
基于多模式分解的碳交易价格组合预测模型
2022-03-04 02:19陈臣鹏毕贵红陈仕龙
电力科学与工程 2022年2期
赵 鑫,陈臣鹏,毕贵红,陈仕龙,谢 旭
(昆明理工大学 电力工程学院,云南 昆明 650500)
0 引言
“十四五”规划指出,二氧化碳排放力争2030 年前实现“碳达峰”,努力争取2060 年前实现“碳中和”。“十四五”期间将出台更加强有力的碳排放交易政策,加强对煤炭消费的控制,加大对可再生能源发展的支持力度,继续推动经济社会加速向低碳方向转型,为“碳中和”奠定基础[1]。过去20 年,我国的二氧化碳排放增速是世界其他国家和地区的6 倍,在全球二氧化碳排放增量中约占70%;2020 年以来,我国人均二氧化碳排放量已超过欧盟;引入碳交易机制、降低碳排放强度已成为当前的紧迫任务[2]。为了减少碳排放,作为应对气候变化、降低碳排放、履行国际减排承诺的重要手段,我国于2017 年12 月启动了7 个全国统一的碳排放权交易市场。
影响碳产品交易价格的因素主要包含政策因素、供求因素和气候、能源价格和宏观经济环境等因素。文献[3]通过参数检验法得出:有效的市场试点及政策实施会减少碳交易价格的波动性和非平稳性。碳交易价格是提高碳市场风险管理能力的基础,也是制定碳交易市场政策的重要依据;因此寻求一种能有效提取碳交易价格的波动特征并对其进行较为准确地预测的方法十分重要。
传统的统计和计量预测模型,如GED-GARCH域[4]、改进的Grey-Markov[5]等,对非线性数据的处理能力较差。为了解决这个问题,提出了基于机器学习的预测方法,如ARIMA-SVM[6]、BP[7]等。与传统方法相比,机器学习预测方法可以更好地处理非线性数据,能有效地提高预测精度。为了更进一步捕获时间序列的深度特征和波动规律,人们又将时间序列进行多尺度分解,得到代表原始序列的多尺度特征;然后选择合适的预测模型分别预测各子序列;最后用特定的方法将各子序列预测值合并得到最终预测值。实验证明,该方法具有更高的预测精度[8-10]。
由于历史碳价序列具有较强的非线性和非平稳性,若采用传统数学计量与机器学习方法对其进行预测,则对碳价序列的特征提取能力较差,预测效果一般。因此为了进一步降低各模态耦合的非线性与非平稳性对预测准确率的影响,充分提取碳价序列的多尺度特征,本文提出一种多模式分解、样本熵重构和WOA-LSTM 组合的预测模型。首先,用奇异谱分解(singular spectrum decomposition,SSD)、变分模态分解(variational modal decomposition,VMD)以及完全集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)这3 种方法分别分解原始碳价序列,实现不同模式模态分量规律的互补;然后,使用样本熵对熵值接近的模态分量进行重构,以减少分量数,提高预测效率;最后,分别将各重构分量输入到WOA-LSTM 预测模型中进行预测,得到3 个初始预测值,再由最优加权组合法将3 个初始预测值线性组合得到最终的预测值。
1 分解及预测算法分析
1.1 多模式分解算法
1.1.1 奇异谱分解
奇异谱分解(SSD)能自适应选取嵌入维数L,克服了奇异谱分析(SSA)按经验手动选取L的缺陷。SSD 的实现步骤包括:创建轨迹矩阵、自适应选取嵌入维数L、从高频分量到低频分量依次重构得到SSC 分量、设置迭代停止条件(当残余项和原始信号间的归一化方差小于给定阈值时停止迭代,分解完成)。具体实现步骤详见文献[11]。
1.1.2 变分模态分解
变分模态分解(VMD)是一种自适应、完全非递归的模态变分和信号处理的方法。VMD 可以根据待分解的序列自适应地确定模态分解的个数,从而自适应地匹配每种模态的最佳中心频率和有限带宽。VMD 克服了经验模态分解(empirical mode decomposition,EMD)存在端点效应和模态分量混叠的问题,可以更好地降低时间序列的非平稳性和复杂度。通过VMD,可以得到多个频率尺度不同且相对平稳的子序列。VMD 的核心思想是构建和求解变分问题,具体实现步骤详见文献[12]。
1.1.3 完全集合经验模态分解
为了解决EMD 分解信号出现模态混叠的现象,提出了集合经验模态分解(ensemble empirical mode decomposition,EEMD)和互补集成经验模态分解(complementary ensemble empirical mode decomposition,CEEMD),两者通过在待分解的序列中加入成对正负高斯白噪声减轻EMD 存在的模态混叠现象。EEMD 和CEEMD 分解得到的模态分量中总会残留一定的白噪声,进而影响后续信号的分析和处理。为了解决这些问题,文献[13]提出了一种基于这2 种分解方法的改进算法——完全自适应噪声集合经验模态分解(CEEMDAN),又称完全集合经验模态分解,具体实现步骤详见文献[13]。
1.1.4 样本熵
样本熵(SampEn)是一种体现信号复杂程度的优化算法。相比近似熵,样本熵的优势为:样本熵的计算与序列维度无关;参数的变化对样本熵的影响程度是一致的,即一致性较好。样本熵值相近的信号,即复杂程度接近的信号可合并为一个分量,起到了降低计算量、简化模型的作用[14]。
1.2 基于WOA-LSTM 的预测模型
1.2.1 长短期记忆神经网络
长短期记忆神经网络(LSTM)是一种特殊的循环神经网络(RNN)。LSTM 有效消除了RNN在处理长时间序列时出现梯度爆炸或消失的弊端[15]。LSTM 由许多记忆块构成,每个记忆块由输入门、输出门和遗忘门组成,三者功能如下。
(1)遗忘门决定信息的更新。
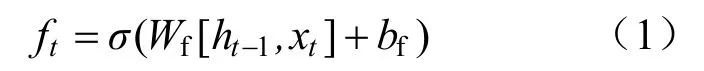
式中:Wf、bf分别为遗忘门sigmoid 激活函数的权重与偏置。
(2)输入门决定当前信息的输入。

式中:Wi、bi分别为输入门sigmoid 激活函数的权重与偏置;WC、bC分别为输入门tanh 激活函数的权重与偏置;Ct为新细胞状态信息。
(3)输出门决定下一隐藏层的值。

式中:Wo,bo分别为输出门sigmoid 激活函数的权重与偏置。
1.2.2 鲸鱼优化算法(WOA)
鲸鱼优化算法的主要原理是模拟座头鲸的随机捕食行为。鲸鱼优化算法具有全局搜索能力强、计算简单、参数少等优点,其主要实现步骤如下[16]。
步骤1:寻找猎物。鲸鱼第i次搜索行为可用式(4)表示:

式中:xrand为鲸鱼群中某个鲸鱼的位置;i,L分别为当前迭代次数和总的迭代次数;A,c为系数;当|A|≤1 时,锁定猎物,进入包围猎物阶段。
步骤2:包围猎物。鲸鱼向最佳猎物的方向更新位置,通过更新位置包围猎物,最终确定猎物的位置。这一行为可由式(5)表示。

在式(5)中,x(i+1)由x(i)向x*(i)更新,逐步包围猎物。
步骤3:狩猎。计算鲸鱼与猎物之间的距离D2,通过式(6)模仿座头鲸的螺旋状移动。

式中:b为常数,定义对数螺线的形状;l∊[–1,1]。鲸鱼群通过随机选择以下2 种方式(概率均为0.5)进行狩猎,可用式(7)表示。
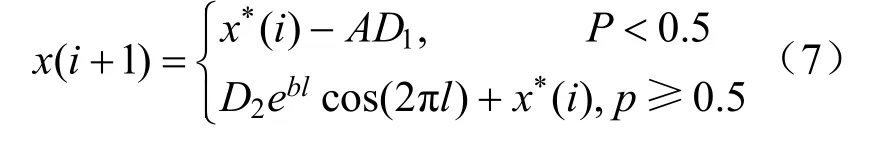
式中:当p<0.5 时,为收缩包围式狩猎方式;当p≥0.5 时,气泡网螺旋式狩猎方式。
1.2.3 WOA-LSTM 预测模型
为降低人工调参的随机性,提高预测精度,采用鲸鱼优化算法对LSTM 网络进行优化。将LSTM 网络的迭代次数l、学习率e、第一层隐藏节点数a1和第二层隐藏节点数a2作为WOA 的寻优对象,以获取最佳超参数[17-18]。WOA-LSTM 模型主要流程如下。
步骤1:将数据划分为训练集与测试集。初始化鲸鱼优化算法的维度、迭代次数以及种群数。设定LSTM 网络各超参数的数值范围。
步骤2:随机生成10 个鲸鱼群,并用对应的参数设置长短期记忆网络。
步骤3:将模型的预测值与真实值的均方根误差作为适应度,计算每个种群对应的适应度。把其中最小适应度对应的结果作为此次的最优结果,并与全局最优结果进行比较。如效果更好,则替换。
步骤4:迭代开始。用WOA 不断更新鲸鱼群对应的4 个超参数;重复步骤3—4,直到所有迭代完成。
步骤5:输出最优结果对应的各个超参数,将输出的超参数带入LSTM 模型中进行预测。
1.2.4 最优加权组合法
在分别采用 SSD-LSTM、VMD-LSTM 和CEEMDAN-LSTM 模型得到初始预测值后,为确定合适的权重使3 个预测值进行线性结合,采用最优加权法计算权重系数。具体步骤如下[19]。
步骤1:计算得到误差矩阵E。

式中:N为预测总时间;et_ssd,et_vmd,et_ceemdan分别为3 个模型在时刻t的预测值与真实值的误差。步骤2:由拉格朗日乘子法得到最优权重。

式中:ω1,ω2,ω3(ω1+ω2+ω3=1)分别为3 个模型预测值的权重系数;R为三维单位列向量。
步骤3:得出最终的碳价预测结果如式(10)所示:

2 多模式分解组合预测模型
为提高碳交易价格的预测准确率,提出一种基于多模式分解、样本熵重构与WOA-LSTM 的组合预测方法。该方法运算步骤如图1 所示。

图1 组合预测模型运算流程Fig.1 Operation process of combined prediction model
(1)数据预处理:由SSD、VMD 和CEEMDAN分解历史碳价序列各得到x个分量,其中,包括x–1 个模态分量和1 个残余分量Ri(i=1,2,3),Ri由原始序列减去x–1 个模态分量之和得到。
(2)分量重构:多模式分解得到的模态分量数量较多,分别预测计算量较大。为了简化模型,减小预测难度,通过计算各模态分量的样本熵值,将熵值接近的分量重构为1 个新分量,再将各重构分量分别输入到WOA-LSTM 网络中进行预测。
(3)一次预测:将各重构分量对应的预测值直接相加,得到3 个模型对应的初始预测值。
(4)二次预测:使用最优加权法计算出3 个初始预测值对应的最佳权重系数,根据权重系数对3 个初始预测值进行线性组合得出最终的预测结果。
3 实验及结果分析
3.1 预测结果评估指标
为了评估预测结果的有效性,使用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)以及均方根误差(RMSE)对实验预测结果进行评估。3 种误差的计算公式如式(11)所示:

式中:Zt为t时刻碳价真实值;为t时刻碳价预测值;为碳价真实值的平均值。
3.2 数据选取
本文实验数据来源于某省碳排放交易所的历史碳交易价格数据。选用2013 年12 月19 日—2021 年10 月25 日的共1 635 个价格数据(不包括公共假日)作为实验的原始数据集。将数据集的前95%作为训练集,后5%作为测试集。对2021 年7 月7 日—2021 年10 月25 日(共76 天)进行碳交易价格预测。交易所的历史碳交易价格如图2 所示。

图2 历史碳交易价格Fig.2 Historical carbon trading prices
3.3 数据分解
使用SSD、VMD 和CEEMDAN 算法分解原始数据。由3 种分解算法分别得到8 个分量(7 个模态分量和1 个残余分量)。分解结果如图3 所示。

图3 各分解算法的分解结果Fig.3 Decomposition results of each decomposition algorithm
图3(a)中,SSC 分量按高频到低频排列,R1 为残余分量;图3(b)中,IMF 分量按低频到高频排列,R2 为残余分量;图3(c)中,imf 分量按高频到低频排列,R3 为残余分量。
3.4 样本熵重构分量
使用样本熵法重构分量,以减少分量数。图4示出各分解方法模态分量的样本熵值。对各分解方法得到的模态分量分别进行重构,重构结果如表1。
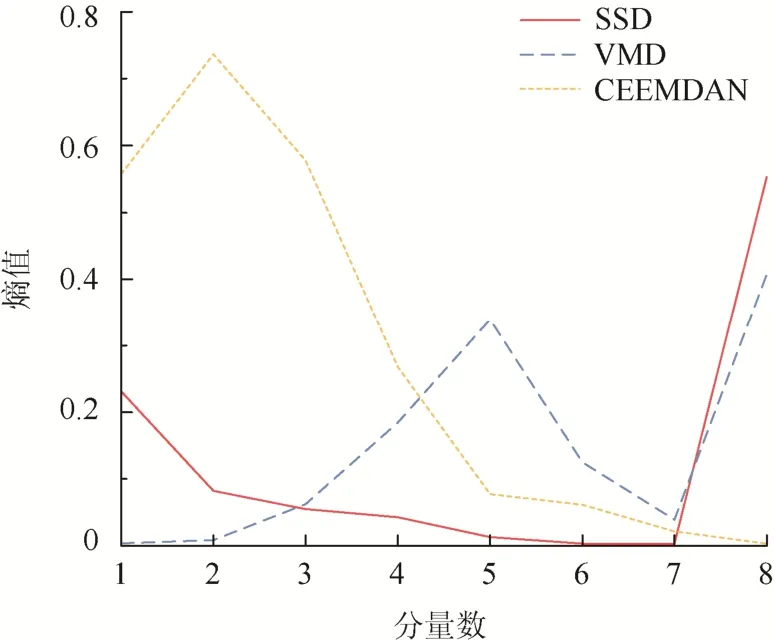
图4 各分量算法对应的熵值Fig.4 Entropy value corresponding to each component algorithm

表1 重构结果Tab.1 Reconstruction results
3.5 实验结果分析
对于重构得到的3 组分量(A1—A4,B1—B4,C1—C4),分别使用WOA-LSTM 网络进行预测,然后分别叠加各组分量的预测值,得到3 组初始预测值;根据最佳加权组合法计算各预测值对应的权重系数,再由权重系数将3 组预测值线性组合为最终的碳交易价格预测值。实验构建的预测网络共4 层,包括输入层、2 层LSTM 和输出层;其中,输入层输入前5 天的数据,输出层输出第6天的预测值,损失函数采用均方根误差RMSE;鲸鱼优化算法迭代次数设为10,种群数设为10。表2 为各初始预测值对应的权值系数。

表2 各初始预测值的权值系数Tab.2 The weight coefficient of each initial prediction value
为了验证本文多模式分解集成的组合模型对多尺度碳交易价格预测的有效性,采用相同的WOA-LSTM 预测网络,同时构建了单模式(SSD/VMD/CEEMDAN)分解集成的组合模型。各模型预测值与真实值的对比结果如图5 所示。对各模型的预测值与真实值之间的误差进行比较,比较结果如表3。

图5 不同模型预测值与真实值比较Fig.5 Comparison between predicted values with real values of different models

表3 不同模型的误差对比Tab.3 Error comparison of different models
由图5 和表3 可看出,相比其他单模式分解模型,本文提出的多模式分解模型的预测值与真实值的拟合性能最优,3 个误差评价指标相比单模式分解模型明显降低。
与同样以该所碳交易价格为研究对象的文献[20-21]结果做比较,比较结果如表4。由表4 可看出,本文提出的预测模型比文献[20-21]中的各误差评价指标均小:基于多模式分解WOA-LSTM 的组合预测模型可以得到更高的预测准确率,在碳交易价格预测领域更具优势。

表4 与其他文献对比Tab.4 Comparison with other documents
4 结论
本文提出基于多模式分解WOA-LSTM 的碳交易价格预测模型,以某省碳交易价格为研究对象,通过实验计算得到以下结论。
(1)使用SSD+VMD+CEEMDAN 的多模式方法分解原始碳交易价格序列,可以得到更能反映碳交易价格序列的深层次变化特征的多层模态分量,能充分发挥各种分解方法的优势,降低碳交易价格序列非线性和非平稳性对预测准确率的影响。
(2)使用样本熵法将分解得到的分量重构为新分量后进行预测,减少了预测分量数,提高了运算效率;再引入WOA-LSTM 的组合预测网络,利用LSTM 时序依赖的特性对输入向量进行拟合并输出碳交易价格的预测值。相比其他文献的方法,WOA-LSTM 预测模型的准确率明显提升。
碳交易价格预测的准确率是提高碳市场风险管理能力的基础,也是制定碳金融市场政策的重要依据。本文对某一个省的碳交易价格进行了实验预测;该模型也可为其他7 个碳排放交易市场的碳交易价格预测提供一定的参考。
猜你喜欢
电子产品世界(2021年6期)2021-02-10
读者·校园版(2020年19期)2020-09-16
中国现代医生(2020年2期)2020-04-09
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
法制与社会(2018年20期)2018-08-21
英美文学研究论丛(2018年1期)2018-08-16
中国经贸(2018年7期)2018-05-10
会计之友(2017年20期)2017-10-25
医学信息(2016年31期)2017-02-27
