
基于小样本学习的植物病害识别研究*
2021-12-06 07:28肖伟冯全张建华杨森陈佰鸿
中国农机化学报 2021年11期
肖伟,冯全,张建华,杨森,陈佰鸿
(1.甘肃农业大学机电工程学院,兰州市,730070;2.中国农业科学院农业信息研究所,北京市,100081;3.甘肃农业大学园艺学院,兰州市,730070)
0 引言
在农业种植中,病害是影响农作物的产量和质量的关键因素之一。当病害发生时,若能快速准确的识别病害类型并做出相应的处理,可以为农作物的保产、增产提供有力的支持。传统对植物病害识别经常依靠经验丰富的专家用眼睛进行识别,但依靠人眼识别植物病害会出现速度慢、效率低、准确性低等问题。
近年来,以深度学习为代表的人工智能领域发展非常迅速,已经渗透到农业病害识别领域,其中使用最为广泛的深度学习方法是深度卷积神经网络[1-3],Mohanty等[4]在PlantVillage数据集上利用54 306张植物病害叶片图像训练和测试,采用AlexNet和GoogLeNe两个模型,得到最高准确率为99.35%。Amara等[5]使用3 700张香蕉病害叶片图像作为训练和测试,采用LeNet模型,准确率达到99.72%。Brahimi等[6]利用14 828张西红柿病害叶片图像作为训练和测试,采用AlexNet和GoogLeNet模型,准确率分别达到98.66%和99.18%。Liu等[7]利用13 689张苹果病害图像作为训练和测试,采用AlexNet模型,准确率达到97.62%。Dyrmann等[8]用22种杂草和农作物品种共10 413张图像的数据集训练测试建立模型,平均分类准确率为86.2%。张建华等[9]在原有VGG-16模型基础上不断改进,提出了一种新的VGG棉花病害模型,准确率达到89.51%。郑一力等[10]利用大量的植物叶片图像作为训练和测试,采用AlexNet和InceptionV3模型,准确率分别达到95.31%和95.40%。
以上采用深度卷积网络作为识别器的方法需要大量的数据样本才能取得好的识别效果。但是在实践中,一些病害样本的采集成本较高,特别是不常见的病害,往往收集到几张或者几十张病害图像,达不到深度网络训练所需要的样本数量,导致网络不能充分训练,泛化效果不好,病害识别效果下降。虽然通过迁移学习可以在某种程度上减少训练的样本数量,但是无法解决少量样本训练导致模型容易过拟合的问题。
为了解决深度网络数据依赖问题,在人类的快速学习能力启发下,研究者提出了小样本学习(few-shot learning)的概念,希望深度网络能像人类一样拥有从少量数据样本中学习的能力。Vinyals等[11]提出匹配网络(MatchingNet),使用长短期记忆网络(long short-term memory,LSTM)模型和注意力机制,在miniImageNet数据集上识别准确率为46.60%。Sung等[12]提出关系网络(RelationNet)模型,在miniImageNet数据集上识别准确率为50.44%。近年来小样本学习在农业病害识别方面已经开始得到应用[13]。
本文为研究有效的少样本植物病害识别方法,选取匹配网络、原型网络和关系网络3种典型算法作为小样本学习框架,这3种网络属于元学习中基于距离度量的方法,具有识别准确性较高的特点。在这些框架下,特征提取网络分别采用Conv4、Conv6、ResNet10、ResNet18和ResNet34 5种浅层网络,在PlantVillage数据集上分别采用5-way、1-shot和5-way、5-shot方式进行训练、测试。通过试验分析了小样本学习框架与不同特征提取网络的配合特点,比较了学习框架与特征网络不同组合方式对于植物病害叶片图像识别准确率的影响。
1 试验材料和方法
1.1 试验材料
PlantVillage是一个开放的植物病害图像数据集,其中包含14种植物,共54 306张植物病害图像,最多的类有5 507张样本图像,最少类的有152张。PlantVillage数据集的详细信息见表1。由于本文采用的是小样本学习方法,故采用了模拟小样本的策略,即随机从38个类别中的植物叶片图像分别抽取20张,组成38×20的样本集合模拟小样本数据集。把该数据集划分为训练集、验证集和测试集。
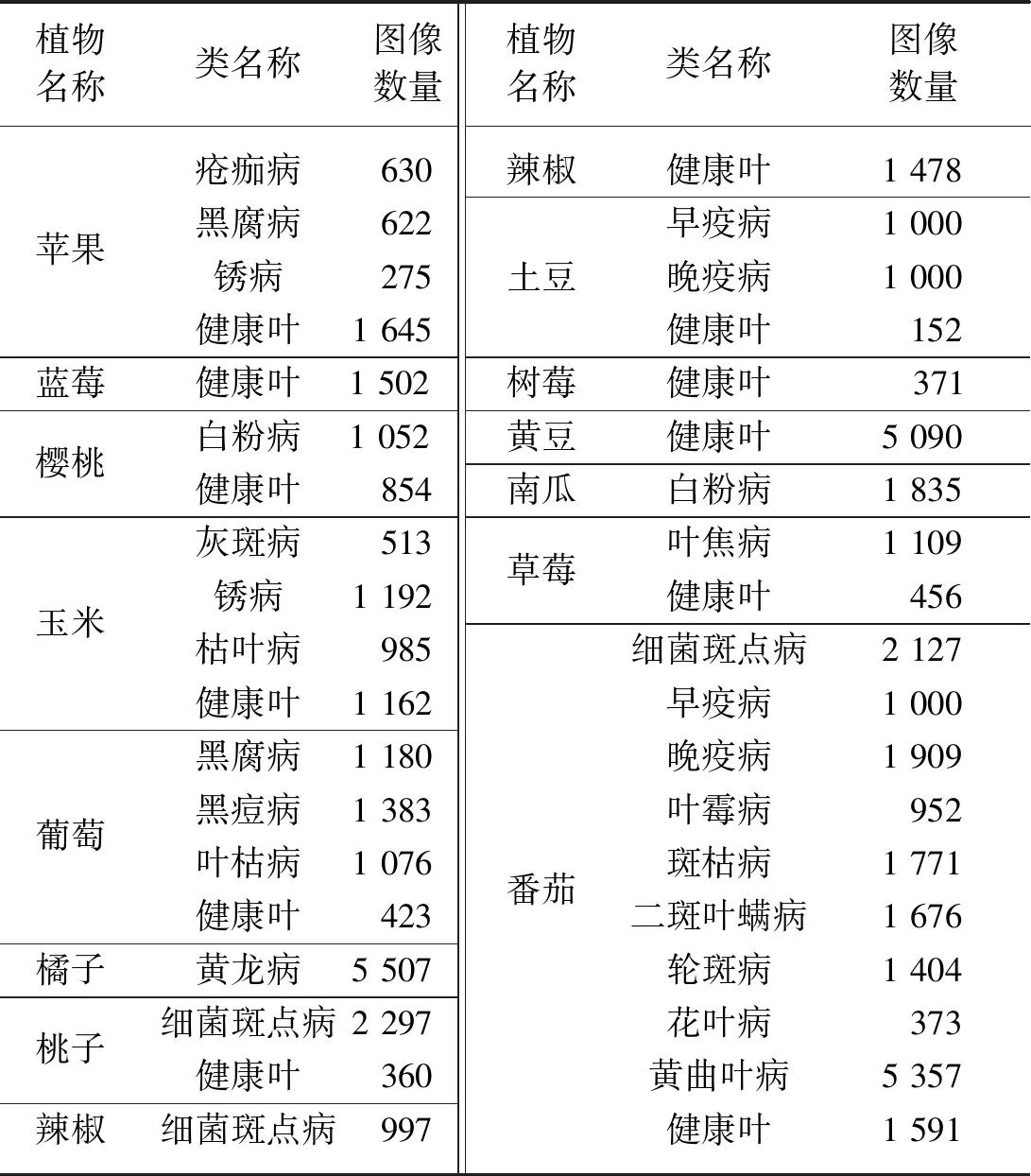
表1 PlantVillage数据集图像信息Tab.1 Image information of PlantVillage data set
为了方便起见,将PlantVillage数据集的病害按英文字母排序,将位置处于1、3、5、…、37共19类病害作为训练集,包括了苹果疮痂病、苹果锈病、蓝莓健康叶、樱桃白粉病、玉米锈病、玉米枯叶病、葡萄黑痘病、葡萄枯叶病、桃子细菌性斑点病、辣椒细菌性斑点病、土豆早疫病、土豆晚疫病、黄豆健康叶、草莓健康叶、番茄细菌性斑点病、番茄健康叶、番茄叶霉病、番茄二斑叶螨病、番茄花叶病。将字母排序位置处于2、6、10、…、38共10类病害作为验证集,包括了苹果黑腐病、樱桃健康叶、玉米健康叶、葡萄健康叶、桃子健康叶、土豆健康叶、南瓜白粉病、番茄早疫病、番茄斑枯病、番茄黄曲叶病。测试集则由剩下位置的病害组成,包括苹果健康叶、玉米灰斑病、葡萄黑腐病、橘子黄龙病、辣椒健康叶、树莓健康叶、草莓叶焦病、番茄晚疫病、番茄轮斑病9种类型。
1.2 研究方法
1.2.1 匹配网络(MatchingNet)
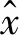
(1)
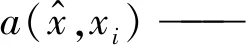
(2)
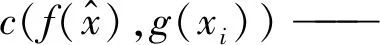
f,g——嵌入函数,一般有f=g。
1.2.2 原型网络(ProtoNet)
在原型网络方法中,使用卷积神经网络将数据样本投影到一个特征空间。在这个特征空间中,将每个类别的数据样本嵌入向量的均值作为原型,用新测试样本与原型作比较,距离较近的为同类样本,距离较远的为异类样本。原型网络与匹配网络有诸多相同之处,都是采用计算距离的方式来判断图像是否为同类。原型网络创新之处使用k最近邻(k-means)的思想对注意力机制进行替换,使用欧氏距离代替了余弦距离。原型网络首先使用嵌入函数f将数据映射到特征空间中,然后为支持集中的每个类别计算原型
(3)
式中:Ck——类别k的原型;
fφ(xi)——样本xi经特征提取网络得到的特征;
Sk——支持集S中类别为k的数据样本集合。
(4)
1.2.3 关系网络(RelationNet)
关系网络有两个模块构成,一个是特征嵌入模块fφ(Embedding module),另一个是关系模块gφ(Relation module)。特征嵌入模块由4个卷积层和2个最大池化层构成,每个卷积层包含卷积核尺寸为3×3,其作用是将图像特征生成样本的特征向量。关系模块含有2个卷积层和2个全连接层,该模块负责计算查询样本和支持集样本的相似度。如图1为关系网络结构示意图。
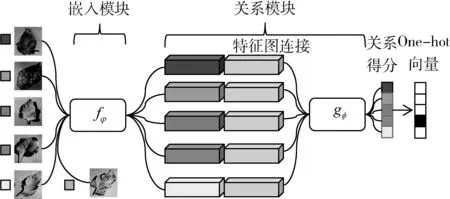
图1 关系网络结构图Fig.1 RelationNet structure
1.3 特征提取网络
本文采用的特征提取网络包括Conv4、Conv6[14]和ResNet网络[15]。这些网络在上述小样本框架下,实现对病害识别特征的提取。Conv4网络由4个卷积模块组成,其中每个卷积模块由卷积层、批归一化层(Batch Normalization Layer)、LeaklyReLU层和最大池化层(Max Pooling layer)构成。而Conv6网络比Conv4网络多了两个额外卷积模块,但这两个卷积模块并不含有池化层,其余组成都是一致的。ResNet是一种常用的高效卷积网络,通过给非线性的卷积层增加直连边的方式来提高信息的传播效率。
1.4 试验方法
小样本学习分为元训练阶段和元测试阶段。在元训练阶段,会在训练集中随机抽取C个类别,每个类别抽取k张样本,C×k张样本作为训练阶段模型的支持集(support set)输入;再从这C个类别剩余的数据中抽取一批样本作为模型的预测对象查询集(query set)。通过训练让模型从C×k张样本中学会如何区分这C个类别,一个支持集和一个查询集组成一个任务,这样的任务被称为C-way、k-shot问题。在元测试阶段,按照同样的方法,在测试集上抽取支持集和查询集用于二次训练。本文的试验方法采用了小样本学习中最常采用的5-way、1-shot和5-way、5-shot的方式。
在元训练阶段,每次训练都会在一般的病害训练集中采样得到一系列不同任务,采样得到的每一个任务都是不同类别的组合,去学习一般病害类别变化的情况下模型的泛化能力。这种机制使得模型学会不同任务中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉任务中非共性部分。通过这种学习机制学到的模型,模型的泛化能力比较强。在测试阶段,测试集与训练集完全不同,但上个阶段的训练使得模型已经学习到了识别一般病害的知识,用该模型对要在测试集进行病害分类的模型进行初始化,在测试集上按照与元训练阶段相同的抽样方法,从测试集和验证集上抽取多组任务,完成二次训练和测试。可以看出两个阶段的训练使得模型完成了从一般病害到特定病害识别的进化。
图2展示了5-way、1-shot学习任务的具体例子。可以观察到在训练阶段构建了一系列任务来让模型学习如何根据支持集来预测查询集中的样本标签。测试阶段输入数据形式与训练阶段一致,但会在全新的类别上构建支持集和查询集。图中第一行是随机抽取的一个任务,将苹果疮痂病叶片、苹果锈病叶片、樱桃白粉病叶片、玉米锈病叶片、玉米枯叶病叶片5类病害叶片图像作为训练的支持集,苹果锈病叶片作为查询集。通过学习支持集中的5张病害叶片图像来对查询集中新的病害叶片图像进行预测然后分类。图中第三行则是在测试阶段抽取的一个任务,该任务将玉米灰斑病叶片、葡萄黑腐病叶片、橘子黄龙病叶片、草莓叶焦病叶片、番茄晚疫病叶片5类病害叶片图像作为训练的支持集,番茄晚疫病叶片作为查询集。与训练阶段采用一致的学习方法来对查询集中新的病害叶片图像进行预测然后分类。

图2 5-way、1-shot学习任务分类Fig.2 Classification of 5-way、1-shot learning tasks
2 试验结果与分析
2.1 试验平台
试验操作系统为Ubuntu16.04 LTS 64位系统,采用Pytorch深度学习开源框架,选用Python作为编程语言。硬件环境:计算机RAM为8 GB,搭载Intel(R)Core(TM)i7-8750H CPU@2.20 GHz处理器,GPU是NVIDIA GeForce GTX 1050 Ti。软件环境:CUDA9.0,CUDNN7.0,Python3.5,Pytorch0.4.0。在元训练阶段的训练集和元测试阶段的测试集对任务的采样次数均为600次。
2.2 病害识别测试结果
5-way、1-shot和5-way、5-shot条件下,在PlantVillage数据集上的病害识别试验结果准确率如表2。
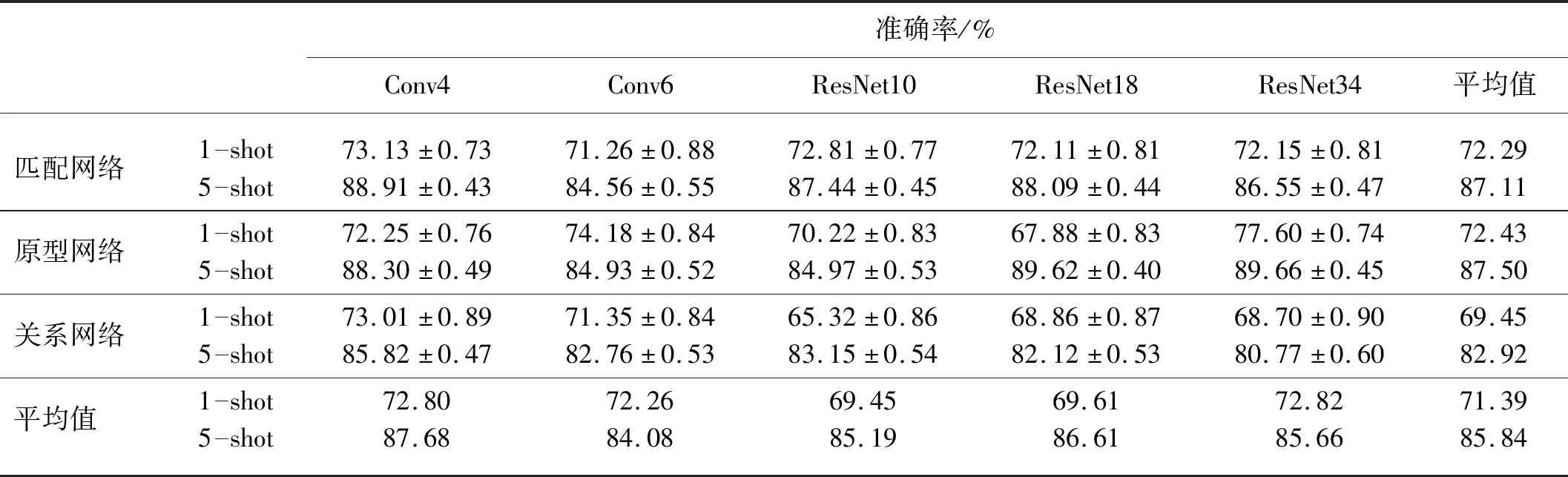
表2 5-way、1-shot和5-way、5-shot试验结果Tab.2 5-way、1-shot and 5-way、5-shot test results
2.3 病害识别效果分析
2.3.1 5-way、1-shot试验结果分析
根据表2,匹配网络、原型网络框架和5种特征提取网络组合,对病害叶片识别平均准确率分别为72.29%和72.43%,均达到72.00%以上,表明用一个数据样本训练也能对病害识别取得较好的效果。关系网络框架下和5种特征提取网络组合,对病害叶片识别平均准确率为69.45%,低于前两种网络。稳定性角度看,匹配网络与5种特征提取网络组合,其识别精度在71.00%~74.00%之间,方差为0.42;原型网络识别精度在67.00%~78.00%之间,方差为11.08;关系网络识别精度在65.00%~74.00%之间,方差为6.85。相较于原型网络和关系网络,匹配网络与各种特征提取网络组合表现较稳定。
通常情况下,深度卷积网络随着层数增加,其识别精度会随之提高。但从表2中试验结果可看出,在3种小样本学习框架下,特征提取网络层数增加与识别精度似乎没有关系。相反,随特征提取网络层数增加,试验结果的准确率可能增加也可能减少。在匹配网络和关系网络框架下,当特征提取网络从Conv4变到Conv6时,其识别精度分别从73.13%下降到71.26%,73.01%下降到71.35%;在匹配网络和原型网络框架下,当特征提取网络从ResNet10变到ResNet18时,其识别精度分别从72.81%下降到72.11%,70.22%下降到67.88%。
表2试验结果表明,匹配网络作为小样本学习框架时,匹配网络+Conv4是表现最好的组合,病害识别准确率为73.13%;原型网络作为小样本学习框架时,原型网络+ResNet34是表现最好的组合,病害识别准确率为77.60%;关系网络作为小样本学习框架时,关系网络+Conv4是表现最好的组合,病害识别准确率为73.01%,这表明不同的小样本学习框架和不同的特征提取网络合理组合能获得较好病害识别效果。
2.3.2 5-way、5-shot试验结果分析
表2试验结果可以看出,相较于1-shot,训练样本增加到5时,3种小样本学习框架和5种特征提取网络的组合对病害叶片识别都有不同程度的上升。匹配网络框架下Conv4、Conv6、ResNet10、ResNet18和ResNet34模型分别提升了15.78%、13.30%、14.63%、15.98%、14.40%;原型网络框架下Conv4、Conv6、ResNet10、ResNet18和ResNet34模型分别提升了16.05%、10.75%、14.75%、21.74%、12.06%;关系网络框架下Conv4、Conv6、ResNet10、ResNet18和ResNet34模型分别提升了12.81%、11.41%、17.83%、13.26%、12.07%。说明增加训练的样本数,对网络提升病害叶片识别的准确率有一定的帮助。在稳定性方面,匹配网络、原型网络和关系网络框架下与5种特征提取网络的组合,方差分别为2.23、4.56和2.75,相较于1-shot,5-shot条件下各种组合的方差维持在较小的范围内,具有较好的稳定性。
表2中可以看出,植物病害叶片识别准确率并不是随特征提取网络层数增加效果越佳,与1-shot表现一致。在匹配网络、原型网络和关系网络框架下,当特征提取网络从Conv4变到Conv6时,其识别精度分别从88.91%下降到84.56%,88.30%下降到84.93%,85.82%下降到82.76%。在匹配网络和关系网络框架下,当特征提取网络从ResNet18变到ResNet34时,其识别精度分别从88.09%下降到86.55%,82.12%下降到80.77%。
表2试验结果表明,匹配网络作为小样本学习框架时,匹配网络+Conv4是表现最好的组合,病害识别准确率为88.91%;关系网络作为小样本学习框架时,关系网络+Conv4是表现最好的组合,病害识别准确率为85.82%;原型网络作为小样本学习框架时,原型网络+ResNet34是表现最好的组合,病害识别准确率为89.66%,该组合也是所有组合中的最优组合。
试验数据表明,1-shot和5-shot条件下,匹配网络+conv6始终都是对病害识别准确率最差的组合。原型网络+ResNet34始终都是对病害识别准确率最佳的组合。试验结果表明小样本学习框架和特征网络组合有较强的稳定性,最优的组合暗示着模型有较强的学习特征能力。得出最优的组合方式也为以后试验研究特定的植物病害提供了一种思路。
3 结论
为验证小样本学习方法对植物病害识别的有效性,本文采用了匹配网络、原型网络和关系网络3种小样本学习框架,选择了Conv4、Conv6、ResNet10、ResNet18和ResNet34特征提取网络进行了组合植物病害识别试验。
1)3种小样本学习方法对病害识别是有效的,1-shot条件下,匹配网络、原型网络和关系网络对植物叶片病害识别的平均准确率分别为72.29%、72.43%、69.45%;在5-shot条件下,3种网络识别的平均准确率分别达到了87.11%、87.50%和82.92%。
2)5-shot比1-shot识别率分别提高了14.82%、15.07%和13.47%,说明训练样本数量对识别率影响较大,应尽量采用更多样本进行训练。
3)各种组合中,原型网络+ResNet34是表现最佳的组合方式,识别率达到89.66%。小样本病害识别研究对于农业生产具有重要价值,随着越来越多更好的学习方法被提出,我们相信只需少量样本训练出的模型识别性能是能够逼近大样本训练的深度模型的,这将大大降低学习成本,降低模型从样本采集到训练和部署的时间。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小资CHIC!ELEGANCE(2021年45期)2021-01-11
电子制作(2018年19期)2018-11-14
英美文学研究论丛(2018年2期)2018-08-27
中国交通信息化(2018年5期)2018-08-21
自动化学报(2017年11期)2017-04-04
剑南文学(2016年14期)2016-08-22
人间(2015年20期)2016-01-04
