
基于深度学习的基层网络数据个性化挖掘算法
2022-03-01 01:03彭吉琼邓伦丹
计算机仿真 2022年1期
熊 蕾,彭吉琼,李 铭,邓伦丹
(1. 江西科技学院信息工程学院,江西 南昌 330098;2. 南昌大学科学技术学院,江西 共青城 332020)
1 引言
在数据库技术与计算机网络技术水平的持续升高的进程中,各种基层网络平台层出不穷,已然成为人们生活工作中不可缺少的一部分[1]。在各类基层网络的使用过程中,用户的各种数据均在基层网络内聚集,为更加有效地运用互联网空间内基层网络数据资源,扩大基层网络数据资源的应用范围,需对基层网络数据实施有效的挖掘[2-3]。怎样由海量的基层网络数据内容获取到所需数据,成为当前众多学者研究的重点课题。
以往所应用的数据挖掘方法中,大多通过资源检索各类基层网络数据资源的方式,运用数据封装类型实施逻辑归类区分,再经各自的数据挖掘算法实施数据挖掘。经过分析众多基层网络数据挖掘结果发现,以往的基层网络数据挖掘方法所运用的数据挖掘逻辑算法大多缺少逻辑序列,在挖掘数据节点集合序列存在数列耦合性排序时,会导致此类算法逻辑发生数据挖掘效率下降、数据回流及数据溢出等问题,造成最终的基层网络数据挖掘精度与效率的降低[4]。为有效提升数据挖掘精度与效率,很多学者做出了相关研究。其中基于贝叶斯网络的挖掘算法在一定程度上优化了以往的数据挖掘算法,通过贝叶斯算法构建三层挖掘平台实施数据挖掘,该算法挖掘精度高,但挖掘效率稍低[5];基于机器学习的数据挖掘算法是通过借助现代人工智能与各类数学模型,实现数据挖掘的目的,该算法具有较高的数据挖掘效率,但挖掘精度不够稳定[6]。
深度学习属于一种多层次的学习方法,其代表之一即为神经网络。神经网络可通过模拟人脑内部构造,模拟人脑的并行处理与自组织能力实施模拟推理与深度自主学习等,它无需依赖对象的数学模型,可通过深度自主学习以权值的方式对输入和输出实施编码,实现输入与输出的关联,具有较好的联想记忆能力及概括能力,其鲁棒性与精度较高令其在数据挖掘问题中具有较大的优势[7-8]。模糊神经网络(Fuzzy Neural Network,FNN)是通过有机结合神经网络与模糊逻辑,令其既具备模糊逻辑的不准确信息处理能力,而且具备神经网络的自学习能力,较普通神经网络其学习速度更高且规模更小[9]。
综合以上分析,本文研究一种基于深度学习的基层网络数据个性化挖掘算法,通过构建5层模糊神经网络并实施自主学习训练与裁剪后,提取出模糊神经网络规则,运用此规则实现基层网络数据个性化挖掘,为有效运用基层网络数据、扩大基层网络数据的应用范围提供帮助。
2 基于深度学习的基层网络数据个性化挖掘算法研究
2.1 挖掘算法整体过程设计
基于模糊神经网络的基层网络数据个性化挖掘算法的过程包括数据准备阶段、模糊神经网络构建与训练阶段、网络裁剪与规则提取阶段,如图1所示。

图1 基于模糊神经网络的基层网络数据个性化挖掘算法过程图
2.2 数据准备阶段
数据准备阶段属于基层网络数据个性化挖掘算法的基础阶段,为实施基层网络数据个性化挖掘提供数据准备。该阶段主要由数据清洗、数据选取及数据表示构成,其主要目的是实现对待挖掘数据的定义、处理及表示,令其可适用于所应用的数据挖掘算法。数据准备阶段功能结构图如图2所示。

图2 数据准备阶段功能结构图
各部分具体功能如下:
1)数据清洗部分:由于基层网络内的数据来源不同,导致此类数据中难免存在某些精确度低、不完整、重复及不一致等数据,需经数据清洗对此类数据实施空缺值填充、不一致数据纠正以及去噪等处理[10],其中去噪处理选取小波非线性滤波方法实现。
2)数据选取部分:通过在两个维上对用于此次挖掘的基层网络数据列与行实时选取,分别为列或参数维的选取、行或记录维的选取。
3)数据表示部分:该部分的主要任务为转化经过清洗与选取的数据为模糊神经网络数据挖掘算法能够接受的形式。因模糊神经网络数据挖掘算法能够处理的为数值数据,故此部分应转化符号数据为数值数据。可运用恰当的Hash函数,以给定的字符串为依据将某个唯一的数值数据形成。虽然基层网络内所存在的数据类别较多,但此类数据几乎均可归为连续数值数据、离散数值数据及符号数据三种逻辑数据类别。此三类数据之间的转化关系如图3所示。

图3 数据表示与转化
通过符号“Apple”部分运用Hash函数转化符号数据为其相对的离散数值数据,此时的离散数值数据不但能够编码为编码数据,也能够量化为连续数值数据。
经过数据准备阶段对待挖掘基层网络数据实施清洗、选取及表示后,获取到可适用于模糊神经网络挖掘算法的精确完整统一的基层网络数据,为提升整体挖掘精度奠定基础。
2.3 模糊神经网络构建与训练阶段
2.3.1 模糊神经网络的构建
构建五层模糊神经网络,其中第1层属于输入层;第2层属于模糊输入层,在该层内经各个属性的模糊隶属度函数化成三个分别为大、中、小语言变量的隶属度值,并令隶属度的最高单元输出为1,其它为0,以此构成第3层网络的输入;如果第2层网络存在N个单元,那么N=3n,其中n表示输入数量;第3层属于隐含层,同第2层全连接,该层存在H个单元;第4层属于模糊输出层,同第3层全连接,该层存在Q个单元,且Q=3m,其中m表示输出数量;第5层属于期望输出层,与输入到模糊输入层相似,经隶属函数化成隶属度值,最高值取为1,其它取为0,将通过模糊化之后的期望输出向该层输出。
针对基层网络内一个属性集中的数据序列,应运用统计的方式处理该数据序列,获取到模糊隶属度函数,实现模糊化过程[11]。所获取到的模糊隶属度函数形式可表示为

(1)
式(1)中,S、M及B依次表示属于小、中、大输入属性的隶属度值;对三个隶属度函数交点位置斜率实施操控的参数以e-k1、e-k2及e-k3表示;三个隶属度函数的中心值以δ1、δ2及δ3表示,可经求数据序列的均值χ与方差σ获取到,其运算式为

(2)
式(2)中,输入属性x的样本总数以k表示;输入属性的第i个样本以xi表示,其中i=1,2,…,k。
2.3.2 模糊神经网络的训练
为提升模糊神经网络的精度,需要通过训练神经网络的方式对隶属度函数的参数实施调整。将数据准备阶段中所获取到的待挖掘基层网络数据划分为训练组与测试组,选用反向传播学习算法实施模糊神经网络训练,其中训练组采样数据以(X1,X2,…,Xn;Y1,Y2,…,Ym)i表示,针对该组数据的训练过程如下:
1)在模糊神经网络的第1层输入X1,X2,…,Xn,那么outA(X1)=X1,…,outA(Xn)=(Xn);
2)依据式(1)在第2层运算各个输入对应的三个隶属度函数值;

5)在第5层中,对推理误差实施运算同时修正参数,运算式为
ω(n+1)=ω(n)+αi×Δω
(3)
式(3)中,学习系数以ω(n)表示;训练次数以n表示;第5层i节点以αi表示,当Δω>0时,ai=1,当Δω=0时,ai=0;
6)重复1)~5)训练过程,直至学习完全部样本数据;继续重复以上全部训练过程,直至学习时间结束或者训练误差比所要求误差低为止。
2.4 网络裁剪与规则提取阶段
为令模糊神经网络权值与节点数量最低,需根据特定规则裁剪训练后模糊神经网络,将训练后模糊神经网络内所存在的某些冗余权值消除掉,提升模糊神经网络的训练精度[12]。网络裁剪过程为:
1)设神经网络的误差极限与权值删除的阈值分别以η1和η2表示,同时η1+η2<0.5,训练神经网络至设定精度;

4)重新对模糊神经网络实施训练,如果神经网络的精度比设定的精度低,则向步骤3)返回继续对神经网络权值实施取舍;反之则终止训练,并运用此时的神经网络权值。
完成神经网络裁剪之后,对训练所产生的规则实时提取。视网络权值为0或近似于0的规则为无效规则,对于具备共同前提的全部规则,提取并保留其中权值最大规则,删掉其余规则。在此基础上,运用最终训练后的模糊神经网络依据所提取规则对测试组基层网络数据实施挖掘。
3 实验结果分析
为检验本文算法的应用效果,以采集的两个标准基层网络数据集(A数据集与B数据集)为实验数据集,运用本文算法实施挖掘。其中A数据集属于网页数据集,共包括127个类别97874个网页文本;B数据集属于常见的文本数据集,共包括20051个文本。现分别将两个实验数据集划分为训练集与测试集,并选取基于贝叶斯网络的挖掘算法(文献[5]算法)与基于机器学习的挖掘算法(文献[6]算法)作为本文算法的对比算法,分别对三种算法实施训练与测试,依据训练与测试结果对比三种算法的应用效果与性能。
3.1 整体挖掘效率对比
检验三种算法的收敛速度与测试时单位时间处理数据样本的数量,对比结果如图4所示。

图4 各算法收敛速度与训练测试速度对比
通过图4可以看出,在收敛速度测试中,本文算法的单位时间处理数据样本数量明显高于其它两种算法,可见,本文算法在收敛速度与训练测试速度上均具有显著优势,可有效节省训练与测试时间,提升整体挖掘效率。
3.2 挖掘精度对比
为提升挖掘精度检验结果的可信度,实验中运用A、B两个数据集分别对三种算法实施15次训练与测试,以各算法15次实验结果的平均值作为检验各算法挖掘精度的对比结果。实验中选取精确率P、查全率R及重合率D作为检验各算法挖掘精度的指标,各指标的运算方式为:
1)精确率P是指正确挖掘的数据量在挖掘总数据量中的占比,其运算式为

(4)
式(4)中,挖掘总数据量与真实待挖掘数据量分别以φ和r表示;
2)查全率R的运算式为

(5)
3)重合率D是指运用挖掘算法所挖掘到的数据与实际需要挖掘数据之间的相似程度,该值越高则表明挖掘效果越好,其运算式为

(6)
式(6)中,运用挖掘算法所挖掘到的数据以γ表示;实际需要挖掘的数据以θ表示。
各算法挖掘精度对比结果如表1所示。
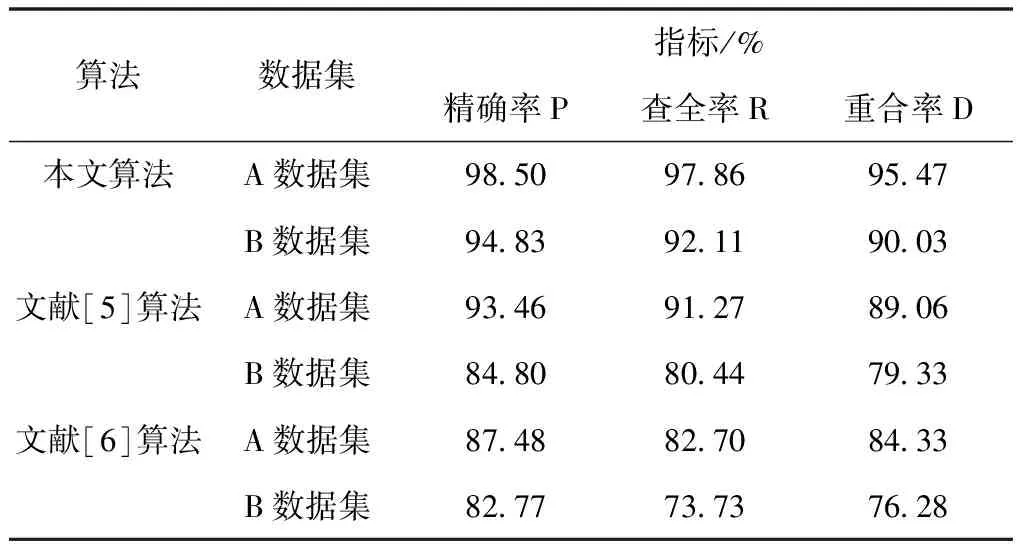
表1 各算法挖掘精度对比结果
分析表1中数据可得知,在对A数据集实施挖掘中,本文算法的挖掘精确率、查全率及重合率均高于其它两种算法,
表明本文算法针对A数据集的挖掘精度最高;在对B数据集实施挖掘中,本文算法的挖掘精确率、查全率及重合率均比挖掘A数据集时稍低,但也明显比其它两种算法高。由此可见,本文算法在针对不同数据集实施挖掘时,均有较高的整体挖掘精度,且挖掘性能较为稳定。
4 结论
本文针对深度学习的基层网络数据个性化挖掘算法展开研究,设计包含数据准备阶段、模糊神经网络构建与训练阶段、网络裁剪与规则提取阶段的模糊神经网络基层网络数据个性化挖掘算法整体过程,经数据准备阶段定义、处理及表示初始基层网络数据,得到精度较高的待挖掘基层网络数据,通过模糊神经网络构建与训练阶段构建5层模糊神经网络并对其实施训练,由网络裁剪与规则提取阶段实现对训练后模糊神经网络内冗余权值及规则的删减,同时保留最高权值规则作为模糊神经网络的挖掘规则对基层网络数据实施个性化挖掘。实验结果表明,本文算法具有较高的收敛速度,在训练与测试中具有较高的数据样本处理效率,整体挖掘结果精度高且性能十分稳定,实际应用价值较高。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
软件(2017年6期)2017-09-23
电子技术与软件工程(2016年24期)2017-02-23
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
职业·中旬(2009年12期)2009-06-01
