型升级,达成“双碳”目标,大力发展光伏产业已经确定为国家既定国策,光伏发电将迎来黄金机遇期。2020 年,光伏新增装机48.2 GW,弃光量达52.6 亿kWh。准确预测光伏发电功率对充分挖掘源网荷储调节潜力,提升消纳利用率具有重要意义[1]。
光伏发电功率具有较大的波动性和随机性,其预测方法主要分为物理法和统计法。物理法主要通过天气预报、卫星遥感测量和地面测量设备来获得预测所需数据,对设备要求较高;统计法是一种数据驱动的方法,根据历史数据提取特征来预测未来的光伏发电功率,成本低且适应性强,得到广泛应用[2]。当气象类型相同时,光伏发电具有较高的相似性,发电功率大小与各种气象特征有着密切的联系[3-4]。因此,对气象数据进行聚类分析,针对不同气象类型的数据,选用相似日样本数据进行预测可以有效提高预测精度[5-6]。但目前聚类方法存在最佳聚类数难以确定和初始聚类中心随机选择导致聚类结果不稳定的缺点。文献[7]针对K-means 聚类算法(K-均值聚类算法)无法聚类确定最佳聚类数的缺点,提出了自适应K-means 聚类算法,并结合了LSTM(长短时记忆网络)算法,在提高预测精度上取得了较好的效果,但是并没有解决K-means 聚类算法初始聚类中心随机选择的缺点,随着数据集规模的增大容易导致聚类结果不稳定;文献[8]通过减法聚类确定K-means 聚类算法的最佳聚类数,通过分散选取聚类中心的方法避免聚类结果陷入局部最优,但降低了聚类速率。在预测模型方面,传统的GBDT(梯度提升树)算法存在预测结构简单、预测精度低的缺点。XGBoost(极端梯度提升)算法[9]是一种基于决策树的集成学习算法,使用梯度上升框架,在数据分类以及回归处理方面有着显著的效果,广泛应用于天文学、气象、电力等领域中的预测分析。文献[10-11]中使用XGBoost 算法建立了光伏发电功率预测模型,实验证明该算法具有较好的实用性和可行性,但没有充分考虑天气对光伏发电功率预测精度的影响。
基于上述分析,本文提出基于集成聚类和XGBoost 的短期光伏发电功率预测方法。首先,采用Mean-shift(均值漂移算法)、凝聚层次聚类算法确定初始聚类中心,结合DBI(戴维森堡丁指数)确定最佳聚类数,得到自动确定最佳聚类数且聚类结果稳定的集成聚类算法;然后,采用集成聚类算法对数据进行聚类,得到不同气象类型的预测样本集;最后,对各种天气类型的训练集数据分别采用参数少、计算效率高的XGBoost 集成学习算法训练模型,结合训练完成的模型分别对晴天、多云、阴雨天3 种天气类型的测试集数据进行算例分析,验证了所提组合预测算法可以得到更加精确的预测结果。
1 XGBoost 预测算法原理
相比于传统的GBDT 算法,XGBoost 具有更强的扩展性,而且可以同时使用一阶和二阶导数,能更好地获得代价函数的信息量,提高预测结果的精确度;且XGBoost 算法使用类似随机森林的策略对数据进行采样,不需要重复调取数据,这使得计算效率大大提高[12]。
设有n 个样本和m 个特征的数据集D=(xi,yi),其中,yi∈R。提升树模型中构建了K 个树,表示为F={f1(x),f2(x),…,fk(x)},k∈K;目标函数表达式如下:

式中:fk为XGBoost 中的一个CART 回归树函数;表示预测值;yi为真实值。
经过t 次迭代后将XGBoost 拟合残差代入式(1),并对其进行二阶泰勒展开,得到新的目标函数:

为了学习模型中的函数集合,XGBoost 模型最小化正则化目标如下:
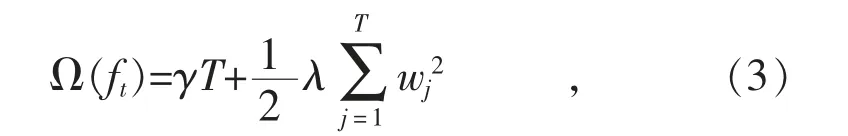
式中:fk(x)=wq(x),q(x)为输入测试集样本决策树叶子结点编号的映射,表征决策树结构;w 为决策树的输出值;设每个树的节点样本集合为IJ={i q(xi)=j};T 为每个回归树的叶子节点数;γ 为叶子节点个数;λ 为正则化项惩罚系数。
将式(3)和式(2)进行组合可得XGBoost 基于加法方式的迭代函数:

假设式(4)中q(xi)的值固定,求导得到目标函数的极值点,代入式(4)可得最终目标函数:
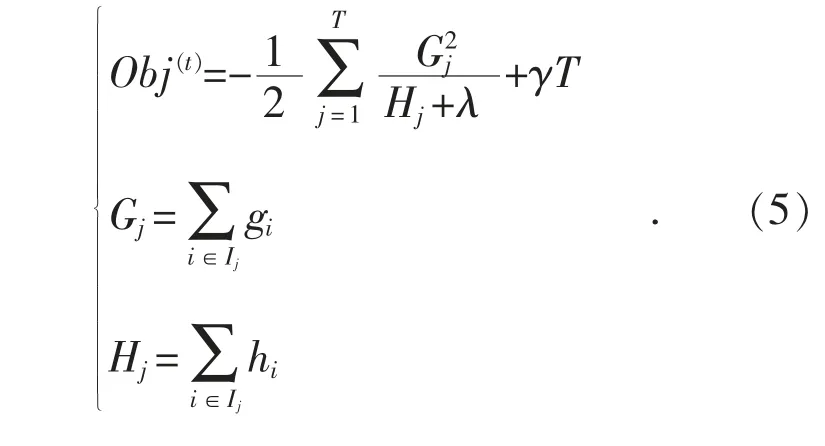
Obj(t)表示选定树结构增益损失的最大值,其数值越小表示模型精度越高,在模型训练过程中XGBoost 算法利用误差函数不断优化模型。
2 集成聚类和XGBoost 的组合预测框架
2.1 数据预处理
不同的气象特征数据具有不同的数量级,对于聚类算法来说,将气象特征数据集中到一个范围内可以提升模型的收敛速度,得到更好的聚类结果。影响光伏发电功率的气象特征有温度、压强、湿度、辐照度和实发辐照度[13],采用最大-最小归一化方法预处理数据,得到式(6):

式中:xmax,xmin分别为样本中特征最大值和最小值;xnew为归一化后的样本x。
将实验数据集表示为H,数据集中的日气象特征表示为:
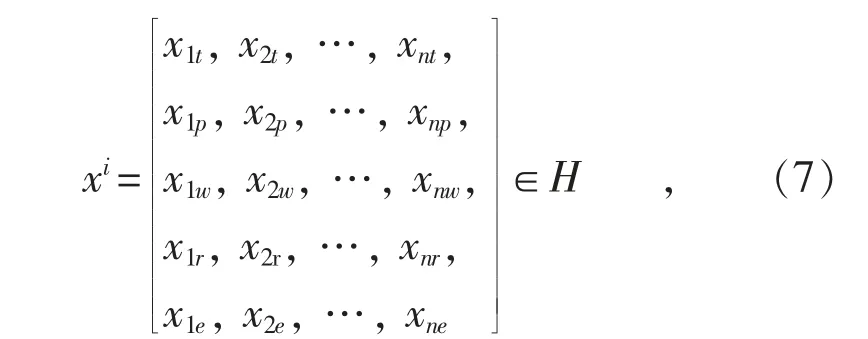
式中:xi表示第i天的气象特性样本;xnt,xnp,xnw,xnr,xne分别表示第n 时刻的温度、压强、湿度、辐照度和实发辐照度。
2.2 集成聚类算法
K-means 聚类算法[14]无法确定最佳聚类数,且初始聚类中心选择具有随机性,导致聚类结果不稳定。为此,本文设计的集成聚类算法,其基本思路是使用Mean-shift 密度聚类确定初始聚类中心,通过凝聚层次聚类和聚类结果评价指标确定最佳聚类数。具体过程:首先在经过数据预处理的数据集上进行Mean-shift 密度聚类,对得到的聚类中心使用凝聚层次聚类算法进行组合;再根据聚类结果评价指标,将相似的聚类中心合并,得到新的聚类中心和聚类数;最后将新的聚类中心和聚类数分别作为K-means 聚类算法的初始聚类中心和最终聚类数对数据集再次进行聚类,得到最终的聚类结果。
2.2.1 Mean-shift 聚类
Mean-shift 算法是Fukunaga 团队提出的一种无参数密度估计算法,又称均值漂移算法。由于这种算法可以应用在任意形状数据集的密度估计中,因而在数据聚类、图像追踪中应用广泛。它通过计算当前样本的均值偏差来不断更新类簇的中心点,直到类簇中心收敛到概率密度极大值处,并且不需要提前设置聚类数。用Mean-shift算法对电力负荷曲线进行初步聚类可以在全局范围内确定聚类中心,避免聚类结果陷入局部最优。
2.2.2 凝聚层次聚类
在集成聚类算法中,凝聚层次聚类可以看作对K-means 聚类算法初始聚类中心的预处理步骤,它对Mean-shift 算法选出的聚类中心进行组合。为了确定最佳聚类数,解决K-means 聚类算法受初始聚类中心影响较大的问题,采用聚类质量高、结果稳定的凝聚层次聚类算法,可以输出较好且稳定的聚类中心组合,从而使得K-means算法聚类结果更优。
集成聚类算法的具体步骤如下:
1)通过Mean-shift 算法对数据集进行聚类处理,得到S 个聚类中心。
2)采用凝聚层次聚类对CA的聚类中心进行合并,合并结束条件为“是否达到事先给定的聚类数目”,需要通过聚类有效性指标来确定最佳的聚类数目kbest,得到合并后的聚类中心。
3)将kbest以及聚类中心作为K-means 聚类算法的输入参数和初始聚类中心对数据集进行聚类,输出聚类结果。
聚类流程如图1 所示。
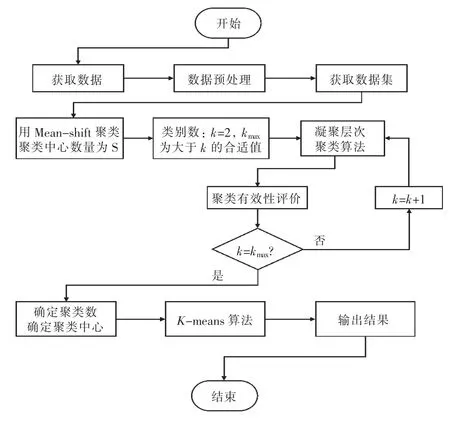
图1 集成聚类流程
2.3 组合算法结构
本文采用集成聚类和XGBoost 组合预测算法对短期光伏发电功率进行预测,具体流程如图2所示。
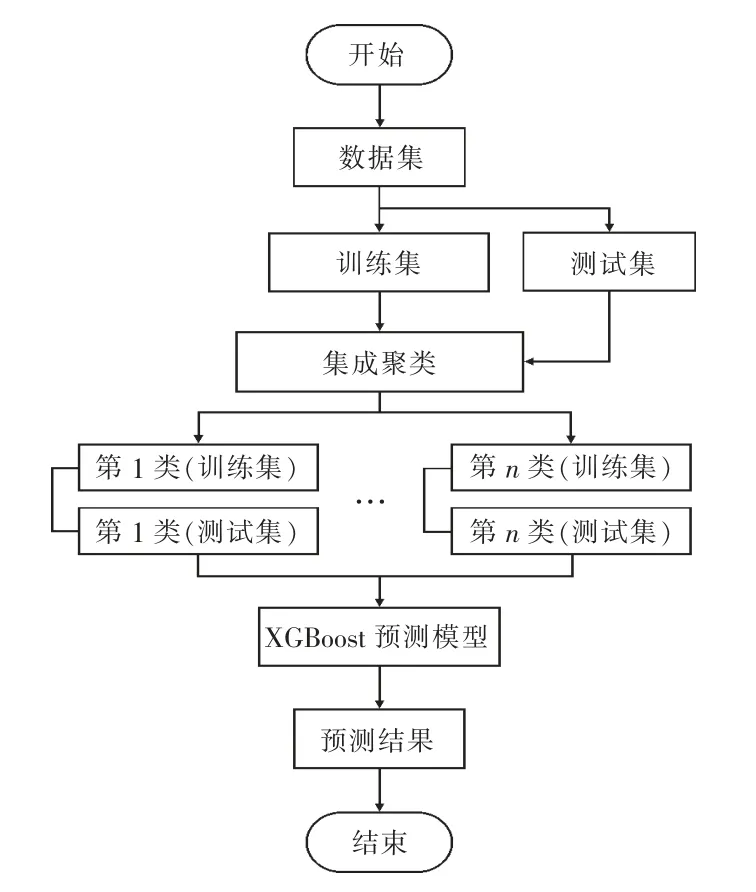
图2 组合预测流程
1)获取功率数据与气象数据样本,选取温度、压强、湿度、辐照度和实发辐照度为气象特征分量。
2)采用集成聚类对训练集气象数据聚类处理,得到不同气象类型的预测样本集。
3)预测模型初始化,并对XGBoost 算法的主要参数寻优,直至训练网格模型最优;然后利用不同气象类型的训练集样本分别训练XGBoost 算法预测模型。
4)通过计算测试集样本与聚类中心的距离来确定预测样本的气象类型,输入对应气象类型的预测模型中得到预测结果。
3 实验结果与分析
本文实验数据来自某市一个三相并网光伏发电系统,数据采集天数为600 天,日气象特征向量为每隔15 min 采集一次的温度、压强、湿度、辐照度和实发辐照度,共600 个样本。考虑到光伏发电的特殊性,将预测时间区间设定为6:00—18:00。
3.1 聚类结果分析
以所有样本的温度、压强、湿度、辐照度和实发辐照度作为输入,分别采用K-means 聚类算法和集成聚类算法进行聚类。考虑到K-means 聚类算法的不稳定性,对数据进行多次(20 次)聚类,取最优值,其中输出类簇的设置范围为[2,10],采用DBI 评价其聚类质量,计算公式如下:
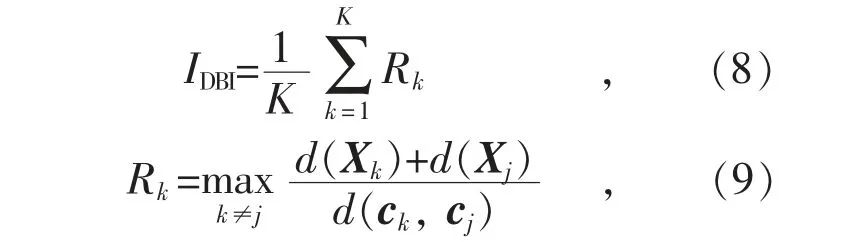
式中:d(Xk)与d(Xj)分别表示类簇k,j 中的每个样本到类簇中心的平均距离;d(ck,cj)表示类簇k,j 的类簇中心之间的距离。IDBI的数值越小,表示聚类结果的质量越好。
当k 取不同值时IDBI如图3 所示,可以看出,当k 取3 时,IDBI最小为1.59,此时聚类效果最佳。使用集成聚类处理相同数据集,聚类结果如表1 所示,经对比可以看出,集成聚类算法可以自动得到最佳聚类数,且IDBI为1.42,比K-means的聚类效果更好。因此,采用集成聚类算法不仅可以自动得到最佳聚类数,同时由于避免了初始聚类中心的随机选择,还能得到更好的聚类效果。
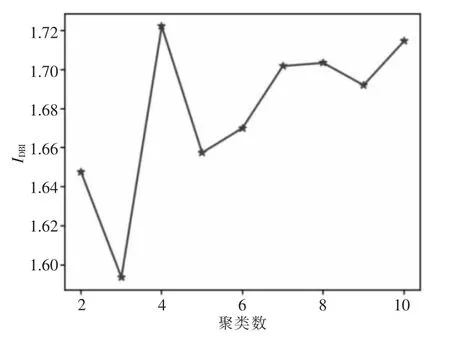
图3 K-means 不同聚类数的IDBI
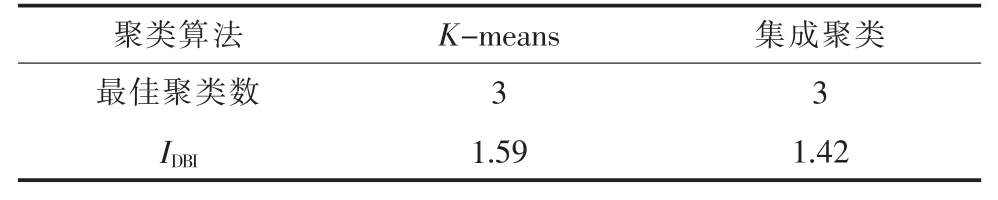
表1 聚类结果
3.2 预测结果分析
选取3 个不同天气典型日,分别采用3 种方法进行预测:方法1,集成聚类与GBDT 相结合;方法2,K-means 与XGBoost 相结合;方法3,集成聚类与XGBoost 相结合。
为了确保参数设置最优,本文使用Gridsearch网格搜索法对2 种算法的主要参数寻优进行。XGBoost 模型参数:learning_rate(学习率)设置为0.1,max_depth(树的深度)设置为4,n_estimators(树的棵树)设置为45,min_child_weight(最小叶子权重)设置为4,其余参数设置为默认值;GBDT 模型参数:n_estimator(最大迭代次数)设置为52,learning_rate(学习率)设置为0.3,loss(损失函数)设置为“huber”,其余参数设置为默认值。
为了评价不同方案的预测效果,本文采用MAPE(平均绝对误差)和RMSE(均方根误差)分别评价预测结果,2 种评价指标的数值越小,表示预测结果越接近真实值。
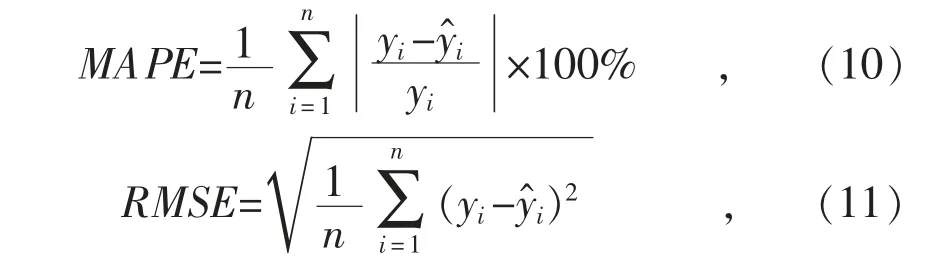
式中:n 为预测值数量;yi和分别为负荷真实值和预测值。
3 种方法的预测结果如表2 所示。

表2 3 种方法预测结果
1)晴天预测结果。
由图4 中光伏功率曲线可以看出:晴天光伏发电功率比较稳定,使用3 种方法都可以得到较好的预测结果,同时结合表2 中的MAPE 值可知,集成聚类与XGBoost 组合算法的预测结果误差最小。

图4 晴天预测结果
2)多云天预测结果。
由图5 中预测曲线可以看出:多云天气的光伏发电功率波动较大,方法1 的预测结果与实际波动曲线相差较大,在13:00—15:00 的预测值偏差非常明显;但方法2 和方法3 的预测结果相对准确,更加接近真实值,结合表2 中的MAPE 值可以看出,方法3 的预测结果最准确。
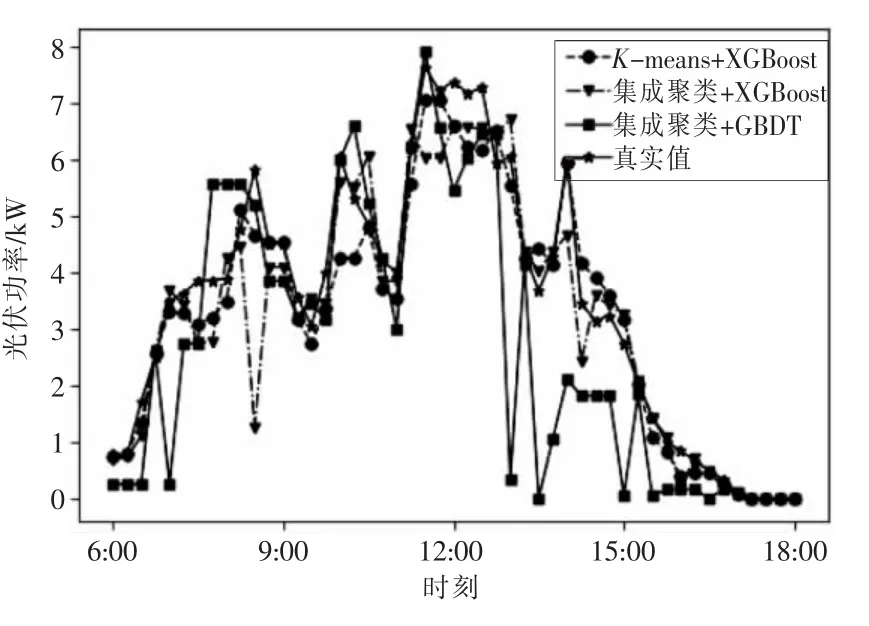
图5 多云天预测结果
3)阴雨天预测结果。
由图6 中预测曲线可以看出:3 种类型天气中,阴雨天的光伏发电功率最小,且波动最为明显,这导致方法1 的预测结果与真实曲线差距较大,特别是12:00—16:00 的预测值偏离真实值最多,与真实曲线不符;方法2 预测功率值与真实曲线相差较小;方法3 的波动情况比方法2 更加接近真实曲线,结合表2 的MAPE 值可以看出,本文提出的集成聚类与XGBoost 组合的算法更加适应功率的波动,预测结果更准确。
图6 阴雨天预测结果
对比不同天气状况下的预测结果发现,GBDT算法虽然在晴天的预测结果较好,但是无法应对较为波动的天气情况,当天气情况发生波动时,预测结果误差会迅速加大,无法像XGBoost 算法一样适应天气波动。经过集成的K-means 聚类算法比原始K-means 聚类算法的聚类结果更稳定,聚类质量更高,并且可以自动得到最佳聚类数,还能通过提供更准确的聚类样本提高XGBoost 算法的预测精度。
4 结论
通过实例分析可以证明,本文所提的预测方法具有以下优势:
1)结合了Mean-shift 算法、凝聚层次算法和K-means 聚类算法的集成聚类算法解决了Kmeans 聚类算法无法确定最佳聚类数和随机选定初始聚类中心的问题,使得聚类结果更加稳定,且准确实现了对气象特征的聚类。
2)采用XGBoost 集成机器学习算法,在减少参数设定的同时,相比于GBDT 算法可以得到更加准确的预测结果;对于短期光伏发电功率预测,XGBoost 算法可以更好地适应不同天气情况带来的影响。
本文所建立的预测模型在不同天气情况下均获得了较好的预测结果,实用性较强,在短期光伏发电功率预测研究方面具有一定的参考价值。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
内蒙古气象(2021年2期)2021-07-01
铁道通信信号(2019年6期)2019-10-08
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
雷达学报(2017年6期)2017-03-26
风能(2016年8期)2016-12-12
互联网天地(2016年1期)2016-05-04
电源技术(2015年7期)2015-08-22
电测与仪表(2015年22期)2015-04-09
