
基于XGBoost算法的共享单车借车需求量预测
2021-12-24 02:17徐良杰朱然博罗浩顺陈国俊
武汉理工大学学报(交通科学与工程版) 2021年5期
李 福 徐良杰 朱然博 罗浩顺 陈国俊
(武汉理工大学交通学院1) 武汉 430063) (湖北文理学院汽车与交通工程学院2) 襄阳 441053)
0 引 言
共享单车的出现有效地弥补了公共交通难以实现“最后一公里”的出行的不足,为城市居民的出行提供了极大的便捷.共享单车快速发展的同时也带来了一系列的问题,其中最为严重的是用户乱停乱放和部分地点单车堆积,造成后者出现的主要原因是区域内的共享单车供需的不平衡[1].通过对共享单车用户的借车需求量的精准预测,有助于实现共享单车的供给与用户需求的相匹配.
共享单车兴起时,武汉市交通发展战略研究院根据活跃度对武汉市的共享单车的需求总量进行了预估,精度较低.当前共享单车的需求预测的研究大多采用机器学习的方法.宋鹏等[2]通过主成分分析法对数据进行降维,验证了基于径向基核函数支持向量机对共享单车需求的预测具有较好的效果,平方相关系数可达到0.968.曹旦旦等[3]为了准确预测每小时的共享单车的使用需求,采用长短期记忆神经网络模型对纽约市Citi Bike共享单车的需求量进行了预测.种颖珊等[4]基于随机森林和时空聚类对美国湾区的共享单车的需求量进行了预测.国外共享单车的运营模式虽然与国内的存在一定的差异,但关于共享单车的需求预测的研究仍具有参考价值.Campbell等[5]采用最小二乘法、线性模型等多种方法对单车需求量进行预测.Xu等[6]采用深度学习和大数据的方法.Pan等[7]采用了递归神经网络模型.Almannaa等[8]分别采用机器学习中不同模型的进行了预测.
综上所述,机器学习算法被广泛运用于共享单车的需求量的预测.但所预测的对象大多是某个城市或片区的整体用户的使用需求,对某个站点的使用需求涉及较少,研究重点往往放在了大数据的降维、消噪等处理步骤上,而忽略了对共享单车用户的使用需求的影响因素的分析.因此,文中基于XGBoost的机器学习算法,通过纽约市的Citi Bike共享单车用户的历史订单数据,分析影响用户的使用需求的主要因素,由此建立基于机器学习的预测模型,最后以北京市摩拜单车的用户订单数据为例,对具体站点的共享单车的借车需求量进行预测,验证预测方法的可行性.
1 XGBoost算法
极端梯度推进决策树(extreme gradient boosting tree, XGBoost)是一种基于决策树的集成机器学习算法,使用梯度上升框架,在GBDT(gradient boosting decision tree)算法基础上改进而来,适用于分类和回归问题.XGBoost在传统Boosting的基础上,引入正则化项的逻辑回归和线性回归,对代价函数做了二阶Talor展开,能自动学习分裂方向且支持列抽样,防止过拟合.上述优点使得XGBoost成为各类回归预测中的较为合适手段[9],其预测模型为
(1)

损失函数为
(2)
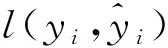
XGBoost将模型上次预测(由t-1棵树组合而成的模型)产生的误差作为参考进行下一棵树(第t棵树)的建立.当往模型中加入第t棵树时,预测结果为
(3)
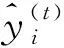
(4)
对于目标损失函数中的正则项部分,第t棵决策树的正则项为
(5)
式中:wj为第j个树子节点的得分值;T为数的子节点的个数.
用泰勒展开式来近似原来的损失函数.
(6)
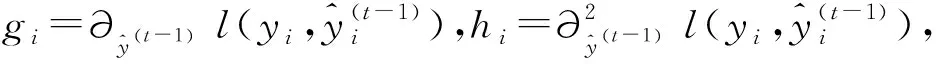
(7)
对wj求偏导,使其导函数为0,则有:
(8)
则预测模型的目标函数为
(9)
2 需求影响因素分析
2.1 数据概况
当前开源的且齐全的共享单车大数据为纽约市某区域的Citi Bike的用户订单数据,原始数据集记录了24个月的用户每小时借车数量,包含时间、季节、节假日、工作日、天气、实际温度、体感温度、相对湿度、风速等数据.采用Python工具包读取数据集,删除其中的缺失值与异常值后,共17 357条数据.
2.2 因素分析
对数据归一化后,分析时间、季节、节假日、工作日、天气、实际温度、体感温度、相对湿度、风速等环境因素对用户借车数的影响.其中温度、相对湿度与风速为连续变化特征,通过不同的温度、相对湿度与风速下的共享单车的借车数量的分布,分析上述因素与借车数间的相关性;不同实际温度、体感温度、相对湿度、风速的下的每小时的共享单车借车数量分布见图1.
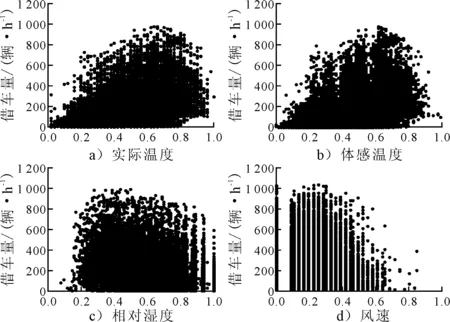
图1 不同连续变化特征下共享单车借车数量分布
由图1可知:在气温较低时,随着气温的升高,共享单车的借车数量增加,当气温较高时,随着气温的上升,共享单车的借车数量减少.同时,共享单车的借车数量在不同的实际温度与体感温度下的分布相似,则两个因素对共享单车的借车数的影响机理相同,单一的因素即可反应气温对借车数的影响.共享单车用户的借车集中分布在相对湿度为0.2~0.9的范围内,且在该范围内共享单车的借车数量变化不显著.随着风速的上升,共享单车的借车数量减少.因此,气温、风速与共享单车的借车数量之间存在着相关性,相对湿度变化与不影响共享单车的借车数量.
时间、季节、节假日、工作日与天气为离散特征,不具有连续性,则采用统计分析的方式分析是否具有相关性.每日不同时间、1周不同时间、不同季节、不同天气下的每小时的共享单车借车数量见图2.
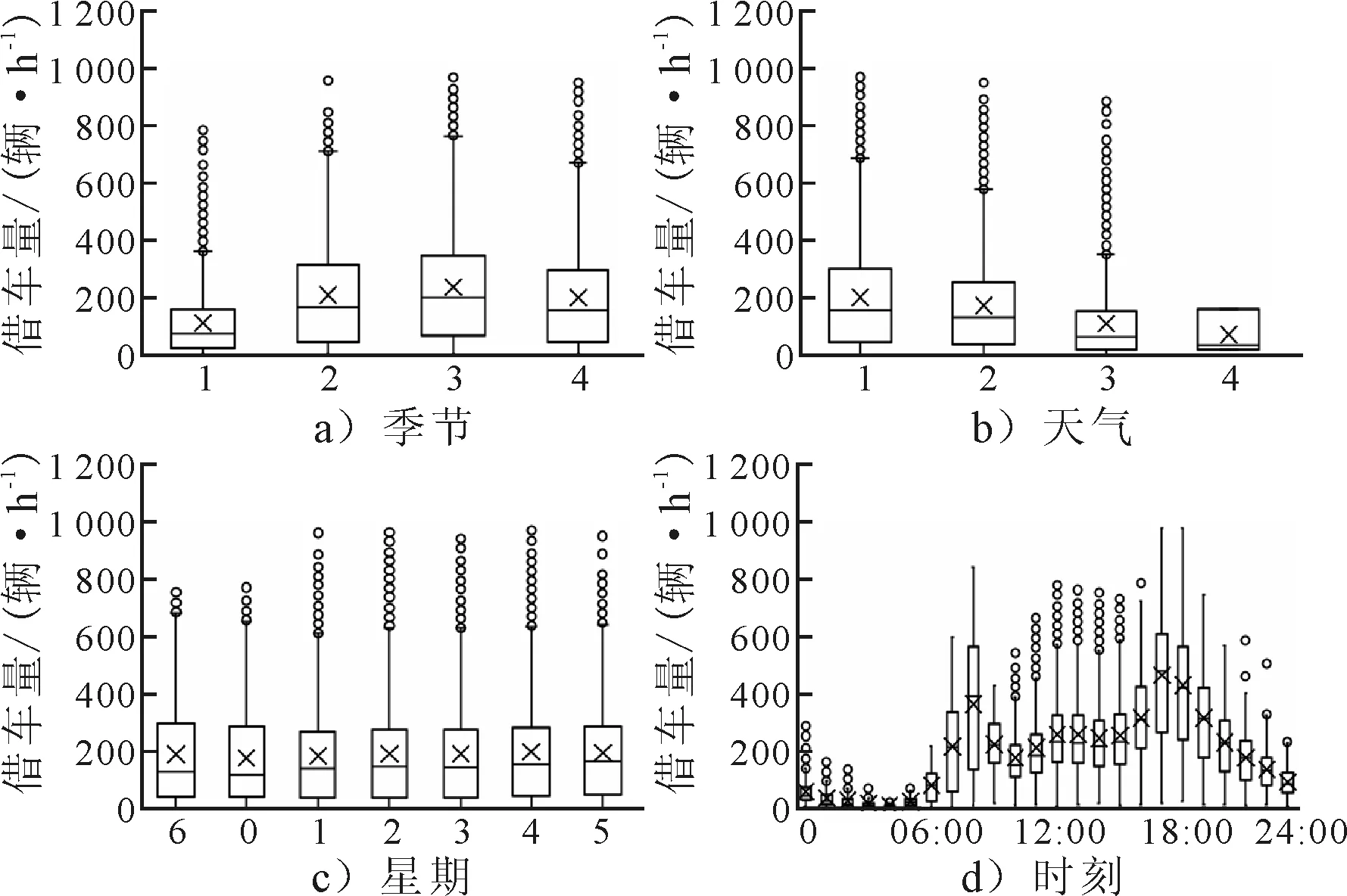
图2 不同离散变化特征下共享单车借车数量分布
由图2可知,共享单车的借车数量在1 d内有着较为明显的波动,呈现明显的早晚高峰;周一周日的平均每小时的用户借车量的分布相近,但周一到周五的借车量的极大值均显著大于周六与周日,而上四分位数低于周六与周日,1周内星期的变化仍会影响共享单车用户的借车需求;在1年内,春季的借车量最小,秋季最大;天气的变化对于共享单车的借车数量的影响较为显著,用户的借车需求大多发生在晴天和阴天,雨雪及恶劣天气的需求量极少;同时统计发现,工作日的平均每天借车量为4 592辆,非工作日为4 330辆.因此,每日时间、1周时间、季节、天气均与每小时的共享单车的借车数量之间存在着相关性.
3 共享单车借车需求量预测
3.1 聚集区划分
选用北京市摩拜单车的用户历史骑行订单数据,采用均值漂移聚类算法,对用户的骑行起点进行聚类.算法的均值漂移向量mh(x)为
(10)
式中:h为滑动窗口半径;x为初始中心点;M为需聚类的所有点的集合;G(x)为核函数,常用为高斯核函数;,为点xi的权重值.此次研究中的用户骑行起讫点OD样本为二维空间数据,无需引入高斯核函数,且空间内每个分布点的选取权重相同,则均值漂移向量化简为
(11)
式中:mh为离中心点距离为h的空间内所有点的集合.选取滑动窗口半径为200 m,对北京市部分区域的摩拜单车的用户骑行起点进行聚类.
3.2 数据预处理
北京市摩拜单车的用户订单数据集记录了用户的租借车的时间和位置信息,以每小时为时间间隔,统计各个聚集区的每小时的用户借车数量.消除数据集中无效和波动异常的数据.常用的数据去噪方法有K-近邻替换法、局部加权替换法、有序最近邻替换法、均值法等,由于共享单车的借车量在1 d内存在明显的早晚高峰,且峰值持续时间较短,每小时的借车量存在较大波动,见图3a).因此,采用上述降噪方法对数据消噪时,受前后数据的影响,数据中的极值容易受到削减而失去数据集的原有特征.
图3a)中的用户借车数量具有明显的周期变化的特征,该类型数据常用小波变换进行降噪.小波变换是时间(空间)频率的局部化分析,它通过伸缩平移运算对信号逐步进行多尺度细化,最终达到高频处时间细分,低频处频率细分,能自动适应时频信号分析的要求,从而可聚焦到信号的任意细节,适用于分析非平稳的周期性信号,如心电图、音频信号等,提取信号的局部特征.采用小波变换降噪对数据进行预处理,消除异常的噪声值,突显用户需求量的整体趋势,降噪后的摩拜单车用户借车数量见图3b).
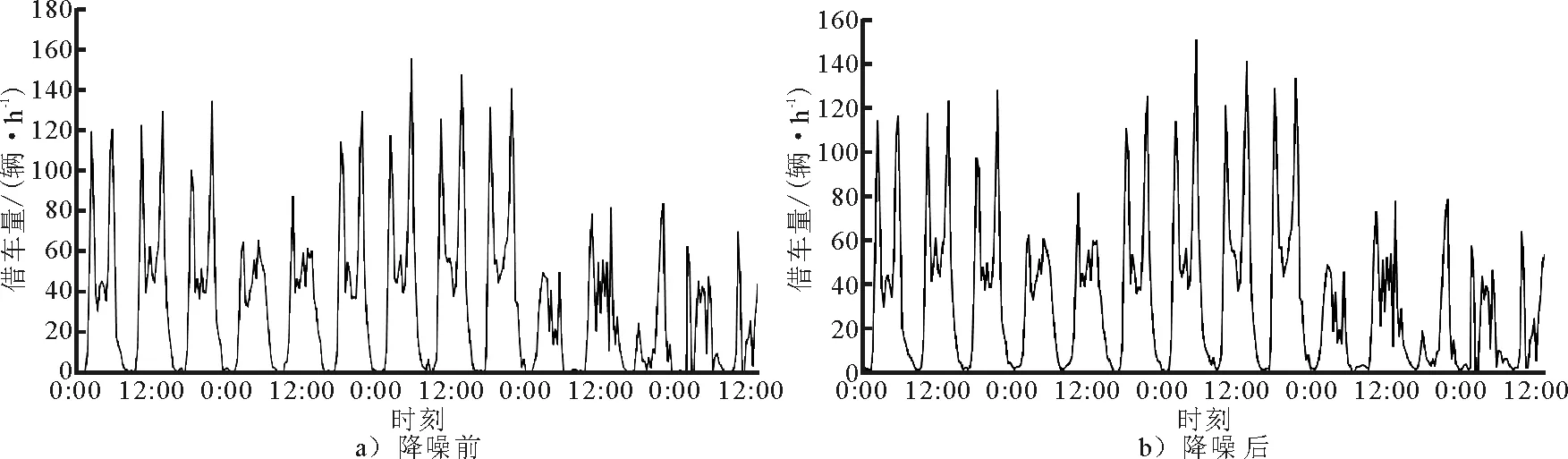
图3 北京市某区域的14日的摩拜单车用户借车数量
进行根据上述的因素分析中的对共享单车的借车需求量存在相关性的环境特征,选取气温、风速、天气、小时、星期、季节、工作日与否为影响因素,查询中国气象网获取当日的北京市天气数据.数据集的时间跨度较短,因此不考虑季节对于借车需求量的影响.由于不同影响因素的数据属性之间的量级不同,量级大的数据属性会对预测模型产生大的影响而掩盖了其他影响因素对于借车需求量的影响,不符合实际情况,因此需要统一各属性量级.采用离差标准化对数据集进行归一化处理,处理方法为
(12)
3.3 预测结果
将预处理后的用户订单数据集分为训练集与测试集两部分,使用Python中的sklearn工具包构建预测模型,调整模型参数后,利用XGBoost模型对北京市分钟寺和公益西桥区域的5月10日(周三)和5月14日(周日)的每小时的用户借车数量进行预测,预测结果见图4.
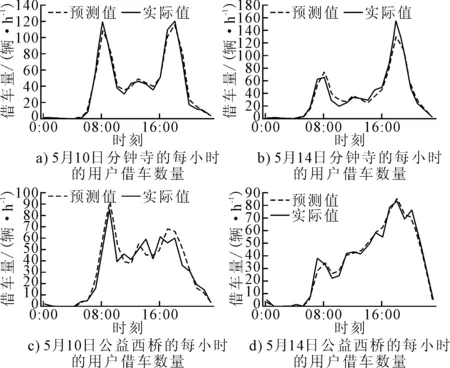
图4 共享单车借车需求量预测结果
由图4可知,使用气温、风速、天气、小时、星期、季节、工作日与否为影响因素,对某区域的共享单车用户的每小时的借车需求量有着较好的预测效果,且对于不同区域以及工作日和非工作日均能进行有效的预测.同时使用支持向量机SVM中的linear核函数、poly核函数、rbf核函数和sigmoid核函数对用户的借车需求量进行预测,使用平均绝对误差MAE和平方相关系数R2并用数据集中的实际数据进行模型的预测精度评估.平均绝对误差MAE和R2的计算方法为
(13)
(14)
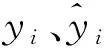
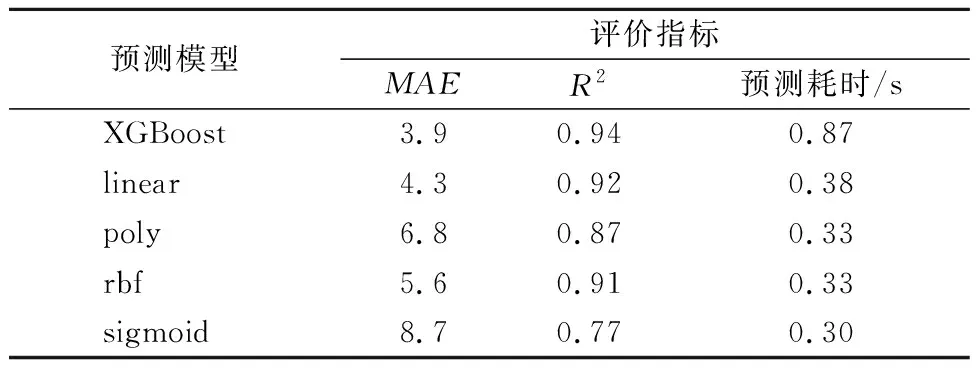
表1 不同预测模型的预测效果
由表1可知,使用XGBoost预测模型的对共享单车用户的借车需求量的进行预测,其预测结果的平均绝对误差最小,为3.9,平方相关系数可达到0.94;在SVM预测模型中,使用linear核函数的预测效果最好,平均绝对误差为4.3,平方相关系数为0.92,但仍低于XGBoost预测模型的预测效果.在预测耗时方面,使用XGBoost预测模型的预测时长最大,为0.87 s,使用SVM预测模型中不同核函数的用时均低于XGBoost预测模型.在进行整个北京市的共享单车需求量预测时,由于数据量巨大,因此在选择预测模型时对模型的预测耗时有着一定的要求,针对某具体区域进行共享单车的借车需求量预测时,数据量较小,则更看重预测模型的预测精度.因此,使用XGBoost预测模型可以较好进行具体区域的共享单车的借车需求量预测,且预测精度较linear核函数、poly核函数、rbf核函数和sigmoid核函数的SVM预测模型的预测精度更高.
4 结 束 语
文中提出了一种基于极端梯度推进决策树(XGBoost)算法的共享单车的借车需求量的预测方法,通过对纽约市的Citi Bike共享单车用户的历史订单数据的处理挖掘,分析发现,在众多的影响素中,气温、风速、天气、每日时间、1周时间、季节与共享单车的借车数量之间存在着相关性.以北京市的摩拜单车为例,对其用户的历史骑行订单数据,采用均值漂移聚类算法划分用户骑行的聚集区,对数据进行降噪和归一化处理后,对北京市分钟寺和公益西桥区域的用户借车需求量进行预测,平均绝对误差为3.9,平方相关系数可达到0.94,相比SVM预测模型预测精度更高.结果表明,使用XGBoost算法结合天气和时间因素以及历史数据,可实现对某区域的每小时的共享单车用户借车量的有效预测.
通过XGBoost算法构建的预测模型在预测精度方面优于SVM预测模型,但在预测耗时上存在不足,因此当所需预测的区域的数量较大时,论文所提出的预测模型的预测耗时较长.论文中所使用的数据集为用户的骑行订单数量,未涉及共享单车的实时分布数据,忽略了共享单车的供给对于用户骑行需求的影响,因此预测结果与用户的实际需求存在一定的偏差,相关研究可在下一阶段进一步展开.
猜你喜欢
意林彩版(2022年1期)2022-05-03
数学大王·中高年级(2021年6期)2021-09-27
读友·少年文学(清雅版)(2020年1期)2020-05-20
当代水产(2020年2期)2020-03-17
汽车与驾驶维修(汽车版)(2017年1期)2017-10-30
中国公共安全(2017年5期)2017-09-04
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20
汽车与驾驶维修(汽车版)(2017年1期)2017-02-22
棋艺(2016年6期)2016-11-14
