
基于大数据的信息融合技术在电力系统中的应用
2021-12-14 11:07王璐程晓荣
网络安全技术与应用 2021年12期
◆王璐 程晓荣
基于大数据的信息融合技术在电力系统中的应用
◆王璐 程晓荣
(华北电力大学(保定) 控制与计算机工程学院 河北 071000)
伴随着电力行业中系统和设备的不断升级,出现了大量需要处理的数据集,电力行业进入大数据时期。这使得传统的电力系统无法满足新的需求,所以引进新的算法和框架。本文首先分析了传统数据融合算法的缺点,然后分析了新的Hermite正交基前神经网络的算法,并且电力系统要处理大规模的数据集,因此加入MapReduce框架,将其与该算法相结合。通过对上述算法实验的结果进行分析,证实了该算法对于电力行业的大数据处理非常高效。
电力行业;大数据;神经网络
当前的社会中,大数据技术发展很快速,并且对于大数据的技术应用也非常的广泛。在电力行业中,几乎所有设备都趋于智能化,所以对于电力行业的系统和设备可能利用大数据技术的支持来进行发展和升级。
因为电力系统是定时收集数据,并且随着设备种类越来越多,所以数据的种类和数量也越来越多。在大数据技术的基础上进行数据的分析和处理就很有必要,也就是数据融合[1]。数据融合在研究电力大数据中起着重要作用,它可以整合许多方面的数据信息,让数据的特点一目了然。
1 电力大数据的分类
电力系统中的数据有两种:结构化的数据和非结构化的数据。结构化数据可以通过数据库进行存储和处理,但是使用数据库去处理非结构化的数据会比较难[2]。
2 数据融合技术
数据融合的本质是转换和合并X的n块信息,其中 X 是具有未知含义的实体。根据融合程度,它分为数据层、特征层、决策层。数据层的功能是从所有的监测对象的数据集中提取出研究需要的特征状态量。对于特征层,它的工作是对于数据层所提取的特征状态量进行分析,并且对于相同特征的状态量进行融合,就可以得到具有决定性的对于状态的判断和模式具有识别作用的特征向量。最后一部分,也就是决策层的作用是通过前两部分所得到的决策向量与规定的算法结合,然后做出决策[3]。
2.1 传统数据融合技术
传统的数据融合算法主要利用反向传播(Back Propagation, BP)网络。它的网络模型主要分为三个部分,如图1的网络拓扑结构所示,分别是输入层、隐含层和输出层。

图1 BP网络拓扑结构
根据图1的BP网络拓扑结构,可以观察到一个简单的模型。通过观察模型,隐含层的每个神经元都会收到输入层中所有神经元的输入信号,并且这些输入信号会经过处理后通过连接传递到隐含层,这些连接都带有权重。神经元将接收到的总输入值与设置的阈值进行比较,只有大于阈值,才能通过“激活函数”来产生输出,也是输出层的输入[4]。
这里使用的激活函数为如下公式:

第层第i个神经元的输入值为:
利用激活函数计算第层第个神经元的输出:

第层第个神经元输出的导数:
在误差逆向回传时,设预期输出是d,第层第个神经元所得误差为,其中∈[1,]。误差为:

接下来就可以计算整个BP网络的均方误差:
由此可以得到权值调整式:

如果输出值与预期输出值不相符时,根据计算误差,通过网络的各层次将所得到的误差值进行反向传递[5]。经过多次的调整,使得输出值接近实际值(预期输出值)。大部分情况下,对数据集进行融合归纳都使用这种学习和训练的方法。
利用以下节点对BP算法进行简单的介绍,i1和i2为输入节点,h1和h2为隐藏节点,o1和o2为输出节点。引入初始权值,以及节点的数值,如图2所示。

图2 引入初始权值,以及节点的数值
如图2所示,下面求解迭代过程,当输入样本为0.05和0.10时(一个2维样本数据),神经网络的期望输出是与0.01和0.99接近。
首先来计算节点h1的输入值,激活函数就是之前的Sigmoid函数。
Inh1=0.15*0.05+0.10*0.20+0.35*1=0.3775
根据上式得到h1的输入值后,通过激活函数得到h1的输出值:
Outh1=f(0.3775)=0.593269992
按照上述方法,计算h2的输出值:
Outh2=0.596884378
可以通过上述计算方法,计算输出层节点o1的输出值:
Ino1=W5*Outh1+W6*Outh2+b2*1=1.105905967
Outo1=f(1.105905967)=0.75136507
同样的方法计算o2的输出值:
Outo2=0.772928465
得到输出值后,计算输出节点的误差:
Eo1=(0.01-0.75136507)2/2=0.274811083
Eo2=(0.99-0.772928465)2/2=0.023560026
所以这个神经网络的总误差为:
E=Eo1+Eo2=0.274811083+0.023560026=0.298371109
这就是前向传播的整个过程,接下来就是后向传播。后向传播过程就是替换迭代网络的权值,利用传播所计算的误差得到新的权值,再一次进行前向传播时,通过新的权值进行计算,得到的误差将会缩小,直到误差接受范围内。
2.2 Hermite 正交基前向神经网络算法
Hermite正交基前向神经网络算法,它的特殊之处为激励函数是正交多项式,可以通过一步就计算出神经网络的最优的权值[6]。
该神经网络模型如图3所示。

图3 Hermite 正交基前向神经网络模型
通过伪逆矩阵就可以一步得出其权值w(= 0,1,2,...,-1)。网络的最优权值计算公式如下:

3 结合MapReduce模型算法的并行化
MapReduce(分布式处理框架)由两部分组成,一个是“Map”,它的作用是映射,一个是“Reduce”,它的作用是归纳[7]。主要是通过所有节点并行处理数据,结点独立执行所分配的任务并且实时反馈其状态。
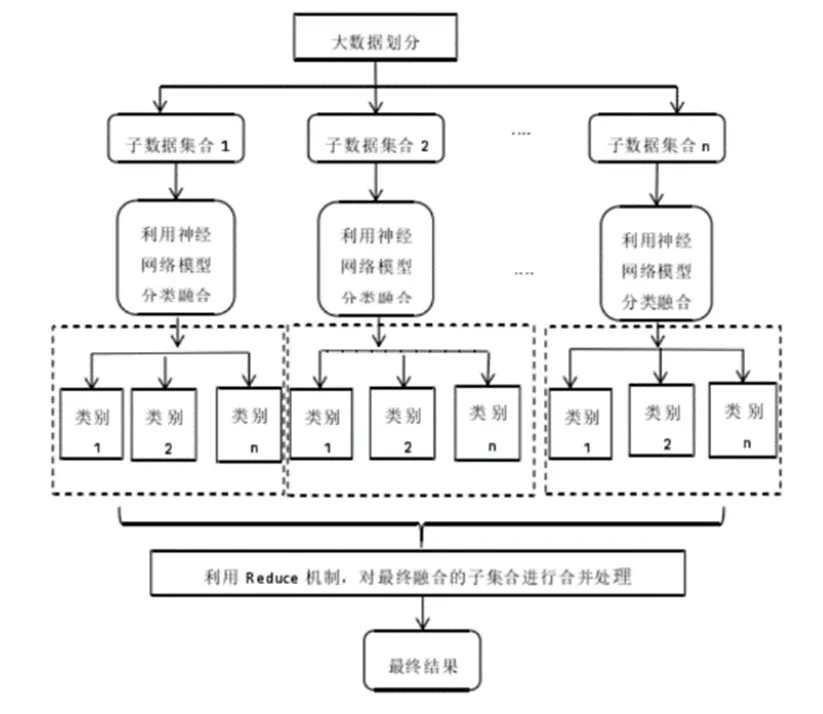
图4 结合 MapReduce模型的 Hermite 正交基前向神经网络算法的并行化处理流程图
MapReduce框架可以将算法并行处理,而Hermite算法中的数据块可以单独处理并且执行其工作。所以可以将两者结合。
4 结合 MapReduce 并行化模式下融合算法的步骤
(1)离散数据。首先收集大量的相关数据。如果收集的数据为连续数据,则先将数据离散化;如果收集的数据为离散数据,则不用做处理。


利用多个设备在一定时间内的收集的数据为矩阵:
(3)根据MapReduce与 Hermite 正交基前向神经网络算法相结合的网络并行化算法进行训练预测。
5 实验结果
这个实验就是基于对比上述MapReduce 与 Hermite相结合算法和BP算法神经网络算法产生的结果,通过对功率预测的准确度比较的仿真实验,利用MapReduce 与 Hermite相结合算法预测结果的曲线与BP算法的预测结果曲线及实际功率的曲线进行对比。
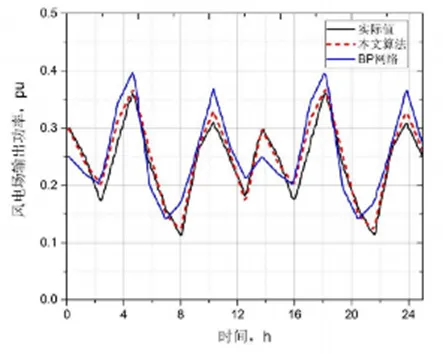
图5 不同算法下风电场功率预测对比
从上面的三条曲线可以看出,MapReduce和Hermite相结合的算法所预测的结果与实际结果更接近,这是因为Hermite算法隐含层神经元的激励函数是正交多项式,一步就可以计算出神经网络连接最优的权值,这保留了初始数据的信息特征,使算法预测得结果更接近实际值。
还可以通过计算误差,对两种算法进行比较,表1为两种算法的误差。

表1 两种算法标准误差对比
6 结论
结合本文,可以得出新融合算法的优势:
(1)新融合算法在步骤上进行了简化,提高了算法的工作效率,并且将误差缩小,更易于在硬件上实现。
(2)根据 MapReduce 模型,将算法并行,改进后的算法比传统方法更易于处理大数据[8]。
本文介绍了一种处理电力系统大数据的平台结构,总结了其功能和必要的技术支持,并监控数据,可以为各种需求提供服务。
[1]刘青松,钱苏翔,严拱标.基于多传感器的信息数据融合技术在电力系统中的应用[J].微计算机信息,2006(31):191-193.
[2]朱付保,徐显景,霍晓齐,等.多源数据融合技术在后备干部管理系统中的应用[J].微型电脑应用,2014,30(01):10-12.
[3]肖慧灵.基于信息融合的港机健康诊断研究[J].中国设备工程,2021(10):162-163.
[4]李翀,刘林青,陶鹏,等.基于多源数据融合技术的输电线路故障定位方法[J].水电能源科学,2021,39(01):168-170+210.
[5]万磊,陈洪胜,王晓婷,等.面向电力大数据的多源异构数据融合技术研究[J].电子技术与软件工程,2021(02):172-173.
[6]江友华,易罡,黄荣昌,等.基于多源信息融合的变压器检测与评估技术[J].上海电力大学学报,2020,36(05):481-485.
[7]林瑀,陈日成,金涛.面向复杂信息系统的多源异构数据融合技术[J].中国测试,2020,46(07):1-7+23.
[8]Jitendra R. Raol Data Fusion Mathematics:Theory and Practice[B].CRC Press,2015.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
现代装饰(2018年5期)2018-05-26
自动化学报(2017年7期)2017-04-18
中国工程咨询(2017年5期)2017-01-31
现代电子技术(2016年15期)2016-12-01
能源(2016年1期)2016-12-01
能源(2016年10期)2016-02-28
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
