
多视图主动学习的多样性样本选择方法研究
2021-11-27 00:48陈立伟房赫朱海峰
智能系统学报 2021年6期
陈立伟,房赫,朱海峰
(哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001)
随着遥感技术的迅速发展,高光谱图像(hyperspectral image,HSI)在土地覆盖物分类中得到了广泛的应用[1-3]。训练一个HSI 分类器,通常需要大量的标记样本,而标记样本的采集过程既昂贵又费时[4-5]。主动学习(active learning,AL)方法可以有效解决HSI 标记样本少的问题[6-7]。在AL方法中,多视图主动学习(multiview active learning,MVAL)方法可以从多个视图中提取互补信息,大大减少训练样本的数量[8-10]。
学者们对MVAL 的样本选择方法展开了广泛研究:文献[11]提出了自适应最大不一致(adaptive maximum disagreement,AMD)的样本选择方法,该方法利用各分类器对样本预测结果的不一致性选择样本;文献[12] 提出了加权投票熵(weighted voting entropy,WVE)的样本选择方法,由于不同视图对于不同类别的区分能力不同,该方法通过各视图的权重体现了不同视图对样本的辨别能力的差异;文献[13]提出了一种IEUE 样本选择方法,该方法综合考虑了视图内和视图间的不确定性。这些方法均取得了良好的分类结果,但是这些方法只考虑了样本的不确定性,没有考虑样本的多样性,导致所选样本中存在冗余。并且,随着迭代次数的增加,不同视图训练的分类器会趋同,具有相同的分歧程度的样本越来越多,样本冗余问题会进一步加剧[11-14]。
目前,学者们对MVAL 中所选样本的多样性研究较少。文献[15]提出了一种用于MVAL 的基于聚类的多样性样本选择方法,该方法采用局部聚类密度度量方法对HSI 样本进行聚类,采用光谱角距离作为聚类的距离准则。然而,该方法在聚类过程中只使用了光谱信息,没有考虑样本的空间信息,由此选出的相似样本会产生同谱异物的问题[16-17]。
本文提出了一种基于超像素分割[18]的MVAL多样性样本选择方法。HSI 的超像素分割方法同时基于样本的光谱特性和空间特性,可以有效地避免样本选择过程中的同谱异物问题。
在MVAL 中,多个视图训练的多个分类器,彼此独立并互相补充,共同对样本选择过程和得到最终分类结果起作用[19]。分类器对不同样本的预测结果的一致性直接与样本间的相似性有关,因此本文又提出了一种基于多视图预测标签一致性的样本选择方法。
1 算法框架
1.1 MVAL 的基本流程
基于MVAL 的HSI 分类的基本流程是:首先将HSI 的全部已标记样本分为训练集和候选集,然后对HSI 采用某种视图生成方法得到多个视图。每个视图分别训练一个分类器,并使用每个分类器对全部样本进行预测,得到其预测的结果和精度。根据预测结果,使用MVAL 样本选择策略从候选集中选出信息量大的样本。依次迭代,直到满足停止条件。根据各个分类器的预测结果得到最终的分类结果和分类精度[20-21]。停止条件一般为达到了最大迭代次数或分类精度达到某个值。基于MVAL 的HSI 分类的基本流程图如图1 所示。

图1 基于MVAL 的HSI 分类的基本流程Fig.1 Basic flow chart of HSI classification based on MVAL
1.2 视图生成方法
本文使用了3D-Gabor 滤波视图生成方法,通过使用不同频率和方向的3D-Gabor 滤波器将原始HSI转换成多个具有不同频谱空间特征的数据集[22]。利用这些数据集提供的频谱空间信息,将HSI 的光谱和空间信息结合起来。3D-Gabor 内核为

式中:ω为波向量的中心频率;φ为波向量和光谱维度的夹角;ωx、ωy、ωλ分别是样本的特征向量在高光谱图像的横纵坐标轴x、y和光谱方向 λ上的投影;θ是样本的特征向量在地面x、y上的投影与x轴的夹角;g(x,y,λ)是在(x,y,λ)域的三维高斯包络线。频率和方向的参数设置为:。当φ=0时,波向量与不同的 θ矢量方向相同,共13 个方向。HSI 经3DGabor 滤波后,得到65个不同频率和方向的Gabor 立方体,得到的Gabor立方体与原始HSI 大小相同。
然后,采用文献[13]中提出的FR 准则衡量视图的充分性。从得到的全部视图中选出充分性最大的5 个视图作为MVAL 的多视图。FR 准则为
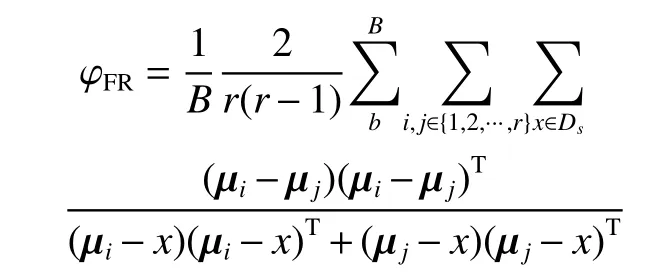
式中:Ds为初始标记训练样本;r为地物类别数量;(µi−µj)(µi−µj)T为第i、j类的均值类间散射矩阵;(µi−x)(µi−x)T+(µj−x)(µj−x)T为第i、j类的方差类内分散矩阵。
1.3 传统的AMD 查询策略
传统样本选择方法通过比较各分类器对样本的不同预测结果个数,衡量样本的不确定性,并从候选集中选出不同预测结果个数最多的样本进行查询。该方法称为自适应最大不一致策略(adaptive maximum disagreement,AMD)。具体表达式为

式中:Lk(xi)为第k个分类器对样本xi的分类结果,共有K个分类器;DC为候选集;|·|count为其中不同元素的个数。
2 MVAL 样本选择方法的多样性选择策略
针对MVAL 样本选择过程中存在冗余样本的问题,本文提出了基于超像素分割和基于预测标签一致性的两种MVAL 多样性样本选择策略。在MVAL 的传统AMD 样本选择方法后,使用提出的多样性方法对所选样本进行进一步筛选,减少训练样本个数,从而降低人工标记成本。
2.1 基于超像素分割的多样性选择策略
传统的超像素分割方法有Meanshift、简单线性迭代聚类(simple linear iterative clustering,SLIC)、归一化分割(normalized cut)、基于熵率(entropy rate)等。其中,SLIC 算法能够根据HSI 的同质性和非均匀性特点进行超像素分割,使不同超像素的空间相干性大大降低。同时只需设置一个预分割超像素数量参数即可在运行速度、紧凑整齐度等方面有一定优势[23]。因此,本文采用SLIC 超像素算法[24]用于HSI 的MVAL 多样性样本选择过程。
利用SLIC 超像素方法对MVAL 样本选择过程进行多样性改进的步骤为:首先对整个HSI 进行SLIC 超像素分割,分割后的HSI 数据如图2。设共得到k个超像素,每个样本xi均对应一个超像素标签Li,同一超像素的样本的超像素标签相同。然后使用一种样本选择方法(如AMD 策略)选出不确定性最大的m个样本,记为XAMD=[x1x2···xm]。再从这m个样本找出属于相同超像素的样本。接下来对其中属于同一个超像素的样本,随机选出其中一个作为代表,剩下的样本放回候选集中。令选出的样本必须来自不同的超像素,从而实现样本选择过程的多样性改进。
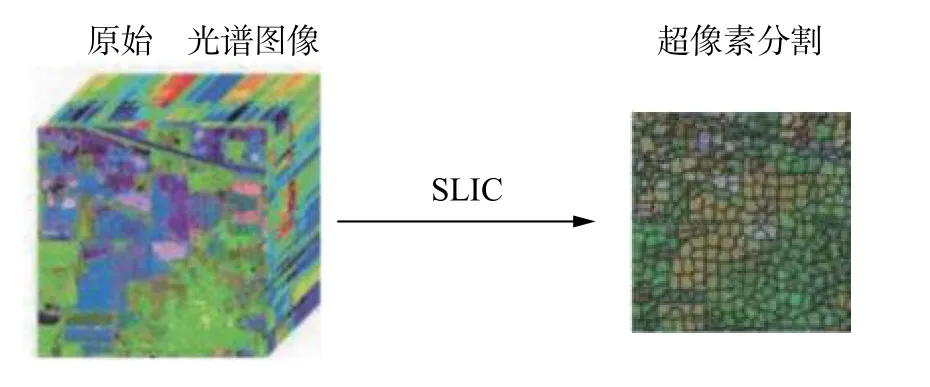
图2 高光谱图像的SLIC 超像素分割图Fig.2 SLIC superpixel segmentation schematic of hyperspectral images
得到超像素标签的表达式为

提出的基于超像素的多样性样本选择方法的定义公式为

式中XSLIC为XAMD经过提出的基于超像素的多样性样本选择方法后得到的最终所选样本。unique函数的具体过程如图3。

图3 unique 函数的流程Fig.3 Flow of unique function
此方法先对原始HSI 进行超像素分割,该过程同时考虑了样本的空间相邻性和光谱相似性。将HIS 中光谱相似且空间相邻的样本判别为相似样本,放入一个超像素区域中。通过超像素分割方法得到相似样本可以有效地避免同谱异物问题,从而更好地进行多样性样本选择。
2.2 基于预测标签一致性的多样性选择策略
在HSI 分类的MVAL 方法中,每个分类器均对样本进行预测。对于两个特别相似的样本,各分类器对它们的分类结果大概率相同。基于MVAL方法特有的多视图特点,以及每个视图分别训练分类器的特点,提出一种基于预测标签一致性的去冗余算法。该算法通过比较分类器对不同样本预测结果的一致性,找出所选样本中的相似样本,并去掉其中冗余样本。此方法的定义为
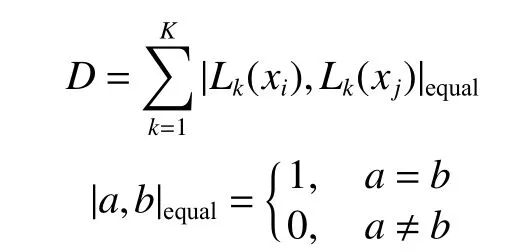
式中:xi,xj∈UC,且xi≠xj;D为样本xi和xj的相似程度,D越大,xi和xj越相似。
基于预测标签一致性的多样性样本选择方法如图4 所示。首先使用一种样本选择方法(如AMD策略)选出一批信息量大的样本{X1,X2,···,X8},然后对从中找出预测标签完全相同的样本。从图4中可以看出,样本X1与样本X3的预测标签完全相同,均为[3,4,4,6,7];样本X5与样本X6的预测标签完全相同,均为[6,6,7,12,7]。从样本X1和样本X3中随机选择一个作为代表加入训练集,如样本X1,其余样本放回候选集;再从样本X5和样本X6中随机选择一个作为代表加入训练集,如样本X5,其余样本放回候选集,最终选择的训练样本为{X1,X2,X4,X5,X7,X8}。从图4 中可以看出,训练样本数由8 个减少为6 个,通过基于预测标签一致性的去冗余方法可以实现去除多余的训练样本的目的,减少人工标记成本。

图4 基于预测标签一致性的多样性样本选择方法示意Fig.4 Graphical representation of a diversity sampling method based on predictive label consistency
3 实验结果与讨论
3.1 实验数据集
为了验证本文算法的有效性,采用了2 个常用的高光谱图像进行仿真实验,分别是Indian Pines 数据集和Salinas 数据集。Indian Pines 数据集包括16 个类别,共有21025 个样本,其中有真实标签的样本为10249 个;Salinas 数据集也包括16 个类别,共有111104 个样本,其中有真实标签的样本为54129 个。
3.2 分类性能评价指标
本文使用综合精度(OA)、平均精度(AA)、Kappa 系数(Kappa)对两组对比实验结果进行定量比较。
OA 方法通过混淆矩阵判别总体分类精度,具体表达式为

式中:N为全部样本数;n为类别总数;mi为 将样本正确分类到第i类的数量。
AA 表示在每个类别中分类正确的样本所占的比重。如果各类别样本数量相同,则平均分类精度AA 与总体分类精度OA 相同。AA 的表达式为

Kappa 系数用来表示分类图与真实图像的一致性。Kappa 系数的具体表达式为

3.3 实验结果对比
本节主要验证本文提出的两种多样性样本选择方法的效果,并将提出的基于超像素分割的多样性选择方法和基于预测标签一致的去冗余算法分别简称为方法A 和方法B。采用选取的2 组HSI 数据进行3 组实验。第1 组:使用传统AMD策略进行样本选择,记为AMD。第2 组:先使用AMD 策略进行样本选择,再将所选样本使用方法A 去除冗余,最后将去冗余后的所选样本加入训练集,进行MVAL,记为AMD+A。第3 组:将方法A 换成方法B,其他操作与第2 组实验相同,记为AMD+B。将第2、3 组实验结果与第1 组实验结果进行对比,验证这2 种方法的有效性。
以上所有实验均使用MLR 分类器[25],采用3D-Gabor 滤波视图生成方法,视图数量为5。3 组数据使用相同频率和方向的3D-Gabor 滤波器,滤波后均得到65 个Gabor 立方体,再通过FR 准则选出充分性前5 的立方体作为MVAL 的5 个视图。实验前,分别在Indian Pines 数据集和Salinas 数据集中有真实标签的样本中选出一部分样本作为初始训练样本。具体方法为:从每个类别中随机选出5 个样本作为初始训练样本,共80 个样本。其余的有真实标签的样本为候选样本,测试样本为有真实标签的全部样本。在AMD样本选择方法中,每次迭代最多选择15 个样本,共迭代20 次。在方法A 中,超像素的边长为4×4,超像素个数大约为总样本数除以16,超像素中光谱和空间的权重因子为0.5。
为了进一步测试方法的效果,本文对比了实验中每5 次迭代对应的分类精度以及各组实验的耗时情况。Indian Pines 数据集的AMD 和AMD+A 实验迭代过程中的分类结果如表1 所示。Salinas 数据集的AMD 和AMD+A 实验迭代过程中的分类结果如表2 所示。

表2 Salinas 数据集的AMD+A 与AMD 的实验结果Table 2 Experimental results of AMD+A and AMD in the Salinas dataset
从表1、2 可以看出:无论迭代次数是多少,通过基于超像素分割的多样性选择方法改进后得到的实验精度基本不变,而训练样本数量均有不同程度的减少。

表1 Indian Pines 数据集的AMD+A 与AMD 的实验结果Table 1 Experimental results of AMD+A and AMD in the Indian Pines dataset
两个数据集在AMD 和AMD+A 实验中得到的最终分类结果如表3 所示,分类结果对比图如图5、6 所示。

图5 用方法A 改进前后的实验结果分析(Indian Pines)Fig.5 Comparison of experimental results before and after improvement with method A (Indian Pines)

表3 AMD+A 与AMD 实验的最终结果Table 3 Final results of the AMD+A and AMD experiments

图6 用方法A 改进前后的实验结果分析(Salinas)Fig.6 Comparison of experimental results before and after improvement with method A (Salinas)
由AMD 和AMD+A 的对比实验结果可以看出:3 个HSI 数据集在两组实验中的OA、AA、Kappa 值区别不大,分类结果图也无明显差别,然而两个数据集在AMD+A 实验中用到的训练样本总数比AMD 实验中分别减少了10.2%、17.1%,耗时仅增加了3.49 s、24.92 s。Indian Pines 数据集的AMD 和AMD+B 实验迭代过程中的分类结果如表4 所示。Salinas 数据集的AMD 和AMD+B 实验迭代过程中的分类结果如表5 所示。

表4 Indian Pines 数据集的AMD+B 与AMD 的实验结果Table 4 Experimental results of AMD+B and AMD in the Indian Pines dataset

表5 Salinas 数据集的AMD+B 与AMD 的实验结果Table 5 Experimental results of AMD+B and AMD in the Salinas dataset
从表4、5 中可以看出:无论迭代次数是多少,通过基于预测标签一致的去冗余算法改进后得到的实验精度基本不变,而训练样本数量均有不同程度的减少。两个数据集在AMD 和AMD+B实验中得到的最终分类结果如表6 所示,分类结果对比图如图7、8 所示。

图7 用方法B 改进前后的实验结果分析(Indian Pines)Fig.7 Comparison of experimental results before and after improvement with method B (Indian Pines)

表6 AMD+B 与AMD 实验的最终结果Table 6 Final results of AMD+B and AMD experiments

图8 用方法B 改进前后的实验结果分析(Salinas)Fig.8 Comparison of experimental results before and after improvement with method B (Salinas)
由AMD 和AMD+B 的对比实验结果可以看出:3 个HSI 数据集在两组实验中的OA、AA、Kappa 值区别不大,分类结果图也无明显差别,然而两个数据集在AMD+B 实验中用到的训练样本总数比AMD 实验中分别减少了8.2%、25.4%。AMD+B 比AMD 实验的耗时增加0.88 s、14.34 s。
通过观察以上实验结果可以看出,AMD+A方法和AMD+B 方法相对于传统AMD 方法具有明显优势。从实验结果来看,将本文提出的两种样本多样性选择方法用在传统AMD 样本选择方法后,OA、AA、Kappa 及分类结果图均无明显变化,训练样本数量均有不同程度的减少。使用这两种改进方法虽然会少量地增加耗时,但增加的时间成本与节省的人工标记成本相比可以忽略不计。
4 结束语
本文基于SLIC 超像素分割方法和各视图预测结果的一致性,提了出2 种MVAL 多样性样本选择方法,有效地解决了传统MVAL 样本选择过程存在冗余样本的问题。在2 组HSI 中进行实验,验证了这两种方法能够有效地去除传统样本选择过程中的冗余样本,在分类精度不变的前提下,减少训练样本总数,进而减少人工标记成本。
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
北京理工大学学报(2016年6期)2016-11-22
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
