
基于可拆分倒排索引的可搜索加密方案
2021-12-07 10:09孙晓玲杨光沈焱萍杨秋格陈涛
计算机应用 2021年11期
孙晓玲,杨光,沈焱萍,杨秋格,陈涛
(防灾科技学院信息工程学院,河北三河 065201)
0 引言
随着云计算技术[1-2]的快速发展以及大数据时代的到来,越来越多的用户选择将数据存储到云服务器,以节省自身的开销,实现便捷的多点访问。
为了保护数据安全,数据拥有者通常将数据加密后存储在云端。用户对数据进行检索和更新时,需要将所有密文数据从云端下载到本地,再进行解密、检索和更新,随着数据资源的激增,这种方案是无法满足时效要求的。因此,如何在用户提交检索请求时,实现云端对密文数据的检索是云数据安全存储的重要需求。为了解决这一问题,提出了可搜索加密的概念。具体地,数据拥有者对文件进行加密,并提取文件中的关键词加密以建立安全索引,将密文和索引外包给服务器,当用户需要访问含有某个关键词的文件时,计算该关键词的搜索凭证发送给云服务器,云服务器根据搜索凭证查询索引,获得文件标识符,将对应文件的密文返回给用户。
可搜索加密思想最早由文献[3]提出。第一个实际的对称可搜索加密方案由文献[4]提出。文献[5]提出了一个基于前向索引(Forward Index)的对称可搜索加密方案,采用为每个文件建立一个布隆过滤器(Bloom filter)的方法来建立索引。文献[6-7]均采用建立前向索引的方法构建可搜索加密方案。与前向索引结构相对应的是倒排索引(Inverted Index)结构,该索引结构由文献[8]提出。文献[9]设计了一个完全支持动态操作的基于倒排索引的对称可搜索加密方案。文献[10]在文献[9]的基础上使用红黑树提出了一个支持并行和动态操作的对称可搜索加密方案。文献[11-13]分别提出了不同的动态可搜索加密方案,都是对文件和关键词配对进行处理,文献[14]中提出了一种在云端创建搜索索引的方案,该方案首先由用户创建一个存储了文件-关键词映射的文件索引和一个用于存储关键词-文件映射的空的搜索索引,并提交给云端,云端在用户提交检索凭证时查询文件索引获取检索结果,并将检索结果添加到搜索索引中,搜索索引只存储了已被搜索过的关键词及其所在文件集合,该方案将搜索索引的构建时间分摊到了每次检索过程中,同时提高了检索效率,节省了存储空间,但动态更新的效率不高。文献[15]在文献[14]的基础上由云端增加了一个删除索引,用以存储已被搜索过的文件-关键词映射,在删除文件时,可迅速查找出被删除文件在搜索索引中的位置,极大提高了搜索索引的更新效率。近年来,研究学者设计了许多不同功能的可搜索加密算法,比如:支持模糊搜索[16],支持多关键词搜索[17],支持近似搜索[18],支持搜索结果排序[19-20],支持分块处理[21-22]。
现有方案对可搜索加密技术在安全、效率、功能、存储空间和动态更新等方面进行了不同程度的取舍,以适应不同应用环境的需求。随着大数据技术的发展,海量密文存储场景增加,如何有效利用云端资源、快速地批量更新数据,成为了新的应用需求。
本文采用了文献[14]中的方案,用户在本地创建文件索引,由云端在搜索过程中构建搜索索引,充分利用了云端资源,将搜索索引的存储空间和计算时间分散到了每次搜索过程中,且对于已搜索过的关键词,该方案实现了近似最优的线性搜索时间。文献[14-15]方案中索引的存储采用的是哈希链表的形式,索引的更新是单个节点的增加和删除,要逐个进行,故文件的添加和删除只能单个进行。本文采用了keyvalue 集合形式的存储结构,可对索引进行合并和拆分,能够快速实现文件的批量添加和删除。本文方案可兼容分布式系统架构,应用于海量数据处理场合。
1 问题描述
1.1 方案对比
称文件中的不重复关键词为唯一关键词,设n为唯一关键词的总数,m为所有关键词的总数,|F|为文件的总数,IDw为包含w的文件标识符集合,r为一次查询中平均返回文件记录总数,表1给出了本文方案与其他方案的各方面性能比较。

表1 不同方案的性能比较Tab.1 Performance comparison of different schemes
1.2 系统模型
云环境下密文检索系统模型如图1 所示,包括三个主体:数据拥有者、用户和云服务器。

图1 云环境下密文检索系统模型Fig.1 Ciphertext retrieval system model in cloud environment
数据拥有者是拥有原始数据的企业或组织,要将文件集合F=(f1,f2,…,fn)存储在云服务器,为了保障数据的安全,先使用对称加密算法对文件进行加密,得到密文集合C=(c1,c2,…,cn),同时,对每个文件提取唯一关键词构成唯一关键词集合(1 ≤i≤n),对文件的唯一关键词用伪随机函数进行变换,构造key-value 形式的文件索引If,key 值为文件标识符id(f),value 为集合形式存储的唯一关键词密文,同时生成一个空的key-value 形式的搜索索引Iw,key值为由被搜索关键词生成的搜索凭证,value 为集合形式存储的包含该关键词的文件的标识符,数据拥有者将密文集合C、文件索引If、空的搜索索引Iw一起提交给云服务器。当用户想要获取某些文件时,需利用关键词对文件进行搜索,用户从数据拥有者获取陷门密钥,由关键词生成搜索凭证,将搜索凭证提交给云服务器。云服务器首先查找搜索索引Iw中是否有该关键词的key值,有则直接返回对应的value值,若没有,则根据搜索凭证对文件索引If进行搜索,记录包含该关键词的文档编号集合,并在搜索索引Iw中添加该项记录,最后返回搜索结果中的文件密文给用户。
1.3 变量和定义
文中所用到的变量和相应定义如表2所示。

表2 所用到的变量和相应定义Tab.2 Used variables and corresponding definitions
定义1基于可拆分倒排索引的可搜索加密方案由一个五元组SIISE构成,SIISE=(Keygen,Indexgen,Search,Add,Delete),具体如下。
1)SIISE.Keygen。用户端根据安全参数λ生成密钥集K,分别为对称加密和解密、带密钥的伪随机算法提供不同密钥。
2)SIISE.Indexgen。用户端根据文件集合F和密钥集K,生成文件索引If、空的搜索索引Iw、空的搜索历史集合σ和加密后的密文集合C,将If、Iw和C提交给云端。
3)SIISE.Search。用户端根据检索关键词w和密钥集K,生成检索凭证提交云端,并更新搜索历史σ,云端检索得到包含此关键词的文件标识符集合IDw,同时更新搜索索引Iw。其中,未被检索过的关键词先通过搜索文件索引If获得检索结果并将结果添加到Iw中,已搜索过的关键词可直接检索搜索索引Iw。云端返回密文集合Cw,用户解密得到文件集合Fw。
4)SIISE.Add。用户端根据要添加的文件集合Fa、唯一关键词集合Wa、搜索历史σ和密钥集K,生成文件索引Ifa、搜索索引Iwa和密文集合Ca,将Ifa、Iwa、Ca提交给云端。云端将已有的If、Iw分别与Ifa、Iwa合并,将Ca添加到密文集合中。
5)SIISE.Delete。用户端根据要删除的文件集合Fd、唯一关键词集合Wd、搜索历史σ和密钥集K,生成索引Iwa,将Iwa和要删除的文件标识符集合IDS提交给云端。云端从If中删除由IDS中的标识符作为key 值的记录,从Iw中拆除Iwa,从密文集合中删除IDS中标识符对应的密文。
称可搜索加密方案SIISE是有效的,如果对任意λ∈N,由算法Keygen生成的密钥集K,文件集合F,对称加密所得密文集合C,以及所有基于索引I所进行的添加、删除等操作,任一搜索操作返回的结果都是正确的。
理想情况下,可搜索加密方案应避免云端获取有关文件和搜索内容的相关信息,但如此高安全性的实现是以存储消耗和搜索效率为代价的,可以允许泄露少量信息来构建更加有效的方案。采用文献[10]中给出的方法,使用泄露函数(leakage function)来验证方案的安全性。
定义2SIISE=(Keygen,Indexgen,Search,Add,Delete)是一个安全的动态可搜索加密方案。进行以下实验,假设A是一个有状态攻击者、S为有状态模拟器,LSearch,LAdd为泄露函数,有:

称SIISE对自适应动态选择关键词攻击是(LSearch,LAdd)安全的,如果对任意概率多项式算法A,存在概率多项式时间模拟器S,使得A的优势|Pr=1]|对于λ是可忽略不计的。
2 倒排索引的构建
本文方案的核心设计是建立可拆分倒排索引,云端可独立合并和拆分索引,实现文件的批量增加和删除。采用keyvalue形式存储索引,key为索引键值,value为集合形式的结果集,假设有表T,key 值为k,value 值为v,可表示为T[k]=v。实现的时候可直接采用哈希表结构,也可使用非关系型数据库,与分布式系统结合,用于大规模数据场合,可获得更高的检索效率,更灵活的增量添加和删除,且云端可在不依赖客户端的前提下实现对索引的更新。
2.1 索引的构建
本文方案中,用到了两个索引If和Iw,采用key-value 集合形式存储。客户端首先生成一个文件索引If,用以存储文件标识符与其唯一关键词的映射,如图2 所示,key 为文件标识符id(f),value 为该文件的唯一关键词密文集合cˉ=,H为伪随机函数;云端在检索过程中构建搜索索引Iw,如图3所示,key为由关键词w生成的搜索凭证τw=G(w),G为随机函数,value 为包含该关键词的文件标识符集合IDw={id(f1),id(f2),…},m为文件集合F的唯一关键词个数。

图2 文件索引If示意图Fig.2 Schematic diagram of file index If
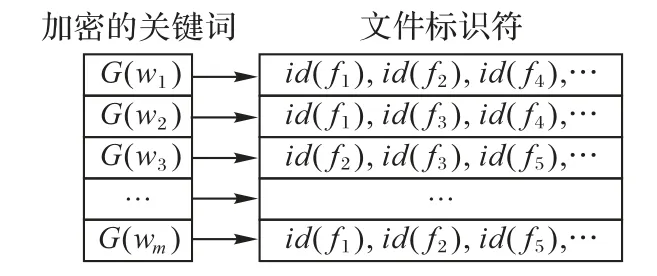
图3 搜索索引Iw示意图Fig.3 Schematic diagram of search index Iw
用户检索时,假设被检索关键词为w,根据陷门密钥生成搜索凭证τw,提交给云端,若w不在搜索历史中,则云端依次搜索If中的每个关键词密文进行匹配,将含有关键词w的文件标识符添加到Iw[τw]中,以创建表Iw的一条记录;否则,已搜索过的关键词可直接查询索引Iw获取搜索结果。
2.2 索引的动态更新
目前常用的索引构建方法主要有倒排索引、树形索引和前向索引(布鲁姆过滤器索引)。大部分方案中的索引构建都采用类似链表结构,节点之间存在依赖关系,索引执行添加和删除操作时,只能单个节点操作,因此无法实现批量添加和删除。
本文方案中的索引采用key-value 集合形式存储,可实现一次性合并与删除,适用于批量增加和删除文件。
批量添加文件时,在本地生成添加文件集合Fa的文件索引Ifa和添加索引Iwa,这里Iwa中的key 值只需包含那些属于Wa且已被搜索过的关键词,因为云端现有的Iw中只有已被搜索过的关键词记录,只需将这些关键词对应的新增文件标识符添加到Iw中相应的value 集合中即可,同时将Ifa整个合并到云端已有的If中。
批量删除文件时,只需用相同的方法生成要删除文件集合Fd的删除索引Iwd,云端直接将要删除文件的记录从If中删除,将Iwd中关键词对应的删除文件标识符从Iw中对应的value集合中一次性删除。
3 方案描述
假设对称加密方案SKE=(Gen,Enc,Dec)是抗不可区分选择明文攻击的,选取一个伪随机数生成器V:{0,1}λ→{0,1}*,一个伪随机函数G:{0,1}λ×{0,1}*→{0,1}λ,一个随机函数H:{0,1}λ×{0,1}*→{0,1}λ,构建的方案SIISE=(Keygen,Indexgen,Search,Add,Delete)描述如下。
算法1SIISE.Keygen。



4 安全性分析
方案中的查询和更新操作会泄露特定信息给服务端。与文献[14-15]相同,采用文献[5]中提出的安全标准和文献[10]中提出的泄露函数来证明可搜索加密方案的安全性。下面用两个泄露函数LSearch、LAdd具体给出泄露的信息内容。


5 性能测试
5.1 存储空间复杂度
方案中使用了两个索引If、Iw。If中存储了文件标识符与文件唯一关键词密文集合的映射,假设m为If中所有关键词的总量,则If的空间复杂度为O(m)。Iw中存储了关键词的搜索凭证与文件标识符集合的映射,Iw的空间复杂度为
5.2 搜索时间复杂度
假设m为If中所有关键词的总量,n为If中唯一关键词总量。本文方案中,第一次搜索某个关键词时,其搜索时间是与m线性相关的,当所有关键词都被搜索过后,即Iw中有n个输入,搜索时间达到近似最优。此时,进行一次查询操作,平均返回m/n个文件。故在搜索时间达到最优值后,搜索时间复杂度为O(m/n)。
5.3 搜索时间测试
本文方案的测试中,所用环境为AMD 锐龙52400G 整合Radeon Vega Graphics 3.60 GHz,32 GB内存,64位Windows 10操作系统,开发环境为Python 3.7,IDE 为Pycahrm。使用Enron Email 20150507 测试数据集,此数据集包含517401 个邮件,共1.32 GB。
初始搜索时,需要遍历If中几乎所有的节点,耗时较长,随着搜索次数的增加,Iw中记录条数增多,搜索历史中的关键词可直接返回结果,平均耗时逐渐降低。以5000次搜索为递增单位,给出搜索次数与搜索历史关键词数及新增关键词数的统计情况,如图4 所示,同时给出对应的平均搜索时间变化情况,如图5所示。
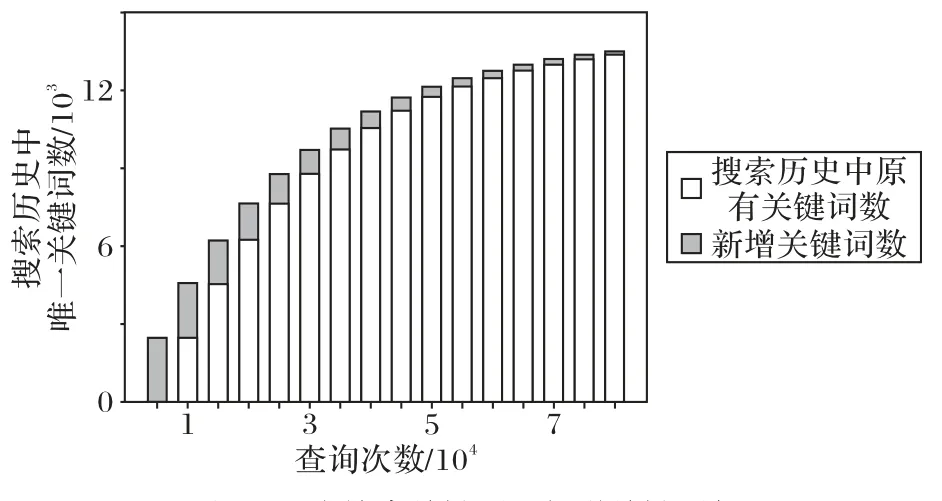
图4 历史搜索关键词及新增关键词与总搜索次数关系Fig.4 Relationship between historical search keywords,new keywords and total search times

图5 平均每次搜索耗时与总搜索次数关系Fig.5 Relationship between average time cost in each search and total search times
5.4 动态更新时间测试
本文方案相较文献[14]方案和文献[15]方案的最大改进是采用key-value 结构构建索引,索引可一次性批量添加和删除value 值,可高效实现文件的批量增删,下面对索引添加和删除操作进行对比测试。
对于索引If,本文方案与文献[14]方案、文献[15]方案这两种方案相比,增加和删除文件的区别在于一条记录的增删和多条记录增删,时间差别在于n次操作和单次操作的区别。
对于索引Iw,文献[14]方案、文献[15]方案中添加文件操作是相同的,每添加一个文件f,对f中已在搜索历史中的每一个关键词w,将id(f)添加到Iw[τw]中,添加多个文件时要逐个添加。本文方案中,对于要批量添加的文件集合,构造Iwa,将Iwa[τw]一次性添加到Iw[τw]中,图6给出了两种方案(本文方案和文献[14-15]方案)的Iw添加文件耗时对比。
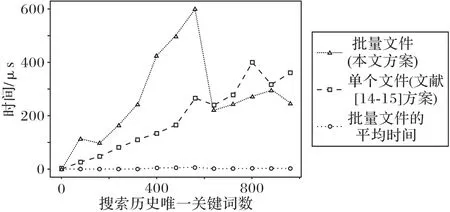
图6 Iw添加文件在本文方案与文献[14-15]方案的耗时对比Fig.6 Time consumption comparison of adding files in Iw between proposed scheme and scheme in literature[14-15]
文献[14]方案每删除一个文件,要遍历Iw中每一项,并逐个查找Iw[τw]处列表的每个节点,直到找到所删除文件的标识符或者到达末尾节点,若要批量删除文件,也需要逐个删除。本文方案中,对于要批量删除的文件集合,构造Iwd,将Iwd[τw]一次性从Iw[τw]中删除,图7给出了本文方案与文献[14]方案的删除文件耗时对比。
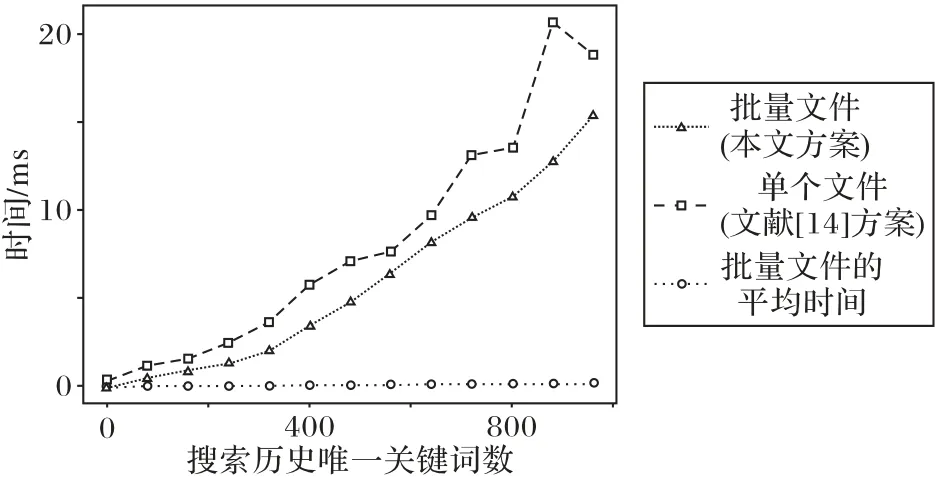
图7 Iw删除文件在本文方案与文献[14]方案的耗时对比Fig.7 Time consumption comparison of deleting files in Iw between proposed scheme and scheme in literature[14]
文献[15]方案每删除一个文件,先查找删除索引以确定该文件中有哪些关键词已被搜索过,然后直接查找已搜索关键词在搜索索引中的记录,依次查找链表节点直到找到文件的标识符并将其删除。图8 给出了本文方案与文献[15]方案的删除文件耗时对比。

图8 Iw删除文件在本文方案与文献[15]方案的耗时对比Fig.8 Time consumption comparison of deleting files in Iw between proposed scheme and scheme in literature[15]
6 结语
在文献[14]方案的基础上,基于key-value 结构构建倒排索引,本文提出了一种可对索引进行批量更新的可搜索加密方案,适用于批量数据的添加和删除。本文索引的可合并与可拆分特性,支持云端独立对索引进行操作,而不依赖于客户端的状态,可进一步应用于分布式系统,更加高效地实现海量数据处理。本文方案还可用于其他功能下的搜索方案,如多关键字查询、模糊查询等。
猜你喜欢
华人时刊(2022年5期)2022-06-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
计算机仿真(2021年2期)2021-11-17
技术与创新管理(2020年5期)2020-10-09
奥秘(2020年6期)2020-06-30
现代装饰(2020年5期)2020-05-30
科学与财富(2019年27期)2019-10-25
无线互联科技(2019年13期)2019-10-17
意林(图解作文)(2019年6期)2019-07-16
