
课程教学中基于模糊规则的知识网推荐方法
2022-03-07 02:38朱玉全
江苏大学学报(自然科学版) 2022年2期
朱玉全, 石 亮, 李 雷
(江苏大学 计算机科学与通信工程学院, 江苏 镇江 212013)
课程是实施教学的基本单位,其教学效果直接决定着人才培养质量.通常情况下,每门课程是由功能相对独立且相互间有联系的知识点构成,如《程序设计基础》课程包含了200多个知识点.知识点逻辑结构与知识点线性表之间存在着前继关系.知识点是学习者学习的对象,是知识在意识层面的抽象集合.在线下教学环境中,学习者对知识点的学习过程就是任课老师课堂知识点的传授过程,老师根据个人理解和课程的知识体系将知识点连成一条路径,这种学习方法方便、快捷、直观性强,易于初学者循序渐进地学习课程知识.但学习者无法根据各自已有知识制定个性化的知识学习路径,不适应(超前或跟不上)老师节奏的现象时有发生,线上课程教学为改变这种情况提供了一个很好的机会.为了避免线上课程教学中出现“一抓就死,一放就乱” 的尴尬局面,需要为每个(每类)学习者推荐适合其自身特点的学习路径,知识网推荐已成为线上课程教学中的一个重要技术支撑.
对于知识网构建和知识推荐技术,P. BRUSILOVSKY[1]用平面地图来描述所有知识,学习者通过地图获得与学习课程内容相关的学习指南.O. C. SANTOS等[2]通过测试学习者的学习等级来推荐与其等级相对应的知识.王丽萍[3]提出了一种基于学习者当前知识点水平的学习路径推荐方法,推荐合适的知识点、学习对象、学习路径等内容.PAN L. M.等[4]将学习路径规划问题分解为先后序学习问题,进而将其形式化为二分类问题进行解决,该方法只考虑了学习对象本身对学习路径推荐的影响,但未考虑学习者的个性化因素.陈娬[5]给出一种知识构建方法,将知识构建评价效果反馈到知识构建中,能及时掌握学生的学习变化情况.黄亚澎[6]给出一种基于知识模式的个性化学习路径推荐方法,构建了刻画学生学习行为特征和学习状态特征的学习特征模型,具有一定的有效性和适应性.翟域等[7]提出一种基于知识状态的个性化学习资源推荐方法,通过知识图谱构造、待学习知识点向量生成、相似性迭代算法设计等过程,从学习资源库中推荐最适合学习者的学习资源.苏庆等[8]构建一个基于学习情况的个性化学习推荐模型LS-PLRM(learning situation based personalized learning recommendation model),为学习者推荐一种个性化学习方案.刘真等[9]提出了一种知识聚合和迁移相结合的跨领域推荐算法ATCF(aggregation and transfer collaborative filtering algorithm),融合了辅助域和目标域的知识,通过基于矩阵分解的两级矩阵拼接和两次矩阵填充,得到在群集矩阵及评分矩阵上的共性知识表示,通过知识迁移构建了重叠用户和非重叠用户的个性知识表示,有效避免了负迁移.周炫余等[10]提出一种基于联合知识图谱和时间特性的数学知识自动推荐方法,该方法利用自注意力机制和前馈神经网络获取带有时间特性的学习者表示,根据知识图谱三元组中知识点与知识点的高阶连通特性和学习者特性深层次表征知识点,计算学习者与知识点交互的概率,并根据概率进行推荐.罗莘涛等[11]提出基于评论特征提取和隐因子模型的评分预测推荐模型,使用自适应感受野的卷积神经网络提取局部特征,同时使用门控循环单元提取全局特征,将不同特征融合为评论的嵌入表达,再结合隐因子模型对用户的特征偏好和商品的特征属性进行整合.
由此可见,目前已提出了许多知识网构建和知识推荐方法,这些方法或多或少为知识推荐提供了一种有效的解决方案.然而,这些推荐方法未能充分考虑学习者的学习目的,而学习目的的不同会导致不同的知识需求.如学习某一编程语言,计算机专业的学生需要进行深入研究,而其他专业的学生只需了解即可,需要根据学习者的目的来推荐知识和学习路径.另外,在学习某课程知识时,学习者对某一知识点的现有了解程度也会影响知识点的学习次序.
文中拟提出一种基于模糊规则的知识网推荐方法,将课程老师的教学经验和已学过该课程学习者的学习路径分别组成知识网;融合匹配度和认知水平来计算知识网之间的相似度,采用模糊C均值聚类方法对知识网进行聚类;将聚类隶属度最大的知识网推荐给学习者,或将各聚类隶属度最大的知识网优化组合成一个新的知识网推荐给学习者.
1 知识网及其构建
1.1 知识网
借鉴图形结构的思想,将每门课程的知识点以及相互之间的关系组织成一个知识网.另外,根据课程知识网和每位学习者的学习习惯,将每位学习者学习过的知识点按照认知水平和学习次序组织成一条学习路径,按照不同的知识模块将学习路径组织成一个学习者知识网,该知识网基本继承了课程知识网中的包含和递进关系.在此,知识模块可以按照某门课程的章节划分,或对知识点进行聚类得到知识模块.知识网结构见图1,不同学习者的知识网可能有所不同.

图1 知识网结构图
1.2 知识网的构建
知识网的构建过程如下:
1) 把某一课程中的知识点按照章节组织成各个知识模块,或使用聚类方法将知识点组织成不同的知识模块.
2) 把各个知识模块按照树形结构组织成知识框图,根据某个知识点构造根节点,根节点的孩子节点即为根节点所对应知识点的进一步细化,叶子节点即为最小的知识点,非叶子节点的孩子节点即为该节点所对应知识点的进一步细化.
2 基于模糊规则的知识网推荐方法
每个学习者的学习路径都与某知识网有一定的对应关系,每个知识网有不同的知识模块,学习者选择适合其学习目的的学习路径就是对知识网的选择.
2.1 知识网的相似度
将学习者的认知水平融合到知识网的匹配度计算中,分别从质和量两方面来定义知识网的相似性.
2.1.1知识网的匹配度
匹配度用来衡量两个知识网之间的匹配程度.设知识网U和V中最底层的知识点集分别为PU、PV,PU={Pu1,Pu2,…,Pum},PV={Pv1,Pv2,…,Pvn},其中m、n分别为PU和PV中所包含的知识点个数.设Pui中知识点的个数为lui(i=1,2,…,m),Pvj中知识点的个数为lvj(j=1,2,…,n).PU与Pvj具有相同知识点的个数为lvj,U,PV与Pui具有相同知识点的个数为lui,V,U和V的匹配度为
2.1.2学习者的认知水平
认知水平是指学习者对知识的掌握程度,是判断学习者对知识掌握程度的主要指标.一般情况下,人脑对知识的记忆随时间的推进而逐渐减退.
当学习者需要学习某知识模块时,与该知识模块相匹配的知识网并不一定适合学习者的目的,学习者希望采纳具有相近认知水平学习者的知识网来指导其学习.
2.1.2.1认知水平
根据布鲁姆认知理论,认知水平可分为6个等级,从低到高分别为知道(知识)、领会(理解)、应用、分析、综合、评价.由于学习者的认知水平具有较大的不确定性,采用模糊集来表示其认知水平;用隶属度uk(i)表示各个级别的值,i=1,2,…,6,模糊集计算式为

2.1.2.2模糊推理及其模糊化
模糊推理是指从不精确前提集中推出可能不精确结论的推理过程,文中采用Mamdani模糊推理方法,具体计算如下:
式中:M为模糊规则总数;uA′(x)为论域U上的一个模糊集.在实际应用中,还需进行解模糊化,常用的解模糊化方法有中心法、重心法等.文中采用重心法,计算式为
2.1.2.3记忆量
试验表明人脑有一套容量有限的记忆系统,随着时间的推移,有些信息会被遗忘.所谓遗忘是指识记过的内容在一定条件下不能或错误地恢复和提取,按照信息加工的观点,遗忘就是信息提取不出或被错误提取.研究成果表明记忆的保持和遗忘是时间的函数,即记忆量是时间的函数,文中采用的记忆量计算式为
式中:Mt为学习者对知识点的记忆量;a和b为权重参数,a+b=1;t、t0为第1、2次的学习时间,d;lt为本次学习所用的时间,d.
在现实学习环境中,学习者对知识的认知水平随着学习次数的增加而不断提高.在某一认识水平上,随着学习次数的增加,学习者对此知识的记忆时间也会延长,同时认知水平等级提高的概率也会随之增加.为了使记忆量模型遵循这一规律,在此进一步完善了记忆模型,具体修改如下:
式中:R为认知水平等级;T为学习知识的次数.
2.1.2.4做题时间
学习者的做题时间是其对知识掌握程度的一个重要体现,文中将做题时间划分为两个时段,即正常时段和非正常时段.在正常时段内正确答题,表示学习者熟练掌握试题所体现的知识点.而在非正常时段内完成,则认为其对知识不了解、不熟练.由于学习者对某一知识的熟练程度具有一定的模糊性,文中用隶属度函数来表示其熟悉程度,采用F(t)函数来计算学习者的做题时间,计算式为
式中:t≤α为正常时段;t≥γ为非正常时段;β=(α+γ)/2.
2.1.2.5隶属度函数及模糊规则库
隶属度函数的确定方法有指派法、模糊专家法、二元对比排序法等.文中结合指派法和模糊专家法来确定隶属度函数,建立试题难度分别为小、中、大的3个模糊集,设定其对应的模糊隶属度函数.同样建立试题难度贡献率为很少、少、适中、多、很多的5个模糊集,设定其对应的模糊隶属度函数.
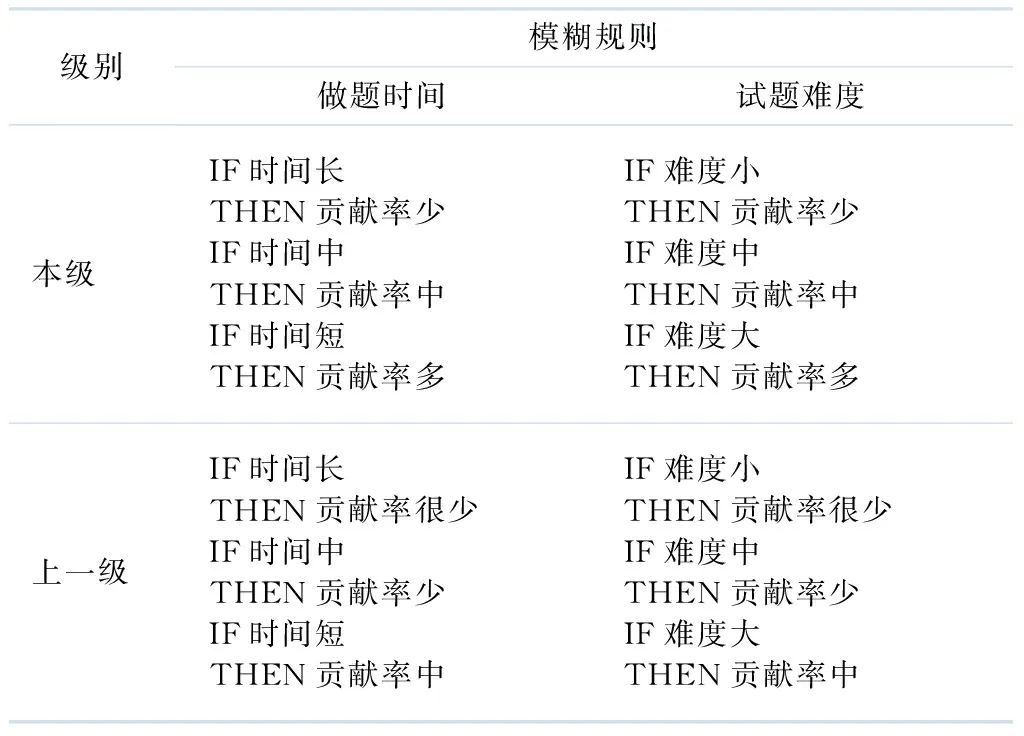
模糊规则库是一系列模糊IF-THEN规则的集合,是模糊推理的基础.在采纳有关专家经验的基础上建立规则库,表1-3分别给出了记忆量多、中、少时所采用的模糊规则,其中的上一级、本级、次一级是相对于学习者当前的认知水平等级而言的.

表1 模糊规则(记忆量多)

表2 模糊规则(记忆量中)

表3 模糊规则(记忆量少)
续表
由表1可见,当学习者的记忆量高时,其认知水平等级(知道、领会、应用、分析、综合、评价)上升的可能性较大.学习者做对次一级别试题时,次一级的做题时间贡献率要比本级和上一级低.做对本级试题时,其做题时间贡献率要高于次一级而低于上一级.做对上一级的试题时,其做题时间的贡献率要高于次一级和本级.同理可解释表2、3中的模糊规则.
2.1.2.6学习者认知水平估算方法
认知水平估算方法综合考虑做题时间、试题难度和记忆量等因素,通过模糊规则和模糊推理推出认知等级的影响参数,以此估算出认知水平的等级隶属度,隶属度最大的等级即为学习者的最新认知水平等级.具体估算过程如下:
1) 根据历史数据计算出学习者的当前记忆量.
2) 当前记忆量模糊化.
3) 选择相应的水平等级分为6个不同的等级,分别用1、2、…、6来表示,在此基础上对认知水平等级进行规格化.
2.1.3知识网的相似度
由于知识网之间的层次结构不同,即使两个知识网的匹配度和认知水平完全相同,仍不能说明它们是相同的.
文中综合考虑知识网的质、量及层次结构等因素,给出知识网相似度的计算方法,计算式为
式中:αui、lui、μui和βvj、lvj、μvj分别为知识点pui和pvj所处的知识网层次、知识数、认知水平.
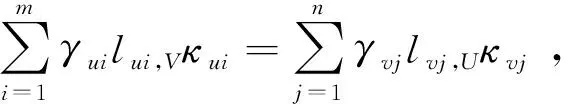
2.2 算法描述
综上所述,基于模糊规则的知识网推荐方法的基本思想如下:
1) 计算知识网之间的相似度,由此得到知识网的相似度矩阵.
2) 利用模糊C均值聚类算法对学习者知识网进行聚类.
3) 将聚类中隶属度最大的知识网推荐给学习者.
4) 将每个聚类中隶属度最大的知识网优化组合成一个新的知识网,并将之推荐给学习者.
5) 设学习者需求的知识网为W,计算W与每个聚类中隶属度最大的知识网之间的相似度.
6) 将相似度最大的知识网作为参考知识网推荐给学习者.
3 试验结果与分析
从《数据库系统原理》课程知识点模块的学习信息中提取15名学习者的学习路径,组成知识网,并将之作为文中的试验数据.
3.1 知识网之间相似度计算实例
下面以知识网W1和W2为例来展示知识网之间相识度的计算过程,W1和W2结构见图2、3.
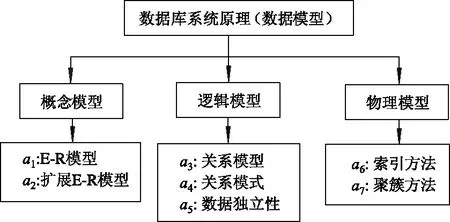
图2 知识网W1
W1和W2中最底层的知识点集分别为
PW1={a1,a2,a3,a4,a5,a6,a7},
PW2={b1,b2,b3,b4,b5,b6,b7},
式中:a1包括实体、属性、联系、E-R图等;a2包括ISA联系、基数约束等;b5包括关系、元组、属性、分量等.

图3 知识网W2
利用前面所述方法估算出学习者对各知识点的认知水平,利用函数y=x/6将认知水平等级值规格化.如W1中学习者对知识点a1的认知水平估算值为5,规格化后为0.833.由此得到W1和W2的模糊化认知水平分别为
uW1=(0.833,0.833,0.501,0.501,0.334,0.668, 0.334),
uW2=(0.997,0.833,0.668,0.501,0.334,0.501, 0.501).
计算W1和W2之间的相似度,计算式为
式中:
A=2×0.997+2×0.833+2×0.668+3×0.501+2×0.334+2×0.501+3×0.501;
B=2×0.833+3×0.833+2×0.501+2×0.501+2×0.334+2×0.668+3×0.334;
C=2×( 3×0.997+2×0.668+3×0.501+3×0.334).
3.2 试验结果与分析
采用与3.1同样的方法计算出W1-W15的模糊化认知水平,具体如表4所示.
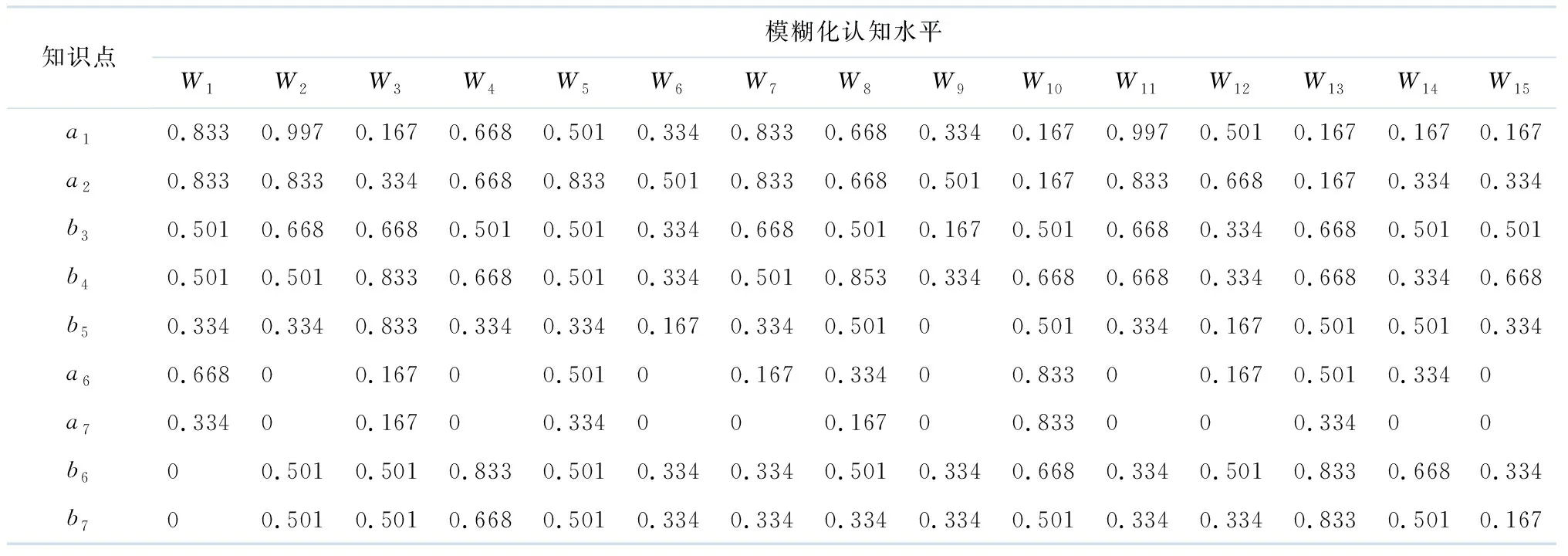
表4 知识网模糊化认知水平
同理计算出15个知识网的相似度,构建相似矩阵,具体如表5所示,显然相似度矩阵为对称矩阵.
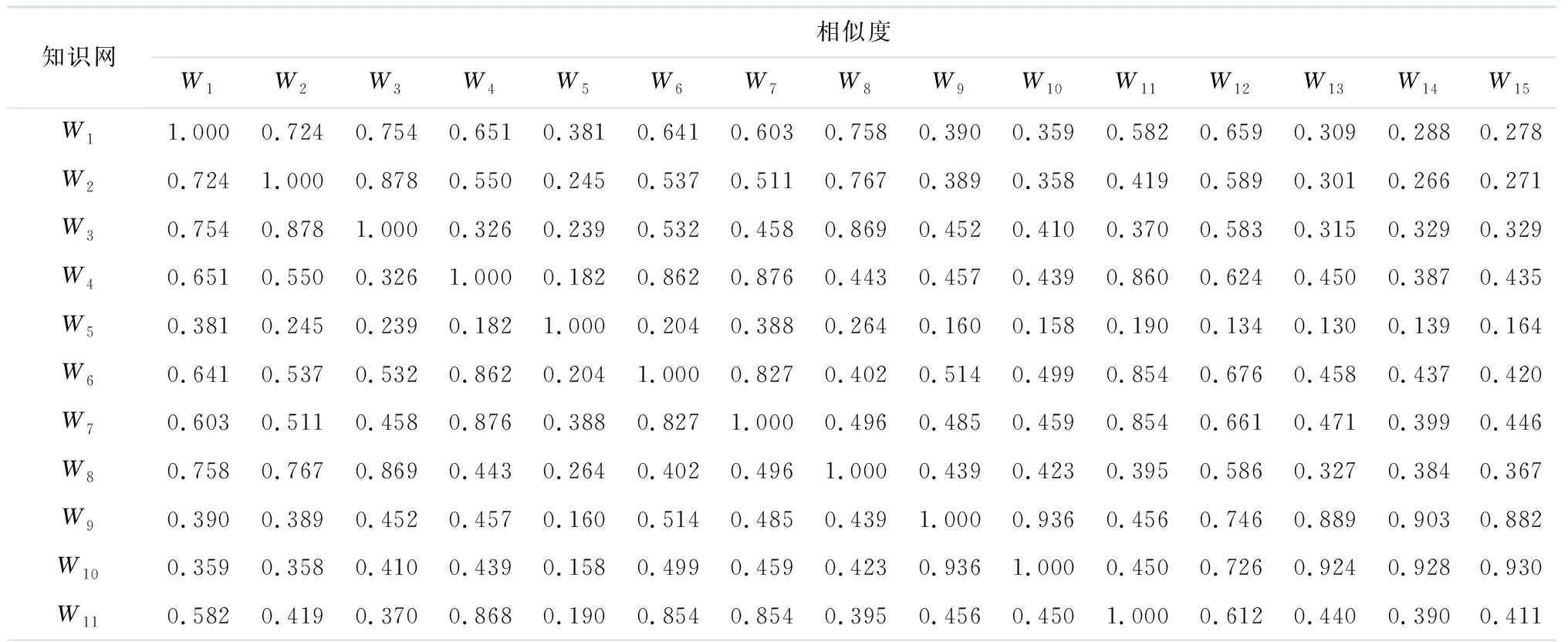
表5 知识网相似矩阵

续表
采用模糊C均值聚类(FCM)方法对知识网进行聚类,设置聚类数为3,模糊化因子为 2,迭代终止条件为隶属度最小变化量≤10-5.计算结果如表6所示.

表6 知识网隶属度
由表6可知:W2对聚类C1的隶属度最大,W3对C2的隶属度最大,W10对C3的隶属度最大,可以将W2、W3、W10对应的学习方法、学习知识点的次序推荐给学习者,并优先推荐W2.另外,可以将隶属度最大的知识网优化组合成一个新的知识网,即将W2、W3、W10组合形成一条新的学习路径推荐给学习者.
若学习者学习过一段时间,有属于自己的学习路径,此时可以根据学习者的学习路径组织成知识网,通过和其他知识网进行相似度匹配,选择匹配度最大的知识网作为学习者下一步学习的目标路径.
4 结 论
提出了一种基于模糊规则的知识网推荐方法,该方法将课程老师的教学经验和已学过该课程学习者的学习路径分别组成知识网,融合匹配度和认知水平来计算知识网的相似矩阵;采用模糊C均值聚类(FCM)方法对知识网进行聚类,将聚类隶属度最大的知识网推荐给学习者,或将各聚类属度最大的知识网优化组合成一个新的知识网推荐给学习者.学习者的学习风格也是学习者个性化的重要体现,下一步工作将综合考虑学习者的学习风格和认知水平等因素,对学习者学习资源和学习路径进行推荐,使推荐效果更符合学习者的个性化需求.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电脑知识与技术(2022年11期)2022-05-31
小猕猴智力画刊(2022年3期)2022-03-29
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
意林·少年版(2020年2期)2020-02-18
知识文库(2019年24期)2019-12-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
现代职业教育·职业培训(2019年6期)2019-10-09
电影(2018年9期)2018-10-10
