
Positive unlabeled named entity recognition with multi-granularity linguistic information①
2022-01-09 02:08OuyangXiaoye欧阳小叶ChenShudongWangRong
High Technology Letters 2021年4期
Ouyang Xiaoye(欧阳小叶),Chen Shudong②,Wang Rong
(*Institute of Microelectronics,Chinese Academy of Sciences,Beijing 100029,P.R.China)
(**University of Chinese Academy of Sciences,Beijing 100049,P.R.China)
(***Key Laboratory of Space Object Measurement Department,Beijing Institute of Tracking and Telecommunications Technology,Beijing 100094,P.R.China)
Abstract
Key words:named entity recognition(NER),deep learning,neural network,positive-unlabeled learning,label-few domain,multi-granularity(PU)
0 Introductio n
Named entity recognition(NER)refers to the task of recognizing named entities in text and classifying them into specified types[1].NER is also a foundation task in natural language processing(NLP),and supports downstream applications such as relation extraction[2],translation[3],question and answer[4].At present,traditional methods based on supervised learning use a large amount of high-quality labeled data for NER[5].However,neural NER typically requires a large amount of manually labeled training data,which are not always available in label-few domain,such as biological/medical/military. Training neural NER with limited labeled data can be very challenging[6-7].
Researchers have investigated a wide variety of methods and resources to boost the performance of label-few domain NER,e.g.,annotation learning and reinforcement learning[8],domain-adaptive fine-tuning[9],a fully Bayesian approach to aggregate multiple sequential annotations[10], adversarial transfer network[11],joint sentence and token learning[12],weak supervision to bootstrap NER[13].Wheras most of the previous studies have injected expert knowledge into the sequence labelling model,which is often critical when data is scarce or non-existent.This work presents a positive unlabeled learning approach,which is positive unlabeled named entity recognition(PUNER),using some positive instances and multi-granularity linguistic information to automatically annotate all unlabeled instances.Positive unlabeled(PU)learning refers to learning a classifier through unlabeled instances and positive instances,classifying unlabeled instances by this classifier,and finally making all unlabeled instances into annotation instances[14-15].PUNER solves the problem of a large amount of unlabeled data in the label-few domain by PU learning,and effectively parses rich semantic information to identify correct named entities through multi-granular language information.
This paper has the following three contributions.(1)Designed a novel algorithm PUNER,which continuously iterates the unlabeled data through the PU learning method,and combines the neural networkbased PU classifier to identify all named entities and their types in the unlabeled data.(2)In PU classifier,there is a multi-granularity language information acquisition module,which integrates multi-granularity embedding of characters,words,and sentences to obtain rich language semantics in the context and helps to understand the meaning of sentences.(3)The experimental results show that PUNER is 1.51%higher than the most advanced AdaPU algorithm on the three multilingual NER data sets,and the performance of PUNER on SIGHAN Bakeoff 2006 is higher than that on CoNLL 2003 and CoNLL 2002 due to the different number of training set.
1 Related work
1.1 Named entity recognition
The NER usually adopts a supervised learning approach that uses a labeled dataset to train the model.In recent years,neural network has become the mainstream of NER[16-17],which achieves most advanced performance.Many works use the long short-term memory(LSTM)and conditional random field(CRF)architecture.Ref.[18]further extended it into bidirectional LSTM-convolutional neural networks(CNNs)-CRF architecture,where the CRF module was added to optimize the output label sequence.Ref.[19]proposed task-aware neural language model(LM)termed LM-LSTM-CRF,where character-aware neural language models were incorporated to extract character-level embedding under a multi-task framework.
1.2 Label-few domain NER
The aim of label-few domain modelling is to reduce the need for hand annotated data in supervised training.A popular method is distant supervision,which relies on external resources such as knowledge bases to automatically label documents with entities that are known to belong to a specific category.Ref.[8]utilized the data generated by distant supervision to perform new type named entity recognition in new domains.The instance selector is based on reinforcement learning and obtains the feedback reward,aiming at choosing positive sentences to reduce the effect of noisy annotation.Ref.[9]proposed domainadaptive fine-tuning,where contextualized embeddings are first fine-tuned to both the source and target domains with a language modelling loss and subsequently fine-tuned to source domain labelled data.Refs[20,21]generalized this approach with the Snorkel framework which combines various supervision sources using a generative model to estimate the accuracy of each source.Ref.[22]presented a distant supervision approach to NER in the biomedical domain.
1.3 Positive unlabeled learning NER
PU learning is a distant supervision method,which can be regarded as a special classification task,that is,learning how to train a classifier with a small number of positive instances and many unlabeled instances.AdaSampling[23]first randomly selects a part of the unlabeled instances as the negative instances for training,then the process of sampling,modeling,and prediction is repeated for each iteration,and final predicted probability uses the average of theTiterations as the probability of the final prediction.Ref.[24]proposed the unbiased positive-unlabeled learning,and Ref.[25]adopted a bounded non-negative positiveunlabeled learning.Ref.[10]proposed a fully Bayesian approach to the problem of aggregating multiple sequential annotations, using variational expectationmaximization(EM)algorithm to compute posterior distributions over the model parameters.Ref.[13]relied on a broad spectrum of labelling functions to automatically annotate texts from the target domain.These annotations are then merged using a hidden Markov model which captures the varying accuracies and confusions of the labelling functions.
For the label-few domain NER,the PU learning method can solve the problem of only a small amount of labeled data and a large amount of unlabeled data.At the same time,combining the neural network model to realize the PU classifier can obtain multi-granular sentence semantic information and identify named entities.Therefore,a novel PUNER algorithm is adopted,which applies PU learning with multi-granular language information to perform NER in the label-few domain.
2 The proposed PUNER algorithm
2.1 Problem formalization
PU learning can be regarded as a special form of two-class(positive and negative)classification methods,when there are only given a set of positive instancesPand a set of unlabeled instances that contains both positive and negative instances.This work uses the binary labeling mechanism for NER tasks,rather than the mainstream B-begin I-inside O-outside(BIO)or B-begin I-inside O-outside E-end S-single(BIOES)mechanism.This is because the defect of positive instances affects the accuracy of BIO or BIOES mechanism labeling,and the binary labeling mechanism can avoid this effect well.Therefore,the NER task here can be regarded as a binary classification task.

2.2 Algorithm overview
The algorithm of the novel PU learning is shown in Algorithm 1,which is inspired by Ref.[26].It is a two-step approach,first selecting reliable negative instances from the unlabeled datasetU,then using the positive instances and reliable negative instances to train a classification model for new instances prediction.

Algorithm 1 PUNER Algorithm Data:Positive dataset P and unlabeled dataset U Result:Predicted classification of all instances y∈{0,1}1. T0←P;//the initial positive training data;2. S0⊂U;//treat all unlabeled instances in U as negative instances,get S0 as initial negative training data;3. g1 ner←PULe Classifier(P,S0)//PU learning classifier g1 ner using「P,y=1■∪「S0,y=0■as the initial training dataset;4. UL1←g1ner(U)//use g1 ner to classify unlabeled data U,then get the labeled data UL1;5. S1←extract Negatives(UL1)//get negative instances from the labeled data UL1;6. RN1←S0;//get the initial set of reliable negative instances RN1;7. S1←S0;8. T1←P;9. while(|Si|≤|Si-1|and|P|⊂|Ti|)do:10. i←i+1 11. giner←PULe Classifier(P,RNi-1)12. UL i←gi ner(U)13. RNi←extract Negatives(UL i)14. Ti←extract Positives(UL i)15. return(giner)//use gi ner as the final classifier.
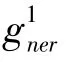
In this paper,the PU learning classifiergneris a neural-network-based architecture with multi-granularity linguistic information used to recognize named entities and their types,and the specific introduction ofgneris shown in the next section.
2.3 PU learning classifier gner
In this section,a neural-network-based architecture is adopted to implement PU learning classifiergner,and this architecture is shared by different entity types,as shown in Fig.1.
2.3.1 Multi-granularity word processor
In this module,word processor semantically extracts meaningful word representation from different granularities,i.e.,the character-granularity representationec(w), the word-granularity representationew(w),and the sentence-granularity representationes(w).
For the wordwin the sentences,the convolution network[27]is used for the char-granularity representationec(w)ofw,the fine-tuned Stanford’s GloVe word embeddings tool[28]for the word-granularity representationew(w)ofw,and the fine-tuned Bert embedding tool[17]for the sentence-granularity representationes(w)ofw.The final word presentation is obtained by concatenating these three parts of embeddings:

where,⊕denotes the concatenation operation.Thus,a sequence of word vector{vt}is got.

Fig.1 Architecture of PU learning classifier
The word vector is obtained through the concatenation of multi-granularity linguistic information,that is to obtain multi-granularity features such as char,words,and sentences,and cooperate with the task model.Specifically,this work first uses CNN to generate char-level embedding,GloVe to generate word-level embedding,and Bert to generate sentence-level embedding,and then concatenates the three granular embeddings to obtain a more comprehensive and rich language semantics in the context,which further helps understanding the meaning of the sentence.Finally,it is more effective to cooperate with the upper sentence processor module.
2.3.2 Sentence processor
Based on the word vector{vt},the sentence processor employs a layer of gated recurrent unit(GRU)[29]to learn the contextual information of the sentence,which uses a hidden state vector{ht}to remember important signal.At each step,a new hidden state is computed based on previous hidden state using the same function.

where,ztandrtare an update gate and a reset gate,σ(·)is a sigmoid function,Wz,Wr,Wh,Uz,UrandUhare parameters.e(wk/s)is the representation ofwkgivens.
2.3.3 Entity recognition classifier
The sentence representatione(w/s)is taken as the entity detection classifier’s input,and the probability of the positive classf(w/s)is defined as
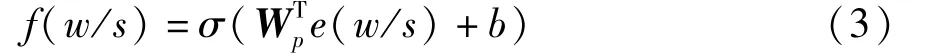

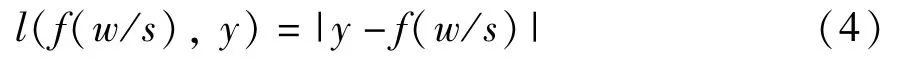
The cross-entropy loss function to learn a betterf(w/s)is minimized and defined as

After training,PU classifier is used to perform label prediction.However,since a distinct classifier for each entity type is established,the type with the highest prediction probability(evaluated byf(w/s))is chosen.The predictions of other classifiers will be reset to 0.For sentences={w1,w2,w3,w4,w5,w6},if the label predicted by the classifier of a given type isL={0,1,0,0,1,1},then consider{w2}and{w5,w6}as two entities of the type.
3 Experiments
In order to demonstrate the performance and adaptability of the algorithm,several methods on three multilingual datasets are compared and details of the implementation and analysis of the experimental results are given.
3.1 Compared methods
Six methods are chosen to compare their performance with the proposed PUNER.The first four are supervised learning methods,which are Stanford NER(MEMM)[30]adds jump features between observation sequences,Stanford NER(CRF)[31]uses global normalization,BiLSTM[32]is combined by forward LSTM and backward LSTM,BiLSTM+CRF[32]uses the BiLSTM as baseline,and learn an optimal path by CRF in the last layer.The last two are applied to the label-few domain,Matching directly uses the constructed named entity positive instances to label the testing set,Ada-PU[33]is an adapted PU learning algorithm for NER.
In addition,the partial structure of PUNER is also changed,and the performance of three variations of the proposed MGNER is compared.PUNERELMOuses ELMo[16]to do sentence embedding instead of Bert;PUNERbiLSTMreplaces GRU with BiLSTM neural network;andPUNERatt-implements entity processor module without attention mechanism.
3.2 Data sets
PUNER is evaluated on CoNLL 2003[34],CoNLL 2002[35]and SIGHAN Bakeoff 2006[36].The corpora statistics of the three datasets are shown in Table 1.These three datasets are labeled with four types,person(PER),location(LOC),organization(ORG),and miscellaneous(MISC),and the training set(TRAIN),development set(DEV)and testing set(TEST)are officially segmented.
CoNLL2003 is an English dataset, collected from Reuters.There are four types of entities in this data set,namely PER,LOC,ORG,and MISC.The official split training set is used for model training,testa is used for development and testb is used for testing in the experiments,which contains 23 407,5918 and 5620 entities,respectively.Besides,there are about 45.6 k additional unlabeled entities.
CoNLL2002 is a Spanish NER dataset,collected from Spanish EFE News Agency.It is also annotated by PER,LOC,ORG,and MISC types.The esp.train set is used for model training,esp.testa is used for development set and esp.testb is used for testing in the experiments.The TRAIN,DEV and TEST data sets contain 18 752,4324 and 3551 entities,respectively.
SIGHAN Bakeoff 2006 is a Chinese dataset using multiple data sets provided by different institutions for evaluation.This dataset is also labeled with four types,PER,LOC,ORG,and MISC.It has about 32 317 entities in the training set(ner.train),3667 entities in development set(ner.dev)and 7403 entities in the testing set(ner.test).
For the qualification of the label-few domain NER,each training set of the dataset is used for training.And it should be noted that the data annotation information during training is not used.The method of building named entity dictionary given in Ref.[33]is used to construct positive instances.For CoNLL2003,most popular and common names of person,location and organizations from Wikipedia are collected to construct the dictionary.For CoNLL2002,Google translator is used to translate the English PER,LOC,ORG,MISC dictionary into Spanish.And for SIGHAN Bakeoff 2006,a dictionary based on Baidu Baike is built.
3.3 Implementation details
If the comparison methods and PUNER method are all in the identical experimental environment,the results of these experiments will be copied directly,otherwise the methods will be reproduced in the context of this paper.

Table 1 Corpora statistics for the CoNLL(en),CoNLL(sp)and Bakeoff(ch)datasets
The proposed algorithm is implemented using Pytorch libraries.A random search[37]is used for superparameter optimization,and the best performance setting is chosen as the final setting.In this experiment,the Adam optimizer with the learning rate decay is applied.The learning rate starts from 0.001 and begins to decrease by 0.9.The batch size is set to 20.The word presentation consists of three parts,pretrained GloVe word embedding,sentence Bert embedding,along with a randomly initialized training CNN encoder for character embeddings.And the dimensionality of word embedding is set as 300.In order to prevent over-fitting,all the GRU layers dropout rates are set to 0.4.Besides,the positive instances in the PU learning algorithm are selected following previous work[33].
3.4 Results
Experiment results on the CoNLL 2003,CoNLL 2002 and SIGHAN Bakeoff 2006 datasets are shown in Table 2.As can be seen from Table 2(2),among the methods applied in label-few domain,performance of the proposed PUNER is better than others on three different datasets.PUNER achieves excellent results in label-few domain.
The last set of methods shown in Table 2(2)are deformations of the proposed PUNER.By using Bert for embedding instead of ELMo,it increasesF1 score 1.4%on the CoNLL(en)dataset,1.3%on the CoNLL(sp)dataset and 0.8%on the Bakeoff(ch)dataset.Choosing GRU to extract semantics instead of BiLSTM,F1 score is improved by 0.8%on the CoNLL(en)dataset,0.3%on the CoNLL(sp)dataset and 0.7% on the Bakeoff(ch)dataset.The attention mechanism improvesF1 score by 1.2%on the CoNLL(en)dataset,0.8%on the CoNLL(sp)dataset and 1%on the Bakeoff(ch)dataset.The initial multigranularity linguistic information of word embedding has important effect on subsequent tasks,and at the same time,the attention mechanism also significantly helps to extract important semantics.

Table 2 F1 scores on CoNLL(en),CoNLL(sp)and Bakeoff(ch)testing set for NER
Analyzing different performance results of these three datasets,the ranking ofF1 value on the three data sets are Bakeoff(ch),CoNLL(en)and CoNLL(sp).F1 score on the Chinese dataset is 0.54%higher than English dataset and 7.78%higher than Spanish dataset.Considering the data set analysis information provided in Table 1,it is believed that the performance difference between different data sets is mainly caused by the difference in the number of sentences and entities.Specifically,the number of Bakeoff(ch)sets is larger than that of CoNLL(en)and CoNLL(sp),and the number of data sets directly affects the effect of model training.From the experimental results,F1 score on the CoNLL(sp)is the worst.This may also be caused by the low quality of the positive instances of CoNLL(sp),because the Spanish positive samples are translated from the positive instances of CoNLL(en).The translation process may produce noise data,which affects accuracy.
Moreover,compared with the previous AdaPU,the performance of the proposed method is improved,because the combined use of Bert,GRU neural network and attention mechanism can improve the semantic understanding of context.However,compared with Table 2(1),the performance of PUNER is still worse than that of supervised learning.
Experiments are conducted on three datasets,using different sizes of training sets to train the model,and studying the impact onF1 values.On three data sets,20%,40%,50%,60%,80%,and 100%training sets are selected for training PUNER,respectively.Fig.2 describes the results of this study on three datasets.It can be seen from Fig.2 that as the number of training sets increases,the overall performance of the model also increases,although there are fluctuations.Therefore,the amount of data has an impact on the performance of the model.Meanwhile,the performance of the supervised learning method BiLSTM+CRF in Fig.2 shows that the gap between supervised learning and unsupervised learning and research on unsupervised learning are also very meaningful.

Fig.2 F1 of PUNER on the testing set of CoNLL(en),CoNLL(sp)and Bakeoff(ch)datasets for training using different segmentation of the training dataset.The dotted line indicates the F1 value obtained by using the supervised learning method BiLSTM+CRF
4 Conclusion
A novel PUNER algorithm for label-few domain is proposed,which uses PU learning algorithm combined with deep learning method to obtain multi-granularity language information for NER task.In PUNER,PU learning uses the positive instances and many unlabeled instances to effectively solve the labeling problem.Meanwhile,the neural network-based architecture is used to implement the PU learning classifier,which obtains multi-granularity linguistic information and facilitates named entity labeling.Experimental results show that PUNER achieves excellent results in labelfew domain on three multilingual datasets.In future research,graph convolutional network will be considered to model richer sentence semantics.
猜你喜欢
故事作文·低年级(2021年2期)2021-02-04
故事作文·低年级(2021年2期)2021-02-04
作文大王·低年级(2020年12期)2020-12-31
今日农业(2020年20期)2020-11-26
中华诗词(2019年9期)2019-05-21
海峡姐妹(2019年1期)2019-03-23
思维与智慧·上半月(2018年4期)2018-04-09
小天使·四年级语数英综合(2017年7期)2017-08-04
美与时代·城市版(2016年9期)2016-05-14
人民交通(2009年2期)2009-03-04
 High Technology Letters2021年4期
High Technology Letters2021年4期
- High Technology Letters的其它文章
- On the performance of full-duplex non-orthonogal multiple access with energy harvesting over Nakagami-m fading channels①
- Research on optimization of virtual machine memory access based on NUMA architecture①
- Online prediction of EEG based on KRLST algorithm①
- Reconfigurable implementation ARP based on depth threshold in 3D-HEVC①
- Behavior recognition algorithm based on the improved R3D and LSTM network fusion①
- Performance analysis of blockchain for civil aviation business data based on M/G/1 queuing theory①