
基于LightGBM 和随机森林算法的二手车估价
2022-02-02 03:38代金辉仲璇王梦恩
高师理科学刊 2022年12期
代金辉,仲璇,王梦恩
(山东工商学院 统计学院,山东 烟台 264005)
据二手车业内人士分析,二手车的大众接受度之所以逐渐得到提升,主要是因为受到芯片短缺、二手车增税减少等利好政策和经济下行的影响,二手车低成本、高性价比的优势越来越得以凸显.数据显示,近年来,我国的二手车交易量持续增长,从2000 年的25.17 万辆增长到2019 年的1 492.3 万辆.在新冠疫情爆发后,虽然二手车的销售量受到疫情的冲击,但2021 年二手车销量增幅仍创新高,相较于2020 年,二手车交易量增幅高达22.62%.二手车市场之所以呈现出如此迅猛发展的态势,究其原因,一方面,人们受新冠肺炎疫情的影响,对私家车的需求有所增加;另一方面,由于疫情对经济发展产生了一定的影响,这使得人们降低消费预期转而着眼于拥有更高性价比的二手车.
虽然二手车市场在疫情的冲击中展现了其强大的韧性,并且在现在乃至将来存在着巨大的发展潜力,然而,二手车市场的问题也随着其繁荣发展逐渐显露.二手车“一车一况”的特性决定了其交易的复杂性,二手车品牌众多,不同品牌车系复杂,损坏程度也不同,其价格受多方面因素的影响,价值难以准确估计和设定.同时,在二手车交易市场中,买卖双方的信息不对称无疑增加了二手车价格评定的难度.再加上国家尚未出台二手车评估的统一标准,因此,亟需建立一套合理的估价体系,采用更科学准确的估价模型来帮助规范二手车市场的定价业务,完善二手车市场的信用体系,以保证二手车实现顺利交易.
1 数据来源及算法介绍
1.1 数据来源
数据来源于2021 年MathorCup 高校数学建模挑战赛大数据竞赛赛道A[1],包含4 个附件:(1)附件1为估价训练数据,给出了30 000 条数据,主要数据有车辆id、展销时间、品牌、车系id、车型id、里程、颜色、车辆所在城市id、国标码、过户次数、载客人数、注册日期、上牌日期、国别、厂商类型、年款、排量、变速箱、燃油类型、新车价、匿名特征1~15、二手车交易价格等,共计36 列;(2)附件2 为估价验证数据,给出了5 000 条数据,与附件1 数据相同,但缺少二手车交易价格数据;(3)附件3 存放估价模型结果;(4)附件4 为门店交易训练数据,给出了10 000 条数据,包括6 个字段,分别为车辆id、上架时间、上架价格、价格调整时间及调整后价格、下架时间、成交时间.
1.2 算法介绍
1.2.1 LightGBM算法 GBDT(Gradient Boosting Decision Tree)是一种基于决策树的集成算法,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型.LightGBM(Light Gradient Boosting Machine)是实现GBDT算法的框架,该算法有高效的训练效果,并具有更快的训练速度、更高的精确度、更好的准确率,具有高效处理海量数据等优点.相对于XGBoost算法,LightGBM主要对特征数量、分裂点的数量和样本的数量3个因素分别优化[2].
1.2.2 随机森林算法 随机森林是以决策树为基学习器的集成学习算法,可以处理多类型的变量[3],在对特征重要性评估上有较好的表现.随机森林算法是由多个决策树加权集合构成的,采用多个决策树的投票机制来改善决策树容易过拟合的特点.随机森林对特征重要性评估的思想就是看每个特征在随机森林中做了多大的贡献,特征选择的准则主要有信息增益、信息增益率和基尼指数[4].
2 模型假设及符号说明
为简便起见,假设:(1)样本缺失值较多的数据能为有效预测提供的必要信息较少;(2)二手车未来年限内能够正常使用;(3)二手车交易市场车源充足,信息公开;(4)影响二手车价格变动的宏观因素相同.文中相关符号及含义见表1.

表1 符号说明
在软件处理中,由于相关软件只识别英文字母,故采用英文字母进行相关数据分析,即carid(车辆id)、tradeTime(展销时间)、brand(品牌)、serial(车系id)、model(车型id)、mileage(里程)、color(颜色)、cityId(车辆所在城市id)、carCode(国标码)、transferCount(过户次数)、seatings(载客人数)、registerDate(注册日期)、licenseDate(上牌日期)、country(国别)、maketype(厂商类型)、modelyear(年款)、displacement(排量)、gearbox(变速箱)、oiltype(燃油类型)、newprice(新车价)、anonymousFeature1~15(匿名特征1~15)、price(二手车交易价格).
3 数据预处理及初步分析
3.1 数据预处理
由于二手车交易样本数量过多、变量过多等因素,导致估价训练数据和估价验证数据存在缺失值或重复值,无法直接对数据进行分析.为了改善上述情况,提高后续模型预测结果的精确度和可靠性,因而对二手车数据集进行预处理.数据预处理的步骤分为数据清洗(包括去除重复值、填补缺失值)、数据转换和特征处理3部分.
3.1.1 数据清洗 数据清洗的基本步骤为:
Step1查看和填补缺失值.运用Python 中pandas库对附件1和附件2 中的数据进行读取,判断数据缺失和异常.通过可视化查询缺失值,结果见图1.

图1 训练数据和测试数据缺失值分布
由图1可以看出,数据集包含连续数据集和非连续数据集,若将含有缺失值的非连续数据集全部去除,则会造成数据的浪费,为了有效地利用数据集进行研究分析,需要采取缺失值填补的方法,使用fillna()函数将含有较少缺失值的数据采用众数填补,从而为下一步研究提供足够大的数据量,以增强后续算法模型的准确率和泛化性能.其中carCode(国标码)、modelyear(年款)、country(国别)、maketype(厂商类型)、anonymousFeature1,11(匿名特征1,11)缺失值较少,采用众数填充;anonymousFeature4,7,8,9,10,13,15(匿名特征4,7,8,9,10,13,15)缺失值较多,选择删除该字段所在列,最终训练数据中保留29列变量信息,测试数据中保留28列变量信息.
Step2去除重复值.运用Python 中duplicated()函数判断数据是否存在重复,drop_duplicates()将重复的数据行进行删除.去除重复值是为了防止在数据集中出现相同的数据,导致异常结果以至于影响最后的算法精确度.
3.1.2 数据转换 附件1数据集中给出的日期格式是xxxx-xx-xx,不利于进行数据处理,对tradeTime(展销时间),registerDate(注册日期)和licenseDate(上牌日期),提取时间信息并转换为xxxx 年xx 月xx 日形式,同时删除原数据,便于后续算法识别.对附件4 中的updatePriceTimeJson进行处理,以“,”作为分隔符将其分为12 个数据,统计每一列调价记录次数、调价幅度以及与新车的价差比.
3.1.3 特征处理 为了让数据更具有可读性和方便算法识别,避免数据影响算法,对数据进行特征处理.采用字典对附件1中匿名特征11进行处理,将对应的值变为特定数值,以方便算法处理;对匿名特征12 的处理,采用将三维特征值转变为3个一维特征值的方法,同时去掉原有的三维特征值;对附件4 中的成交时间与上架时间做函数运算,得到交易时间,进而可算得交易周期.
3.2 数据分析
3.2.1 异常值查看 为了确保后续预测结果的准确性,必须对训练数据集进行异常值查看,如出现较为明显的数据异常情况,需要对异常值进行适当的调整.在处理训练数据缺失值后剩余的29个变量基础上进行异常值的查看,其中,日期类型数据如展销日期、注册日期和上牌日期以及车辆id、经过特征处理的匿名特征11和匿名特征12 均不需要进行异常值查看,故此处仅查看23个变量的异常值情况,数据分析结果见图2(限于篇幅,仅展示8个特征的异常数据分布情况,分别为品牌、车系id、车型id、里程、颜色、车辆所在城市id、国标码、过户次数).图2中8个特征均不存在异常值,经检验,载客人数、国别、厂商类型、年款、排量、变速箱、燃油类型、新车价、匿名特征1、匿名特征2、匿名特征3、匿名特征5、匿名特征6、匿名特征14、二手车交易价格数据同样没有异常值.综上,23个变量数据均在正常范围内.
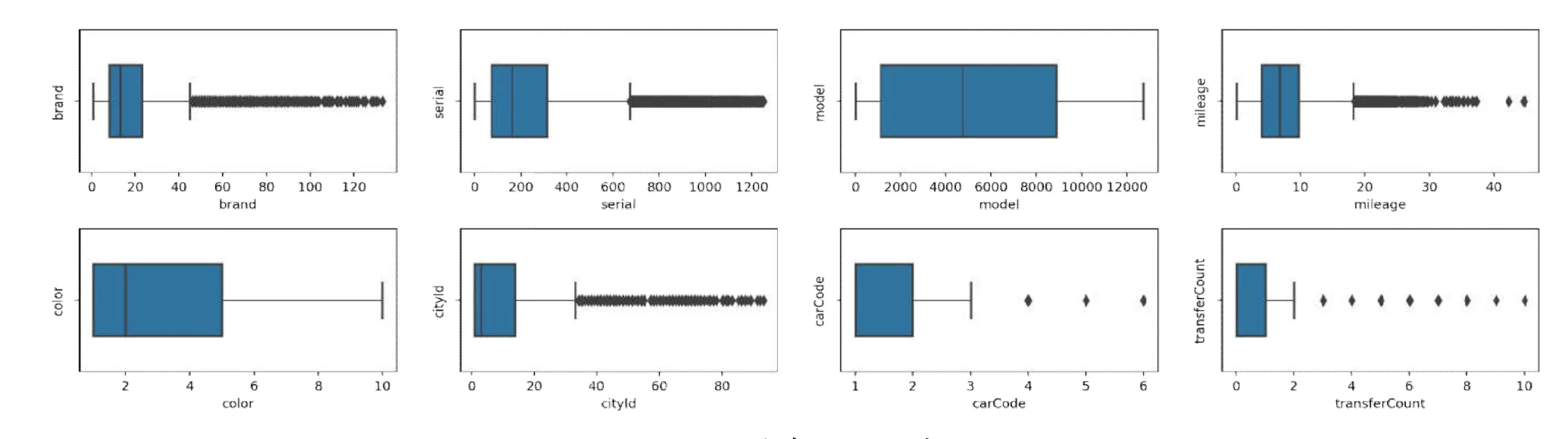
图2 异常数据分布
3.2.2 数据分布 由于所有字段的数据分布影响到最后的分析结果,因此需要查看附件1和附件2的具体数据分布情况,通过了解数据的分布情况,以便后面进行特征相关性分析.训练数据中包含36列变量,测试数据中包含35列变量,缺少“二手车交易价格”这一列.由于二手车交易价格数据仅在训练数据中,故在此不进行展示.于是在查看异常值的23个变量基础上去掉二手车交易价格这一变量查看数据分布,得到22个特征字段的数据分布见图3(其中:红色区域为训练集的数据分布,蓝色区域为测试集的数据分布).
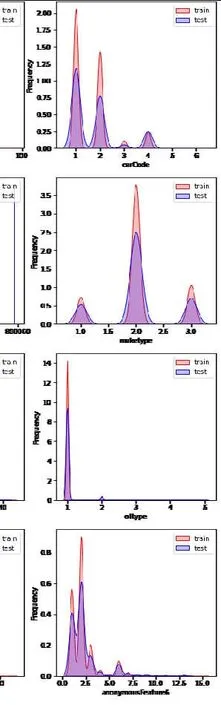
图3 特征字段数据分布
由图3可以看出,红色区域和蓝色区域大体重合,这说明训练集和测试集的数据分布情况几乎相同.
3.2.3 相关性查看 二手车交易价格的影响因素包括但不限于车况条件、里程、品牌、过户次数、使用时间等.由于影响因素过多,需要对其进行相关性查看和数据处理,以便对后续定价与调价有更理想的作用,更快地促成成交.
计算特征变量的相关矩阵(见图4,其中第1~23 行分别为二手车交易价格、新车价、排量、匿名特征2、年款、厂商类型、变速箱、匿名特征5、车型id、载客人数、车系id、过户次数、品牌、匿名特征6、燃油类型、匿名特征1、匿名特征3、国别、匿名特征14、国标码、颜色、车辆所在城市id、里程,对应的列相同).此处仍然是在处理训练数据缺失值后剩余的29 个变量基础上进行相关性的查看,由于车辆id、展销日期、注册日期、上牌日期、匿名特征11、匿名特征12 与二手车交易价格的相关系数均小于0.001,可忽略不计,故在相关矩阵图中予以剔除.
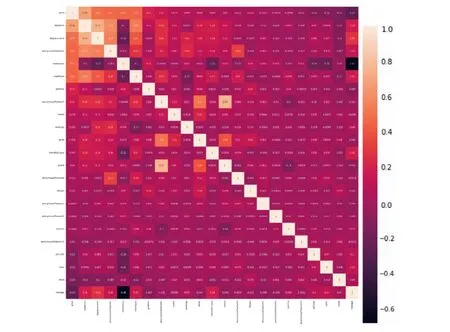
图4 特征变量相关矩阵
由图4可以看出,匿名特征5和排量相关系数高达0.76,存在显著性正相关;排量与新车价相关系数为0.75,说明它们之间存在较强的相关性.此外,新车价、排量、匿名特征2、年款、厂商类型均与二手车交易价格存在不同程度的正相关性,且相关性呈现递减的趋势;国别、国标码、颜色、车辆所在城市id以及里程均与二手车交易价格存在负相关性,且相关性递减.
4 二手车交易价格预测及成交周期特征重要性分析
4.1 基于LightGBM算法的二手车价格预测
对预处理后的数据进行描述统计,部分数据见表2.
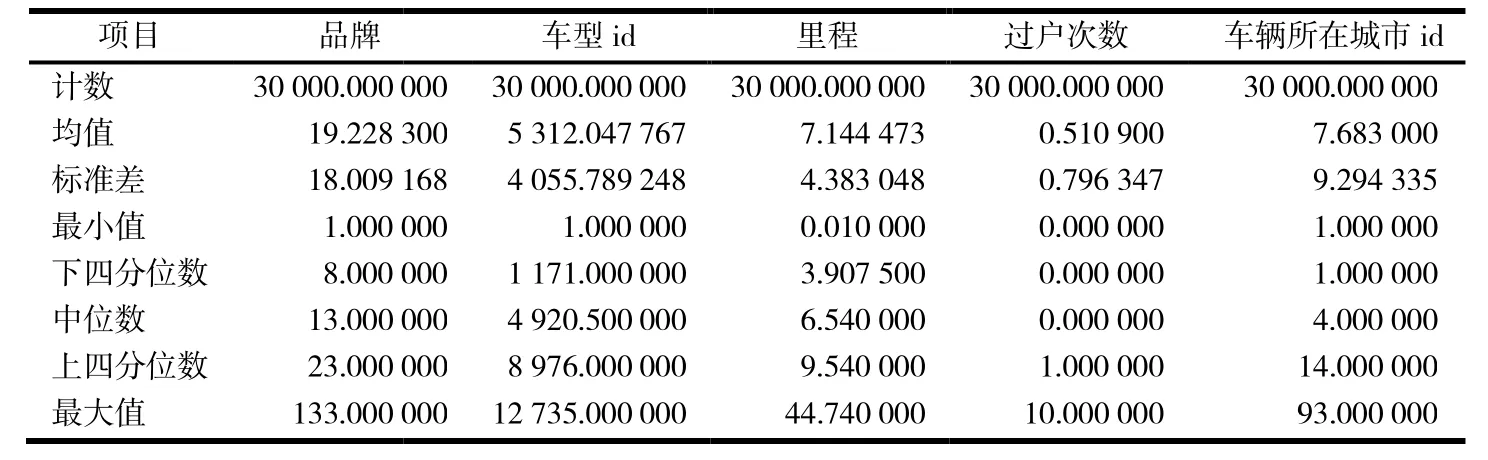
表2 样本数据描述统计
使用Python中的log1p对数的右偏变换函数,将数据分布转变为近似正态分布.而后筛选数据并归一化,对大于75的异常值予以舍弃.模型评测标准为 0.2(1-Mape)+0.8Accuracy5,式中:Mape为平均相对误差,计算公式为,m为需要预测交易价格的二手车数量,即测试数据总条数,取值为5 000,Apei为第i辆二手车交易价格预测值的相对误差,计算公式为为第i辆二手车交易价格的预测值,yi为第i辆二手车交易价格的实际值;Accuracy5为5%误差准确率,计算公式为Accuracy5=为相对误差Apei在5%以内的样本数量,count(total)为样本总数量.
考虑到模型评测标准,使用LightGBM 算法,采用6 折划分训练[5-7],训练次数从10 000 次到500 000 次,其中训练10 000 次可以达到模型评估结果84.8%的效果;训练500 000 次,可以达到模型评估结果86.7%的效果.部分预测结果见表3.
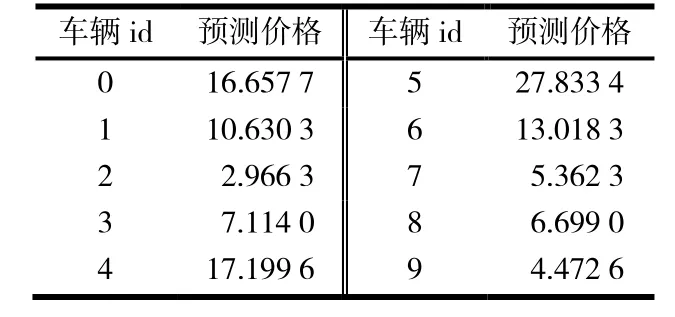
表3 估价模型结果 万元
4.2 基于随机森林的成交周期特征重要性分析
影响二手车成交周期的因素多种多样.基于附件1 中剔除车辆id 和缺失值较多变量后剩余的28 个变量以及附件4 中剔除车辆id 后经过分解得到的6 个变量的数据,加之包含调价次数、最后售卖价格、价差比以及成交周期在内的4 个自定义变量,最终确定选择包括品牌、里程、车型等在内的38 个特征变量,使用随机森林算法选择影响二手车成交周期的关键特征[8-9].
本文选择基尼指数来评估特征变量的重要性.基尼指数反映样本集合中一个随机选中的样本被分错的概率.基尼指数越小,表示集合中被选中的样本被分错的概率越小,集合的纯度越高;反之,集合越不纯.

使用随机森林算法对二手车成交周期特征的重要性进行计算,筛选出重要性大于0.2 的特征并进行排序(见图5).
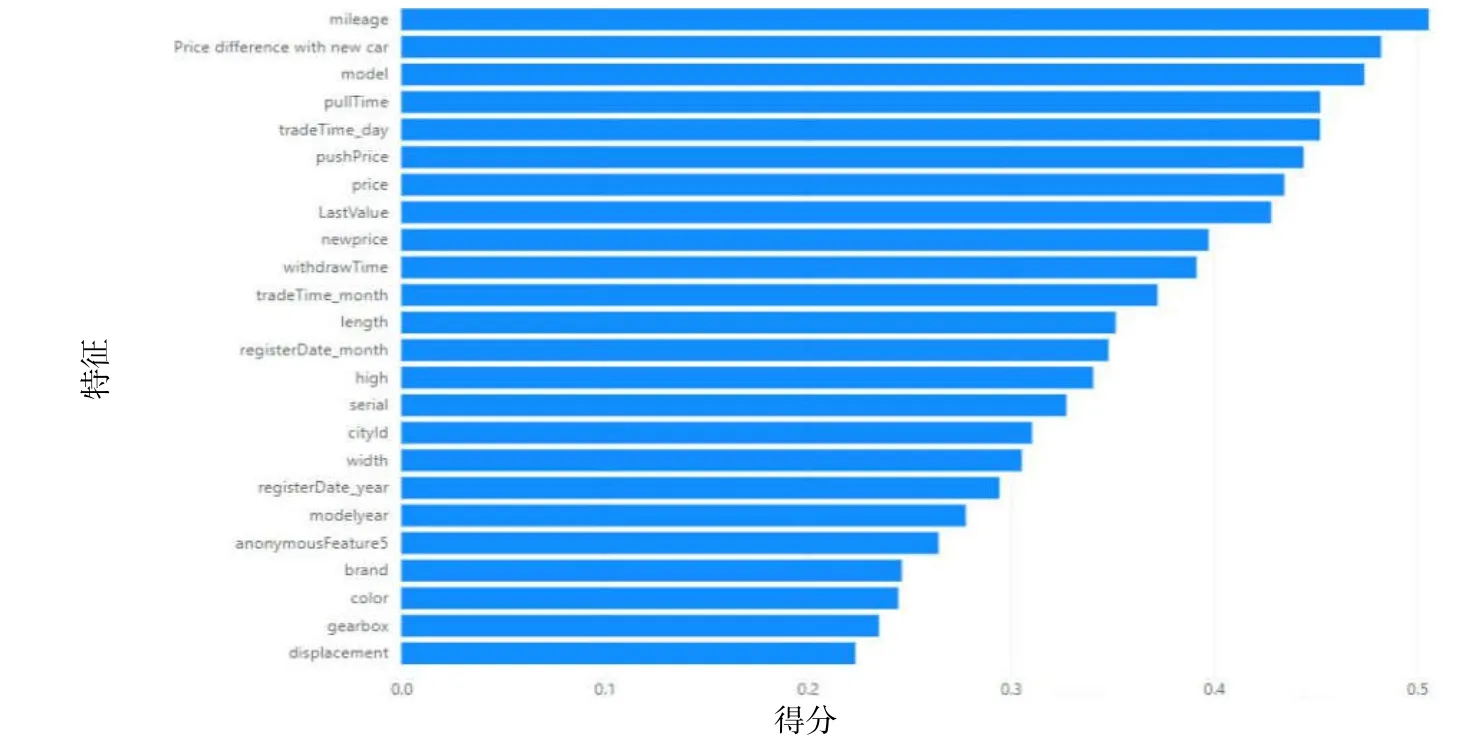
图5 二手车成交周期特征重要性排序
由图5 可以看出,二手车的里程是影响成交周期最重要的因素,根据里程数可以判断车辆的使用频率、使用强度,从侧面反映了具体车况,是购车者考虑的重要指标.影响在库车辆销售速度的关键因素还有二手车最终的出售价与新车价格差的比值、二手车的车型、上架时间以及上架价格,反映了购买者主要从车况和价格2个方面考虑是否购买二手车.
根据已有的数据分析,已成交二手车大部分集中在车辆上架的0~14 d 之内卖出(见图6).本文结合成交周期对二手车的部分特征进行更深入的分析,已成交二手车的里程以及价差与新车价格的比值(价差比)分别见图7~8.

图6 已成交二手车的成交周期
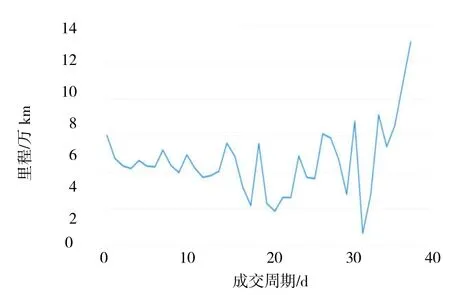
图7 已成交二手车的里程与成交周期
由图7 可以看出,里程在6~8 万km 的二手车更容易卖出,里程在4~6 万km 的二手车卖出的速度相较于6~8 万km 的车售出的速度较慢.销量小且成交速度更慢的二手车里程分布波动大.一般来说,二手车跑的里程数越少,其损害程度越小,成交周期应相对较短.但是从分析的结果可知,里程在6~8 万km范围内更受客户的青睐,说明客户购车意愿受价格、车型等其他因素的影响,也从侧面反映了大部分客户对于二手车里程数的需求低于8 万km.
由图8 可以看出,成交周期在0~20 d 的二手车,其价差比主要在0.4~0.6 之间,成交周期长的二手车其价差比随着成交周期的延长波动幅度增大.这说明价差比在0.4~0.6 之间的二手车更受客户青睐,极少数客户会选择购买价差比低于0.4 或高于0.8 的二手车.这一指标也反映了二手车的保值率,说明了虽然保值率高的二手车其质量会相对好一些,但是它的价格也相对较高,违背了人们追求用尽可能低的成本去享受更好品质的心理.一些保值率相对较低的二手车,反而性价比相对较高.
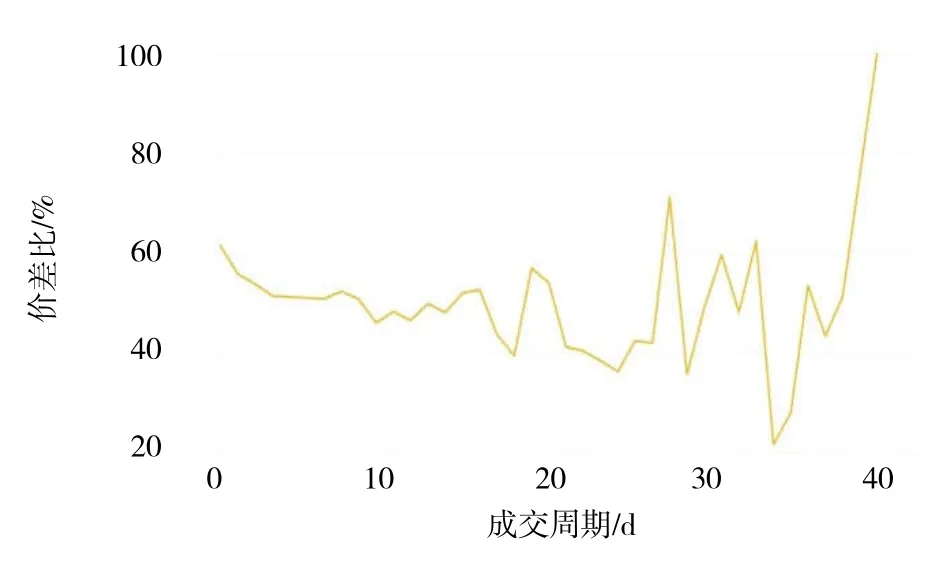
图8 已成交二手车的价差比与成交周期
5 结论及建议
5.1 结论
本文在数据处理的基础上,通过查看异常值、数据分布情况以及各特征变量之间的相关性,对数据进行分析,并对部分数据进行描述统计.而后通过构建基于LightGBM 算法的二手车估价模型,对二手车价格进行预测,最后使用随机森林算法对影响成交周期的各因素的重要程度进行探究.得到如下结论:
(1)采用6 折划分训练进行预测,通过不断增加训练次数,使得预测准确率不断提高,当训练次数达到500 000 次时,算法预测准确率达到最高,为86.7%,预测效果较为理想.
(2)在影响二手车成交周期的诸多因素中,里程、价差比为关键影响因素.其中,里程在6~8 万km的二手车更容易畅销,这从一定程度上反映了大部分客户对于二手车里程数的需求小于8 万km.价差比在0.4~0.6 范围内的二手车成交周期较短,更受客户青睐,同时还说明保值率相对较低的二手车其性价比反而相对较高.
截至目前,精准评估二手车的价格仍是一项十分困难的工作,但是基于机器学习建立模型实现预测具有极为广阔的应用空间.本文在一定程度上可以为二手车市场提供一个简单的定价思路,同时为缩短交易周期提供一系列建议.
5.2 建议
基于对部分特征的分析,结合实际的销售场景,为加快门店在库车辆的销售速度提出建议:
5.2.1 建立品质评价体系 在分析车况时,要关注二手车的里程等影响因素,以此来判断车辆的等级.购买者只有了解了二手车的具体车况并结合价格来判断二手车的性价比,才能最终决定是否购买二手车.针对这一情况,二手车市场可以建立二手车品质鉴定体系[10-14],对二手车进行质量检测,根据车辆识别代码的唯一性为每辆二手车建立档案,编写品质情况与使用情况报告,方便销售人员以及购买者对二手车的真实状况做出合理的判断.
5.2.2 建立二手车价格以及降价体系 应当密切关注新车的价格、二手车上架的时间以及每次调价引起的销售速度的变化.新车型上市时,对应的二手车应进行相应的降价.二手车市场有淡旺季之分,据分析,二手车的成交大多集中在3~7 月份,8 月份之后较前几个月有所减少,但较为平稳.针对这种情况,在销售淡季时,应加大二手车的优惠力度,销售旺季时可以减小降价的幅度.此外,销售人员应重视二手车调价前后销售数量、销售额以及销售利润等的变化.根据调价之后的销售状况对价格进行调整或为下一次调价提供参考,以确定下一次的调价幅度.
在门店的实际销售场景中,要在不同的时间段及时了解客户的需求,并结合当前的销售市场,不断调整销售策略.门店根据所做的综合分析,可利用随机森林回归算法和BP 神经网络对二手车的售出价格、降价幅度进行及时的调整.最终门店不仅能提高自己的销售速率、节省资源,还能促使整个二手车行业保持稳定发展.
猜你喜欢
中国特种设备安全(2022年5期)2022-08-26
全面腐蚀控制(2021年7期)2021-10-28
汽车维修与保养(2020年11期)2020-11-23
中国特种设备安全(2019年8期)2019-10-14
中国外汇(2019年9期)2019-07-13
中国经贸(2018年7期)2018-05-10
会计之友(2017年20期)2017-10-25
轻兵器(2017年3期)2017-03-13
江苏农业科学(2016年7期)2016-10-20
车迷(2016年10期)2016-02-14
