
基于锁闭功率的地铁折返道岔锁闭卡阻临界态自适应判别研究
2021-11-19 07:30毛珺芸
城市轨道交通研究 2021年10期
文 豪 毛珺芸 徐 阳
(1.武汉铁路职业技术学院铁道通信与信号学院,430205,武汉;2.武汉地铁运营有限公司,430019,武汉;3.武汉铁路职业技术学院质量与教育教学督导管理处,430205,武汉∥第一作者,工程师)
道岔及其转换装置是最基础的轨道交通行车设备,一旦出现故障,轻则影响列车运营,重则导致安全事故,因此,保障道岔动作的可靠性至关重要。道岔锁闭是通过尖轨、锁闭装置、转辙机等3处构件的动作共同完成的,且该阶段时常出现卡阻问题。地铁折返道岔动作频繁、磨耗加剧,更易短期内诱发锁闭卡阻故障。因此,及时有效地捕捉故障临界点,提前进行预警处置有着重要意义[1]。
由于道岔锁闭阶段各部位动作复杂,非故障时难以直观发现异常,且尚无可以用来正面综合分析设备工况演变趋势的物理模型。因此,目前针对卡阻故障的预判,以人工分析锁闭功率曲线等可侧面反映道岔及转辙机整体动作状态的监测数据为主,存在主观性强、不确定因素大等问题。此外,人工分析通常利用转辙机额定功率(如S700K交流电机转辙机额定功率为400 W)作为统一阈值判断所有道岔当前动作是否异常,但实践效果并不稳定。文献[2-4]可实现机器代替人工进行道岔故障诊断,但针对故障智能预警方法的研究仍较为匮乏,且在当前普遍不具备深度智能监测的条件下难以直接应用。
针对上述问题,本文以S700K转辙机及其动作功率为对象,基于统计视角建立道岔锁闭卡阻临界态自适应判别机制和实现模型,进而设计故障预判应用场景,目的在于同时满足各场景一般应用需求和将来道岔设备运维的深度智能化监测发展需要。
1 地铁折返道岔锁闭卡阻故障前锁闭功率变化行为分析
1.1 实际道岔锁闭卡阻故障前锁闭功率统计分析
以武汉地铁S700K双机牵引道岔为分析对象,将近期4号线、6号线、8号线、阳逻线某5个折返站的6组不同道岔转辙机发生的共8起锁闭卡阻故障(故障编号为1—8)作为案例。其中,故障7、故障8分别为故障2、故障5的二次发生。
从监测提供的故障前连续100次道岔锁闭功率曲线上,采集锁闭阶段的最大瞬时锁闭功率(以下简为“锁闭功率”),并将其作为分析集合。将每个案例所采集的故障前的锁闭功率值按产生先后次序连接成趋势图,并绘制在同一个坐标系中,如图1所示。

图1 各案例下地铁道岔锁闭卡组故障前锁闭功率变化曲线Fig.1 Metro switch power change curve before locker card group fault in each case
由图1可知,各故障前100次的前半程锁闭功率值基本处于较平稳状态,约后半程开始有相对明显的上升趋势且数值整体增大。进一步将分析样本集分为G1(前半程50个数据)和G2(后半程50个数据)2组,计算两组的平均值p,并进行Mann-Kendall趋势检验(以下简为“M-K趋势检验”)来客观评价锁闭功率变化趋势。M-K趋势检验过程如下:
设有n个样本量{X1,…,Xn}的时间序列,对参数k和j有:k≤n,j≤n,k≠j。按式(1)计算检验统计量S:
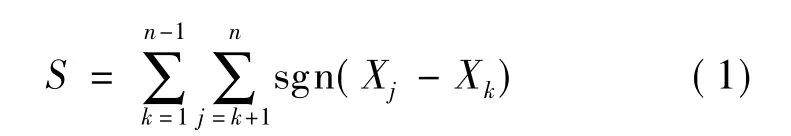
当n≥10时,认为S大致服从正态分布。其中,正态分布的均值为0,方差V计算如下:
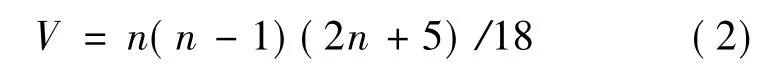
将计算所得的标准正态统计变量Z作为锁闭功率变化趋势检验值:
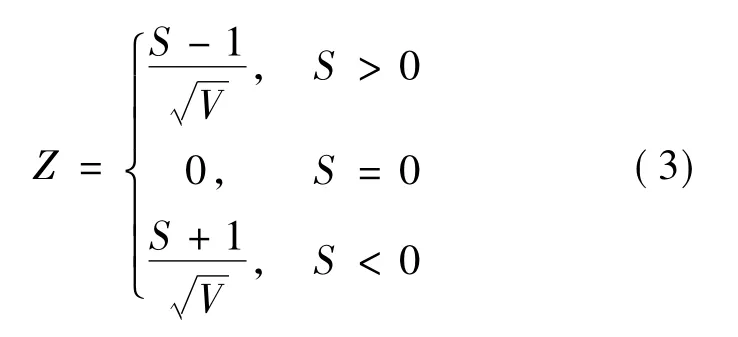
当Z>0时,表示锁闭功率处于上升趋势,反之处于下降趋势。分别表示通过置信度90%、95%、99%的显著性检验。
表1给出了各案例故障前锁闭功率变化指标分组的计算结果。由表1可知:所有故障前G2组的锁闭功率平均值均大于G1组,说明临近故障前的锁闭功率整体有提升;G2组锁闭功率的M-K趋势检验值均大于0(多数超过了99%的置信度区间),且都大于G1组,说明临近故障前的锁闭功率普遍较更早前有相对明显的上升趋势,符合图1的直观分析结果。

表1 地铁折返道岔锁闭功率变化指标分组计算结果Tab.1 Calculation results of change index grouping of metro turnback switch power
1.2 分析结论
1)锁闭卡阻故障前的锁闭功率普遍呈明显的上升趋势,分析锁闭功率值可以用来进行锁闭卡阻临界状态判别,从而进一步实现故障预判。
2)图1除展示出锁闭卡阻故障前锁闭功率值有上升趋势外,还提供了1项重要信息:不同道岔故障前锁闭功率变化范围存在差异,这和道岔所处环境、电机状况,以及锁闭功率采集的情况相关。由此说明,将S700K转辙机的出厂额定功率作为阈值来进行所有道岔锁闭卡阻临界状态的判别并不合理。事实上,每个道岔的每个动作方向都应根据自身情况来设置锁闭卡阻临界功率阈值(以下简为“临界阈值”),这样方可自适应地进行临界态判别。
2 临界阈值自适应分割模型的建立
2.1 基于循环Otsu的临界阈值自适应分割模型
现有求取故障分类或预警阈值的方法主要基于对丰富样本进行关联度分析或分类学习而展开[5]。而实际上道岔动作故障次数要远小于正常动作次数,因此存在正负数据样本比例失衡的问题。对此,文献[6]提出使用单分类机器学习对大量非故障数据进行训练获取预警阈值,但核函数和惩罚因子等关键参数需要人为主观确定。由于临界阈值分布于“端值区”,人为设置参数引起的不确定性会被放大从而影响判断结果。
本文借鉴阈值分割和异常值检验等相关知识,从样本数据间的关系入手,基于经典Otsu方法[7]设计了1种自适应的循环分割模型来获得临界阈值。
2.1.1 Otsu算法内容
将Otsu算法推广到一般数据处理中。给定有限实数组,在其取值范围内定义阈值T,将其分为大于T的前景数组和小于T的背景数组。设前景数组的元素个数占比为ω0,平均值为μ0;背景数组的元素个数占比为ω1,平均值为μ1;总体平均值为μ。由此得到如下关系式:

前景数组和背景数组类间方差g按下式计算:

将式(4)和(5)代入式(6),化简得到:
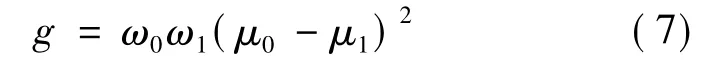
在定义域内遍历T的取值使g达到最大,此时对应的T值即为Otsu阈值。其意义是以数组自身最大类间方差为客观标准,将其分割为相对差别最大的前景数组和背景数组。
2.1.2 循环Otsu分割确定临界阈值
循环Otsu分割确定临界阈值的具体过程,共包括3个环节:
1)采集非故障锁闭功率样本集{P1}。同时采集故障前后期、状态稳定期和状态波动期的数据组成样本集。并利用等间隔采集方式扩大覆盖时期,样本容量n不少于5 000例。
2)循环Otsu分割机制。首先将{P1}进行Otsu分割,把数值更大的前景数组作为相对异常数组留下。由于第1次分割是粗糙的,接下来继续把留下的数组进行Otsu分割,如此循环。前景数组范围随分割次数增大而逐步减小,达到一定条件后停止分割,此时的分割阈值即为临界阈值。
3)客观控制条件设置。主要设置两类条件:
第1类条件:确定T的取值范围。设待分割样本集最大值和最小值分别为Pmax和Pmin,则有:

式中:
此外,规定T按步长0.5增长。若一次分割后存在多个T值使得g达到统一最大值,则取Tmax作为分割阈值。
第2类条件:循环分割终止判定。当T增长到超过样本异常值常规检验标准时终止分割,即:

式中:
p、σ——分别表示样本的平均值和标准差。
若T未满足式(9)的条件,但却增长到其取值范围内的最大值时,则提前终止分割。
2.2 模型有效性验证
根据2.1节中的方法得到故障案例1—8对应的临界阈值,并将其作为参考线,绘制各故障前连续100次锁闭功率变化趋势图,并与各样本集中随机抽取的100个锁闭功率进行对比,如图2所示。
由图2可知,所得临界阈值可有效分割出各故障前相对明显的异常锁闭功率值,能起到提前预判作用,且对于绝大多数相对正常值具有鲁棒性。

图2 不同故障案例下循环Otsu阈值分割有效性验证Fig.2 Validation of cyclic Otsu threshold segmentation effectiveness in different fault cases
3 地铁折返道岔锁闭卡阻临界态判别的应用
3.1 应用场景方案设计
该场景方案应用于地铁折返主用道岔运营中的实时锁闭卡阻故障预判。出现告警时提前更换备用道岔折返,避免故障发生。
3.1.1 场景模式
1)事先准备。采集各道岔非故障锁闭功率样本训练得到临界阈值Tl,将其与样本最大值Th组成临界阈值范围[Tl,Th]。
2)现场应用。以天为1个应用周期,以当前时刻为基准,采集道岔最近连续10次同方向扳动产生的锁闭功率,并按次序组成分析簇。基于临界阈值范围和决策参数进行逻辑分析,判断其是否可能萌发故障。每动作1次,可更新1次分析簇。
3.1.2 应用场景流程及管控参数
应用场景流程见图3。其管控参数有:分析簇所有元素落入[Tl,Th]内的统计量S1,分析簇所有元素大于Th的统计量S2,控制门限t(规定t取大于1的整数)。
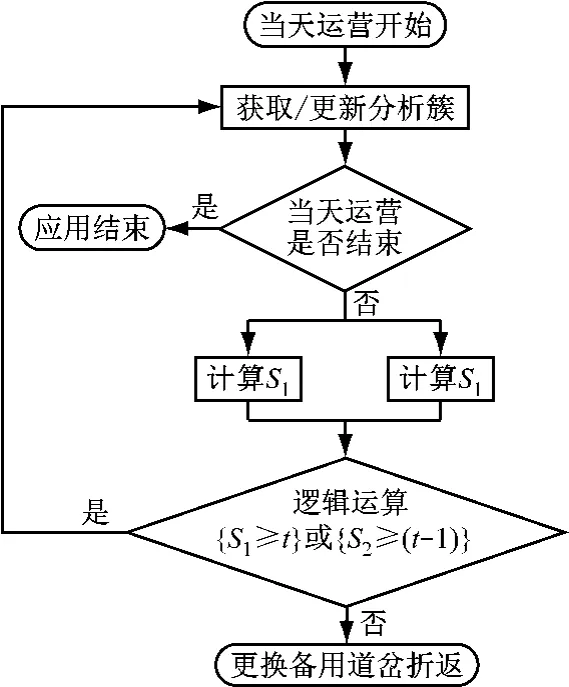
图3 应用场景流程图Fig.3 Application scenario flow chart
3.2 方案测试验证
1)故障当日预判试验。在前述8个故障案例试验中,采集故障当日运营开始道岔第1次动作至故障前最后1次动作产生的锁闭功率,并将其作为样本。按照图3的应用流程,模拟试验阈值t分别取2、3、4、5时的故障预判提前步数Q。Q的定义如下:从当日第1次道岔动作算起,实际故障发生时已动作次数与预判故障发生时动作次数之差。若故障前仍未发出告警,则Q为0。试验结果见图4。由图4可知,t取2、3时,Q均大于0,表明在各故障前可成功预判;t为其他取值时,均存在漏判。

图4 故障当日预判试验Fig.4 Predictive tests on the failure day
2)非故障日误判试验。若在非故障日给出故障预判告警,则视为误判。因此,定义当日误判次数与试验方向道岔扳动次数的比值为误判率。按照故障当日预判试验的模式,分别计算t取2、3、4、5时各故障日第1~2 d(记为D1)、第3~7 d(记为D2)、第8~12 d(记为D3)等3个最邻近故障期但均属非故障日的平均误判率,试验结果见图5。由图5可知,D2时期t取3、4、5,以及D3时期t取5时的4组误判率曲线紧贴横轴,表明这4组误判率均为0。

图5 非故障日误判试验Fig.5 Misjudgment tests on the non-failure day
3)试验结果综合分析。t越小预判成功可能性越大,但误判率也加速上升,这符合统计类方法的相悖规律。在实际应用中,通常允许偶尔出现误判,但要尽量杜绝漏判。因此,在本文试验条件下,t取3时方案最有效,能在各故障案例当日成功预判且误判率低,可满足实际运用需求。
4 结语
本文针对目前利用锁闭功率曲线和转辙机额定功率值进行道岔锁闭卡阻故障预警固有模式的不足,提出循环Otsu临界阈值分割方法,建立“样本统计+计算模型+应用场景”的自适应判别新机制。实证测试效果较好,且满足地铁智能化运维的发展需要。
猜你喜欢
电脑报(2022年13期)2022-04-12
进出口经理人(2021年8期)2021-02-12
出版人(2020年5期)2020-11-17
铁道通信信号(2020年3期)2020-09-21
铁道通信信号(2020年1期)2020-09-21
电脑报(2020年24期)2020-07-15
今日农业(2019年14期)2019-01-04
铁道通信信号(2018年10期)2018-12-06
林业调查规划(2017年6期)2017-03-27
铁道通信信号(2016年6期)2016-06-01
