
基于ADMM算法的网络连接数据变量选择①
2022-02-15 06:39方佳佳郑泽敏
计算机系统应用 2022年1期
方佳佳,李 阳,郑泽敏
(中国科学技术大学 管理学院统计与金融系,合肥 230026)
随着科学技术的进步,不同领域的数据都呈现出网络连接的趋势,许多科学领域都涉及某种形式的网络研究,例如人际关系研究、学术论文合著和引用、蛋白质相互作用模式等.20年前,关于网络的流行书籍及其研究开始出现[1],而像Facebook、MySpace和LinkedIn 这样的在线网络社区在近10年间也是蓬勃兴起,这更加增强了人们对网络数据的研究兴趣.网络连接数据由节点和边组成,社交网络是此类网络模型的一个典型代表.社交网络中,每个节点代表一个人,边代表人与人之间的沟通交流,此外,还有商业网络、基因网络等.
目前关于网络连接数据的研究主要分为两个方面.一方面是关于网络结构的研究.另一方面主要是将网络连接数据中的结构信息与统计学习中常用的经典模型结合起来研究.
在网络结构方面,最早被应用于社区检测.社区检测兴起于物理学和计算机科学领域,而后开始应用于统计领域.其中一类社区检测算法是通过在节点的所有可能分区上优化启发式全局准则来检测社区[2,3].基于概率模型的方法[4,5]是另一类社区检测算法.一些学者从观察到的邻接矩阵中检测社区或潜在结构[6–8],从其他节点之间的信息估计特定节点之间的边缘概率[9].社交网络是此类网络模型的代表,因此针对社交网络的研究也受到了大量的关注[10,11].
在与经典模型结合方面,一般是与常用的模型相结合.例如,时间序列模型[12],线性模型[13],变系数模型[14],随机效应模型[15],变化点检测问题[16],自回归模型[17,18]等.
线性回归模型是统计学习中的经典模型之一,应用十分广泛,关于网络数据的回归模型也开始引起学者的关注.例如,Asur 等[19]将网络数据应用于预测模型,通过研究网络结构来预测现实生活中某一现象的结果.Li 等[13]将网络连接数据应用于回归预测模型,Zhu 等[17]和Tang 等[18]将网络连接数据与自回归模型相结合,都表明网络连接数据在回归模型中的研究价值.随着科技的发展,数据的采集变得更加容易,高维数据也越来越受到研究学者的关注,但是高维数据中存在大量的冗余信息,如何选出有研究价值的数据?变量选择领域应运而生.故将网络连接数据应用到变量选择领域是一个值得研究的课题.
对于线性回归模型,超高的维度使得传统的普通最小二乘法不再适用.正则化是稀疏建模和变量选择的有效方法,通过在目标函数上添加惩罚函数来降低模型的复杂度.根据惩罚函数的不同,正则化方法一般可以分为凸正则化和非凸正则化.
凸正则化方法主要包括岭回归、LASSO、弹性网以及Dantzig Selector 等.虽然凸正则化的研究已经很成熟,但由于惩罚函数的凸性,使得凸正则化估计量都是有偏的.Zhang 提出了一个非凸正则化方法—SCAD(smoothly clipped absolute deviation)[20],并证明了其Oracle 性质.非凸惩罚函数回归的渐进无偏估计,能进一步降低模型的预测总误差.此后,非凸惩罚受到了广泛的关注,例如MCP (minimax concave penalty)[21]、限制Capped-L1[22]、Hard 阈值惩罚[23]等.
关于网络连接数据的变量选择问题近年来也有学者做过相关研究[24,25].例如Li 等[24]和Kim 等[25]考虑样本系数之间的网络凝聚效应,即网络中连接节点表现出相似的行为,对系数同时施加了L1惩罚和凝聚效应惩罚 βTLβ,从而能够解决网络连接数据的变量选择问题,但他们针对的是同质性网络连接数据,即假设每个样本的个体效应值 α 相同,并没有考虑到异质性,异质性是指不同样本的个体效应 α 不同.在现实生活中,因为网络凝聚效应的存在而使得网络中的样本存在群组效应,联系密切的样本组成一个群组,他们之间的行为会相互影响而慢慢趋同.针对线性回归模型,这种群组效应的一个直观体现就是群组内样本的个体效应α相同,不同群组间个体效应 α 不同.若忽略群组间个体效应的差异性,将所有样本的个体效应视为相同,在进行变量选择和预测估计时都会产生较大偏差,影响模型精度.故考虑异质性,能够提高模型精度.因此,针对异质性网络连接数据的研究具有重要的价值和实际意义.Li 等[13]考虑到个体效应之间的异质性,并惩罚相连样本个体效应的差异性,提高了回归模型中估计和预测的精度,但他主要关注的是预测问题,没有涉及到变量选择.
本文的目标是对因网络凝聚效应而产生个体效应的组异质性的网络连接数据进行变量选择,我们对组内样本间个体效应的差异性Lα和变量系数 β 进行联合惩罚,从而保证组内样本的个体效应具有相同的估计值.本文提出的方法不仅能够处理含有组异质性的网络连接数据的变量选择问题,而且能够改善变量选择、估计和预测的结果.在本文中,我们主要使用L1、MCP和SCAD 罚函数,并且运用ADMM 算法进行求解,同时证明了算法的收敛性.
1 网络连接数据的变量选择方法
1.1 模型设定
本文中所有的向量都是列向量.考虑一般的线性回归模型,Y=(y1,y2,···,yn)T是n维响应变量,X=(x1,x2,···,xn)T是n×p设计矩阵.假设X是固定的且其列已经标准化.样本X的结构网络为G=(V,E),其中V={1,2,···,n}为样本节点集合,E⊂V×V为边的集合.我们用邻接矩阵A=(Auv)n×n∈Rn×n表示该网络以及样本节点和节点之间的连接关系,若 (u,v)∈E,则Auv=1,否则为0.Auu=0,Auv=Avu.网络G的拉普拉斯矩阵L=D-A,D=diag(d1,d2,···,dn)为度矩阵,D的对角线元素为每个节点的度du=建立如下线性回归模型:

其中,α=(α1,α2,···,αn)T是节点个体效应向量.假设相连样本的个体效应相等,不相连样本的个体效应不等,即样本之间存在组异质性.β=(β1,β2,···,βp)T是模型的回归系数向量.ε=(ε1,ε2,···,εn)T是n维误差向量,E(ε)=0,var(ε)=σ2In.
Li 等[13]提出了网络连接数据的预测方法(the regression with network cohesion,RNC),其主要思想是最小化如下损失函数:
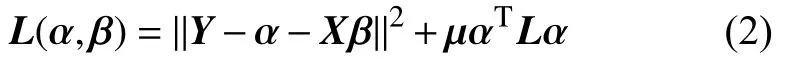
其中,μ>0是调整参数.RNC 主要是惩罚网络中相连节点个体效应的差异性,该惩罚可以推导出一个等价的、更直观的形式 αTLα=
1.2 组异质性网络连接数据的变量选择方法(SNC)
RNC中假设各样本的个体效应不相等,惩罚项μαTLα用来惩罚相连样本个体效应的差异性,从而能够处理异质性网络连接数据的回归预测问题.但是由于连接网络中的个体常常存在群组效应,同一个群组中行为特征存在统一准则而基本相同.因此,在本文中我们假设样本之间存在组异质性,即组内样本(相连样本)的个体效应相等,组间样本(不相连样本)的个体效应不相等.通过对Lα 施加惩罚,惩罚组内样本个体效应的差异性并压缩至0,Lα中的元素是(αu-αv)(u,v)∈E或其等价形式.为了产生 β的一个稀疏估计,我们将同时惩罚 β和Lα,这就是我们提出的方法—网络连接数据的变量选择(variable selection with network cohesion,SNC).
令 θ=(βT,αT)T,H=则Hθ=SNC的目标函数为:
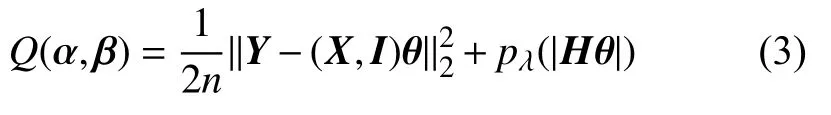
在本文中,对Hθ的惩罚主要使用L1和非凸惩罚,非凸惩罚包括MCP和SCAD 罚函数.MCP 罚函数为罚函数为pS(t,λ)
将SNC 方法的估计结果与没有对节点个体效应的差异进行惩罚的情况下进行对比,能够提高估计和预测的精度.
2 算法
直接最小化目标函数(3)很难求解出估计量的值,因为惩罚函数对于每个 αi是不可分的.因此,我们通过引入一组新的参数 γ=Hθ 来重新参数化准则.最小化式(3)等价于最小化如下约束优化问题:
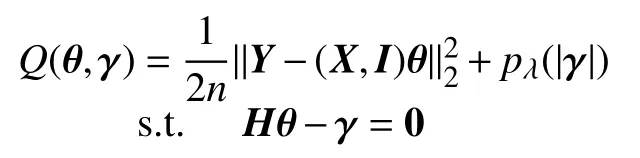
基于文献[26]中的思路,利用增广拉格朗日方法,通过最小化如下损失函数得到参数的估计:
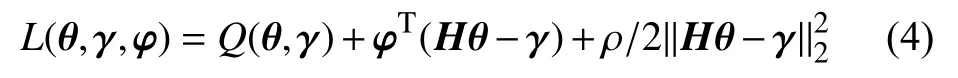
其中,对偶变量 φ是拉格朗日乘数,ρ >0是惩罚因子.我们通过交替方向乘子法(alternating direction multiplier method,ADMM)来迭代求解 (θ,γ,φ)的估计.对于给定的(θ,γ,φ),L(θ,γ,φ) 关于 γ的最小值是唯一的,并且在L1惩罚或非凸惩罚下有一个近似的形式.当给定 (θ,γ,φ),上述最小化问题等价于:
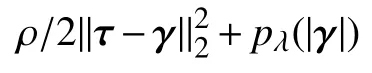
其中,τ=Hθ+ρ-1φ,故在L1或非凸惩罚下估计量的近似的形式为:
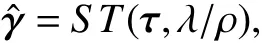
其中,S T(t,λ)=sign(t)(|t|-λ)+是soft 阈值准则,(x)+=x,x>0,否则 (x)+=0.
对于MCP 罚函数 (a>1/ρ),
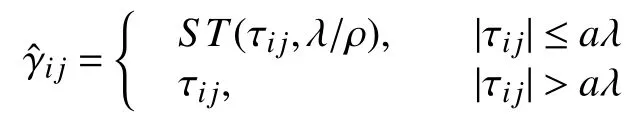
对于SCAD 罚函数 (a>1/ρ+1),
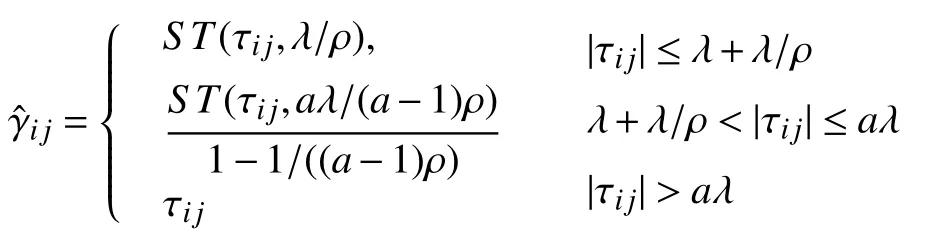
算法步骤如算法1.

算法1.ADMM 算法输入:预测变量,响应变量,邻接矩阵,惩罚因子,停止准则 ;X Y A ρ η^θ,^γ,^φ输出:;目标:迭代求解获得和.θ(0),γ(0)=Hθ(0),φ(0)=0,m=0,η=0.03.初始化θ,γ φ While,do m≥0 θ(m+1)=[n-1(X,I)T(X,I)+ρHTH]-1*[n-1(X,I)TY+ρHTγ(m)-HTφ(m)];γ(m+1)=S T(τ(m+1),λ/ρ);φ(m+1)=φ(m)+ρ(Hθ(m+1)-γ(m+1)).r(m+1)=Hθ(m+1)-γ(m+1)||r(m+1)||<η If,then(^θ,^γ,^φ)=(θ(m+1),γ(m+1),φ(m+1));Break;Else m=m+1;End End
对ADMM 算法过程中的原始变量进行追踪,r(m+1)=Hθ(m+1)-γ(m+1).停止准则为||r(m+1)||<η,其中η>0为一个非常小的常数.
下面考虑ADMM 算法的收敛性.
命题1.对于MCP和SCAD 函数,ADMM 算法的原始残差r(m)=Hθ(m)-γ(m)和对偶残差s(m+1)=ρHT(r(m+1)-r(m)) 满足
命题1 表明该算法实现了原可行性和对偶可行性,证明材料见附录.因此,它收敛于一个局部最优点.当采用非凸惩罚函数,如MCP和SCAD 罚函数时,此最优点是目标函数的局部最优解.综上,算法收敛性和稳定性得到证明.因为θ(m)=((β(m))T,(α(m))T)T是不稀疏的,但我们已证明Hθ(m)=((β(m))T,(Lα(m))T)T是收敛于γ(m),故我们令 γ(m)的前p项作为β的估计值,即可得到β的稀疏解.
3 数值模拟
在数值模拟中,主要比较本文提出的SNC 方法和没有对个体节点效应的差异性进行惩罚的LASSO、MCP、SCAD 方法在变量选择和预测方面的效果.网络凝聚效应下的变量选择方法就是考虑了样本之间的连接关系网络的方法,即我们的SNC 方法.无网络凝聚效应下的变量选择方法,就是不考虑样本之间的连接网络的惩罚方法.在这里,我们首先定义几个效果评估指标:
(1)预测损失(prediction error,PE):E(XTβ0+α0-
(2)Lq损失:
(4)假阳性数(false positives,FP):真实为反例却被预测为正例的个数;
(5)假阴性数(false negatives,FN):真实为正例却被预测为反例的个数;
(6)真阳性数(true positives,TP):真实为正例预测也为正例的个数;
(7)真阴性数(true negatives,TN):真实为反例预测也为反例的个数;
(8)F1-score:2TP/(2TP+FP+FN).
3.1 模拟1
对于式(1)中的线性回归模型,我们从该模型中随机生成100 个数据集.训练样本的大小考虑两种情况(n,p)=(100,200)和(n,p)=(100,500),设计矩阵X中的每一行从正态分布N(0,Σ),Σ=(0.5|i-j|)1≤i,j≤p中随机抽样.真实回归系数为随机误差 ε的标准差.惩罚因子 ρ=1,λ 用交叉验证来选取,停止条件 η=0.03.
为了生成含有组异质性样本间的邻接矩阵A,我们用ER 随机图模型生成一个包含n=100 个节点的样本网络,样本网络由4 个不相连的部分G1,G2,G3,G4组成,每个部分包含25 个节点.每个单独的部分都是一个ER 随机图,节点与节点之间以pb的概率生成边,即Aij=1,否则为0,令pb=0.1.4 个部分中相连样本的个体节点效应 αi的值分别为1,-1,0.5,-0.5,独立样本的个体节点效应为0.3.
表1展示了两种方法在预测评估指标上的结果对比.与没有利用相连节点的网络凝聚效应对个体效应进行惩罚的LASSO、MCP和SCAD 结果相比,SNCLASSO、SNC-MCP和SNC-SCAD 都明显改善了估计和预测误差.这表明将网络凝聚效应加入变量选择模型中,可以改善模型变量选择、估计和预测的精度.
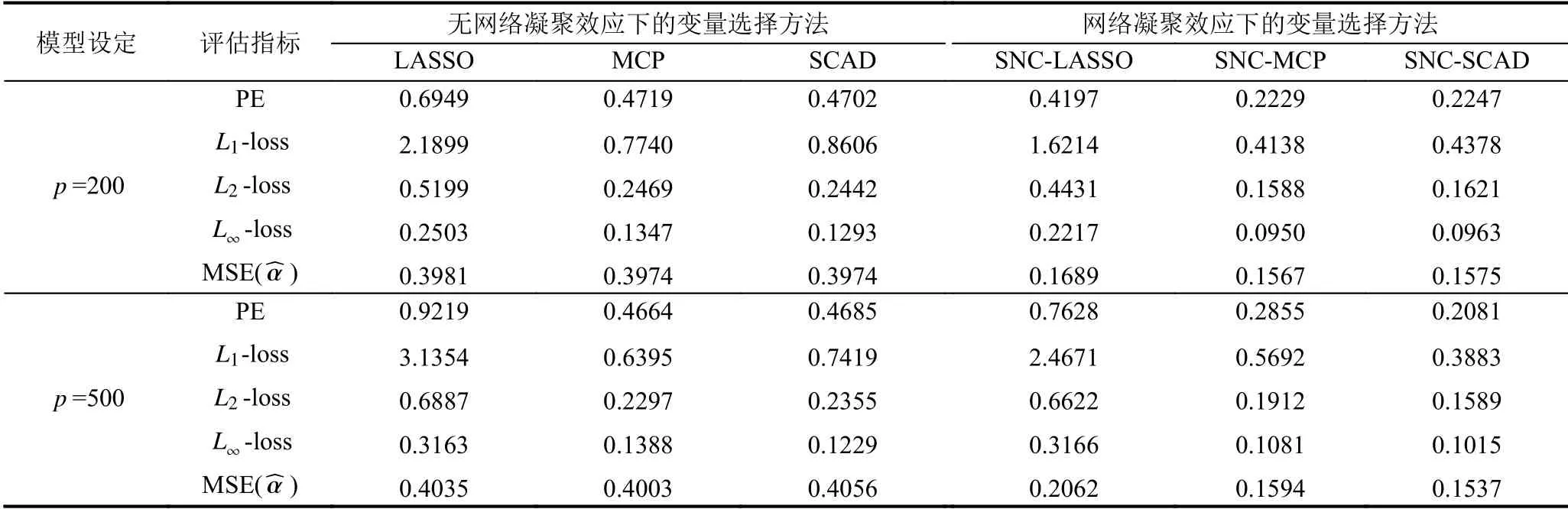
表1 不同方法下预测评估指标结果
表2展示了两种方法在100 次模拟实验下变量选择评估指标结果.我们可以看出各项指标下,SNC 方法的变量选择效果都明显优于没有利用网络凝聚效应进行惩罚的方法.另外,SNC-MCP和SNC-SCAD 都要优于SNC-LASSO.尤其对于假阳性数FP,100 次模拟中,SNC-LASSO的FP 平均为15.41 (p=200)和17.21 (p=500),而SNC-MCP 分别为0.05 (p=200)和0.3 (p=500),SNC-SCAD 分别为1.06 (p=200)和0.2 (p=500),MCP和SCAD 变量选择的准确性比LASSO 显著提高,主要是由于LASSO的有偏性.
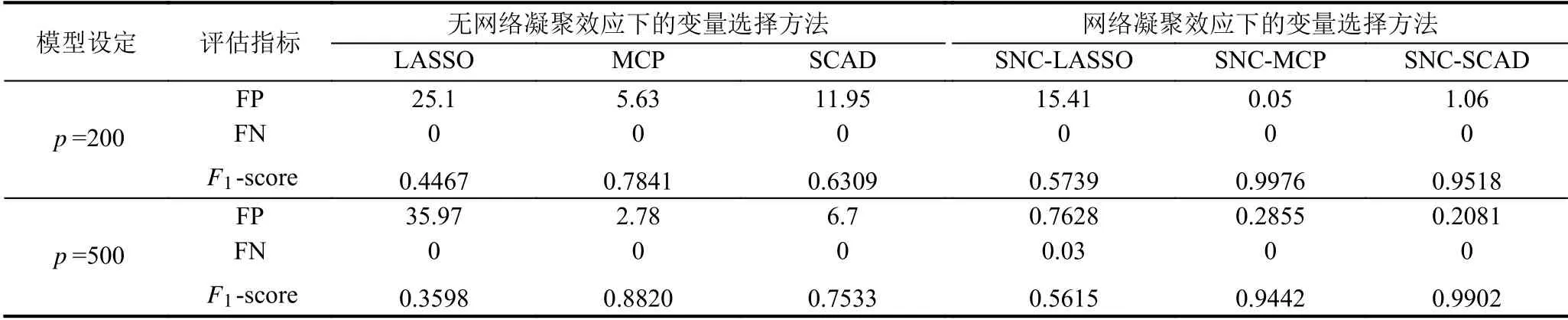
表2 不同方法下变量选择评估指标结果
3.2 模拟2
模拟1中的结果表明网络凝聚效应惩罚能够改善变量选择、估计和预测效果,网络凝聚效应主要与邻接矩阵中个体之间产生联系的概率pb有关,接下来我们将研究pb对SNC 方法的变量选择、估计和预测效果的影响.模型2中的设定与模型1 类似,不同的是我们取pb=seq(0,0.02,0.2),R 语言函数seq(a,b,c)用于生成一组从a到b,间隔为c的序列.
图1和图2分别展示了pb对预测和变量选择效果的影响.从图1可以看出,随着pb的增大,即网络的凝聚效应增强,SNC 方法能够明显降低预测损失,并在pb=0.08 附近趋于稳定.图2表示pb对F1分数的影响,F1分数是查准率和查全率的调和平均数,当pb=0 即样本之间没有连接关系时,F1分数值很低.随着pb的增大,F1分数值逐渐增大,同样地,在pb=0.08 附近达到最大值,此时SNC 方法变量选择的效果较好.
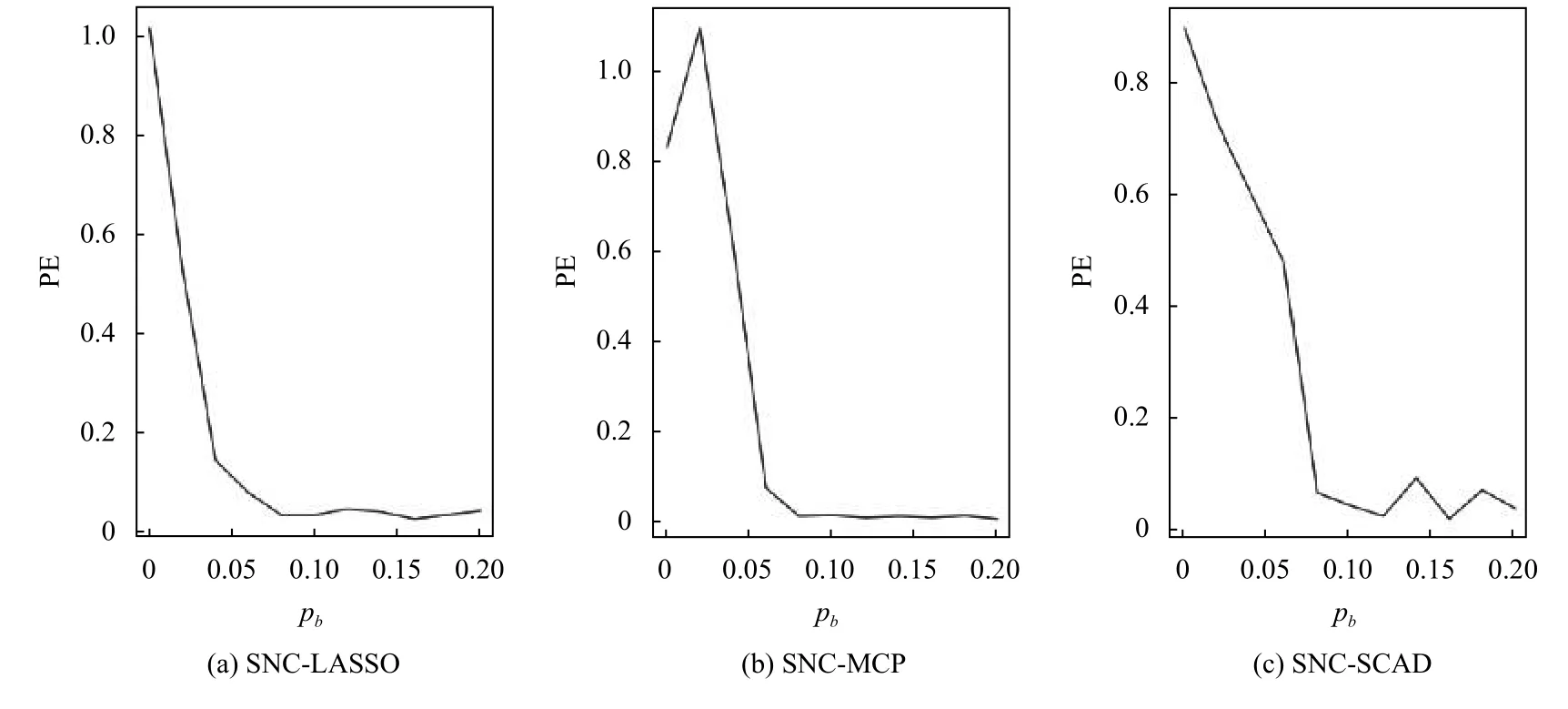
图1 pb 对预测损失的影响
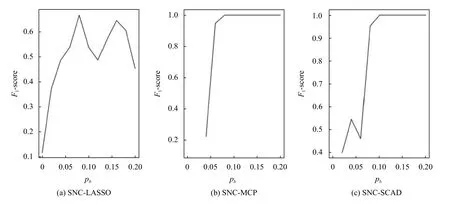
图2 pb 对F1-score的影响
4 实际数据分析
我们研究的真实数据案例来自于Teenagers Friends and Lifestyle Study[27].这项研究主要是青少年友谊网对他们自身某些行为的影响.该实际数据与本文中的模型设定保持一致,因青少年时期学生喜爱团体活动,故凝聚效应使得网络之间存在组异质性.
Teenagers Friends and Lifestyle Study 旨在确定在青少年早期到中期不良习性的变化过程.实验记录了3 个时间点 (T1,T2,T3)的数据.样本来自于160 名学生,通过每个学生及学生之间的朋友(最多6 个)关系来建立友谊网络.研究给出了3 个时期的友谊网络,网络中“1”表示“best friend”,“2”表示“just a friend”,“0”表示“no friend”,“10”表示缺失值,我们根据学生之间的友谊网络来获取邻接矩阵A.
本文使用的数据集X包含160 个样本,40 个特征变量包括青少年的年龄、性别、生活方式、休闲活动以及家庭成员吸烟等情况,考虑特征之间的交互作用,最终特征变量为250 个.我们的目标是利用友谊网络找出影响青少年不良习性的关键因素,并预测青少年自身不良行为的活动频率.我们分别选取alcohol、tobacco和cannabis 作为响应变量Y,对于tobacco,元素1 表示从未抽过烟,2 表示偶尔吸烟,3 表示经常吸烟,故我们将其取对数作为响应变量Y的值.
时间点T1的友谊网络如图3所示.我们只展示了学生之间的“best friendship”(包括“just a friend”和“best friend”).根据友谊网络建立邻接矩阵A时,当学生i和学生j为“best friend”,则Aij=Aji=1,否则Aij=1.
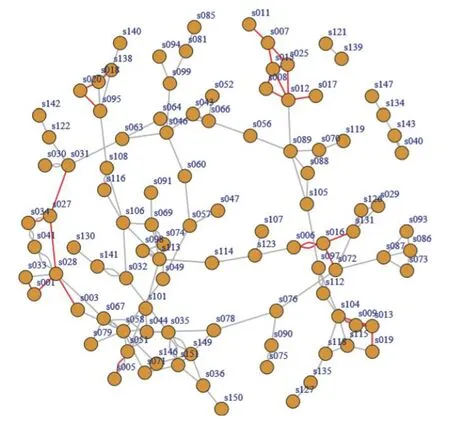
图3 青少年友谊连接网络
分别选取alcohol、tobacco和cannabis 作为响应变量来研究影响青少年酗酒、吸烟和吸毒的因素.将样本随机分成两份:训练集和测试集,重复实验100 次.由于不知道真实情况下的参数设定,无法像模拟实验中那样对比假阴性数、假阳性数等指标.因此,主要从预测损失和变量选择两个方面来验证SNC 方法的有效性.
表3展示了SNC 方法SNC-LASSO、SNC-MCP、SNC-SCAD 与无网络凝聚效应下的变量选择方法LASSO、MCP和SCAD 对青少年不良习性(酗酒、抽烟以及吸食大麻)的预测损失,从结果中可以看出SNC方法预测的相对更准确一点.青少年时期大家都是团体活动,生活习惯很容易相互影响而慢慢趋同,而网络凝聚效应正是考虑了这一点,团体内个体的表现行为更具相似性,惩罚团体内个体效应的差异性,提高了个体效应的预测精度,从而降低了整个模型的预测误差.
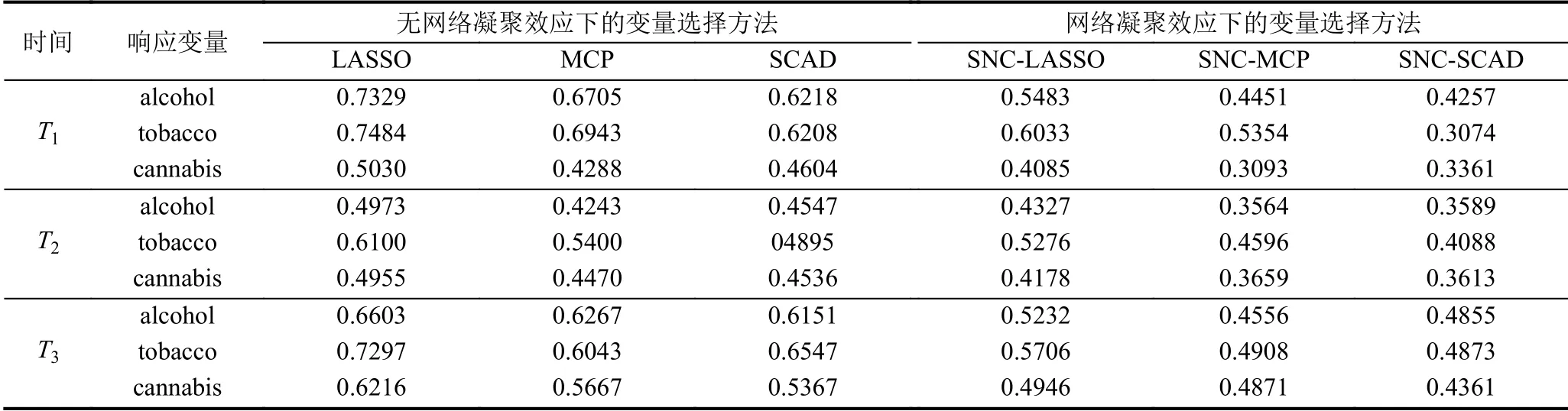
表3 青少年不良习性的预测损失
为了使挑选出来的变量更具可解释性,下面我们不考虑特征之间的交互作用,用SNC 方法和无网络凝聚效应下的变量选择方法来挑选变量,并重复实验100 次,计算100 次实验下挑选出来的变量的比例.
表4中我们看到,LASSO、MCP和SCAD 挑选出更多的冗余变量.显然,两种方法下,特征变量parent smoking,sibling smoking,“I hang round in the streets”,“I play computer games”和“I go to dance clubs or raves”是最显著的.青少年时期他们的世界观、人生观和价值观还在形成阶段,易受他人或团体的影响,在街上闲逛、经常打电脑游戏、参加俱乐部以及兄弟姐妹抽烟等行为都容易使青少年沾染上不良习性.通过研究分析,我们知道了青少年时期朋友以及家人行为的重要性,家人、朋友以及整个社会需要给青少年营造一个良好健康的成长环境,给他们树立积极向上的榜样.
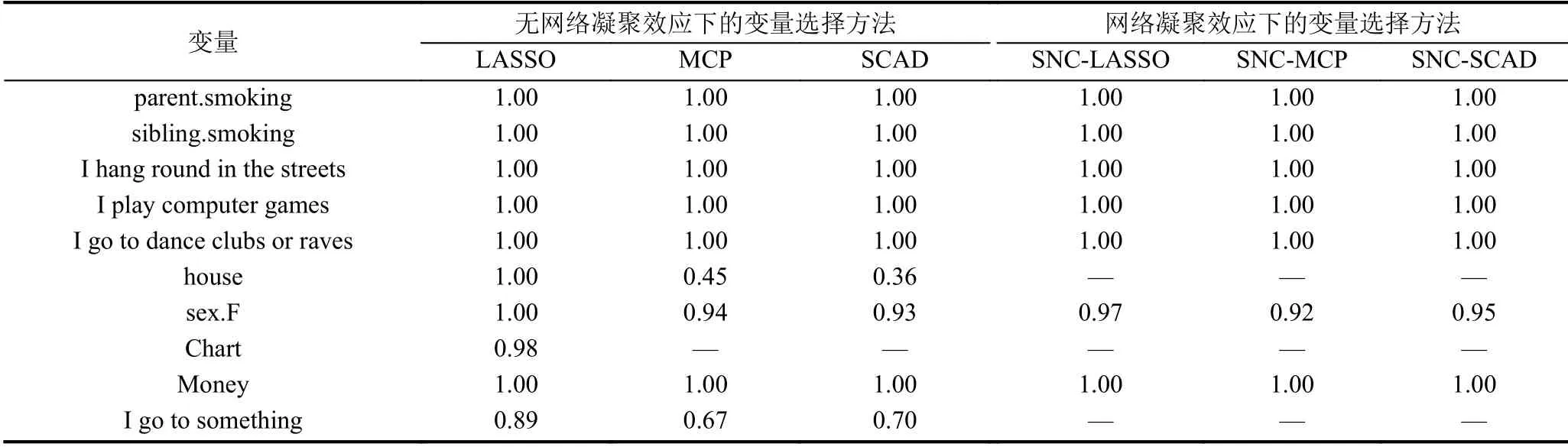
表4 不同方法下挑选出的变量及其比例
针对各种方法挑选出来变量之后的模型进行回归,我们得到回归后各变量系数的显著性检验以及调整可决系数R2和标准误差如表5所示.
由表5可知,SNC 方法选取了sex.F、I hang out in the streets、I play computer games、money、parent.smoking和sibling.smoking 6 个变量,根据值可以看出这些变量都通过了显著性检验.而LASSO、MCP和SCAD 方法选出了少许的冗余变量.另外,从表中的调整可决系数和标准误差来看,SNC 方法的效果也是优于没有网络凝聚效应下的变量选择方法.
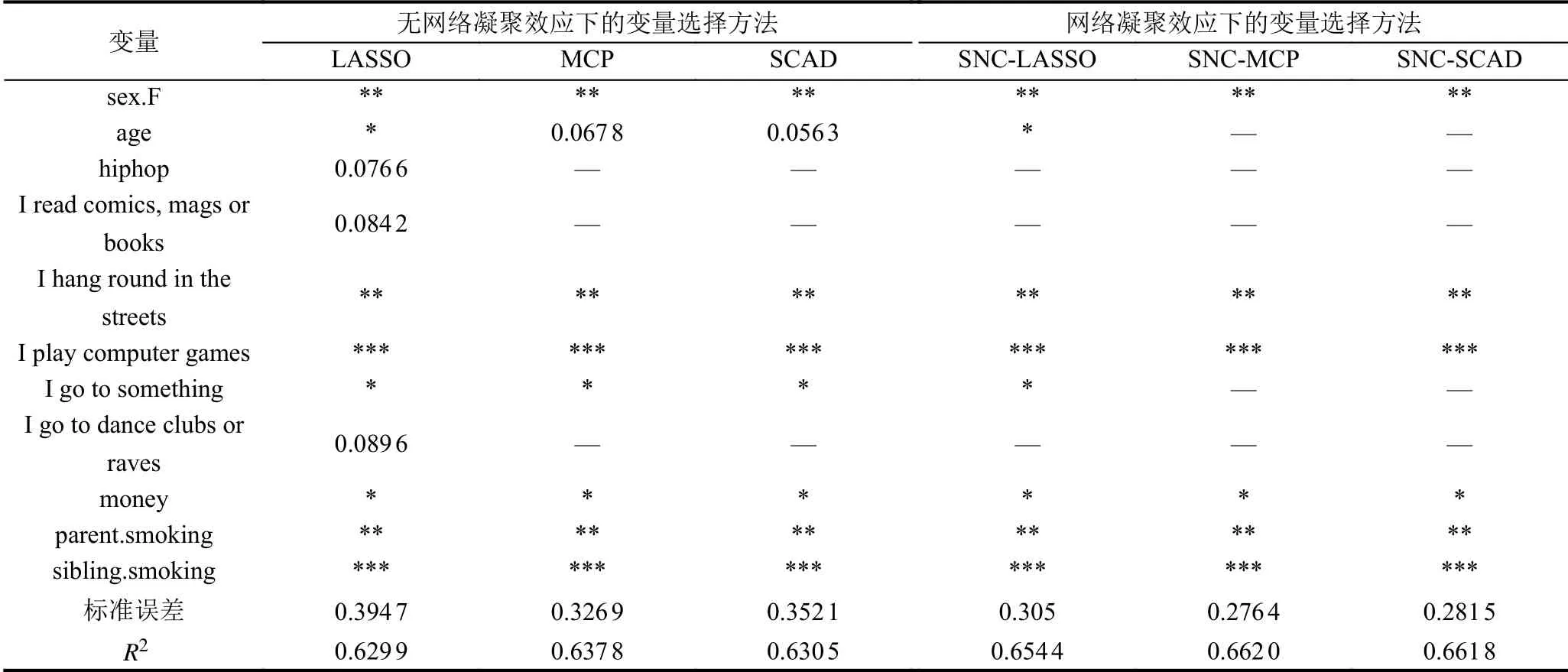
表5 不同方法下挑选出变量的显著性检验
5 总结
本文主要对线性回归模型中因网络凝聚效应而产生个体效应的组异质性的网络连接数据进行变量选择,使用非凸惩罚MCP和SCAD 罚函数同时惩罚变量系数 β和组内样本的个体效应的差异性Lα,使得能够对含有组异质性的网络连接数据筛选出有用变量.
针对本文提出的方法,我们运用ADMM 算法进行求解,并证明了算法的收敛性.针对SNC 方法,本文进行了相关模拟,从变量选择和预测两个方面来衡量该方法的效果.从实验结果来看,无论是预测损失还是变量选择的准确性都有明显改善.实例分析中,我们将SNC 方法应用于青少年友谊网络和生活方式的研究,分析预测青少年吸烟等不良习性的活动频率以及挑选出影响青少年吸烟等不良习性的特征变量.
本文提出的方法,为含有组异质性网络连接数据的变量选择问题提供了一种解决思路.我们将变量选择方法进一步拓展了应用领域,对于基因网络、交通网络、公司网络等网络连接数据,SNC 方法都能适用.
附录A.命题1的证明
命题1 描述了算法的收敛性,下面我们开始证明.由 γ(m+1)的定义可知,对任意 γ:
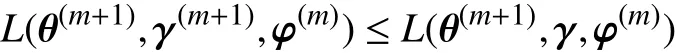
令:
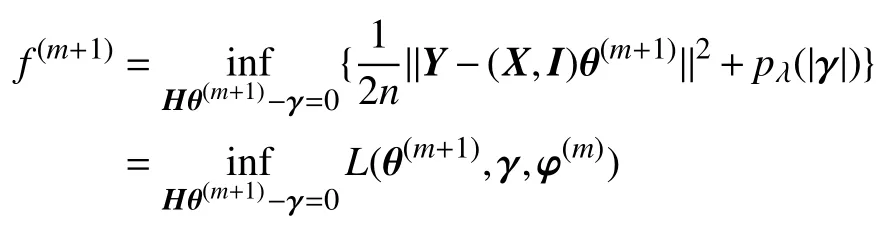
故,L(θ(m+1),γ(m+1),φ(m))≤f(m+1).
令t为整数,φ(m+t-1)=有:
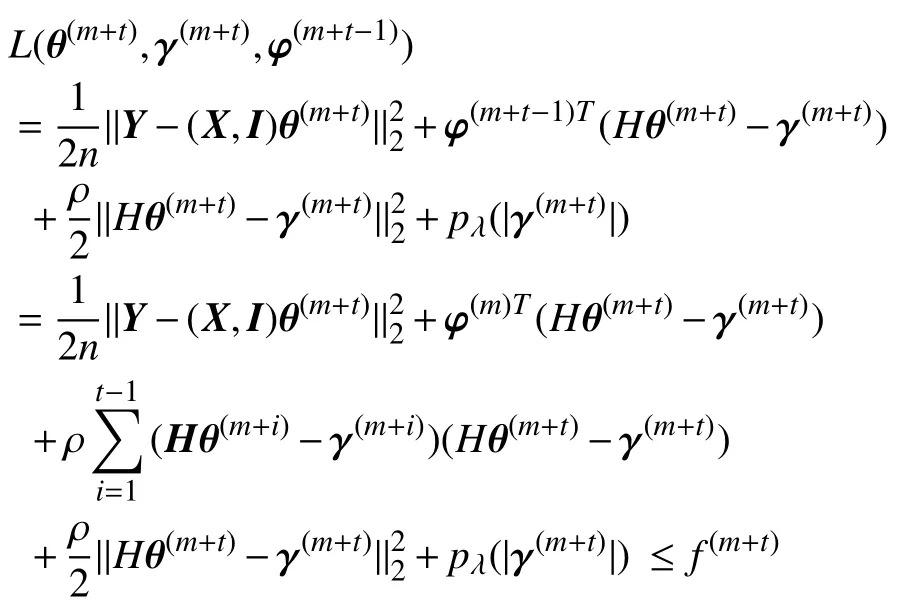
由于目标函数L(θ,γ,φ) 关于(θ,γ) 导的,并且是φ函数,基于文献[28]的定理4.1,(θ(m),γ(m)) 有个极值点,记为(θ*,γ*) 故有:
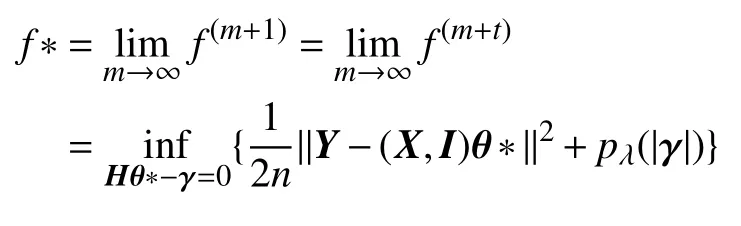
并且对于任意t≥0,有:
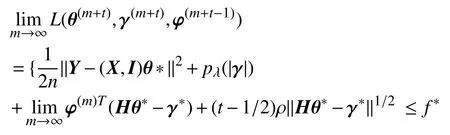
因为θ(m+1)使得L(θ,γ(m),φ(m)) 最小化,故有δL(θ(m+1),γ(m),φ(m))/δθ=0.并且:
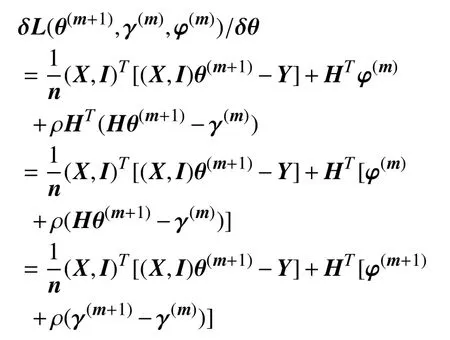
因此:
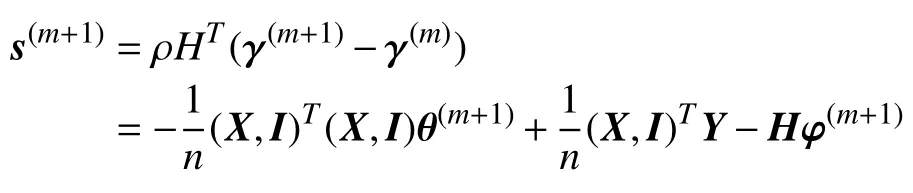
又因为||Hθ*-γ*||2=0,故
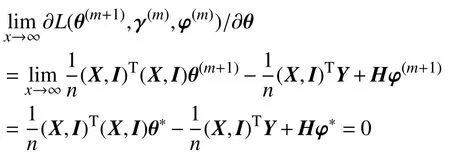
猜你喜欢
语文世界(初中版)(2020年6期)2020-10-27
阅读(快乐英语高年级)(2019年11期)2019-09-10
电脑报(2019年5期)2019-09-10
学苑创造·A版(2015年6期)2015-07-01
新课程·上旬(2014年8期)2014-11-04
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
语文世界(小学版)(2009年10期)2009-12-14
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
小学教学参考(数学)(2006年7期)2006-12-31
