
基于二级U-Net 的小样本下秀丽隐杆线虫端泡分割方法*
2022-02-16 08:32曹思刘俊
计算机与数字工程 2022年1期
曹 思 刘 俊
(1.武汉科技大学计算机科学与技术学院 武汉 430070)
(2.智能信息处理与实时工业系统湖北省重点实验室 武汉 430070)
1 引言
秀丽隐杆线虫作为最为常用的模式生物之一,被广泛用于神经、药物及人类寿命等研究。秀丽隐杆线虫是一种虫体透明,以细菌为食,平均寿命只有两周,在实验室可以培养,非常适合用于寿命研究。对于秀丽隐杆线虫的寿命研究的方法可分为两大类,一是基于基因的研究,如Ellis等[1],首次发现了基因调控的细胞程序性死亡,并且指出人以及哺乳动物细胞凋亡基因与秀丽隐杆线虫的细胞程序性死亡是相似的;Adolfo 等[2]使用sod-3 启动子作为寿命预测器,通过追踪基因的表达来预测寿命。二是基于现象学的研究,如Catherine 等[3]发现随着年龄增长,端泡纹理熵的增加;Cheng等[4]发现长寿与短寿的秀丽隐杆线虫的咽部抽吸跨度不同。
秀丽隐杆线虫的端泡是研究其寿命与老化的重要部位之一[3~4]。从秀丽隐杆线虫的显微图像中自动分割出端泡部位成为了一个重要的任务。本研究尝试了如今在很多分割任务中表现优异的卷积神经网络,如使用U-Net等在数据样本上进行实验。但是由于可以用于训练与测试的只有29 张图像,样本量太少,透明的虫体带来许多相似像素的干扰,并且不同成长阶段的样本间的端泡部位在图像上的表现差异过大,即使在数据扩充的情况下仍然无法取得好的效果。
小样本数据训练后的模型表现差的主要原因有以下几点:1)数据不平衡[5]:本来就小的数据集内部还有较大的差异,使得模型难以学习到正确的正负样本,训练得到的模型本身不具有代表性;2)训练的数据不具备预测能力:新出现的需要预测的数据与训练集本身的差异过大,导致模型学习到的效果只能代表所有可能出现的样本中的极少数;3)数据扩充[6]对效果的提升有上限:即使使用现在流行的数据扩充方法,比如基础变换(旋转、缩放、翻折等),基础形变(扭曲,伸缩,错位等)也只能再增加一部分的预测能力。无法得到更多的突破,过多的扩充甚至造成过拟合;4)迁移学习[7]无法解决特定应用场景问题:比如在COCO 数据集下训练的分割模型是针对80 个类别的现实事物。可以将其迁移到相关类别的分割与分类,但是迁移到其他领域,如微生物的细胞分割等是没有效果的,或者是负面效果的。也就是当特定应用场景下没有相关预训练模型的时候,迁移的效果不佳。本研究为了寻找秀丽隐杆线虫小样本数据用于神经网络的训练方法,进行了各种对比实验,采用合理的管道数据增强方式并提出二级分割网络,以及加入最大包含损失来减小内部干扰,使得秀丽隐杆线虫端泡的自动分割任务可以在小样本下达到良好的精度,足够用于开展后续的研究工作。
2 材料与数据扩充
2.1 秀丽隐杆线虫显微图像的获取与概述
采集显微图像是微生物研究中最容易获取图像的方式之一。本研究采用生命科学学院培养的秀丽隐杆线虫的头部显微图像作为训练样本与测试样本。采集的图像为不同时期(第一天,第三天,第五天,第七天,第九天)的样本,得到咽部不同时期的成长状态,泛化本研究的应用范围。受样本采集时间、成像环境、仪器设备等影响,采集到的显微图像会出现光照不均匀与噪声较多。本研究感兴趣的部位是秀丽隐杆线虫的端泡,在显微图像下,不同生长时期下端泡部位的边缘信息变化较大,且内部像素纹理信息与虫体的其他部分有着较大的相似度,同时还受到观察的培养物质,包括养料、自身产生的废物与玻片污染对图像质量的影响,如图1,加大了分割的难度。本研究采用了29 幅1048×786 像素的图像,其中20 幅用于训练,9 幅用于测试。端泡区域的标准值标注,采用了生命科学学院专家的手工标注,如图1。
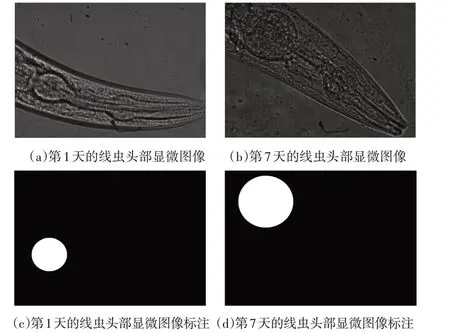
图1 秀丽隐杆线虫的显微图像与手工标注
2.2 秀丽隐杆线虫显微图像的扩充与预处理
图像变换的扩充方法在很早就被提出用于增强小样本数据集,具体的扩充方法应当基于本样本的特征进行选择,否则可能造成负面影响,扩充的数量也对结果有着不同程度的影响。本研究针对数据样本数量较少,只有20张用于训练,将训练集进行多尺度的变换,用于扩充数据集,提高模型的泛化能力与健壮性。本研究首先进行了最常用的随机缩放与随机旋转。这样的处理可以在数量层面上实现数据量的增长,模拟出不同角度的采样效果与目标区域大小变化,这种方式扩充可以在一定程度上提高训练效果,但是在扩充量继续增大时并不能得到更多的效果提升。根据秀丽隐杆线虫的身体柔软与姿态多变的生物特征增加了随机小范围扭曲,模拟了虫体的运动变化。变换的程度参数也需要根据样本来定,在基本能够预测样本变化趋势的情况下去采用合理的变换。本研究除了使用简单的单类变换,还使用了管道变换扩充方法来提升扩充后数据的复杂性与得到更鲁棒的训练模型。
每一次变换可以用式(1)来表示,其中X 为原始输入的样本图像,Y 为变换后的样本图像,trans()为某一种变换方式,N 为变换的数量,Para 为变换的参数,动态调整参数可以得到同一类型下不同程度的变换等。
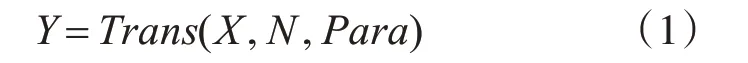
初始的变换就可以表示为以下公式,其中Rotate_random()为随机旋转变换,Zoom_random()为随机缩放变换,Distortiom_random()为随机扭曲变换:

这样就得到了设定好数量的扩充图,而管道变换扩充将各个变换作为管道的一节,节与节之间的自由组合成一种管道,经过管道的原图就会按照管道的顺序得到新的图像,结构如图2 所示,可以表示为以下公式:
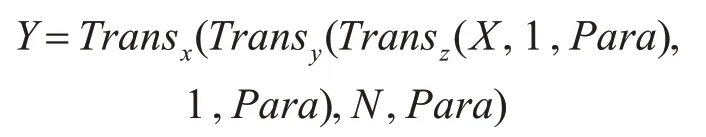

图2 变换管道结构图
用不同的管道组合方式就可以得到更多样的扩充效果,在结合初始的扩充方法就得到更好的扩充数据集。
3 方法
3.1 U-Net网络
U-Net 是 由Olaf 等[8]在2015 年ISBI 竞 赛 中 提出的一种优秀的图像分割卷积神经网络,并且以远超第二名的成绩取得了2015 年ISBI 竞赛的冠军。U-Net 是基于全卷积神经网络[9]的改进,广泛应用于神经元分割[8]、CT 图像分割[10]等医学图像的分割。在其他领域如桥梁检测[11]、遥感图像[12]分割等也有着良好的表现。U-Net网络呈现左右对称的U型结构,如图3所示。
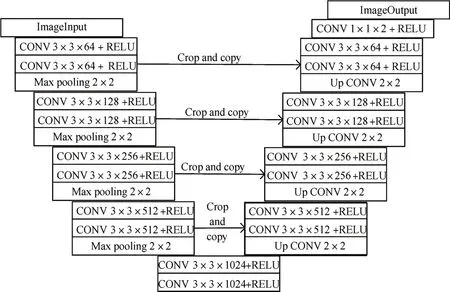
图3 Olaf提出的U-Net网络结构
左边被称为收缩路径,采用卷积来提取特征,每一次包含两个3×3 的卷积操作,采用最大池化来减少计算参数,每一次包含一个2×2 的最大池化操作,池化过后的图像大小会变为原图的1/2。右边被称为扩张路径,使用复制叠加来保留底层上下本信息与特征到高层网络,采用反卷积来恢复图像大小,最后,1×1 的卷积操作用来分类像素,最终实现端到端的模型。
3.2 改进的两级网络结构
是在对数据增强之后使用U-Net 网络进行训练,网络虽然可以收敛,但是在实际的测试中还是出现了过拟合现象,基本无法预测新的目标。分析发现,按照现有的图像标记方式,如图1 所示,目标区域与背景区域在像素层面上有许多相似的地方,给网络识别正负样例带来了干扰,而对小样本的扩充,相当于一定程度上放大这种干扰,使得网络过拟合,难以预测新的目标。所以本研究将图像中整个咽部即端泡以及前端纹理相似的部分作为一个整体进行标记,如图4。

图4 秀丽隐杆线虫的整个咽部标注方法示例
经过测试发现在这样的分割方案下,第一步只需要基本确定咽部的位置与基本的轮廓,但是需要保持轮廓尽可能包含整个目标区域。第二步再从整个咽部分割出端泡部分,这样做就相对之前从整个图像中分割出端泡要简单一些,没有了复杂的背景与相似像素干扰。这样就可以在降低任务的复杂程度,得到想要的效果,从而消除小样本带来的特征提取困难与过拟合。系统的实现流程如图5。
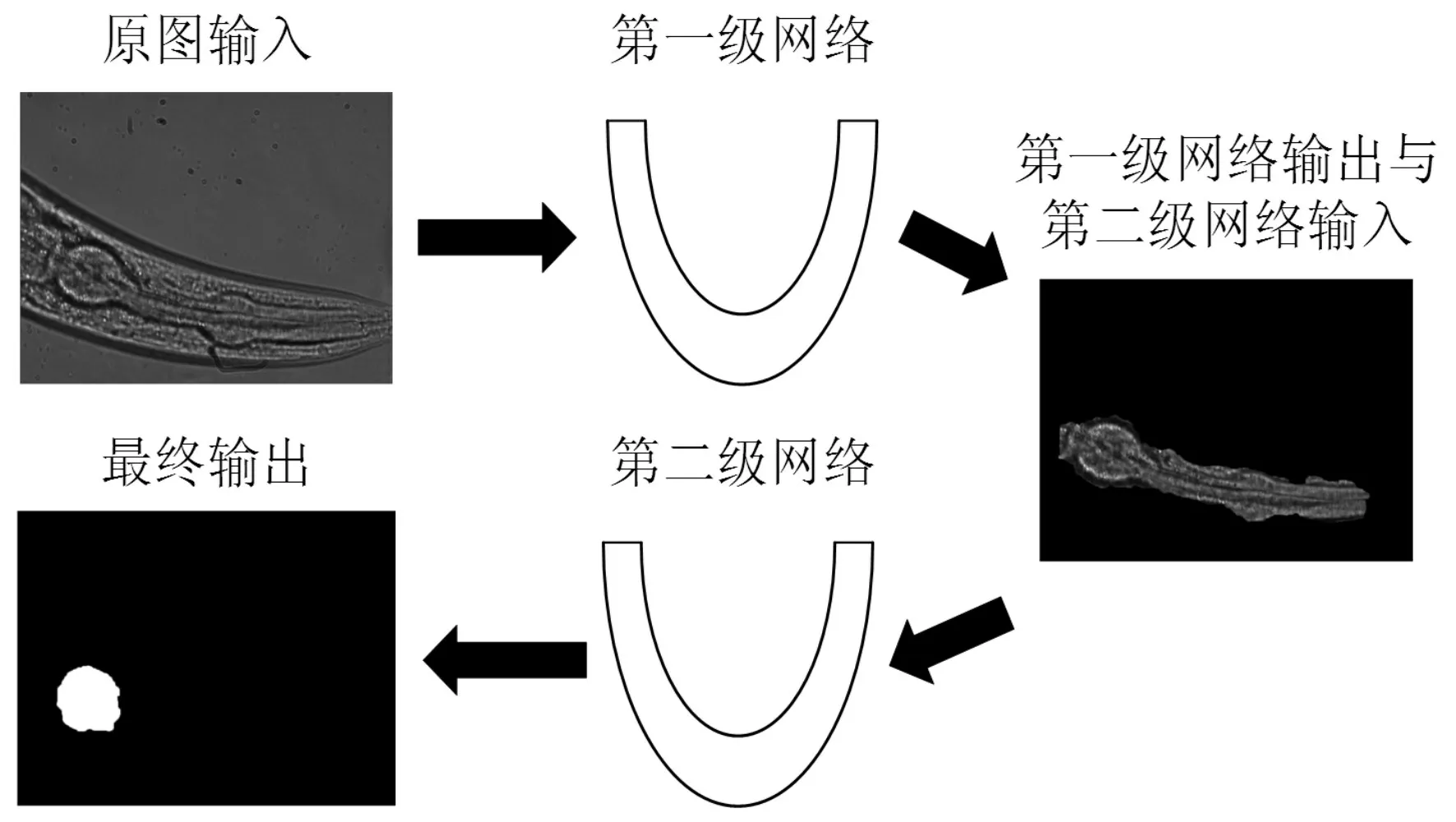
图5 系统流程结构图
第一级网络以秀丽隐杆线虫的显微图像与整个咽部ground truth作为输入,经过U-Net网络的收缩路径的卷积与池化提取咽部的像素特征,再经过扩张路径还原咽部的像素并分类像素,得到一个整个咽部的分割模型。使用第一级的模型,我们可以得到一个整个咽部的掩模,将输出的掩模作用于原图再与端泡的ground truth 输入到第二级网络再经过一次U-Net 得到我们需要的端泡的分割模型。在本研究中改变了原版U-net 卷积结构,分别采用两个3*3*32、两个3*3*64、两个3*3*128、两个3*3*256、两个3*3*512 卷积结构,具体实现与网络整体结构示意图如图6。整个网络结构相当于将复杂任务分解为两个简单任务的组合。第一级解决了端泡的定位与像素干扰的问题,这不需要太高的分割精度,但是需要较高的召回率(Recall)才能保证不会因为第一级网络的干扰,造成最终分割端泡的效果不好。
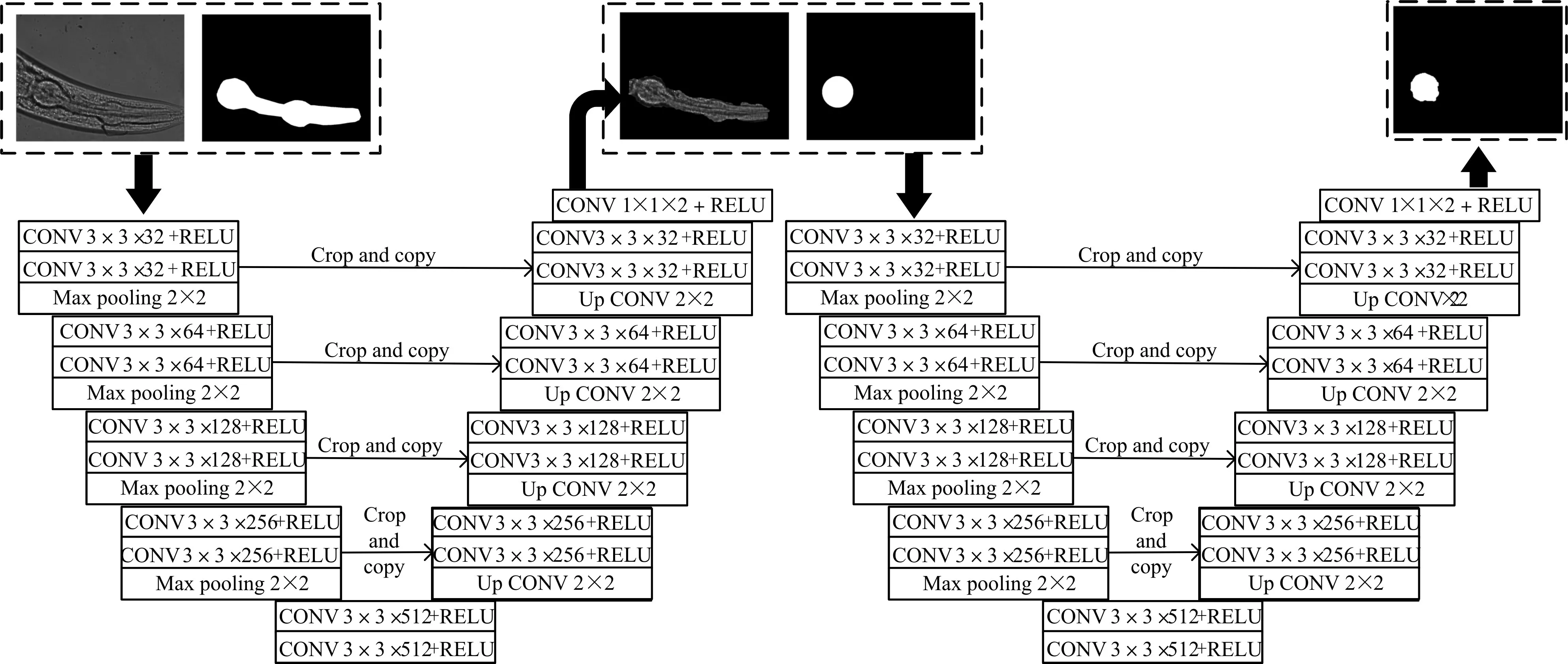
图6 二级U-Net网络结构示意图
3.3 最大包含损失
本研究提出的是一种二级的网络结构,分配两个任务给两个级别的网络,但是实验中发现第一级的某些图的分割结果不能完全包含需要分割的端泡部位。这样就给第二级网络带来干扰,造成二次误差,影响最终的分割效果。所以第一级的任务还需要做到在能达到尽可能大的精度下最大限度包含端泡目标区域。因此需要在原来的网络上加入本研究提出的最大包含损失来提升第一级网络输出的召回率。
本研究在两种常用于图像分割的损失函数下进行了实验,包括交叉熵损失(BCE_Loss)与骰子系数损失(Dice_Loss)。本研究的基础损失选用骰子系数损失。骰子系数可以定义为式(2),骰子系数损失定义为式(3)。
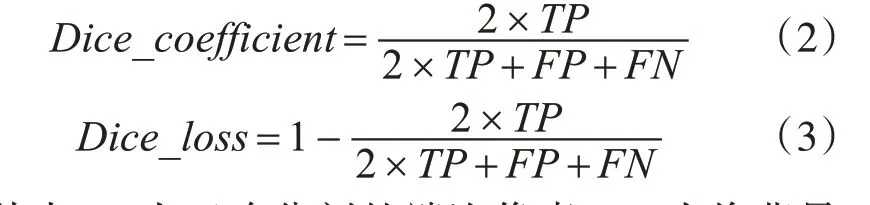
其中TP 为正确分割的端泡像素,FP 为将背景分割为端泡的像素,FN 为了未被分割出的端泡像素,TN为正确分割的背景像素[13],如图7。
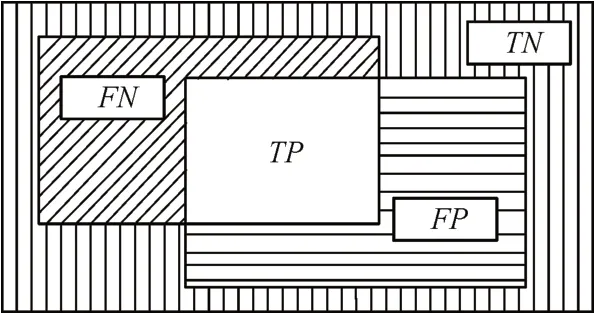
图7 分割结果标识
本研究第一级网络的目的是为了提高召回率,就是要抑制欠分割的部分,即图7 中的FN 部分,本研究将欠分割率[14]应用到损失函数中。可以将欠分割率表示为式(4)。
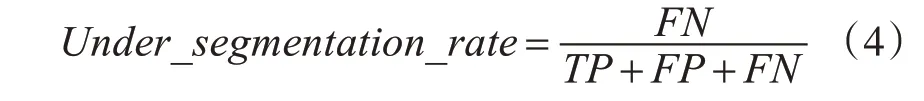
于是整体损失函数可以表示为
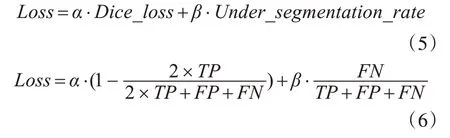
其中α与β分别作为损失函数两部分的权重。在实际实验中通过不断加大β值来减少欠分割所占的比重。实验发现,在β>10α时开始产生效果。
4 实验与评价
4.1 实验环境
1)硬件环境:
CPU:Intel(R)Xeon(R)CPU E5-2676 v3 @2.40GHz
内存:32GB
GPU:NVIDIA GeForce GTX 1080ti*8
2)操作系统:Ubuntu 16.04
3)软件环境:Pytorch 0.40
4.2 实验评价
本研究是在Pytorch 深度学习框架下进行的网络搭建与开发,在一台Linux 服务器使用八块NVIDIA GeForce 1080ti 做GPU 运算。根据本研究提出的二级U-Net分割网络,与最大包含损失在将训练集分别扩充到520 张、2020 张与5020 张进行了实验。在第一级网络用来分析数据增强与最大包含损失的效果,两级网络的整合用来分析最终端泡分割的效果。为了在像素级别评价分割性能,本研究使用四个评价指标[11]:分割精度(Precision),召回率(Recall),骰子系数(Dice Coefficient)与 杰卡德系数(Jaccard Index)。除骰子系数见式(2)外,其余三个评价指标定义如下:

4.3 数据扩充的实验
在第一级网络中使用Baseline的U-Net网络在数据集大小分别为20、520、2020、5020 作为训练集的情况下进行训练,得到的结果如表1。实验发现,扩充数据确实可以提高分割效果,但在扩充数据过大时提升的效果开始减小,如图8 和图9。从增加的训练时间与资源占用来看,过于巨大的数据扩充量并不是小样本提升训练效果的最佳选择,具体的扩充量选择需要由具体应用决定。

表1 不同数据集扩充量下整个咽部分割实验结果对比
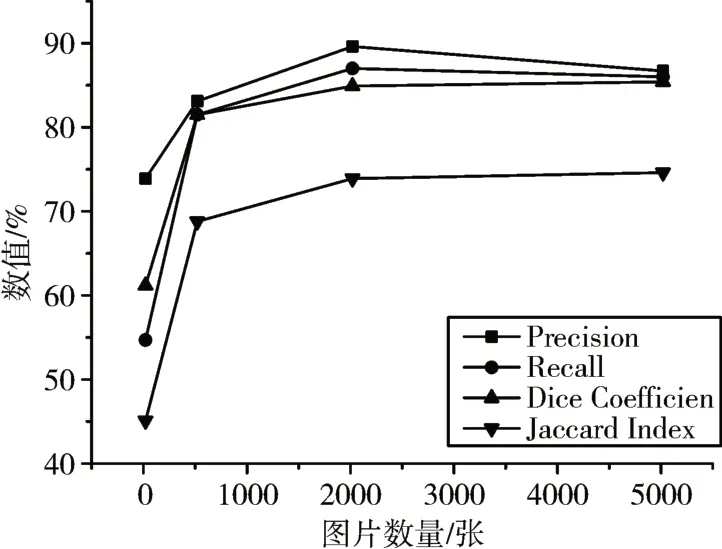
图8 不同数据扩充量的结果对比图

图9 不同数据扩充量的训练时间
4.4 最大包含损失实验
在第一级网络中,分别使用Dice_loss与最大包含损失作为损失函数,在数据扩充量为2020 的数据集下进行训练实验。两种损失的变化曲线如图10 所示,在迭代到大约175 次时,训练模型的损失达到基本稳定的数值,测试时采用训练过程中损失数值最低的模型。

图10 训练损失变化图
在加入了最大包含损失之后,虽然准确性与Dice 系数没有明显的提升或者略有下降,但是Recall明显增加并达到较高的值。第一级网络只作为粗分割,这样的结果是符合后续步骤的条件的。采用最大包含损失后,分割的边界往外部扩张,包含端泡的部位比使用原始的损失函数时更加完整,如图11。

图11 使用不同损失函数的分割结果对比
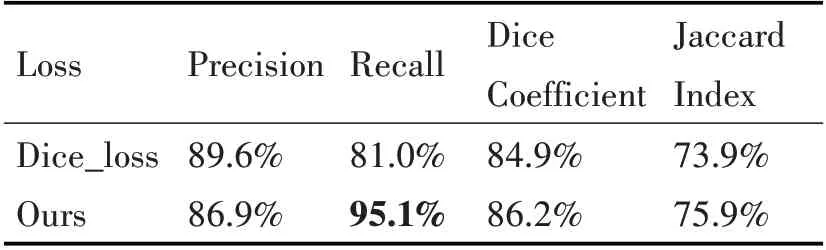
表2 Dice损失与最大包含损失的在整个咽部分割的实验结果
4.5 端泡最终分割实验
本研究加入最大包含损失后,分别在Baseline U-Net 与两级网络的结构中进行训练,并且加入流行的分割网络SegNet[15]作为对照,得到的结果见表3。整体的实验效果对比图见图12。可以看到在小样本下,单纯的单级网络几乎无法分割出目标区域,在改进的二级网络后,得到的分割效果有极大的提升,可以得到满足后续工作开展的效果。

表3 单级网络与加入最大包含损失的二级网络的端泡分割实验结果对比
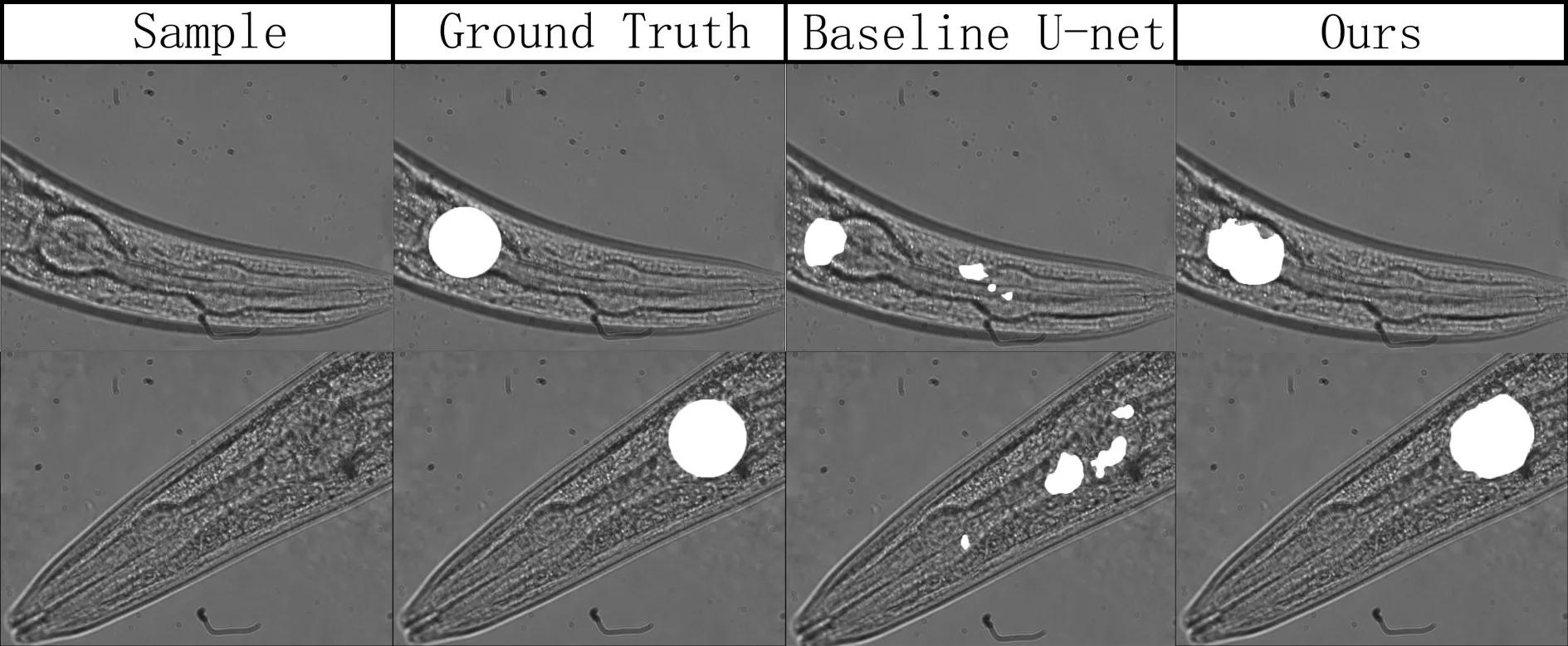
图12 本文提出的方法与Baseline U-net的端泡分割实验结果对照
5 结语
本研究将小样本的秀丽隐杆线虫数据集应用到卷积神经网络,探索了数据扩充方案对小样本的分割效果的影响,在传统网络对小样本不友好的条件下,提出了二级分割网络,配合最大包含损失来降低第一级分割效果不好的部分对最终分割效果的影响,达到较好的效果,为小样本数据的分割任务提出了新的方案。
猜你喜欢
今日农业(2022年15期)2022-09-20
今日农业(2022年14期)2022-09-15
中国生物防治学报(2022年1期)2022-04-22
大众健康(2021年7期)2021-07-28
小天使·二年级语数英综合(2019年10期)2019-11-08
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
读者·校园版(2015年19期)2015-05-14
山西果树(2014年6期)2015-03-12
计算技术与自动化(2014年1期)2014-12-12
