
术语抽取软件测评框架研究
2022-01-12 02:35王华树刘世界
中国科技术语 2022年1期
王华树 刘世界





摘 要:自然语言处理技术的飞速发展,使得术语抽取软件在翻譯、教育、语言学等领域成为不可或缺的资源,软件的种类也越来越多,可为用户提供不同的功能。然而,如何选择合适的软件成了亟待解决的问题。此研究参考ISO/IEC 25010: 2011和GB/T 2500.10—2016,从术语抽取软件的特性出发,选取功能适用性、兼容性、性能效率、易用性、信息安全性五个方面,探讨了术语抽取软件的动态化测评框架,并提出针对性的框架应用建议与应用案例,以期为用户选择恰当的术语抽取软件提供科学依据。
关键词:术语抽取软件;测评框架;术语管理;功能适用性;性能效率
中图分类号:TP391;H083 文献标识码:A DOI:10.12339/j.issn.1673-8578.2022.01.005
Evaluation Framework of Terminology Extraction Software//WANG Huashu, LIU Shijie
Abstract: The rapid development of natural language processing technology has made terminology extraction software (TES) an indispensable resource in translation, education, and linguistics, and there are more and more types of software that can provide users with different functions. However, how to choose an appropriate software has become an urgent problem. Referring to ISO/IEC 25010: 2011 and GB/T 2500.10—2016 standards, this study selects five aspects related to the characteristics of TES, such as functional suitability, compatibility, performance efficiency, usability, and information security, analyzes the dynamic evaluation framework of TES, and proposes recommendations and application cases for the framework to provide a scientific basis for users to choose an appropriate TES.
Keywords: terminology extraction software (TES); evaluation framework; terminology management;functional suitability; performance efficiency
引言
术语自动抽取(automatic term extraction, ATE)是一项从特定领域的语料库(domain-specific corpus)中提取术语的自然语言处理任务,抽取的方法主要包括基于词典、基于统计、基于语言规则、基于机器学习的方法及多种混合的方法[1]。近年来开发的自动术语抽取软件在各种应用场景中发挥着作用,例如术语筛选、同义词库构建、文档索引、技术监视及其本体开发[2],其抽取效率对术语库的构建、数据的挖掘、机器翻译词典的编撰、机器辅助翻译软件效率的提升等方面有着重要的意义,备受学界关注。
术语抽取软件的出现不仅提升了术语抽取效率,也在一定程度上避免了主观性和缺乏系统性的风险。然而,国内外术语抽取软件纷繁复杂,按照系统结构来划分,整体上可分为独立式和集成式两大类[3],其中独立式包含单机版与Web版,单机版如SDL MultiTerm Extract、SynchroTerm、TermSuite、Simple Extractor,Web版如Sketch Engine、Terminus、TermoStat、语帆术语宝(LingoSail TermBox);集成式也可称为非独立模块版,指依附于计算机辅助软件本体、无法单独使用的术语抽取模块,如Déjà Vu中的Lexicon、Anchovy、 memoQ中的术语抽取模块。面对如此繁杂的术语抽取软件,用户经常不知如何客观有效地去评价它们并选择满足自己需求的一款。此外,囿于术语抽取软件测评涉及自然语言处理、软件工程和计算模型构建等领域的知识,测评难度较大。虽已有部分学者对术语抽取软件测评框架进行过实验性的研究,但仍不够系统全面,得出的评测结果存在一定程度的主观性和片面性。
1 研究基础
在现有相关研究中, Sauron以及Perián-Pascual 和 Mairal-Usón的研究[4-5]被认为较具有代表性,其主要目的是超越指标性能测试的层面,为术语抽取软件的比较和测评设计一个全面的框架。Sauron基于ISO/IEC 9126-1: 2001和Expert Advisory Group on Language Engineering Standards(EAGLES)评估工作组的测评方法提出了一种测评术语抽取软件的标准化方法。Sauron从功能性(functionality)、可用性(usability)、可靠性(reliability)和效率(efficiency)4个特性(characteristic)着手,进一步将其分解为7个子特性(subcharacteristic),如准确性(accuracy)、互操作性(interoperability)、易学性(learnability)、可恢复性(recoverability)、适用性(suitability)、时间响应(time response)和可理解性(understandability)[4]。这种选择软件中可量化的质量属性来构建测评模型的方法,在一定程度上为用户提供了较为全面的参考。Perián-Pascual 和 Mairal-Usón同样遵循ISO/IEC 9126-1: 2001,自行设计了一个术语抽取软件的测评框架。两位学者提出的测评框架侧重于软件外部质量(external quality)标准,所以选取了ISO/IEC 9126-1: 2001中的功能性、可用性和效率3个特性,进一步细分为4个子特性:适用性、精确率(precision)、可操作性(operability)和时间特性(time behavior)。并通过实证研究,使用该框架测评对比了其团队自行研制的术语抽取软件(DEXTER)与其他3款开源型自动术语抽取软件[5]。两位学者的研究实验性地利用自行设计的框架测评了4种术语抽取工具的质量特性,打破了理论层面的探讨,为解释测评结果的方式提供了新见解。
然而,以上学者提出的测评框架并非系统全面的。Sauron在对属性(attribute)设定评分规则时表述欠妥。例如,Sauron提出,如果软件是“用户友好型”(user-friendly),评分记为5;如果软件“不是非常用户友好型”(not very user friendly),则评分记为2.5[4]。这里的“very”一词含有比较模糊的意味,对其解读因人而异,也就很难客观地衡量其“用户友好”的属性。此外,框架中设定的每个属性都被设定为3个标准,即“good”“acceptable”“unacceptable”,每个标准对应不同的分值[4],但是这种赋分和表态的方式得出的结果不能更好表达态度强弱,可靠性欠佳。以上两处存在明显缺陷,在Perián-Pascual 和Mairal-Usón的文献回顾部分[5]也曾明确提及,再次证实了Sauron的研究存在一定的局限性。Perián-Pascual 和Mairal-Usón两位学者在介绍选取特性时并没有结合术语抽取软件的特点进行深入的阐述,停留在ISO/IEC 9126-1: 2001中的宏观概念层面。此外,他们仅基于ISO/IEC 9126-1: 2001中的軟件外部质量标准选取了3个特性进行测评,在选取特性的客观性方面欠佳,未将内部质量(internal quality)和使用质量(quality in use)考虑在内,也未深入解释3个特性之间的关系。因此,通过计算模型得出的结论的准确性有待验证。
综上所述,发现相关研究的不足在于:选取的研究特性不全面,特性间的关联度不强,赋分规则设定不科学,概念的阐述脱离术语抽取软件的特点。因此,本研究兼顾术语抽取软件的功能性和非功能性特性,充分结合术语抽取软件的特点对所选取特性的概念进行详细阐述,采用动态化的科学评估方法,力求客观地为用户呈现一个全新的测评视角,提供一个兼具完善性和可操作性的动态测评框架。
2 测评框架构建
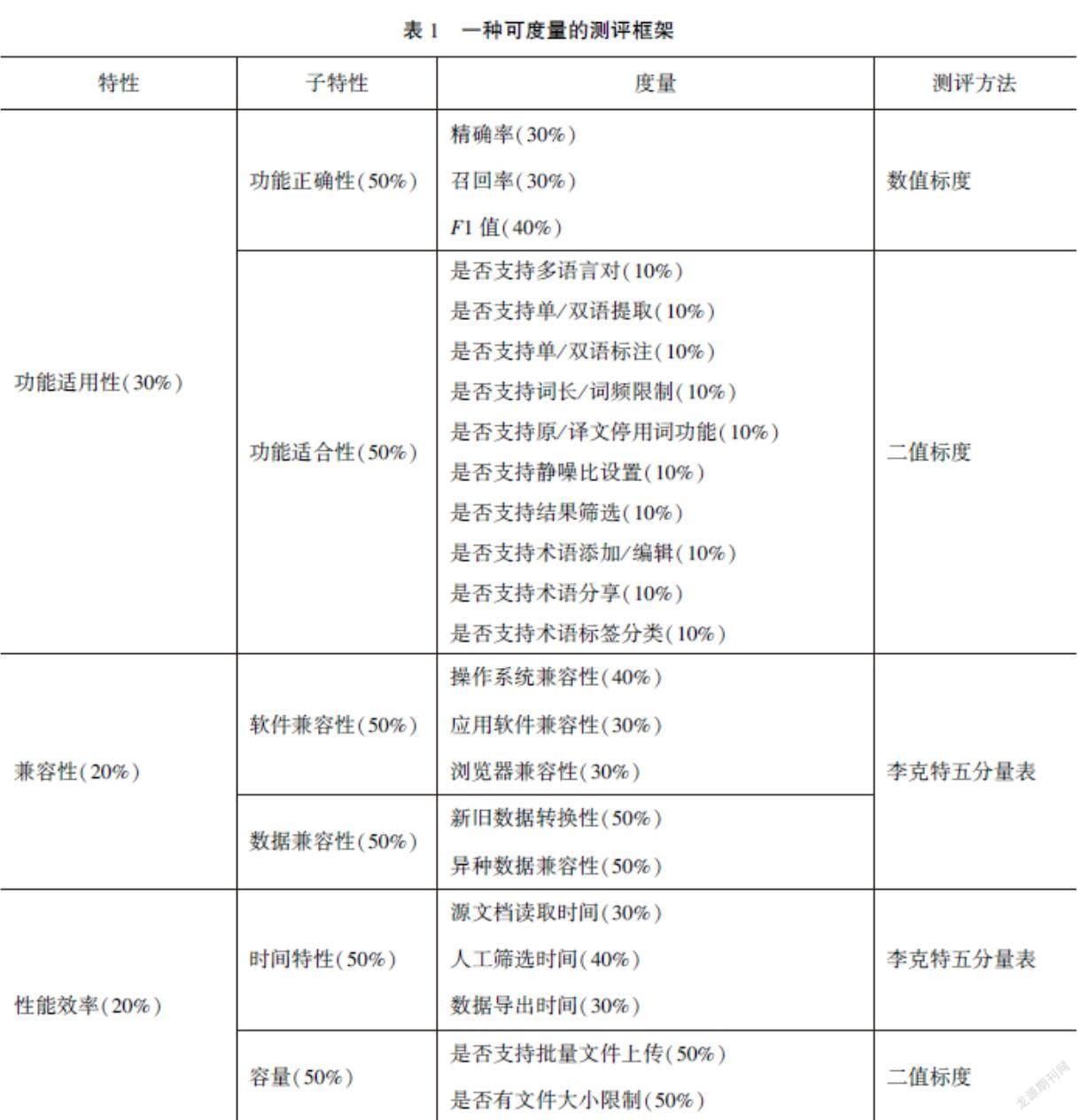
基于此,文章遵循ISO/IEC 25010: 2011[6],借鉴GB/T 2500. 10—2016[7]中的部分内容(如信息安全性),结合软件质量评价的三个部分和术语抽取软件的特性,设计了一个比较全面系统的动态测评框架(见图1)。该框架选取了功能适用性、兼容性、性能效率、易用性、信息安全性5个特性,进一步分解为功能正确性、功能适合性、软件兼容性、数据兼容性、时间特性、容量、易学性、用户界面舒适性、保密性、完整性、信息安全性的依从性11个子特性,最后再细分为若干个属性,以帮助用户确定最适合他们需求的软件。本框架中的子特性并非完全按照ISO/IEC 25010: 2011和GB/T 2500. 10—2016来选取,有一部分是根据术语抽取软件自身的特性(如软件兼容性、数据兼容性)来制定的。需要指出的是,术语抽取软件的测评特性纷繁复杂,本文尽可能全面地列出测评术语抽取软件的重要特性。下文将对这些测评指标逐一介绍和分析,并提出测评框架的应用建议和应用案例。
2.1 功能适用性
功能适用性(functional suitability)是在指定条件下使用时,产品或系统提供满足明确和隐含要求的功能的程度[6]。结合术语抽取软件的特殊性,本框架只考虑与此密切相关的两个子特性:功能正确性(functional correctness)和功能适合性(functional appropriateness)。
2.1.1 功能正确性
功能正确性是产品或系统提供具有所需精度的正确的结果的程度[6]。精确率(precision)、召回率(recall)和F1值(F1 measure)是评价术语抽取结果中较常用且易操作的度量标准[8],可用来测评术语抽取软件的功能正确性。根据Vivaldi和Rodríguez构建的计算模型(见图2),精确率是软件抽取的可采纳的术语(accepted terms)与软件抽取的所有候选术语(term candidates)数量的比值,用来衡量抽取的候选术语的正确性;召回率是软件抽出的可采纳的术语与所测试语料文本中黄金标准(Gold Standard)术语表所包含的术语数量的比值,用来衡量抽取的候选术语的全面性[8]。一般情况下,二者结合使用,精确率和召回率均为高值时,则表示抽取效果理想。然而,抽取的阈值(threshold value)降低或过滤条件宽松(open filter)时,将有更多符合条件的术语,此时召回率提高而精确率降低;抽取的过滤条件严格(closed filter)时,则会导致精确率提高而召回率降低[8-9],由此可以看出精确率和召回率是两个相互制约的衡量标准。在这种情况下,Vivaldi 和Rodríguez引入了F1值的概念(见图3),将其作为加权调和均值来综合精确率和召回率的衡量值,削弱了二者间的明显差异,可以客观测评术语抽取软件的功能正确性[8]。
2.1.2 功能适合性
功能适合性是功能促进指定的任务和目标实现的程度[6],排除任何不必要的步骤,只为用户提供必要的步骤就可以完成任务。各类术语抽取软件提供的功能多种多样,在测评其功能适用性时,需要考虑到系统是否支持多语言对、单/双语提取、单/双语标注、词长/词频限制、(原/译文)停用表功能、静噪比设置、结果筛选、术语添加/编辑、术语管理、术语分享、标签分类等。在满足以上功能的同时也需评估在执行每一项必要功能或任务时是否存在不必要的操作。
2.2 兼容性
兼容性(compatibility)是在共享相同的硬件或软件环境的条件下,产品、系统或组件能够与其他产品、系统或组件交换信息、执行其所需功能的程度[6]。本框架主要考虑与兼容性最相关的两个子特性:软件兼容性和数据兼容性。
2.2.1 软件兼容性
软件兼容性包括操作系统兼容性、应用软件兼容性、浏览器兼容性,是测评术语抽取软件的一个重要因素。理想的术语抽取软件应该具有平台无关性,即不受操作系统类型的影响便可完美运行。市面上多种术语抽取软件或抽取模块,如SDL MultiTerm Extract、Déjà Vu中的Lexicon、memoQ中的术语提取模块,仅支持在Windows环境下运行,比起某些能够在Windows、macOS和Linux系统环境中运行的术语抽取软件,操作系统兼容性便会成为一个典型的区分指标。应用软件兼容性尤指组件在与其他平台或软件共享通用的环境和资源的条件下,能够有效执行其所能提供的功能的程度,如Tmxmall在线对齐界面中接入语帆术语宝的术语抽取端口,实现对现有语料的双语提取,在一定程度上反映了术语抽取软件的软件兼容性。浏览器兼容性主要针对Web端的术语抽取平台,是测试其在不同浏览器或不同分辨率的浏览器中能否正常运行的重要指标。
2.2.2 数据兼容性
数据兼容性包括新旧数据转换性、异种数据兼容性,是确保数据在不同版本和不同软件间自由交换的重要子特性。新旧数据转换性是指术语抽取软件不同版本间的数据兼容,比如软件或平台升级或更新后可能定义了新的数据格式或文件格式,此时需要考虑到转换过程中数据的完整性与正确性,确保对原来格式的支持及更新。异种数据兼容性是指术语抽取软件支持数据格式的程度,即可否完全正确导入、导出常用格式的文件以及导出的数据格式被其他软件读取的程度。例如, SDL MultiTerm Extract 支持从大量的文件格式中抽取术语,具体文件格式取决于用户当前所使用的项目类型,如单语术语抽取项目(Monolingual Term Extraction Project)、双语术语抽取项目(Bilingual Term Extraction Project)、词典编纂项目(Dictionary Compilation Project)、翻译项目(Translation Project)和质检项目(QA Project)。支持的文件格式合计达20余种,如TXT、DOC、HTML、HTM、XLS、PPT、XML、TMX、RTF、ISC、PPS等。抽取后的术语数据(XML、TXT)可以直接导出至术语库,免去术语数据格式转换的步骤。语帆术语宝支持TMX、TXT和DOC(X)格式的文件导入,导出格式为XLS(X)和TBX的文件,然而还需利用SDL MultiTerm Convert将XLS(X)或TBX文件转换为XDT和MultiTerm XML文件,方可进一步导入术语管理软件(如SDL MultiTerm Desktop)。
2.3 性能效率
性能效率(performance efficiency)与指定条件下所使用的资源量有关[6],即在保证高效完成任务的前提下,所用时间越短,性能效率越高。本框架主要考虑性能效率中可量化衡量的两个子特性:时间特性(time behavior)和容量(capacity)。
2.3.1 时间特性
时间特性是指产品或系统执行功能时,其响应时间、处理时间及吞吐率满足需求的程度[6]。Perián-Pascual和Mairal-Usón曾使用一个大小为1.57MB的西班牙语料库来根据词权重(term weighting)的响应时间测评4款术语抽取软件的时间特性,进而得出性能效率的测评结果。根据结果,他们认为主要存在两个影响因素,即候选术语提取(candidate extraction)的方式和词权重的复杂性[5]。至于Perián-Pascual 和 Mairal-Usón所提及的两个因素,不易采用量化的方式去衡量,所以本研究考虑将术语抽取的时间成本作为衡量性能效率的一个重要因素,具体涉及源文档的读取时间、人工筛选时间和数据导出时间。
2.3.2 容量
容量指产品或系统参数的最大限量满足需求的程度[6],可以作为衡量性能效率的辅助子特性。不同术语抽取软件的容量有所不同,譬如,在语帆术语宝中,普通用户无论是单语提取还是双语提取,单次上传仅支持单个文件,且文件大小不超过5M,开通会员后则支持100M的大文件上传;在SDL MultiTerm Extract中根据所选项目类型,支持单个或批量文件上传,文件大小不受限制; memoQ中的术语抽取模块可以即时对翻译文件(translation documents)、翻译记忆库(translation memories)或对齐的语料库文件(LiveDocs corpus documents)以单文件或批量文件的形式进行术语抽取,文件大小同样不受限制。
2.4 易用性
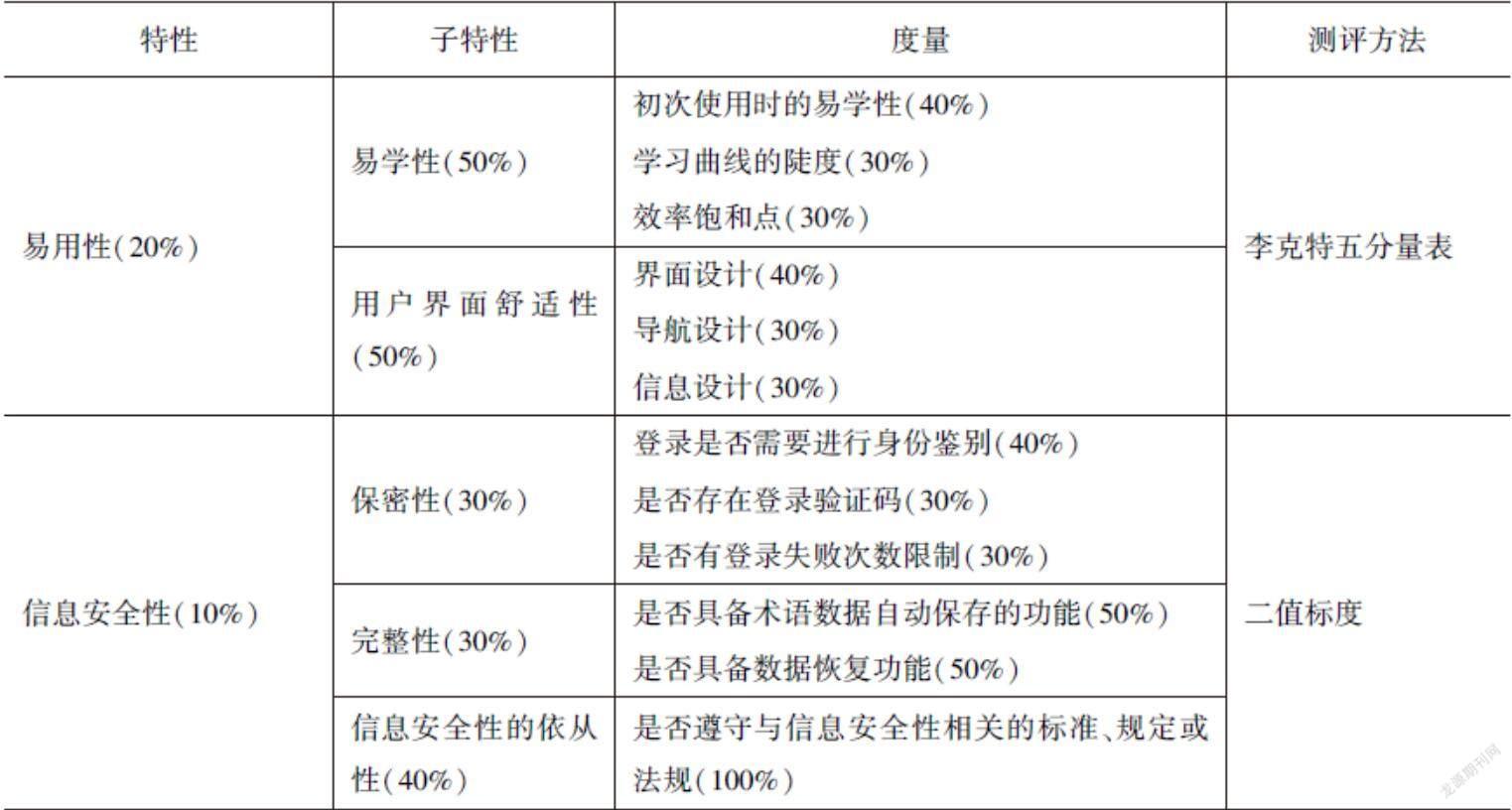
易用性(usability)指在指定的使用环境中,产品或系统在有效性、效率和满意度等方面为了指定的目标可为指定用户使用的程度[6],本框架主要考虑与易用性密切相关的两个子特性:易学性(learnability)、用户界面舒适性(user interface aesthetics)。
2.4.1 易学性
易学性旨在描述用户首次完成界面操作的难度,以及达到熟练操作时所重复的操作次数,是测评术语抽取软件易用性最重要的子特性。根据Joyce的分析,可从3个维度来分析易学性,即初次使用时的易学性(first-use learnability)、学习曲线的陡度(steepness of the learning curve)和效率饱和点(efficiency of the ultimate plateau),理想情况下三者表现优异方可证明软件易学性良好[10]。然而,也常常会面临一种窘境,即用户在使用一款术语抽取软件时,每一个操作步骤都有详细说明和解释,用户感觉比较容易上手,但这种情况下学习曲线较为平缓。随着重复操作的次数增加,用户对操作界面比较熟悉后,便会达到效率饱和点,感觉详细的操作步骤说明会导致使用效率低下。因此,一款易学性良好的术语抽取软件应该考虑增加快捷键或跳过介绍等操作,旨在给用户带来快速的引导流程和较低的学习成本,让用户感到自信,从而提高用户满意度[10]。在语帆术语宝中,平台会为每一步操作提供简单的向导或文字说明,比如在上传待提取的文件时,会告知用户平台所支持的格式和语言对及文件大小的限制,达到了一种用户易学性友好的效果。此外,操作界面是否提供帮助文档或视频(含支持语种的数量)、是否提供技术支持(例如在线客服、及时通信或邮件联系方式)等都应是测评术语抽取软件易学性需要考虑的指标。
2.4.2 用户界面舒适性
用户界面舒适性是指用户界面提供令人愉悦和满意的交互的程度[6],属于视觉上的设计,但其重要性不亚于功能设计。舒适的用户界面设计需要从用户体验的角度出发,充分考虑用户体验的要素,把握好操作界面的人机交互、操作逻辑和界面美观的整体设计。Garett认为用户体验(user experience)是一个自下而上的层级机构,包含5个层级,分别是战略层、范围层、结构层、框架层和表现层[11]。其中,框架层(skeleton)可以进一步分解为界面设计、导航设计和信息设计[11],目的是合理分割页面空间,提高交互体验,同时也方便用户的使用和操作。因此,框架层的理念可用于测评用户界面舒适性。具体而言,界面设计包括颜色的使用、图形化的设计;导航设计用于呈现信息的表现形式;信息设计则用于提供有效的信息交流,如资讯更新、技术支持、咨询方式。以SDL MultiTerm Extract为例,软件整体界面颜色为灰白搭配,最上方采用图标和文字(重要步骤处加粗处理)的形式进行信息指引,最下方为导航區域,简单几个按钮便可以引导用户完成操作,在框架层面考虑了用户的交互体验,达到一种用户界面舒适性良好的效果。
2.5 信息安全性
信息安全性指产品或系统保护信息和数据的程度,以使用户、其他产品或系统具有与其授权类型和授权级别一致的数据访问度[7],信息安全性高的术语抽取软件可以保护软/硬件、数据不因偶然或恶意原因而遭到未授权访问、破坏、篡改和泄露。本框架主要考虑与信息安全性紧密相关的3个子特性:保密性、完整性、信息安全性的依从性。
2.5.1 保密性
保密性指产品或系统确保数据只有在被授权时才能被访问的程度[7],不仅防止未获得授权的人或系统访问相关的信息或数据,还要保证获得授权的人或系统能正常访问相关的信息或数据。以下情况均可作为测评术语抽取软件保密性的指标,例如,登录时是否需要每次都进行用户身份鉴别,是否存在登录验证码,是否有登录失败次数限制,用户账号密码是否可见、可复制。
2.5.2 完整性
保密性与完整性定义相似,但二者侧重点有所不同。完整性指系统、产品或组件防止未授权访问、篡改计算机程序或数据的程度[7]。对于术语抽取软件而言,尤指其数据的完整性,例如在进行术语管理时是否具备术语数据自动保存的功能、术语库数据遭受破坏或篡改后是否具备恢复功能。在语帆术语宝中,如果用户在上次操作时忘记保存或导出术语,再次进入操作界面时,会出现一条温馨提示“系统检测到你提取到的术语还未保存或导出编辑或丢弃”,在一定程度上可确保用户术语数据的完整性,避免重复性操作。
2.5.3 信息安全性的依从性
信息安全性的依从性指产品或系统遵循与信息安全性相关的标准、约定或法规以及类似规定的程度[7],目的是核实软件、系统或组件是否遵循了涉及用户认证安全、系统网络安全、数据库安全、数据采取行为等法律法规。随着信息安全立法进程在全球持续推进,各国政府都对现行信息安全治理相关政策法规进行了改进和完善,如《中华人民共和国计算机信息系统安全保护条例》(1994)、《中华人民共和国网络安全法》(2016)、《在线隐私法》(2019)、《国家安全和个人数据保护法》(2019)、《网络信息内容生态治理规定》(2020)等。术语抽取软件涉及数据的传输和储存,小到个人隐私层面,大到国家信息安全层面,因此术语抽取软件应遵循信息安全性的依从性,不仅对用户的信息或数据资产安全负责,更要重视和贯彻国家信息安全战略。术语抽取软件是否符合或遵从相关标准、约定或法规,只需检查帮助文档或软件用户服务协议即可。
3 测评框架应用
3.1 应用建议
因术语抽取软件中不同特性所涉及的具体指标各异,故通过某个固定的方法去测评一款术语抽取软件的全部特性是很难实现的,得出的结果也会欠缺说服力。因此,在实际测评时,除采用李克特量表这种评分加总式的量表,用户还可以考虑选择模糊综合评价法(Fuzzy Comprehensive Evaluation,FCE)、层次分析法(Analytic Hierarchy Process,AHP)或混合使用的方法,将定性评价转化为定量评价或定性和定量相结合,以科学化的方法处理模糊性强、难以量化测评的特性或子特性。在此方面,翻译自动化用户协会(TAUS)与都柏林城市大学 Sharon O’ Brien 教授团队合作研发的新型翻译质量评估系统(Dynamic Quality Framework,DQF)为本研究带来一种新的评估思路,即考虑核心构成要素,动态灵活地选择评估方法[12],具体使用见下文应用案例。此外,在测评软件的功能正确性时建议严格制定黄金标准术语表,其精确性将直接影响术语抽取的召回率。黄金标准术语表需要先人工进行术语标注,经领域专家(domain specialists)审核后方可制定使用,所以在此过程中用户可通过关注词频(frequency)、短语类别(phrasal category)、詞目(lemma)和原材料的缺陷(source material flaws)来提升标注效率和黄金标准术语表的可靠性[13],进而确保客观测评术语抽取软件的功能适用性。
3.2 应用案例
为综合测评A和B两款术语抽取软件,本研究提供了一种动态、开放、可度量的模型示例,如表1所示。从特性出发,将其分解为多个子特性,子特性继续分解为多个度量(metrics),这样就可以将术语抽取软件的特点以权重的形式全面反映到度量上,形成统一的、可操作性的标准,确保评估值在一个量纲层面。同时参考动态质量评估框架(DQF)的理念,根据不同的度量特点,采用不同的测评方法,比如数值标度、二值标度、李克特五分量表等。具体而言,数值标度是指得到的百分数值,主要针对精确率、召回率和F1值。其中,召回率和F1值均应在严格制定黄金标准术语表的前提下计算得出;二值标度是指得到的回应为“是”或“否”(“是”为1,“否”为0),如“是否支持静噪比设置?”;李克特五分量表测出来的是5个回应类别,比如“非常满意”“满意”“不好说”“不满意”“非常不满意”,每一个回应类别对应不同的分值。
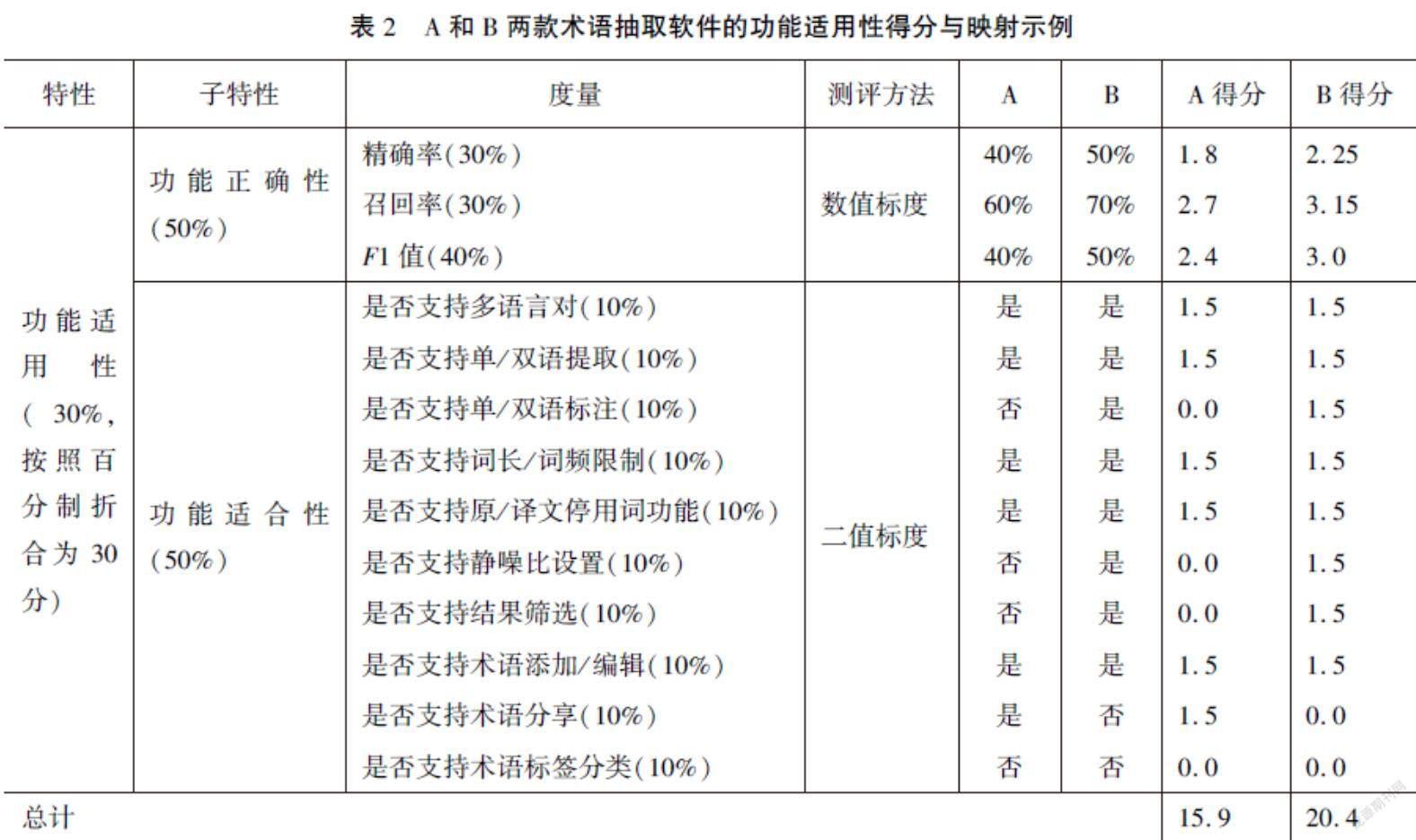
需要注意的是,随着后期研究的不断深入,特性、子特性和度量都会呈现出动态的变化,每个部分的权重也可以随时进行调整,达到一种测评框架复用的效果。目前模型中的权重分配仅做实验演示,真实场景中需要根据用户的需求和其对于各特性、子特性和度量的看法做适当调整。假设用户十分重视术语抽取软件的功能适用性,对于其易用性并没有那么重视,则可适当增加功能适用性的权重,降低易用性的权重。对于子特性和度量的调整也可遵照这种方法操作。此处以功能适用性为例,对A和B两款术语抽取软件的功能适用性进行测评,如表2所示。
在该实验模型中,功能适用性的权重为30%,按照百分制折合为30分,计算起来方便易操作,如A的精确率综合得分=30*50%*30%*40%=1.8。如表2所示,A和B两款术语抽取软件的功能适用性以此方式便算出得分分别为15.9和20.4,则可以说明B款在功能适用性方面优于A款。当其他特性也按照这种方式进行计算后,最后将各特性的分值累加之后便是该款术语抽取软件的总得分。进而根据各款术语抽取软件的总得分情况,便可以客观地计算出用户的最优选择。
4 结语
本文通过遵循和借鉴ISO/IEC 25010: 2011、GB/T 2500. 10—2016标准,选取了功能适用性、兼容性、性能效率、易用性和信息安全性等5个特性,尝试在前人[4-5]的基础上为术语抽取软件构建一个全面、动态、开放的测评框架。针对测评过程中需要注意的事项提出框架应用建议,并为用户演示了如何使用这个动态化、可度量的测评框架模型,以引导用户将术语抽取软件与术语管理过程紧密结合在一起,客观评价术语抽取软件。限于实验条件等方面的原因,本文提供的测评框架还需要进一步验证。后续研究将从用户体验的角度出发,采用李克特五分量表、模糊综合评价法和层次分析法相结合的方法,通过实证研究对该框架进行多轮验证,不断提升其科学性与可操作性。
参考文献
[1] 王华树, 王少爽. 翻译场景下的术语管理: 流程、工具与趋势[J]. 中国科技术语, 2019, 21(3): 9-14.
[2] BERNIER-COLBORNE G. Defining a gold standard for the evaluation of term extractors[C]//Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC ’12), 2012: 15-18.
[3] 王华树. 浅议实践中的术语管理[J]. 中国科技术语, 2013, 15(2): 11-14.
[4] SAURON V. Tearing out the terms: Evaluating terms extractors[C]//Proceedings of the Aslib Conference Translating and the Computer 24, London: The Association for Information Management, 2002: 1-18.
[5] PERIN-PASCUAL C, MAIRAL-USN R. A framework of analysis for the evaluation of automatic term extractors[J]. Vigo International Journal of Applied Linguistics, 2018: 105-125.
[6] ISO. ISO/IEC 25010:2011 Systems and Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—System and Software Quality Models[S]. Geneva: International Organization for Standardization International Electrotechnical Commission, 2011.
[7] 中華人民共和国国家质量监督检验检疫总局, 中国国家标准化管理委员会. GB/T 25000.10—2016 系统与软件工程: 系统与软件质量要求和评价(SQuaRE) 第10部分: 系统与软件质量模型[S]. 北京: 中国标准出版社, 2016.
[8] VIVALDI J, RODRGUEZ H. Evaluation of terms and term Extraction Systems: A practical approach[J]. Terminology. International Journal of Theoretical and Applied Issues in Specialized Communication, 2007, 13(2): 225-248.
[9] FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi-word terms: The C-value/NC-value method[J]. International Journal on Digital Libraries, 2000, 3(2): 115-130.
[10] JOYCE A. How to Measure Learnability of a User Interface[EB/OL]. (2019-10-20)[2021-05-04]. https://www.nngroup.com/articles/measure-learnability.
[11] GARRETT J J. 用户体验要素: 以用户为中心的产品设计[M]. 范晓燕,译. 北京: 机械工业出版社, 2011.
[12] 王均松. 翻译质量评估新方向: DQF动态质量评估框架[J]. 中国科技翻译, 2019, 32(3): 27-29.
[13] DERIEMAEKER J. Research into the performance of the terminology extraction software Termtreffer[D]. Belgium: Ghent University, 2012: 13-17.
作者简介:王华树(1980—),男,博士,北京外国语大学高级翻译学院副教授,兼任世界翻译教育联盟翻译技术研究会会长、中国翻译协会本地化服务委员会副秘书长、中国英汉语比较研究会外语教育技术专业委员会副秘书长、《中国科技术语》编委等。多年来致力于推动翻译技术产学研的生态融合,在《中国翻译》《外国语》《外语电化教学》《上海翻译》等期刊发表论文六十余篇,主持国家级、省部级及校级科研项目十多项,出版《人工智能时代翻译技术研究》《计算机辅助翻译概论》《应用程序本地化》《翻译与本地化项目管理》等十多部著作。研究领域:翻译与本地化技术、外语教育技术、术语管理。通信方式:wanghuashu@vip.qq.com。
刘世界(1994—),男,上海海事大学外国语学院2019级硕士研究生,专业为英语笔译,曾在《外语教学》《中国ESP研究》等刊物上发表论文。研究方向:翻译技术、术语管理、机器翻译译后编辑。通信方式:henryliushijie@163.com。
