
基于DeepLabv3+的图像语义分割优化方法
2022-01-26 09:35郑斌军孔玲君
包装工程 2022年1期
郑斌军,孔玲君
图文信息技术
基于DeepLabv3+的图像语义分割优化方法
郑斌军1,孔玲君2
(1.上海理工大学,上海 200093;2.上海出版印刷高等专科学校,上海 200093)
为了实现良好的图像语义分割精度,同时尽可能降低网络的参数量,加快网络训练速度,提出基于DeepLabv3+的图像语义分割优化方法。编码器主干网络增加注意力机制模块,并采用更密集的特征池化模块有效聚合多尺度特征,同时使用深度可分离卷积降低网络计算复杂度。基于CamVid数据集的对比实验显示,优化后网络的MIoU分数达到了71.03%,在像素精度、平均像素精度等其他方面的评价指标上较原网络有小幅提升,并且网络参数量降低了12%。在Cityscapes的测试数据集上的MIoU分数为75.1%。实验结果表明,优化后的网络能够有效提取图像特征信息,提高语义分割精度,同时降低模型复杂度。文中网络使用城市道路场景数据集进行测试,可以为今后的无人驾驶技术的应用提供参考,具有一定的实际意义。
语义分割;注意力机制;深度可分离卷积;编码器-解码器
图像分割是计算机视觉领域的重要研究任务之一。传统的图像分割方法多数是基于图像本身的特征如颜色、纹理、形状等进行区域的生成,通过合并分类区域来得到图像分割结果[1],过程较为烦琐,且分割精度也有很大的提升空间。深度学习技术由于其强大的计算能力与高效的非线性处理能力,现已被广泛应用在诸如图像分割、目标检测、模式识别在内的计算机视觉领域。语义分割是图像分割的一个类别,其任务是为图像中每个像素都匹配对应的语义标签。语义分割在多个领域发挥着重要的作用例如:医学图像诊断[2],自动驾驶[3],卫星图像处理[4],环境分析[5],语义分割结果的精度直接决定了后续的图像分类及处理结果的好坏,因此具有十分重要的研究意义和应用价值。
现今,大多数语义分割网络基于完全卷积神经网络(Fully Convolution Network, FCN)[6],它第1次提出用卷积层来替代普通分类网络中的全连接层,让网络拥有能够处理任意而非固定图像尺寸的能力,得到了像素级的预测结果。此后,多位研究人员提出了多种方法对该基本网络进行优化。Ronneberger O等[7]提出了一种基于收缩路径与扩张路径的网络架构U-net,收缩路径是为了提取图像的深层次特征语义信息,扩张路径则利用跳跃连接的方式,融合不同分辨率的特征图来产生较好的分割效果。Yoo D等[8]利用空间金字塔结构从不同大小的感受野获取信息。Chen L C等[9—11]发布了一系列的DeepLab网络,先后使用诸如全连接条件随机场,空洞卷积,空洞空间金字塔池化在内的方式,充分利用了特征图的多尺度信息,提高了获取高级语义信息的感受野大小。段立娟等[12]提出一种跨模态注意力机制来提取更精确的语义特征,提高分割精度。周勇[13]、赵宝齐[14]等也关注到注意力机制对于提高神经网络语义信息获取的有效性。
基于上述研究,文中设计一个新的网络架构用于图像语义分割。整体框架设计采用精度较高的DeepLabv3+的网络结构,在主干网络进行特征提取的过程中增加基于通道和空间信息的注意力机制模块[15],引入密集空洞空间金字塔池化(Dense Atrous Spatial Pyramid Pooling, DASPP)[16],该模块能充分利用不同卷积率得到特征图的语义信息,获得更大的密集特征以及感受野,使得图像分割更加精细和平滑。使用深度可分离卷积[17]替换原始的普通卷积,在减少计算量的同时加快了训练网络的收敛速度。文中提出的网络在城市街道场景数据CamVid上进行验证,通过与其他几个网络的比较,以及对图像分割类别精度的提升,验证该网络的有效性。
1 网络架构
1.1 DeepLabv3+网络的基本原理
DeepLabv3+网络基于编码解码器架构,见图1。编码器部分,输入图像会经过骨干网络的下采样而生成高级语义特征图,此后特征图像进入ASPP模块。ASPP模块由3个空洞率分别为6,12,18的空洞卷积、1个1×1的卷积和1个全局平均池化层构成。然后将获得的5个特征图在通道上直接进行级联完成多尺度的采样过程,并经过1个1×1的卷积实现通道数的降维。解码器部分将骨干网络中4倍下采样获得的低级语义特征图进行1×1卷积处理完成通道数的降维,之后与编码器通过4倍上采样得到的特征图像进行连接,完成图像低级语义信息与高级语义信息之间的融合,增强网络分割图像的能力。再用3×3的卷积提取融合图的特征,最后再次进行4倍上采样,输出预测的分割图像。

图1 DeepLabv3+网络架构
1.2 优化的网络
文中提出的网络见图2。在骨干网络的下采样模块之间添加注意力机制模块,该模块能够充分利用特征图的通道信息和空间信息,增强要关注的特征,抑制不必要的特征,有效地帮助特征信息在网络中的流动,提高网络捕获信息的能力。其次,引入DASPP模块来替代图1中的ASPP模块,DASPP以级联的方式连接1组空洞卷积层,从而生成多尺度特征,覆盖尺度范围不仅更大而且更加密集,同时不会显著增加网络大小。最后,使用深度可分离卷积替换普通卷积,即原有的1×1卷积替换为1×1深度可分离卷积,3×3卷积换为3×3深度可分离卷积,并且对引入的DASPP模块的空洞卷积也进行替换。相较于标准卷积方式,深度可分离卷积可以明显减少训练过程中的参数量,能够在对分割精度影响较小的情况下,加快网络拟合速度。
1.3 注意力机制模块的原理
众所周知,在人类的感知系统中,注意力有着十分重要的作用。由于视觉特性的影响,人眼不会同时处理整个场景中的信息而是先选择性地聚焦显著的部分,从而获得更佳的视觉感受,受此启发,引入注意力机制模块(见图3)来提高网络分割图像的性能。
首先对输入的特征图分别进行基于高度与宽度方向上的全局平均池化和全局最大池化,之后再分别通过多层感知器(Multi-Layer Perceptron, MLP)将获得的输出特征进行基于元素的对位相加处理。接下来使用sigmoid函数激活,生成通道注意力特征(生成方式见式(1))。然后将输入的特征图与该通道注意力特征作点乘处理,从而获得空间注意力模块所需的输入特征。
c()=Sigmoid(MLP(AvgPool()+MLP(MaxPool())))(1)
将通道注意力模块输出的特征图用作空间注意力模块的输入特征图,随后分别进行全局最大池化和全局平均池化处理,获得上述的2个结果后根据通道信息做连接。之后使用一个7×7的卷积将连接的结果降成1个通道。再使用sigmoid函数激活得到空间注意力特征,生成方式见式(2),最后将输入的特征图与该空间注意力特征作点乘,获得最终的空间注意力特征。
s()=Sigmoid(([AvgPool(); MaxPool()]))(2)
1.4 密集空洞空间金字塔池化模块
充分地利用多尺度信息可以有效提高对不同目标的分割能力。如图4所示,DASPP通过密集连接的方式将每个空洞卷积层的输出结果传递到在此之后的所有未被访问过的空洞卷积层,每个空洞卷积层只使用有合理膨胀率(≤24)的空洞滤波器。通过一系列的空洞卷积组合,处于结构较后层的神经元会得到越来越大的感受野,同时不会出现卷积核退化的问题。经过前面的特征组合,每个提取特征的神经元都能获得多个尺度的信息,不同的神经元编码来自不同尺度范围的多尺度信息,于是DASPP输出的最终特征图以非常密集的方式覆盖了大规模范围内的语义信息。
1.5 深度可分离卷积模块
可分离卷积的结构见图5,标准卷积滤波器见图5a,图5b和图5c共同组成深度可分离卷积。在标准卷积层中,计算复杂度取决于大小为D×D的输入/输出特征映射(为简单起见,假设为平方特征映射),输入通道数,输出通道数,以及卷积核D的空间尺寸(常见卷积核尺寸为3×3和5×5),整体计算需要D2×D2××次乘法。在深度可分离卷积中,大小为D2×D2××的滤波计算被分成2部分。首先,每个通道进行同一个滤波器的深度卷积,即所有个输入通道的大小为D×D,这里所需要的卷积计算消耗为D2×D2×。
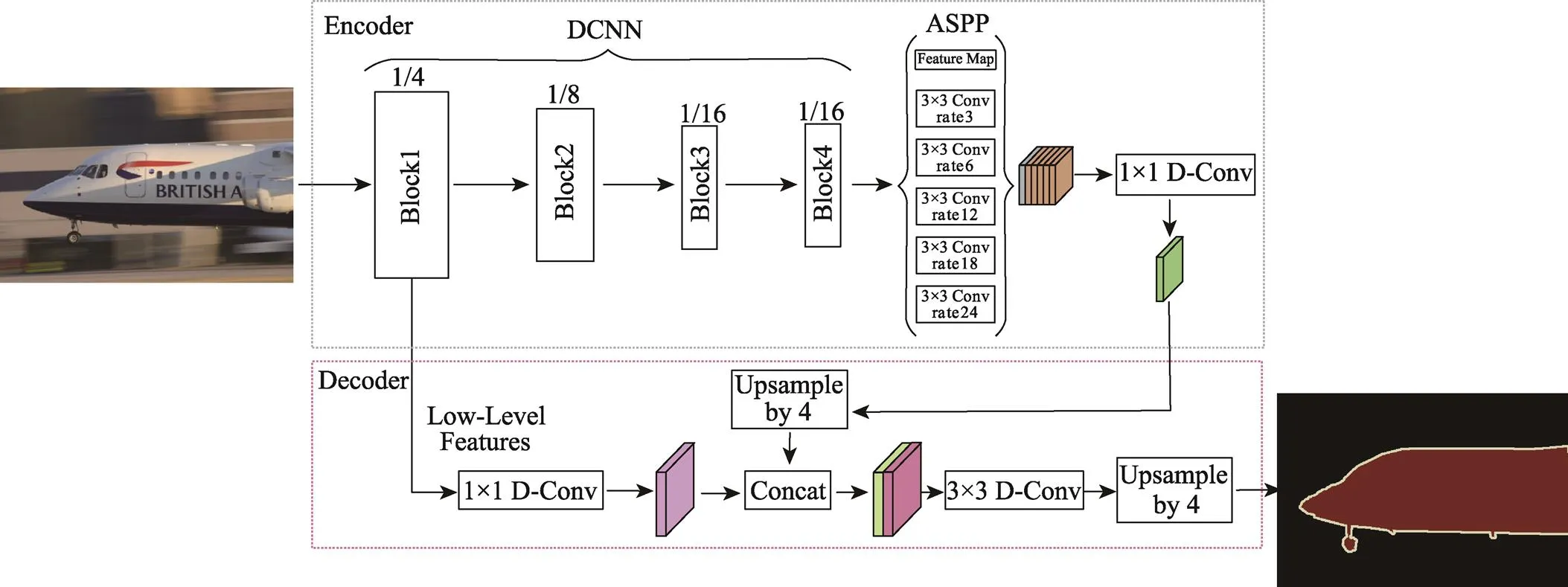
图2 文中优化的DeepLabv3+网络架构

图3 注意力机制模块

图4 Dense-ASPP模块

图5 卷积滤波器
相比于标准卷积,深度卷积十分高效,但是深度卷积只是对输入通道进行了处理,并没有利用通道信息来生成新的特征,因此,这里增加一个额外的层来获得新的特征,该层使用1×1(点方向)卷积滤波器来获得深度卷积的输出并对其进行组合,卷积计算消耗为D2××。深度可分离卷积由深度方向卷积和1×1(点方向)卷积组合而成。计算总的消耗为D2×2×+D2××。
当网络中卷积核尺寸增加或者网络深度加深的时候,通过将标准卷积分解为深度方向和点方向的卷积,可以有效地减少计算量,减少计算量的方式见式(3)。
(3)
2 实验与分析
2.1 实施细节
实验运行环境为Win10专业版操作系统,处理器为Intel Core i9-9900k,内存32 GB,图形处理卡为一张Nvidia GeForce GTX1080 Ti(11 GB),Cuda版本为10.2,数据处理使用Python3.6和Matlab 2020a。网络训练过程中采用的优化算法为带动量的随机梯度下降法(Stochastic Gradient Descent Momentum,SGDM),学习率衰减策略采用分段常数衰减。动量设置为0.9,学习率每10轮降低0.2,让网络以较高的初始学习率进行快速地学习,并且在网络优化迭代的后期阶段逐步降低学习率,这会帮助网络更快收敛,更容易接近最优解。在每轮的迭代过程中都使用验证数据集对网络进行校正,在验证的准确度收敛时提前结束网络训练,这样可以预防网络对训练数据集出现过拟合的现象。受图形计算卡的内存大小限制,设置大小为6的小批量来减少训练时的内存使用量。
2.2 评价指标
语义分割有3个业界常用的评价指标,分别为像素精度(Pixel Accuracy, PA)、平均像素精度(Mean Pixel Accuracy, MPA)、平均交并比(Mean Intersection over Union, MIoU)。假定语义分割结果有+1类(包括个目标类和1个背景类,背景类不计入计算),表示真正(True Postives, TP)的像素数量,表示假正(False Positives, FP)的像素数量,表示假负(False Negatives, FN)的像素数量。式中(4—6)中∈[1,…,]。
(4)
(5)
(6)
2.3 实验结果与分析
2.3.1 CamVid数据集测试
CamVid(Cambridge driving Labeled Video)是一个城市场景数据集,拥有以每秒30帧的速度以960×720像素捕获的4个高清视频序列,所有视频的总时长约22 min,40 K帧。并且挑选出了701张主要的城市道路场景图片。数据是从驾驶汽车的角度拍摄获取的,因为驾驶场景更加符合日常交通生活的情况,同时也增加了观察对象的数量和异质性。每张带注释的图片都由第2个人检查并确认其准确性。在实验中,对CamVid数据集里的60%图像用以训练网络,其余的图像平均分为20%和20%用作验证集和测试集。由于数据集的样本数量有限,因此使用随机地左/右翻转和随机地/平移±20个像素来进行数据增强,从而向网络发送更多的训练样本,以此提高网络的准确度。
文中主要以DeepLabv3+网络和经典的轻量级网络Mobilenetv2作为对比实验。同时加入3个有相关性的神经网络模型作为参照,结果见表1,可明显看出文中方法在前3个评价指标上都优于参照网络,MIOU指标在DeepLabv3+网络的基线上提升了将近2个百分点,PA和MPA指标也有小幅的提高。这要得益于通道注意力机制模块和空间注意力机制模块在骨干网络中的应用,以及DASPP模块的多尺度信息采样,文中的网络能够在编码器结构中高效地提取输入图像的特征信息,进而提高网络分割图像的精度。在网络参数量的比较上,文中的网络为22.4 M相较于DeepLabv3+网络的25.6 M减少了12%,基于深度可分离卷积的Mobilenetv2网络参数量仅为3.6 M,在占用极小空间的基础上实现了较好的分割效率,这体现出深度可分离卷积在降低网络复杂度,减少计算的冗余量,加快网络训练时间方面的有效性。综合权衡网络分割精度和网络的参数量,相较于DeepLabv3+网络,文中提出的网络能够提高分割精度的同时降低网络的参数大小。
语义分割的目的是把图像中不同类别的目标分割出来,因此除了上述的比较外,文中还对不同目标类别的分割精度做了罗列(表2)可以看出这3种网络的共同点在于对于天空、道路、建筑、行人等语义目标的分割精度较高。主要的原因是这几类目标在图像中所占像素的比例较高,因此能够取得良好的分割效果,而像道路杆、标志符号和围墙这类目标,由于本身像素较少,且语义特征不明显,因而分割的精度较低。文中的网络相较于Mobilenetv2和DeepLabv3+网络,效果均有一定程度的提升。
Mobilenetv2,DeepLabv3+和文中网络在CamVid数据集上部分图片的分割可视化结果见图6。
评价语义分割网络的好坏直接取决于网络得到的分割图像与其对应标签图像的重合程度。在可视化的结果中,相较于Mobilenetv2和DeepLabv3+,文中的网络对于大部分类具有更好的分割效果。在第1张图中,3个网络对于近视角的路灯都有较不错的分割能力,但是在远处与树木混合的第2个路灯只有文中的网络较好地捕获到了这一信息并分割出来,而前两者的网络把这个路灯归到了树木的类别中。在第2和第4张图中,前2个网络对于行人这一类的分割效果不理想,行人的轮廓相较于标签图像被扩大了很多,也就是说网络判定为行人的像素数量大大多于标签标记的像素数量。与此同时,文中的网络对于行人类目标的分割情况与标签图像更加匹配,轮廓扩张不明显。还有车辆类目标的分割效果对比中,文中网络相较于前2个,对于车辆外形轮廓的分割拥有更好的连续性和准确性。
2.3.2 Cityscapes数据集测试
Cityscapes是高分辨率城市场景的数据集,包含2048像素×1024像素的街景图像和对应标签。其任务是在汽车摄像头拍摄的视频中分割物体。该大型数据具有来自不同城市街道场景中记录获得的多种立体视频片段,除20 000张弱注释帧以外,还包括5000帧高质量像素级注释。在实验中使用了精细注释的数据集,其中有2975张训练图像和500张测试图像。
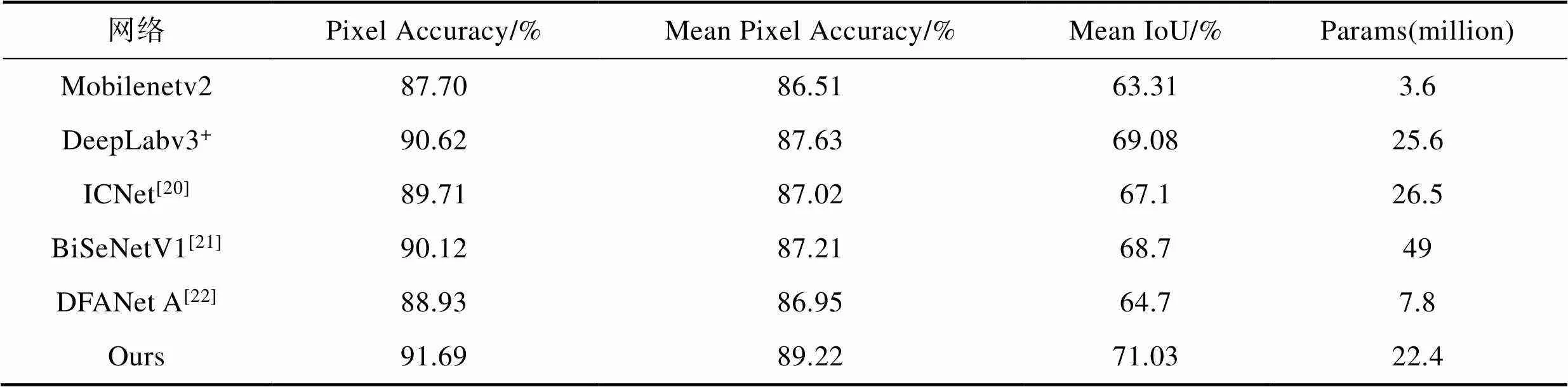
表1 CamVid数据集上不同评价指标的结果

表2 CamVid数据集上11个主要类别的分割结果

图6 CamVid数据集上的部分可视化分割结果
在Cityscapes数据集上的实验结果见表3。可以看出,文中网络性能在Miou这个主要评价指标上依然优于其他的几个网络,对处理高分辨率图像也取得了较好的分数,这也说明文中网络具有比较强的泛化性。文中模型在测试集上实现了较好的准确性,以及准确性与参数量之间的权衡。
Cityscapes数据集上的部分可视化分割结果见图7。4张分割结果图都显示在车头部分出现了较明显的错误,这主要是由于标签图像将其定义为无意义像素区域,但在实际分割结果输出中依然会对该区域进行分割,且车辆行进过程中车前盖会镜面倒映出不同的街道场景,故产生了这个现象。此外,对于大目标像素区域如天空、道路、车辆,文中网络展现出了良好的分割效果。对于小目标像素区域如交通标志,分割效果就出现了参差。

表3 Cityscapes数据集上的结果

图7 Cityscapes数据集上的部分可视化分割结果
综上所述,文中优化后的DeepLabv3+网络拥有更加好的分割精度,对于不同目标类别边缘分割更加平滑,同时得益于卷积方式的优化,文中网络能够在实现更好分割效果,并且降低了参数量。
3 结语
文中提出了一种优化DeepLabv3+网络的图像语义分割算法,通过加入通道注意力和空间注意力机制模块,让网络学习特征图的重要信息及其位置,有效提高了骨干网络提取特征信息的能力;引入DASPP模块,相较于原网络模块,能更加有效地利用特征图中的多尺度语义信息,获得更大的密集特征以及感受野;将原始卷积模块替换为深度可分离卷积,有效地降低了网络训练的运算量,提高了网络的训练速度。实验结果证明,在CamVid和Cityscapes数据集上文中网络能够一定程度上提升分割的精度,同时优化了网络的计算消耗,减少了网络的体量。后续进一步研究提升网络对小目标类别的分割精度,加强不同类别边缘的分割精细程度。
[1] 陈鸿翔. 基于卷积神经网络的图像语义分割[D]. 杭州: 浙江大学, 2016: 7-10.
CHEN Hong-xiang. Semantic Segmentation Based on Convolutional Neural Networks[D]. Hangzhou: Zhejiang University, 2016: 7-10.
[2] JHA D, RIEGLER M A, JOHANSEN D, et al. Doubleu-net: A Deep Convolutional Neural Network for Medical Image Segmentation[C]// 2020 IEEE 33rd International Symposium on Computer Based Medical Systems (CBMS), 2020: 558-564.
[3] SUN L, YANG K, HU X, et al. Real-Time Fusion Network For RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 5558-5565.
[4] WURM M, Stark T, Zhu X X, et al. Semantic Segmentation of Slums in Satellite Images Using Transfer Learning on Fully Convolutional Neural Networks[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 150: 59-69.
[5] KING A, Bhandarkar S M, Hopkinson B M. A Comparison of Deep Learning Methods for Semantic Segmentation of Coral Reef Survey Images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018: 1394-1402.
[6] LONG J, Shelhamer E, Darrell T. Fully Convolutional Networks for Semantic Segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431-3440.
[7] RONNEBERGER O, Fischer P, Brox T. U-net: Convolutional Networks for Biomedical Image Segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Cham, 2015: 234-241.
[8] Yoo D, Park S, Lee J Y, et al. Multi-Scale Pyramid Pooling for Deep Convolutional Representation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2015: 71-80.
[9] Chen L C, Papandreou G, Kokkinos I, et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs[C]// Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 2014: 357-361.
[10] Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(4): 834-848.
[11] Chen L C, Zhu Y, Papandreou G, et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation[C]// Proceedings of the European Conference on Computer Vision (ECCV), 2018: 801-818.
[12] 段立娟, 孙启超, 乔元华, 等. 基于注意力感知和语义感知的RGB-D室内图像语义分割算法[J]. 计算机学报, 2021, 44(2): 275-291.
DUAN Li-juan, SUN Qi-chao, QIAO Yuan-hua, et al. Attention-Aware and Semantic-Aware Network for RGB-D Indoor Semantic Segmentation[J]. Chinese Journal of Computers, 2021, 44(2): 275-291.
[13] 周勇, 陈思霖, 赵佳琦, 等. 基于弱语义注意力的遥感图像可解释目标检测[J]. 电子学报, 2021, 49(4): 679-689.
ZHOU Yong, CHEN Si-lin, ZHAO Jia-qi, et al. Weakly Semantic Based Attention Network for Interpretable Object Detection in Remote Sensing Imagery[J]. Acta Electronica Sinica, 2021, 49(4): 679-689.
[14] 赵宝奇, 尉飞, 孙军梅, 等. 结合密集连接块和自注意力机制的腺体细胞分割方法[J]. 计算机辅助设计与图形学学报, 2021, 33(7): 991-999.
ZHAO Bao-qi, YU Fei, SUN Jun-mei, et al. Glandular Cell Segmentation Method Combined with Dense Connective Blocks and Self-Attention Mechanism[J]. Journal of Computer-Aided Design and Computer Graphics, 2021, 33(7): 991-999.
[15] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]// Proceedings of the European Conference on Computer Vision (ECCV), 2018: 3-19.
[16] Yang M, Yu K, Zhang C, et al. DenseASPP for Semantic Segmentation in Street Scenes[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 3684-3692.
[17] SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: Inverted Residuals and Linear Bottlenecks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520.
[18] ZHAO H, QI X, SHEN X, et al. Icnet for Real-time Semantic Segmentation on High-resolution Images[C]// Proceedings of the European Conference on Computer Vision (ECCV), 2018: 405-420.
[19] YU C, WANG J, PENG C, et al. Bisenet: Bilateral Segmentation Network for Real-time Semantic Segmentation[C]// Proceedings of the European Conference on Computer Vision (ECCV), 2018: 325-341.
[20] LI H, XIONG P, FAN H, et al. Dfanet: Deep Feature Aggregation for Real-Time Semantic Segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9522-9531.
Image Semantic Segmentation Based on Enhanced DeepLabv3+Network
ZHENG Bin-jun1, KONG Ling-jun2
(1.University of Shanghai for Science and Technology, Shanghai 200093, China; 2.Shanghai Publishing and Printing College, Shanghai 200093, China)
The work aims to propose an image semantic segmentation optimization method based on DeepLabv3+network, so as to achieve good image semantic segmentation accuracy, reduce the amount of network parameters as much as possible and speed up network training. The backbone network of encoder was added with attention module and more intensive feature pooling module was used to effectively aggregate multi-scale features. The depthwise separable convolution was applied to reduce the computational complexity of the network. According to the comparison test based on CamVid data set, MIoU score of the enhanced network reached 71.03%, and pixel accuracy and other evaluation indexes such as average pixel accuracy slightly improved compared with the original network. Furthermore, parameters of network were reduced by 12%. The Miou score on the test data set of cityscapes was 75.1%. According to the experimental results, the improved network can effectively extract the feature information of image, improve the semantic segmentation accuracy, and reduce the complexity of the model. The proposed network is tested by the urban street scenes, which can provide reference for the future application of driverless technology, and has certain practical significance.
semantic segmentation; attention module; depthwise separable convolution; encoder-decoder
TP391
A
1001-3563(2022)01-0187-08
10.19554/j.cnki.1001-3563.2022.01.024
2021-08-20
一流专科高等职业教育专业建设项目(2020ylxm-1)
郑斌军(1997—),男,上海理工大学硕士生,主攻数字图像处理、计算机视觉和深度学习。
孔玲君(1972—),女,博士,上海出版印刷高等专科学校教授、硕导,主要研究方向为图文信息处理与色彩再现,数字印刷及质量评价等。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2017年9期)2017-05-27
电子技术与软件工程(2016年24期)2017-02-23
长江学术(2015年1期)2015-02-27
职业·中旬(2009年12期)2009-06-01
