
一种分层并行计算的软件化雷达系统*
2022-02-12 05:15李武旭赵浩然
电讯技术 2022年1期
赵 帮,李武旭,赵浩然
(四川九洲空管科技有限责任公司,四川 绵阳 621000)
0 引 言
雷达系统的主要技术发展阶段大致可以分为模拟定制雷达、数字化雷达、软件化雷达、智能化雷达四个阶段[1]。随着数字化技术的发展,雷达系统逐渐从传统“以硬件为核心,功能单一”的开发模式发展到“以软件为中心,面向实际需求”的开发模式。软件化雷达系统具有标准化、模块化、开放式的系统架构,其系统功能由软件定义、扩展、升级,具有开发周期短、费用低、维修升级方便等优点。然而,实时性和数据处理能力作为软件化雷达的两个重要技术指标,也是软件化雷达实现的难点。通常,处理的数据量越大,处理的时间越长,实时性就越差[2]。
已有大量研究和应用表明,在多核中央处理器(Central Processing Unit,CPU)和多处理器环境下,应用适当的并行计算技术能提高计算机系统的运算能力。当前并行技术主要有线程级的基于CPU的多线程并行计算[3-6]、数据级的基于图形处理单元(Graphic Processing Unit,GPU)的并行加速计算[7-9]和系统级多节点的分布式架构[10-12]。不过从这些文献可知,目前大部分研究主要集中在单一模式或CPU加GPU的异构并行设计,并没有充分利用系统的硬件资源。
当前软件化雷达系统的主要瓶颈之一就是对大量高速数据的实时处理能力。实际工程中,各类雷达系统的实时处理数据率在0.6~10 Gb/s,数据量远没达到海量的互联网云计算级别,但仅靠一台通用计算机又达不到实时处理要求,所以就需要设计一套小型的分布式并行计算系统。基于此,本文设计了一种基于任务级、线程级和数据级的三层并行运算系统,充分利用系统的CPU和GPU硬件资源,使得基于任务级,节点数可在线拓展;基于线程级,线程数可灵活配置;基于数据级,可充分发挥计算机GPU并行处理能力。
1 分层并行计算的软件雷达系统架构
软件化雷达系统分层并行计算架构如图1所示,系统由射频前端、数据服务器、译码、点迹和业务终端五个模块组成。
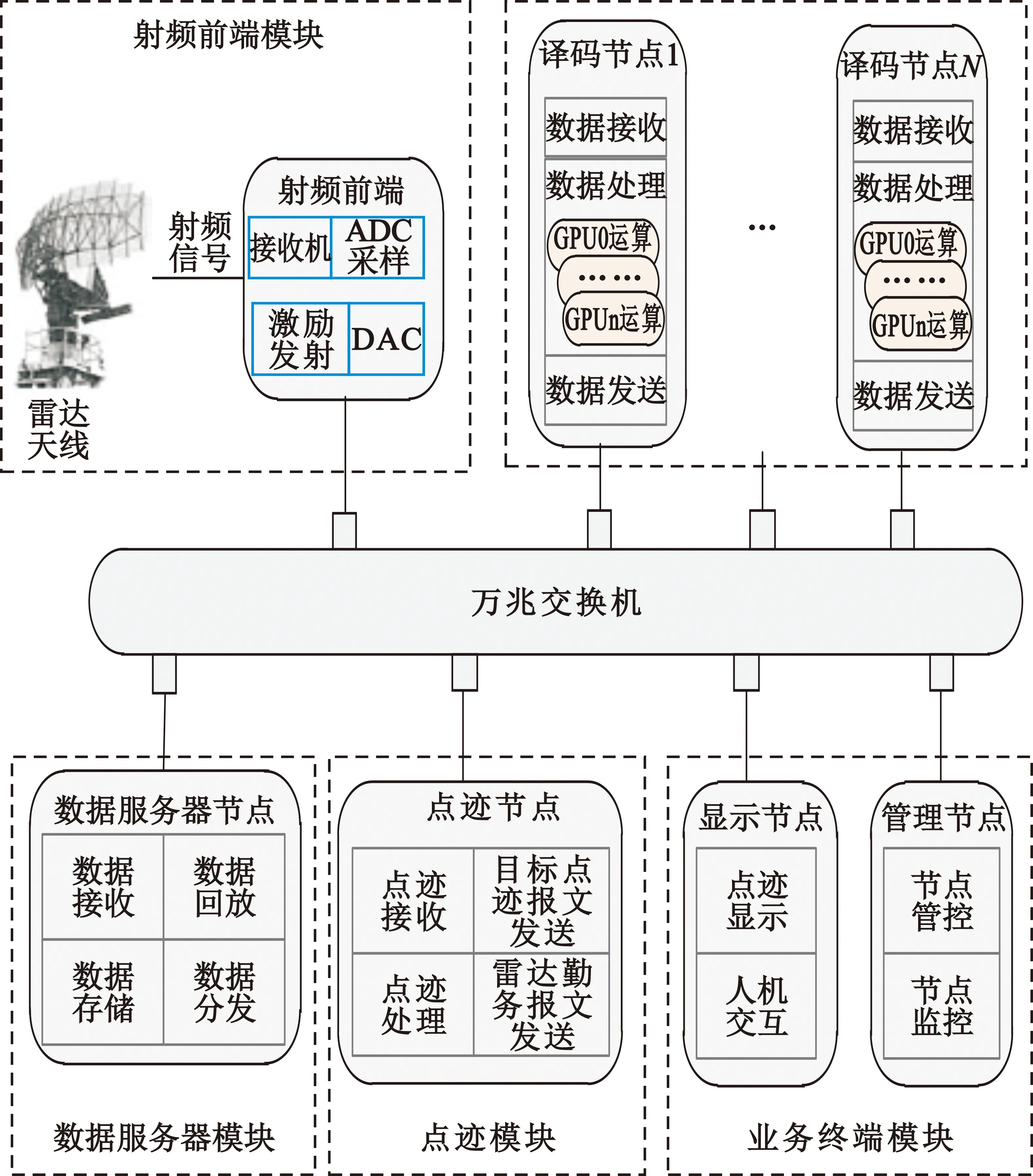
图1 分层并行计算系统架构图
雷达天线接收到信号后,传输给射频前端。射频前端接收机将射频信号转换为中频信号,利用AD/DA高速采样模块对中频信号进行采样,每3 ms产生一个雷达报文的采样数据,数据使用UDP(User Datagram Protocol)网络协议通过万兆光纤传输给数据服务器节点。数据服务器对采样数据进行实时存储和格式转换,为提高数据发送效率,每收到10个雷达报文就发送一次。译码节点并行收取数据和处理数据,译码模块和点迹模块需要在30 ms内完成雷达报文的并行处理,以达到目标的实时显示。
数据服务器模块、译码模块、点迹模块之间采用ZeroMQ技术[13]进行通信。译码模块需要对高速的采样数据进行实时处理分析运算,整个系统的运算量主要集中在译码模块。为满足系统实时性的要求,采用多节点分布式计算,以实现第一层任务级并行计算。数据服务器模块、译码模块、点迹模块基于多线程编程技术,每个模块分为输入线程、处理线程和输出线程。其中,处理线程根据处理数据的实时性要求采用多线程并行处理,实现第二层线程级并行计算。线程内,为提高系统运算效率,采用GPU并行计算技术,实现第三层数据级并行计算。
业务终端模块由显示节点和管理节点组成,显示节点主要是收取目标点迹报文和雷达勤务报文,在显示终端上形成连续的目标点迹。管理节点主要对所有节点进行管理控制和监控,并生成系统运行日志。
2 节点间的任务级分布式计算
2.1 节点间的任务级分布式通信模型的设计
为提高任务级并行计算能力,并解决节点间通信开销大、延迟高、配置复杂的问题,本文引入ZeroMQ技术。ZeroMQ简称ZMQ,是一个消息处理队列库,有“史上最快的消息队列”之称,可在多个线程、内核和主机节点之间弹性伸缩。ZMQ在Socket API之上做了一层封装,将网络通信、进程通信和线程通信抽象为统一的API接口,具有部署简单、性能强大、通信延迟小的特征。该技术能确保系统在任意时间随机加入或撤销一个节点仍然能稳定运行,非常方便开发者搭建属于自己的分布式系统[14]。
ZMQ有简单的请求回应通信模式、广播式的发布订阅通信模式和并行的管道通信模式(推拉模式)三种通信模式。本文采用并行的管道通信模式实现节点间任务级的分布式计算。管道通信模型由上游节点、工作节点和下游节点三部分组成。上游节点负责分发数据,工作节点负责处理数据,下游节点负责收集和汇总数据。数据服务器节点、译码节点和点迹节点分别对应其上游节点、工作节点和下游节点。其分布式通信模型如图2所示。
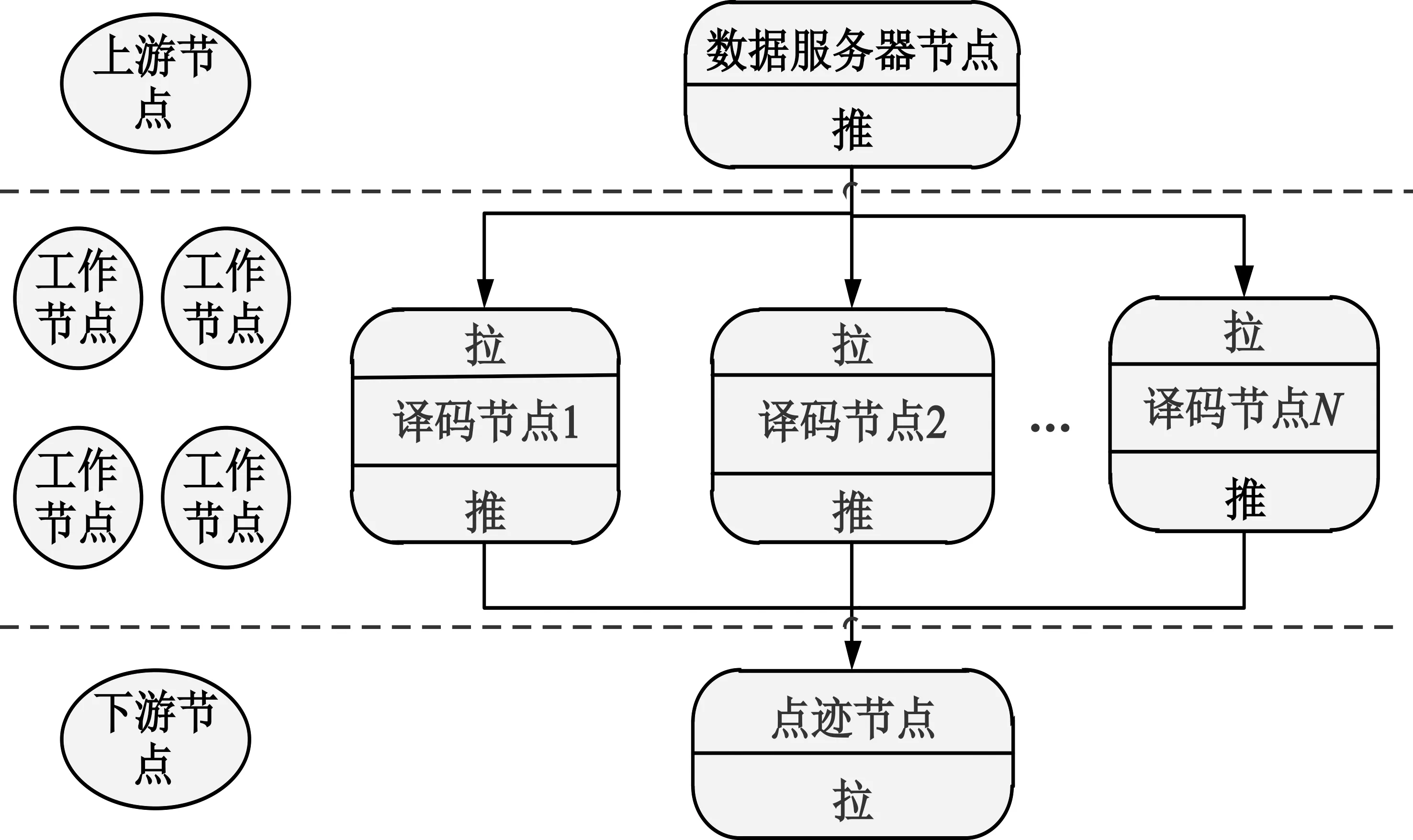
图2 ZMQ分布式通信模型
数据服务器节点为上游节点,与译码节点之间形成一对推拉模式。多个译码节点同时接入数据服务器节点后,数据服务器节点会以负载均衡的方式把数据等份地分给每个译码节点。译码节点属于工作节点,与点迹节点之间形成一对推拉模式。译码节点之间采用公平的队列形式进行数据收发,数据在译码节点上处理完后,将在点迹节点上完成数据融合。最终实现了数据在数据服务器节点、译码节点和点迹节点之间形成一种1∶N∶1的处理模式。工作过程中任一译码节点发生掉线,系统仍能正常运行,其数据将会重新分配到其他工作节点上进行处理。同时当节点负载过高时,本系统支持在任何时间加入译码节点降低节点负载。
2.2 节点间的任务级分布式计算的实现
节点间任务级分布式通信主要是通过数据服务器节点进行数据的分发,译码节点进行数据处理,点迹节点进行数据整合。
数据服务器节点构成了原模型中的上游节点,具有数据分发、存储和回放功能,工作在推模式。
译码节点构成了原模型中工作节点。译码节点可以运行在多个计算机上,并且系统运行中任何时刻译码节点掉线或增加一个译码节点均不影响系统的正常运行。接收数据时工作在拉模式,发送数据时工作在推模式。
点迹节点作为下游节点,其主要作用是接收译码节点的数据,进行数据组合,形成点迹报文和勤务报文发送到显示节点,工作在拉模式。
节点间通信工作流程具体实现如图3所示。

图3 分布式通信工作流程
3 节点内线程级并行计算
分布式系统中节点间的通信是一种进程间的通信。理论上,节点的数量增加,系统的性能会成比例增长。然而事实上,由于节点之间存在通信开销,随着节点数的增长,系统负荷加重,网络通信负载变大,系统数据处理能力反而无明显变化。因此为增强系统的并行处理能力,而简单粗暴的加入节点数并不是一种有效方案。对此本文从细粒度的角度考虑,继续深挖系统单节点的硬件资源。当前多核CPU占主流,采用多线程技术可以充分利用计算机多核的特征,加强单节点的计算能力,从而满足系统运算量大且实时性高的要求。
通过分析总结,系统的每一个节点都存在收数据、处理数据和发送数据的共性。因此,将一个节点分解成3个线程,采用流水线方式进行处理。然而通过试验发现,通常情况下处理线程的数据运算量大且复杂,计算时间长,为整个节点的瓶颈所在。为提高系统并行效率,笔者将处理线程进一步分解为多个线程,设计了一种RnPS的线程模式,如图4所示。其中,R表示收数据线程,P表示处理数据线程,S表示发送数据线程,n表示处理线程的个数。

图4 RnPS的线程模式
进一步分析R收线程、P处理线程与S发送线程发现,R与P、P与S之间正好形成了一对经典的生产者消费者模型:R与P之间,R线程作为生产者线程,P线程作为消费者线程;P与S之间,P线程作为生产者线程,S线程作为消费者线程。由此,每一个节点模型被分解成多个生产者消费者模型[15]。对于解决经典的生产者消费模型的问题本文不再赘述。
此模型中,对于P线程,应重点考虑P线程的个数。P线程的个数主要由以下因素决定:R线程产生的数据量大小和速度;节点CPU核心数;节点需要处理数据的复杂度;节点分解到P线程的任务个数。
由此可见,P线程个数由系统环境等一系列外因决定,并不是一个固定值,系统设计者需要将每个节点的P线程个数设置为可配置状态。在理想状态下P线程所用的时间将与R线程、S线程时间相当。通常情况下,系统内核CPU核心数是一定的,当R线程收到大量高速数据导致P线程来不及处理时,就不能一味地通过增加线程数解决系统延迟的问题了。对此本文下一节将讨论如何利用系统GPU资源增强系统并行运算能力。
4 数据级GPU并行计算
CPU具有处理复杂逻辑和指令级并行的能力,而GPU更适合处理大数据量、高并行、逻辑控制简单的数据。GPU具有大量的可编程内核,可以支持大量的多线程,并且比 CPU 有着更高的峰值带宽,因此,GPU在处理大规模浮点运算上拥有 CPU 无法比拟的优势[16]。
ArrayFire 平台是 AccelerEyes 公司发布的快速开发 GPU 应用程序的开源软件,也是目前最方便、最稳定的 GPU 应用程序开发工具包。ArrayFire 提供了简单的高级矩阵抽象函数,可以让使用者充分利用GPU的硬件优势[17]。
在软件化雷达系统中,通常涉及到信号处理和数据处理的一些常规算法,例如脉冲检测算法、脉冲压缩算法、动目标检测算法、恒虚警检测算法等[18]。这些算法的计算往往就是简单逻辑的大规模浮点运算。基于这个特征,在译码节点上设计了第三层并行计算模型,采用Arrayfire技术实现了节点内的数据级GPU并行计算,充分利用单个节点计算机硬件资源,增强系统计算能力和实时性。
本文以脉冲前沿检测算法为例,介绍在Arrayfire环境下算法的设计实现过程。
在译码节点脉冲检测过程中,首先需要识别出脉冲的前后沿,判断脉冲的有效宽度。以二次雷达应答信号为例,标准脉冲宽度为0.45 μs,由于系统采样率为20 MHz,因此标准脉冲的采样点长度为9。采用延时线的方法,取当前采样点延时半脉冲长度也就是延迟5个采样点,那么脉冲前沿点具有以下特征:
(1)
(2)
用S(n)表示当前采样值,用S(n+5)表示延时5个采样点的值,S(n-1)表示前一个采样点的值,n表示样点个数,那么算式(1)与算式(2)的交集就是脉冲的前沿。样本数n一般是一个非常大的值,以万为单位,那么S(n)将是一个庞大的数组,一个庞大数组的串行计算将严重制约系统的性能。本文利用Arrayfire基于GPU的强大并行运算能力,将大的数组分解成小块,在GPU上进行高速并行计算,实现数据的实时性。其程序设计流程如图5所示。

图5 基于ArrayFire脉冲前沿检测算法的实现
在脉冲前沿检测过程中,ArrayFire 程序只需要定义array就可以实现CPU到GPU的并行处理。其关键代码如下:
array Device_SumBaseband_Amplitude;
//定义和通道电压采样幅度值
array Device_SumBaseband_FrontShift;
//采样值,前移半脉冲并且降低半电压
array Front_CompareArray1;
//大于等于半电压的下标集合
array Front_CompareArray2;
//小于等于半电压的下标集合,且下标加1
array Frontedge_Array;//前沿下标
Device_SumBaseband_FrontShift =
0.5*shift(Device_SumBaseband_Amplitude,5);
//左移5个点,然后×0.5为半电压
Front_CompareArray1=
where(Device_SumBaseband_Amplitude >=
Device_SumBaseband_FrontShift);
//取和通道大于移位半电压的下标,前沿就是下标的子集
Front_CompareArray2=
where(Device_SumBaseband_Amplitude <=
Device_SumBaseband_FrontShift)+ 1;
//取和通道小于移位半电压的下标,然后下标集合加1
Frontedge_Array =setIntersect
(CompareArray1,Front_CompareArray2+1,true);
//上面两个特征的交集就是前沿集合的下标
5 系统运行及测试分析
5.1 系统运行平台
整个系统在某雷达站进行部署,通过采集真实数据进行测试验证。系统包括一个射频前端模块、一个数据服务器节点、两个译码节点、一个点迹节点、一个业务终端模块和一台万兆交换机。系统运行环境参数如表1所示。

表1 系统运行环境参数

表1(续)
5.2 系统运算处理能力测试
系统采用三层并行计算实现,针对节点级、线程级、数据级并行计算的不同数据处理特性,在处理不同的接收数据率情况下,分别对比了三层并行计算和单层并行计算的处理能力。测试结果如图6所示,横坐标表示接收数据的速率,纵坐标表示处理时间,也就是系统延时。
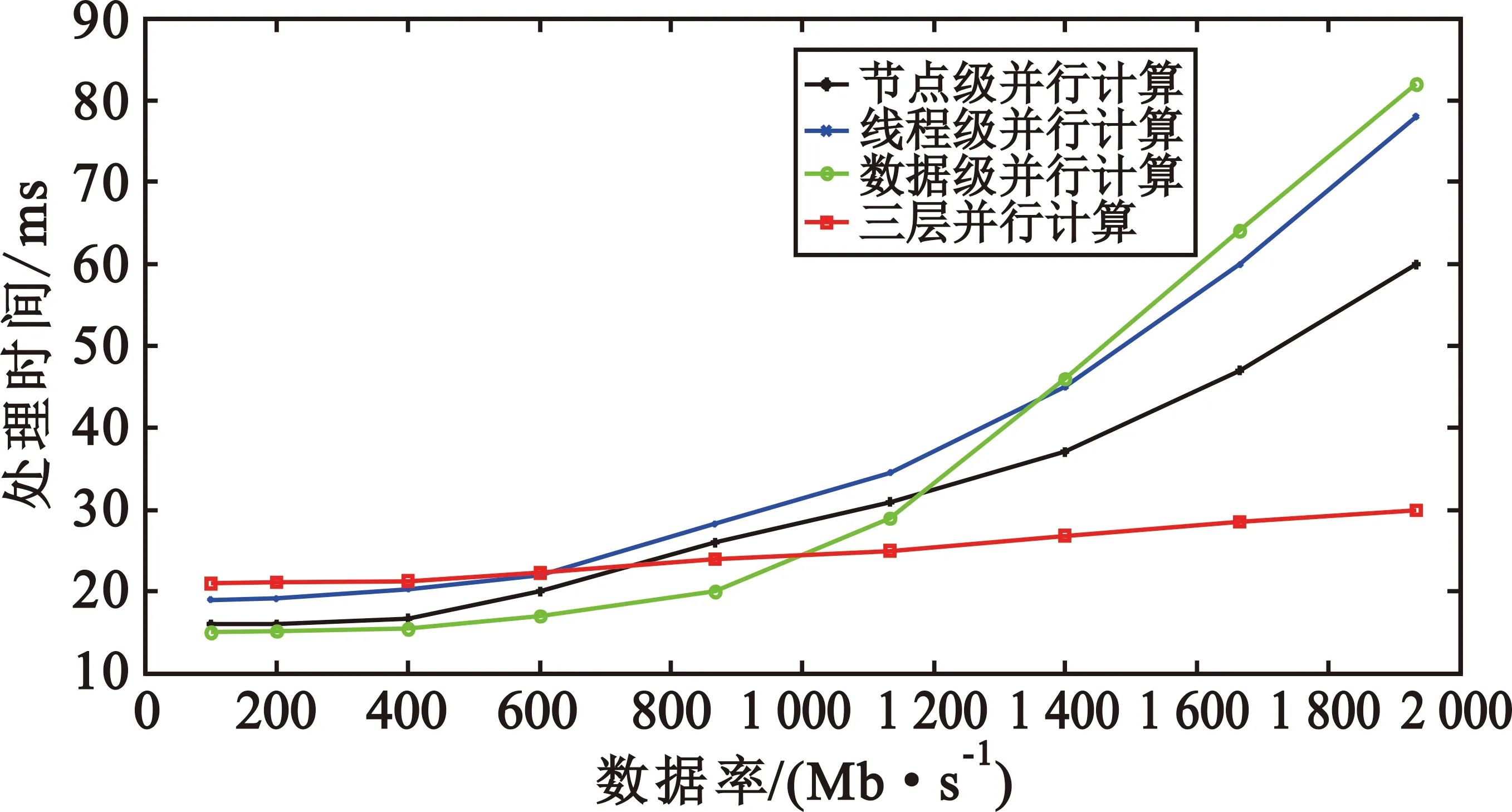
图6 三层并行计算数据处理特性
从图6中可以明显看出,单层并行计算随着数据率的增大处理时间急速增长,而三层并行计算的处理时间增长缓慢。这是由于随接收数据率的增大系统的硬件处理能力达到饱和,此时三层并行处理能力的优势就显而易见了。但在数据率低的时候,特别是数据率低于600 Mb/s时,采用单层并行计算的方式反而优于三层并行计算方式。这主要由于三层并行计算相对单层并行计算方式系统更加复杂,所需初始化硬件资源占用大量的时间,系统高速计算处理能力并没有发挥出来。从测试结果可得出,采用三层并行计算方式在处理高速的接收数据也就是大规模数据量时有明显的优势,特别是数据率在1 000 Mb/s以上时,系统处理时间稳定在30 ms以内,完全符合雷达系统对大规模高速数据处理实时性的要求。
5.3 系统对空测试
系统在某雷达站部署完成后,进行实时数据处理分析,能形成连续的目标点迹,且与雷达站成熟的雷达系统形成的目标点迹一致。系统运行过程中所形成的部分点迹目标如图7所示。

图7 对空目标实时显示
5.3.1 对空测试系统实时性分析
系统延时主要由前端采样系统延时、数据在网络中传输延时、数据译码和点迹显示延时四部分组成。由于系统部署在一个局域网中,网络传输延迟可以忽略不计。前端采样系统以3 ms一个雷达报文周期为时间片段定时采样传输,因此一个雷达报文延时为固定3 ms。数据服务器模块每10个雷达周期发送一次数据,因此后续的译码模块和点迹模块必须保证在30 ms能处理完30 ms的数据(10个雷达周期),那么系统就可以完成实时的处理。通过测试,使用单译码节点、单处理线程,系统在译码阶段需要61 ms左右,数据处理出现明显卡顿,系统有明显延迟现象;若增加一个译码节点,使用双线程进行处理,译码阶段数据处理时间将下降到25 ms左右,整个系统运行流畅。
系统采用三层并行计算,那么系统的性能将取决于任务级、线程级和数据级每一层的性能。由于GPU硬件性能是不可变的,那么系统的性能就完全取决于任务级节点个数和线程级线程个数。分别配置不同的线程数和节点数,使用预先采集的一分钟雷达真实数据进行回放测试。同样系统环境下重复测试10次,记录系统的延时时间并取平均值,如表2所示。

表2 不同模式下系统运行延迟
从表2中数据可以看出,采用单节点单处理线程,系统延迟非常明显,高达61 ms;采用双节点双线程,系统延迟明显下降到25 ms;不过继续加大节点数和线程数,系统延迟将无法突破20 ms。这主要因为系统三层并行设计增加了系统的复杂性,导致系统初始化硬件资源占用时间较长,系统运行延迟占用时间接近20 ms。因此,为了保证系统性能并充分降低硬件成本,采用2节点、至少2线程的处理方式进行系统部署。
5.3.2 对空测试系统实时数据运算量分析
系统总的数据率为采样频率、通道数、IQ路数、数据位数的乘积。其中采样频率为20 MHz,通道数为3,IQ路数为2,数据位数为16 b,计算可得总数据率为1 920 Mb/s。由于数据服务器模块每30 ms送出一包数据,数据量为1 920 Mb/s×30 ms,因此译码模块需要在30 ms内处理57.6 Mb的数据量。一个雷达周期为3 ms,雷达测距范围为时间乘以光速除以2,计算得到理论雷达测距范围为450 km,完全满足雷达系统对测距指标的要求(至少为370.4 km)[19]。
6 结 论
为解决软件化雷达系统的实时性和数据处理能力问题,本文设计了一种分层级并行计算的软件化雷达实时处理系统,实现了基于任务级的分布式并行计算、基于线程级的多核并行计算和基于数据级的GPU并行计算。系统可以根据数据运算量和实时性要求,对节点数和线程数进行灵活配置和部署,有效解决了软件化雷达系统中高实时和大数据量处理的瓶颈问题。在实际工程环境中进行部署测试,结果表明本系统具有良好的扩展性和广阔的工程应用前景。
猜你喜欢
深圳大学学报(理工版)(2022年5期)2022-09-27
现代电子技术(2022年8期)2022-04-13
沈阳工业大学学报(2021年6期)2021-11-29
山西电子技术(2021年3期)2021-06-28
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
网络安全技术与应用(2020年1期)2020-01-07
北京航空航天大学学报(2017年12期)2017-04-23
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年24期)2016-11-14
