
深度神经网络模型构建及优化策略
2022-01-22 10:34杨波,梁伟
计算机时代 2022年1期
杨波,梁伟





摘 要: 针对深度学习构建网络模型以及确定模型参数的问题,在分析神经网络基本结构和线性模型局限性的基础上,研究了深度神经网络设计的关键因素和优化策略。结合手写数字识别问题,对优化策略、动态衰减学习率、隐藏层节点数、隐藏层数等情形下的识别正确率进行了实验。结果表明,不同神经网络模型对最终正确率有质的影响,相同优化策略在不同参数取值时对最终正确率有很大影响,并进一步探究了具体选取优化策略和参数的方法。
关键词: 人工智能; 深度学习; 神经网络; 手写数字识别; MNIST数据集
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2022)01-08-06
Model construction and optimization strategies of deep neural networks
Yang Bo1, Liang Wei2
(1. Chenzhou Vocational and Technical College, Chenzhou, Hunan 423000, China; 2. College of Infomation Science and Engineering, Hunan University)
Abstract: Aiming at the issues of building the network model and determining the model parameters in deep learning, on the basis of analyzing the basic structure of neural networks and the limitations of the linear model, the key factors and optimization strategies of designing deep learning neural networks are studied. Combined with the handwritten numeral recognition problem, a large number of experiments are carried out on the recognition accuracy under the conditions of optimization strategy, dynamic attenuation learning rate, number of hidden layer nodes and number of hidden layers. The results show that different neural network models have a qualitative impact on the final accuracy rate, and the same optimization strategy has a great impact on the final accuracy rate when different parameters are selected. Furthermore, the specific selection method of optimization strategy and parameters is explored.
Key words: artificial intelligence; deep learning; neural networks; handwritten digit recognition; MNIST data set
1 神经网络模型
最早的神经网络数学模型是由W. S. McCulloch和W. Pitts提出[1],其MCP模型仿效了人類神经元的工作机理。该模型需要手动设置权重,即麻烦又难以得到最优结果。为了让计算机自动且合理地设置权重,F. Rosenblatt提出了感知机模型[2],该模型可根据样例数据学习特征权重。F. Rosenblatt在文献[3]中深入阐释了感知机理论及背景。感知机模型可以简单地理解为后续提到的单层神经网络。
1.1 神经元
神经网络的最小构成单元是神经元。神经元通常有多个输入和一个输出,其输出就是该神经元的所有输入经过某种运算后得到的结果。最简单的输出就是对输入进行加权和,如图1所示。
1.2 神经网络的结构
神经元之间的连接结构,构成神经网络结构。如果相邻两层的神经元都有连接则称为全连接神经网络,如图2所示。
每个输入层节点有一个输入值,该值也通常看作是该输入节点的输出值。机器学习中,神经网络输入层所有节点通常对应特征向量,输入层每个节点的值对应特征向量的每个分量值。对于隐藏层,每个节点的输出值是由该节点的所有输入值及其对应边的权重值经过运算得到。当获得所有隐藏层节点的输出值,通过运算便可获得输出层节点的输出值。
1.3 神经网络的数学表示
根据输入层节点的输入值,各层节点经过某种运算,便可得出输出层节点的输出值,该运算过程称为神经网络的前向传播算法。例如图2所示神经网络使用加权运算的前向传播算法,可用矩阵运算描述:
[X=[x1x2x3] W1=w111 w112 w113 w114w121 w122 w123 w124w131 w132 w133 w134]
[W2=w211 w212w221 w222w231 w232w241 w242 Y=XW1W2=y1y2]
1.4 神经网络的训练
当神经网络根据输入值运算后得到输出值,也就相当于得到了一个推算结果。例如,输入一张手写的数字图片(假如图片上所写数字为5),经过神经网络计算后便会得到一个推算出来的数字(该推算值可能为5也可能不为5)。对于推算结果是否和真实情况一致,取决于多个因素,如连接结构、连接边的权重参数以及节点运算方式等。
为了提高神经网络推算结果的正确率,需要不断调整连接边的权重参数,每调整一次便要运算一次进行结果验证。通常,需要进行大量的数据验证才能将神经网络调整到最佳状态,以便神经网络在遇到未知答案的样本时能推测出正确结果。显然,由人工训练神经网络是不现实的。R. J. Williams,D. E. Rumelhart以及G. E. Hinton提出了反向传播算法[4],能自动训练神经网络并大幅降低神经网络训练时间。
2 深度神经网络的设计与优化
2.1 神经网络的设计
图2所示神经网络中,输出是输入的加权和,根据矩阵运算的性质可进行如下变换:
[Y=XW1W2=XW1W2=XW']
[= ][i=13xiw'i1i=13xiw'i2=y1y2]
于是,每一输出节点的输出值[yj]与输入节点的输入[X=[x1x2… xn]]可写成如下运算形式:
[yj=i=1nxiw'ij]
可以看到,输出与输入之间是线性的,称为线性模型。线性模型能解决的问题有限,只能解决线性可分问题,不能解决复杂问题。深度学习主要研究的是非线性可分复杂问题。
如果使用一个非线性函数对加权和再进行运算,神经网络就不再是线性模型了。这种非线性函数通常称作激活函数,常用的有[ReLU]函数、[tanh]函数和[sigmoid]函数等。非线性模型节点结构如图3所示,其中[b]为偏置项,通常为常数。
如图3中加入了激活函数的神经元节点可以看成是没有隐藏层且只有一个输出的神经网络,M. Minsky, S. A. Papert指出这种没有隐藏层的神经网络不能解决抑或问题[5]。
非线性神经网络模型中,加入隐藏层,模型相当于具有了组合特征提取功能,更适用于解决不易提取特征向量的问题。因此,设计神经网络时,需要考虑使用激活函数和隐藏层。
2.2 神经网络的优化
⑴ 优化目标:损失函数
神经网络通过前向传播算法计算得到预测值,将预测值和真实值进行比对得出二者差距值,这种差距值表示的是推算值与真实值之间的损失,越小越好。为评判损失大小,需要定义函数定量地刻画对应的损失值,即损失函数。
对于分类问题,交叉熵是分类问题常用的一种损失函数。
对于给定的两个概率分布[p(x)]和[q(x)],通过[q(x)]来表示[p(x)]的交叉熵定义如下:
[Hpx,qx=-xpxlog (q(x))]
其中,在事件总数有限的情况下,概率分布[p(x)]满足如下条件:
[∀xpx∈0,1andxpx=1]
交叉熵描述的是两个概率分布之间的距离,而分类问题的神经网络输出不一定是概率分布。为了将神经网络输出转变成概率分布,常用方法是在神经网络的输出层后额外增加一[Softmax]层,使用[Softmax]处理神经网络前向传播得到的结果,将结果转变一个概率分布。原始神经网络的输出[yii=1,2,…,n]经[Softmax]处理后的结果如下:
[y'i=Softmaxyi=eyij=1neyj]
交叉熵用作神经网络损失函数时,[p]代表的是正确结果的概率分布,[q]代表的是預测结果的概率分布,因此,交叉熵表示的就是使用预测结果概率分布[q]来表达正确结果概率分布[p]的困难程度,很明显,交叉熵越小,两个概率分布越接近。
回归问题解决的是对具体数值的预测,与分类问题不同。回归问题的神经网络一般只有一个输出节点,输出值就是预测值。回归问题常用的损失函数是均方误差[MSE],定义如下:
[MSEyi,y'i=1ni=1n(yi-y'i)2]
其中,[yi]为一个[batch](即一小部分训练数据)中的第[i]个数据的正确答案,[y'i]为神经网络的预测值。
当然,也可根据问题自定义损失函数,注意的是损失函数定义的是推算值与真实值之间的损失。
⑵ 动态衰减学习率
反向传播算法中,根据损失函数计算得到预测值与正确值之间的损失大小,以此确定参数调整的下降梯度,再根据下降梯度和学习率更新参数值[4]。在海量训练数据情况下,每一次训练如果都计算所有训练数据的损失函数,非常耗时。为加速训练过程,减少网络模型收敛所需要的迭代次数,在实际应用中一般采用计算一个[batch]的损失函数。
学习率代表的是参数更新的幅度,控制参数更新的速度。若学习率过大,更新幅度也大,可能会导致参数在极优值两侧来回移动。学习率越小,越能保证收敛性,但会大大降低优化速度,需要更多迭代轮数。为了解决学习率设定问题,通常采用一种灵活的设置方法--指数衰减法,即在训练初期使用一个较大的学习率来快速得到一个较优参数,随着训练增多,逐步按指数减小学习率,使得模型在训练后期更加稳定地收敛。常用的指数衰减学习率更新公式如下:
[learningRatenew=learningRatebase*decayRatetrainingStep(now)trainingSteps(decay)]
其中,[learningRatenew]表示更新的学习率,[learningRatebase]表示事先设定的基础学习率,[decayRate]表示学习率的衰减率,[trainingSteps(decay)]表示學习率衰减一次需要的训练轮数,也即完整地使用一遍训练数据需要的训练轮数,它的值等于总训练数据量除以一个[batch]的训练数据量(因为每次训练只训练一个[batch]的数据量),[trainingStep(now)]表示当前的训练轮数。
⑶ 避免过拟合
对于一个含有[n]个未知数和[n]个等式的方程组,当方程不冲突时,可以对未知数求解。在神经网络中,当训练数据的总数少于网络模型的参数时,只要训练数据不冲突,神经网络可以很好地记忆住每一个训练数据的结果而使得损失函数为[0],这样会造成神经网络弱化了训练数据中的通用特征和趋势,当使用该神经网络来推算或预测新的未知问题时,则可能会造成推测失误。换句话说,当神经网络模型过于复杂后,它就可以很好的“记忆”每一个训练数据的随机噪音而忽略去“学习”训练数据的通用特征,造成对训练数据的过拟合。通常使用正则化来实现避免过拟合。正则化的思想就是在损失函数中加入能够刻画模型复杂程序的指标。一般来说,当网络结构确定后,模型的复杂度就只由权重参数决定(偏置项[b]为常数,不影响模型复杂度)。常用的刻画模型复杂度的正则化函数是[L2]正则化,公式如下:
[R(W)iw2i]
[L2]正则化,是通过限制权重参数大小使得模型不能任意拟合训练数据中的随机噪音,并避免参数变得更稀疏,即避免有更多的参数变为[0]。
⑷ 提高健壮性
训练神经网络时,为了使网络模型在测试数据上更加健壮,通常可以对参数采用滑动平均模型。滑动平均模型中,网络前向传播计算时,不是直接使用权重参数的值参与计算,而是使用参数的滑动平均值参与计算。为实现滑动平均模型,每个参数需要维护一个影子参数,在每次更新参数时,引子参数的值也会更新,更新公式如下:
[Pshadow=decay*Pshadow+1-decay*P]
[Pshadow]表示影子参数,[decay]表示影子参数的衰减率,[P]为待更新的参数。[decay]决定了模型更新的速度,其值越大模型越稳定,通常设成非常接近[1]。为了使训练过程前期影子参数更新更快,还可以动态更新[decay]的大小,公式如下:
[decay=mindecay, 1+trainingStep10+trainingStep]
其中,[trainingStep]表示当前的训练轮数。
根据上述分析,神经网络的设计目标是要能解决非线性可分的复杂问题,需要使用隐藏层和使用激活函数。神经网络的优化目标是通过降低损失函数的值(即损失值)来优化网络参数,最终提高网络对未知问题的正确预测。实际中,通常是在反向传播算法中使用指数衰减学习率、给损失函数加上正则化、在前向传播阶段使用滑动平均模型等策略实现对神经网络进行优化。
3 深度神经网络应用--以手写数字识别为例
手写数字识别是多年研究热点,研究人员提出了很多方法[6-13],具有较好的识别正确率。
3.1 数据集介绍
MNIST是一个通用的手写体数字识别数据集,在Yann LeCun的网站对数据集的训练数据、测试数据、验证数据、图片内容及像素大小均进行了详细介绍[14]。实验采用的深度学习工具是TensorFlow,TensorFlow对MNIST数据集做了封装,能方便加载该数据集。
3.2 神经网络模型设计
为处理方便,将MNIST数据集中每张图片的像素矩阵(大小为28*28)放到一个长度为784(784=28*28)的一维数组中,作为神经网络输入层的特征向量。因此,神经网络输入层设计为784个节点,输出层设计为10个节点,每个输出节点对应数字0~9中的一个,输出节点的输出值代表的是推测为该节点所对应数字的概率,值最大的输出节点所对应的数字就是一次推测的结果。在输入层和输出层之间,设计一层隐藏层,隐藏层节点数量为500。
网络设计为全连接网络,节点采用加权和运算并使用激活函数[ReLU]对运算进行去线性化,在模型中使用了指数衰减学习率、加入正则化的损失函数、滑动平均模型等优化策略。为方便描述,本文中将采用了以上设计和优化策略的神经网络模型称为全优化模型。
3.3 参数设置
初始情况下,全优化模型的各策略所需的参数设置如表1所示。实验开发和运行软硬件平台环境如表2所示。
3.4 实验结果分析
神经网络关注的目标是训练后的模型对未知数据的预测正确率,因此实验中模型的正确率是根据测试集数据计算得到的,而测试集在训练过程中设置为对模型不可见,以保证模型对未知数据的预判能力。
⑴ 全优化模型与少一项优化策略模型的对比
本文所称的全优化模型概念在上述已描述,少一项优化策略模型是指与全优化模型相比,少了一项优化策略,如少正则化策略的模型、少滑动平均策略的模型等。为探索各优化策略对整体优化效果的影响大小,对比了全优化模型与少一项优化策略模型的正确率,结果如图4所示。
可以看到,使用全优化策略的模型在训练过程中正确率收敛很快,且正确率最佳。不使用隐藏层或不使用激活函数,相当于调整了网络结构,会较大地影响模型对未知数据推测的正确率。不使用指数衰减的学习率(即使用固定的学习率),实验中使用了固定学习率为0.7和0.1两种情况,固定学习率为0.7时的模型正确率与全优化模型的正确率非常接近,而固定学习率为0.1时的模型的正确率收敛较慢,不过在训练一段时间后会逐渐接近全优化模型的正确率,但不如固定学习率为0.7的模型那么好。不使用正则化项或不使用滑动平均的模型的正确率,在此MNIST数据集上与全优化模型较为接近。
可见,设计神经网络时(在硬件算力满足情况下)最佳选择是使用全优化模型,问题在于各优化策略对应参数该如何取值才能更好提高模型的正确率。以下研究全优化模型下各优化策略的参数取不同值时对模型正确率的影响,以选取最合理的参数值。
⑵ 激活函數对正确率的影响
全优化模型下,分别使用三种常用激活函数[ReLU]、[tanh]和[sigmoid]对模型正确率的影响。对每种激活函数都进行多次训练,然后从每种激活函数训练结果中随机选取三条,得到结果如图5。使用[ReLU]激活函数的模型收敛最快,正确率也最高。
⑶ 基础学习率对正确率的影响
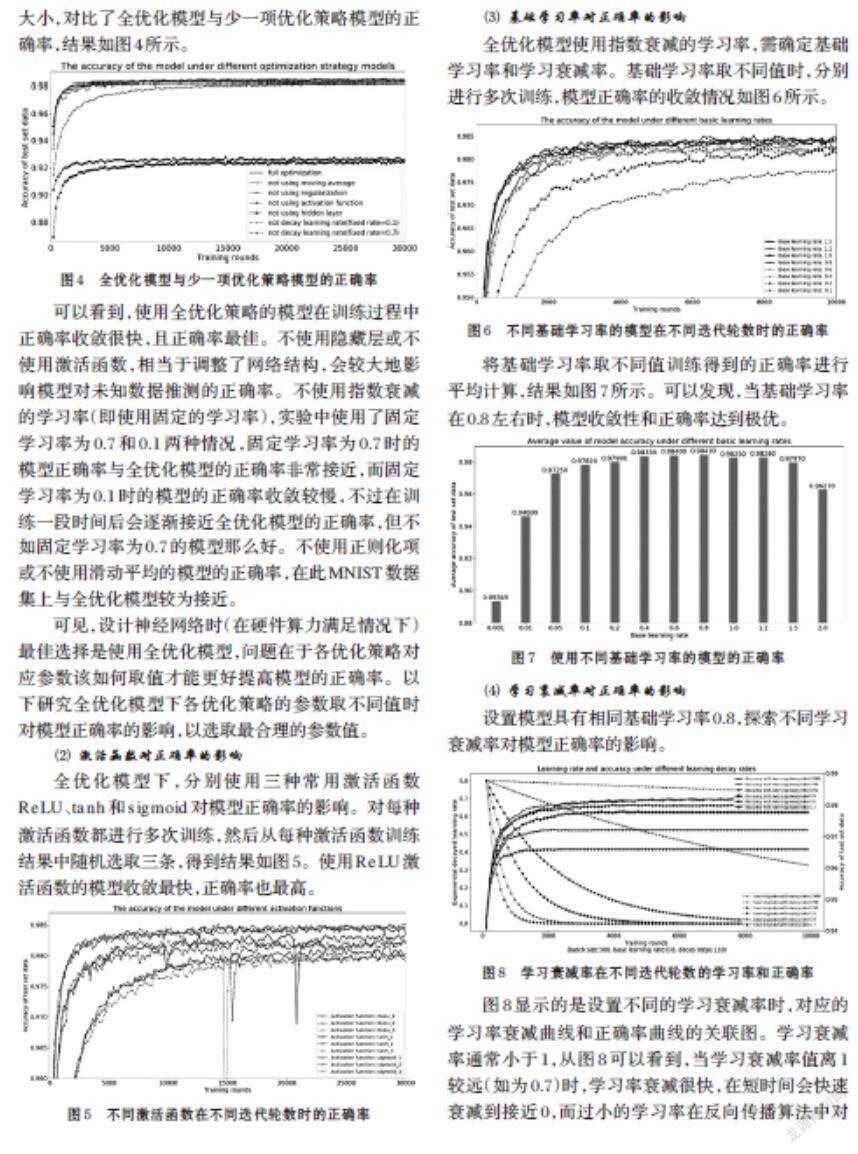
全优化模型使用指数衰减的学习率,需确定基础学习率和学习衰减率。基础学习率取不同值时,分别进行多次训练,模型正确率的收敛情况如图6所示。
将基础学习率取不同值训练得到的正确率进行平均计算,结果如图7所示。可以发现,当基础学习率在0.8左右时,模型收敛性和正确率达到极优。
⑷ 学习衰减率对正确率的影响
设置模型具有相同基础学习率0.8,探索不同学习衰减率对模型正确率的影响。
图8显示的是设置不同的学习衰减率时,对应的学习率衰减曲线和正确率曲线的关联图。学习衰减率通常小于1,从图8可以看到,当学习衰减率值离1较远(如为0.7)时,学习率衰减很快,在短时间会快速衰减到接近0,而过小的学习率在反向传播算法中对更新权重参数基本起不了作用,造成模型在较小正确率的情况下就失去了训练功能,也就是说,模型尽管还处在训练过程中,但是却基本不更新权重参数。从图8可知,学习衰减率设置为接近1(如0.99或0.95)更合适。
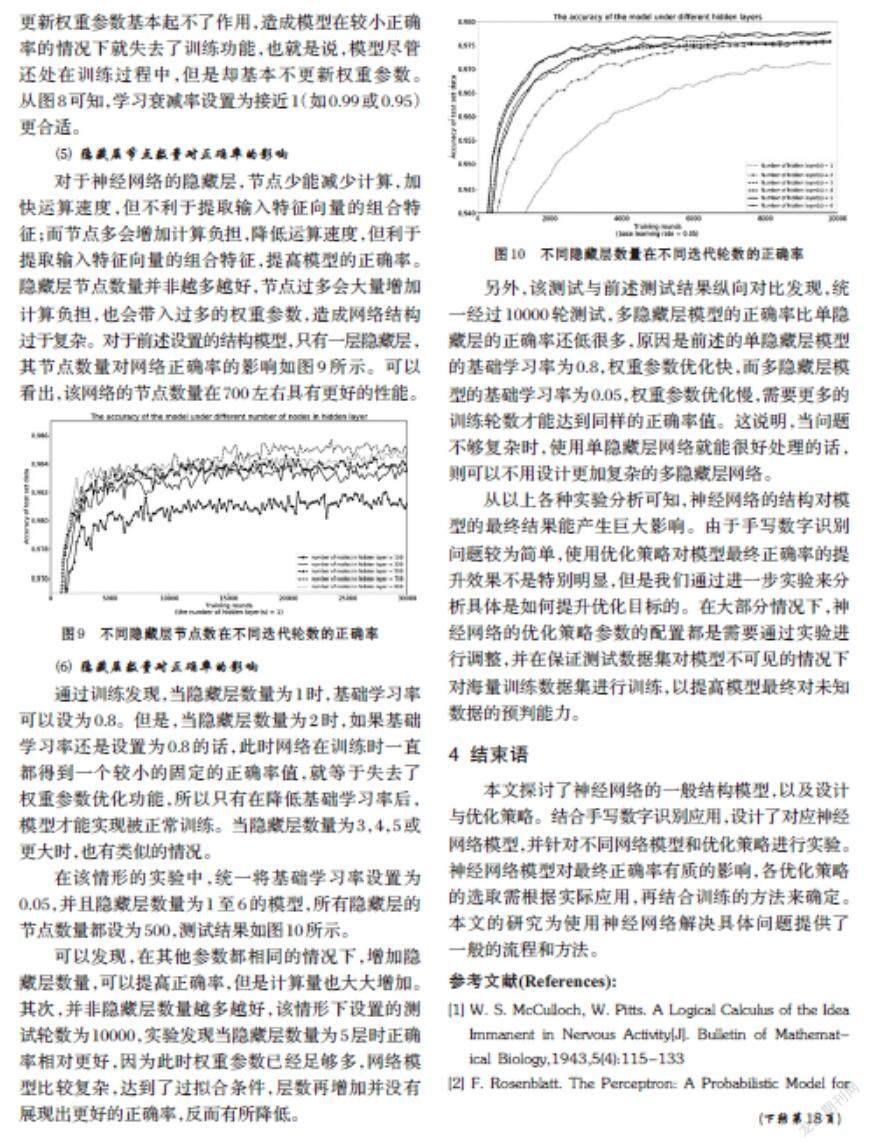
⑸ 隐藏层节点数量对正确率的影响
对于神经网络的隐藏层,节点少能减少计算,加快运算速度,但不利于提取输入特征向量的组合特征;而节点多会增加计算负担,降低运算速度,但利于提取输入特征向量的组合特征,提高模型的正确率。隐藏层节点数量并非越多越好,节点过多会大量增加计算负担,也会带入过多的权重参数,造成网络结构过于复杂。对于前述设置的结构模型,只有一层隐藏层,其节点数量对网络正确率的影响如图9所示。可以看出,该网络的节点数量在700左右具有更好的性能。
⑹ 隐藏层数量对正确率的影响
通过训练发现,当隐藏层数量为1时,基础学习率可以设为0.8。但是,当隐藏层数量为2时,如果基础学习率还是设置为0.8的话,此时网络在训练时一直都得到一个较小的固定的正确率值,就等于失去了权重参数优化功能,所以只有在降低基础学习率后,模型才能实现被正常训练。当隐藏层数量为3,4,5或更大时,也有类似的情况。
在该情形的实验中,统一将基础学习率设置为0.05,并且隐藏层数量为1至6的模型,所有隐藏层的节点数量都设为500,测试结果如图10所示。
可以发现,在其他参数都相同的情况下,增加隐藏层数量,可以提高正确率,但是计算量也大大增加。其次,并非隐藏层数量越多越好,该情形下设置的测试轮数为10000,实验发现当隐藏层数量为5层时正确率相对更好,因为此时权重参数已经足够多,网络模型比较复杂,达到了过拟合条件,层数再增加并没有展现出更好的正确率,反而有所降低。
另外,该测试与前述测试结果纵向对比发现,统一经过10000轮测试,多隐藏层模型的正确率比单隐藏层的正确率还低很多,原因是前述的单隐藏层模型的基础学习率为0.8,权重参数优化快,而多隐藏层模型的基础学习率为0.05,权重参数优化慢,需要更多的训练轮数才能达到同样的正确率值。这说明,当问题不够复杂时,使用单隐藏层网络就能很好处理的话,则可以不用设计更加复杂的多隐藏层网络。
从以上各种实验分析可知,神经网络的结构对模型的最终结果能产生巨大影响。由于手写数字识别问题较为简单,使用优化策略对模型最终正确率的提升效果不是特别明显,但是我们通过进一步实验来分析具体是如何提升优化目标的。在大部分情况下,神经网络的优化策略参数的配置都是需要通过实验进行调整,并在保证测试数据集对模型不可见的情况下对海量训练数据集进行训练,以提高模型最终对未知数据的预判能力。
4 结束语
本文探讨了神经网络的一般结构模型,以及设计与优化策略。结合手写数字识别应用,设计了对应神经网络模型,并针对不同网络模型和优化策略进行实验。神经网络模型对最终正确率有质的影响,各优化策略的选取需根据实际应用,再结合训练的方法来确定。本文的研究为使用神经网络解决具体问题提供了一般的流程和方法。
参考文献(References):
[1] W. S. McCulloch, W. Pitts. A Logical Calculus of the Idea Immanent in Nervous Activity[J]. Bulletin of Mathematical Biology,1943,5(4):115-133
[2] F. Rosenblatt. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain[J]. Psychological Review,1958,65:386-408
[3] F. Rosenblatt. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms[M]. Washington DC: Spartan Books,1962
[4] D. E. Rumelhart, G. E. Hinton, R. J. Williams. Learning Representations by Back Propagating Errors[J]. Nature,1986,323(6088):533-536
[5] M. Minsky, S. A. Papert. Perceptrons: An Introduction to Computational Geometry[M]. Massachusetts: MIT Press,1969
[6] 杜梅,赵怀慈.手写数字识别的研究[J].计算机工程与设计,2010,31(15):3464⁃3467
[7] 焦微微,巴力登,闫斌.手写数字识别方法研究[J].软件导刊,2012,11(12):172⁃174
[8] 张黎,刘争鸣,唐军.基于BP神经网络的手写数字识别方法的实现[J].自动化与仪器仪表,2015(6):169⁃170
[9] 陈浩翔,蔡建明,刘铿然,等.手写数字深度特征学习与识别[J].计算机技术与发展,2016,26(7):19-23,29
[10] 陈玄,朱荣,王中元.基于融合卷积神经网络模型的手写数字识别[J].计算机工程,2017,43(11):187-192
[11] 陈岩,李洋洋,余乐,等.基于卷积神经网络的手写体数字识别系统[J].微电子学与计算机,2018,35(2):71⁃74
[12] 宋晓茹,吴雪,高嵩,等.基于深度神经网络的手写数字识别模拟研究[J].科学技术与工程,2019,19(5):193⁃196
[13] 曾文献,孟庆林,郭兆坤.基于深度卷积自编码神经网络的手写数字识别研究[J].计算机应用研究,2020,37(4):1⁃4
[14] Y. LeCun etc. The MNIST database of handwritten digits [EB/OL]. http://yann.lecun.com/exdb/mnist.
猜你喜欢
电子制作(2019年19期)2019-11-23
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
南风窗(2016年19期)2016-09-21
重型机械(2016年1期)2016-03-01
