
基于改进式k-prototypes聚类的坏数据辨识与修正
2022-02-17 03:07王孝慈董树锋刘育权王莉李俊格
电测与仪表 2022年2期
王孝慈,董树锋,刘育权,王莉,李俊格
(1. 浙江大学 电气工程学院,杭州 310027; 2. 广州供电局有限公司,广州 510620)
0 引 言
随着数据挖掘技术在工业用电领域的逐渐应用,准确的负荷数据变得至关重要。对于工厂来说,准确的负荷数据可以支持其负荷预测、需求响应等多种高级应用,从而提升用能的经济性。另一方面,对于电力企业,准确的用户用电数据可以降低其参与售电市场的风险,并避免用户窃电带来的经济损失[1-2]。然而,由于设备停运、仪表故障、通信线路异常等原因,导致工厂负荷数据中存在大量坏数据,影响工厂和电力企业的正确决策[3]。因此,在对负荷数据挖掘之前,进行坏数据的辨识与修正非常重要。
目前,坏数据辨识与修正方法的研究主要针对系统负荷或母线负荷,主要方法有状态估计法、横向纵向比较法、聚类法。传统的基于加权残差或标准残差的状态估计法,容易出现残差污染和残差淹没现象,造成坏数据的漏检和误检[4-5]。横向纵向对比法根据历史负荷数据值确定正常数据范围,对相邻时刻的负荷数据值非常依赖,因此在一定程度上无法处理连续丢失或突变的坏数据[6-7]。聚类法通过提取用户典型用电模式,确定每种用电模式下负荷数据的合理范围完成负荷辨识,取得了不错的效果[8-10]。文献[8]利用快速爬山法改善模糊C均值(fuzzy C-means, FCM)聚类算法,改善了聚类数难以选择,初始聚类中心随机选择等缺点,并根据每个用电模式中历史负荷的最大最小值确定正常数据可行域完成坏数据辨识。文献[9]利用极限学习机提取数据特征,并利用空间核密度聚类分析特征识别不良数据。但是,上述聚类的特征向量全部为负荷用电数据,在聚类向量中本身包含坏数据的情况下,聚类结果无法准确反映待测日的用电模式特征,会对数据辨识与修正造成影响。文献[10]为了解决上述问题,提出了一种利用灰色关联分析引入非负荷数据信息,改善FCM聚类的坏数据辨识与修正模型,实验结果表明在聚类中引入非负荷数据特征值,可以提高模型的准确性和实用性。
文献[11]指出在进行负荷模式提取时,不存在一种聚类方法普遍优于其他聚类方法。并且对于工业负荷模式提取,直接移植现有的聚类方法效果不佳,需要更有针对性的研究。文献[12]采用统计模糊矩阵分类法对工业负荷进行分类,并通过非参数回归分析方法提取中心负荷向量,进而构造异常数据域,完成负荷辨识。但该方法在落地时,需要海量数据,现有大部分工厂无法满足其对数据存储的要求。
针对上述不足,提出了一种基于改进式k-prototypes聚类的坏数据辨识与修正方法。主要贡献在于:
(1)构建聚类特征向量时,考虑工厂用电特点,引入非负荷数据,削弱负荷数据中坏数据对聚类结果的影响;
(2)对标准k-prototypes算法进行改进,增加了多组初值并行择优,改善了其容易陷入局部最优的缺点,并对聚类数进行自适应处理,解决了主观选择聚类数量的问题;
(3)结合聚类结果,提出了负荷可行域的计算方法,并基于质心曲线置换对坏数据进行修正。
算例分析表明,所提改进式k-prototypes聚类算法较FCM聚类算法在工厂用电模式提取的效果更好,应用到坏数据辨识与修复中,识别的召回率和修复的准确率都有所提高;较简单置信区间坏数据识别、线性插值坏数据修复,效果提升显著。
1 混合特征聚类
1.1 混合聚类特征选择
利用负荷聚类算法进行坏数据辨识与修正的本质是提取用户用电的行为模式,将不符合其行为模式的数据找到,并进行修正。然而用于聚类的工厂负荷曲线本身就包含坏数据,如果在聚类时,仅考虑负荷数据,会带来两个问题:
(1)聚类时,结果受负荷坏数据的影响大,无法对用户用电的行为模式进行精确提取,从而影响负荷辨识与修正结果;
(2)修正时,对于某些用电数据严重缺失的时段,无法通过其他信息辅助对其进行填补。
基于上述原因,需要在特征向量中引入工厂的其他用电特征,修正工厂负荷时序值的聚类结果。工厂用电与其生产计划、生产模式强相关。对于有规律性生产模式的大多数工厂,其生产活动一般按周开展,并受节假日影响。因此,需在特征向量中引入“工作日属性”与“节假日属性”。另外,部分工厂除生产用电外,空调用电占比最大,如轮胎工厂的空调用电可达其总用电量的20%~30%,空调用电量与气温强相。故在考虑温度敏感度大的季度、空调负荷占比高的工厂时,需要增加“气温”特征维度。聚类特征选取结果如表1所示。

表1 聚类特征选取Tab.1 Clustering feature selection
1.2 k-prototypes算法
对于混合类型数据向量,同时包括数值型与非数值型数据。传统的聚类算法会将非数值型数据数值化,在计算聚类损失函数时仍然使用欧式距离。这样不但使非数值型数据脱离了本身的物理含义,还在聚类中引入了干扰因素。针对上述情况,选择k-prototypes算法,在计算聚类损失函数时对数值型、非数值型数据分别进行考虑。
对含有n个向量的集合X={x1,x2,…,xn},其第j个向量由一组特征值组成,可表示为:
(1)
式中xj,m为xj的第m个特征值;上标r表示数值型特征;上标c表示非数值型特征;mr为数值型特征的总数;mc为非数值型特征的总数。
通过k-prototypes算法将所有向量分为k类,则向量集合X可表示为:
(2)
式中Xi(i= 1, 2, …,k)为向量聚类后的第i类向量的集合。
向量聚类中,数值属性的相似距离为欧式距离,非数值型属性的相似距离为分类属性距离[13],则xj到其类心的距离可表示为:
(3)
式中xj所属类Xi的中心向量为:
(4)
式中γ为非数值型变量的权重,可在数值数据分布距离标准差的1/3~2/3之间进行选择[14]。
在聚类过程中,定义各个向量到所属类中心的总距离为聚类损失函数,聚类的目标为使聚类损失函数最小,可表示为:
(5)
式中ni集合Xi中向量的数量。
1.3 改进式k-prototypes聚类过程
为了克服标准k-prototypes容易陷入局部最优,聚类数量难以选择等缺点,对k-prototypes算法进行了如下改进:
(1)聚类过程中,随机选取多组聚类中心初值,并行计算,选取代价函数值最小的作为聚类结果,解决陷入局部最优的问题;
(2)提取聚类效果关键指标,设定阈值,对聚类数量进行自适应处理,克服类别数选择的主观性;
(3)将向量数量较少的类拆散,向量合并到距离最小的其他类,避免算法将坏数据单独分类,无法进行识别。
改进后的k-prototypes聚类主要过程如图1所示。
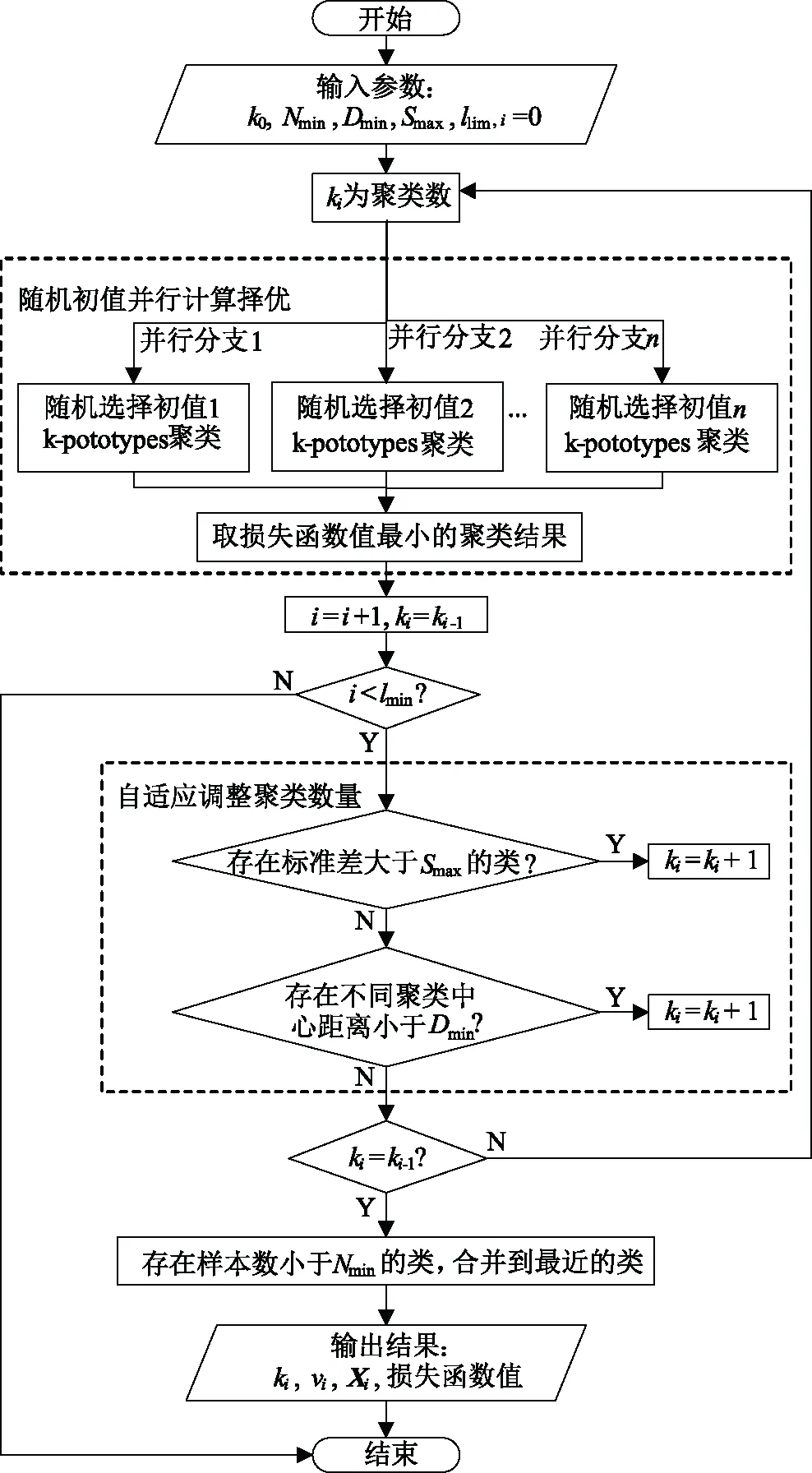
图1 改进式k-prototypes聚类流程图Fig.1 Flow chart of improved k-prototypes clustering algorithm
对于其输入参数进行如下说明:
k0为类数的初始值,由于算法对类数有自适应调整的过程,所以k0的选择不会影响聚类的最终结果。但k0越靠近最终的聚类类数,算法的迭代步骤越少,运算速度越快;
Smax为每一类向量距离分布的最大标准差,若某类的距离分布标准差超过Smax,说明该类内部相似度较低,应进行拆分。Smax的选取可以根据聚类数据的标准差选取其5%~20%,其选值越小,类内越紧凑;
Dmin为不同聚类中心的最小距离,若两类距离小于Dmin,则需进行合并。Dmin的选取可以根据聚类数据的平均距离选取其10%~20%,其选值越大,类间分隔越明显;
Nmin为每一类最少的向量数目,若少于此数,则不能作为一个独立的类。Nmin的选取可以根据聚类数据集的长度选择其5% ~ 10%的数量,如果Nmin= 1则不对每类最少向量数目进行约束。Nmin的限制可以避免将包含大量坏数据的向量单独分类,使其无法被辨识与修正;
llim为算法最大迭代次数。
2 坏数据辨识及修正
2.1 坏数据辨识过程
根据聚类结果,提取每类集合中每个向量的负荷数据。对于采样点数量为s的负荷数据(若采样间隔为15 min,则s=96),向量xj的提取结果可表示为:
(6)
聚类中心向量vi的提取结果为:
(7)
数据提取后,对应分类关系不变,即若xj∈Xi,则pj∈Pi。
每类的负荷曲线具有相似性,即曲线形状大致相似,且几个峰谷时刻基本相同,可认为同一类型负荷曲线以vi*为中心成正态分布[15-16]。根据正态分布理论计算每类负荷功率的可行域,具体步骤如下:
步骤1:针对每一类负荷Pj,计算正态分布参数:
(8)
步骤2:利用步骤1获得的参数,计算负荷曲线可行域的上下限:
(9)
步骤3:形成负荷分类的可行域矩阵,对于第i类负荷其可行域矩阵为:
(10)
2.2 坏数据修正
基于负荷曲线相似的性质,提出一种基于类心曲线置换的坏数据修正方法,其原理为用待修正数据曲线所属的聚类中心负荷曲线的相应部分,根据待修正数据部分首尾差值等比伸缩,置换待修正的数据。如图2所示。

图2 数据修正示意图Fig.2 Schematic diagram of bad data correction
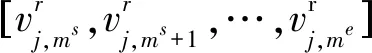
(11)
那么,修复后的数据可表示为:
(12)
2.3 方法应用流程
基于改进式k-prototypes聚类的坏数据辨识与修正方法如图3所示。在进行坏数据的辨识与修复时,含有缺失数据的向量直接标记为待修复数据,不参与聚类,减小坏数据对聚类结果的影响。

图3 方法应用流程图Fig.3 Flow chart of method application
3 算例分析
算例数据集包括负荷用电数据、天气数据、节假日数据。用电数据为广州某工业园现场采集的3个工厂从2018年7月1日~2018年10月24日的负荷96点功率数据(去除光伏)。3个工厂在数据采集期间,以周为单位从事规律性的生产活动,并根据国家法定节假日调整生产模式。天气数据为广州市同期的平均气温,节假日数据来源于国家法定节假日。对负荷数据进行处理:
(1)制造空白数据:每个工厂随机选择10条日负荷曲线,将每条曲线的部分数据删除,删除数据部分连续,长度随机且不超过整条曲线的40%;
(2)制造坏数据:每个工厂随机选择10条日负荷曲线,每条曲线随机选择3~20个点,升高或降低60%~70%。
根据1.3章节所述,选取改进式k-prototypes的算法参数,并结合具体工厂数据微调,如表2所示。

表2 改进式k-prototypes算例参数Tab.2 Example parameters of improved k-prototypes
3.1 改进式k-prototypes聚类效果
为测试随机初值,并行择优对k-prototypes算法陷入局部最优值的改善效果,对3个工厂进行仿真:选取不同的聚类数,从1逐渐增加并行分支数,记录代价函数值的变化,并重复多次。
图4为对空调厂聚类(k=5),并行分支数从0增至50,重复实验50次的效果图。图中每条曲线为一次实验结果,较粗的曲线为多次实验的平均值,数据点在底部形成的平行线为全局最优解。可见,随着并行分支数量的增加,平均代价函数值逐渐趋于全局最优解;并且对于单次运行结果,随着并行分支数量的增加,其代价函数值围绕全局最优解的波动幅度越来越小。

图4 优化后对陷入局部最优的改善Fig.4 Improvement of trapped local optima
利用改进式k-prototypes对工厂数据进行聚类,并选择FCM聚类算法进行对比。FCM聚类算法在坏数据辨识与修正的研究中应用广泛,较传统硬聚类算法效果更好。空调厂的聚类结果如图5所示,每条曲线为一条日负荷向量,较粗的曲线为聚类中心向量。由图5可见,当聚类数相同时,此聚类算法由于引入非负荷数据削弱坏数据的影响,聚类效果更好:
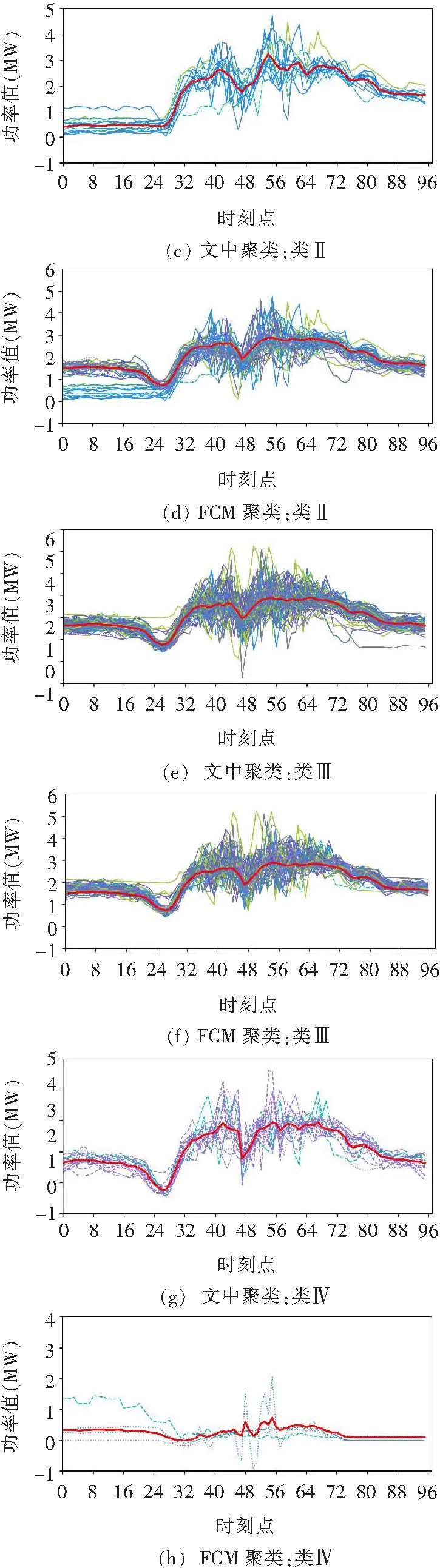
图5 改进式k-prototypes与FCM聚类结果对比Fig.5 Comparison between the improved k-prototypes and the FCM clustering result
(1)每类向量数量更均匀,类内更紧致,不受异常数据影响单独分类;
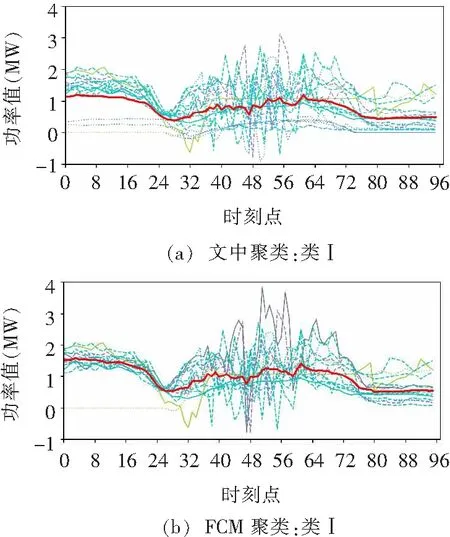
(2)不同类间分隔更明显,聚类的类心向量有明显区分,而FCM的类Ⅱ和类Ⅲ的中心向量比较相似。
3.2 坏数据辨识效果
不同的聚类结果会对坏数据的辨识效果产生影响[17]。图6为空调厂某个坏数据的辨识结果,图中虚线为计算的可行域。在文中算法中,坏数据所属向量被分到类Ⅲ,由于其越出可行域,被成功识别出来;而在FCM聚类算法中,坏数据所属向量被分到类Ⅰ,在该类可行域里,没有被正确识别;如果不进行聚类,虽然坏数据可以识别出来,但是识别结果在置信区间边缘,识别结果不稳定。

图6 聚类结果对坏数据辨识的影响Fig.6 Influence of clustering results on bad data identification
对3个工厂的坏数据辨识结果进行统计,坏数据的召回率与辨识的准确率如表3所示。与FCM聚类算法相比,文中算法在准确率保持不变的情况下,能辨识出更多的坏数据,显著提高了坏数据的召回率。相比于置信区间法,坏数据的召回率与准确率都有显著提升。
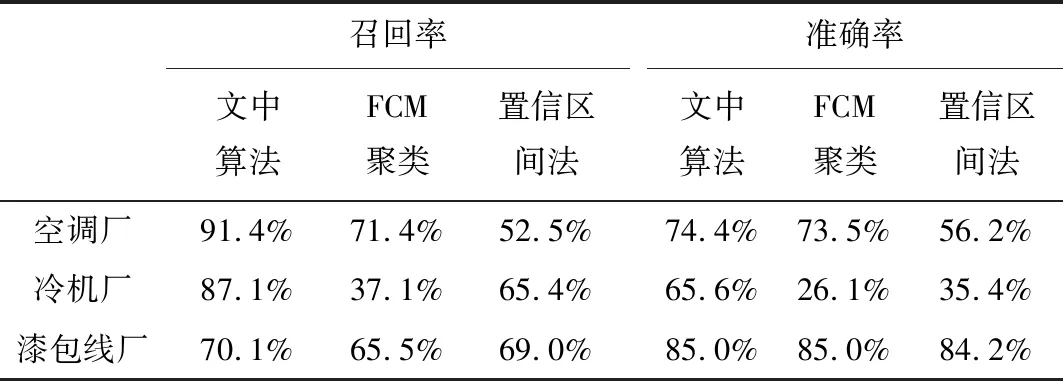
表3 坏数据辨识结果Tab.3 Bad data identification results
3.3 坏数据修正效果
利用所提的类心置换法对坏数据进行修正,通过与FCM+类心置换法比较,分析聚类对类心置换法修正准确率的影响;同时,对比线性插值法,分析所提基于聚类算法的类心置换法与直接插值法的修正准确率的区别。
如表4所示。对比基于FCM聚类的类心置换修正法,文中方法的修正准确率在空调厂、冷机场有少量的提高,在漆包线厂与其持平,可见聚类算法对修正准确率有一定影响。相比于线性插值法,所提类心置换法在修正数据时,由于考虑了数据变化趋势,对坏数据修正的准确率有显著提高。

表4 坏数据修正结果Tab.4 Bad data correction results
4 结束语
基于工业场景中混合数据集的聚类分析,提出了一种有效的坏数据辨识与修正方法。聚类过程中引入随机选择多组初值,并行聚类择优,克服传统k-prototypes算法容易陷入局部最优解的缺陷。并通过对聚类数的自适应处理,解决主观选择聚类数的问题。由于引入了非负荷数据,削弱了本身存在的坏数据对聚类结果的影响,使坏数据辨识的召回率和坏数据修正的准确率有所提高。
文中算法适用于大多数存在规律性生产模式的工厂,在实际生产过程中,一些小型工厂可能会根据需求缺口调整灵活的调整生产活动。后续的研究中,可进一步挖掘影响工厂生产活动的因素及其表征方法,应用到坏数据的辨识与修正的研究中。
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25
快乐语文(2021年35期)2022-01-18
中学生数理化·中考版(2020年12期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
活力(2019年15期)2019-09-25
小学生必读(中年级版)(2018年10期)2019-01-04
消费导刊(2018年8期)2018-05-25
摄影之友(影像视觉)(2017年1期)2017-07-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
