
一种医生推荐的爬虫设计程序
2022-03-11 12:30崔智博杨金灵李欣仪宋青桦闻柏智
电脑知识与技术 2022年1期
崔智博 杨金灵 李欣仪 宋青桦 闻柏智
摘要:网络信息复杂繁多与日俱增,人们越来越重视对数据的研究,为了有针对性地检测提取数据,一种全新的搜索引擎技术应运而生,最大限度上解决了网络信息冗杂难辨的问题,使信息更加简洁、有针对性。与早期的搜索引擎原理类似,该文采取春雨医生及患者作为实验样本,通过医患聊天对话框比率、医生职称的加权、综合数据整理分析得出医生的综合素质水平评分,为患者就医提供有价值的信息,对症就医,为患者精准对接医生提供了可靠的信息支持。
关键词:Python;网络爬虫;数据分析;数据可视化;热力图
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2022)01-0020-03
1 引言
随着对科技领域的深入研究,接收信息的科技手段不断创新,人们每天接收着海量信息,繁杂的信息与紧张的时间碰撞,由此,在短暂的时间内找到有价值的信息才能更好地利用信息为人们服务。通过采用爬虫、数据分析技术,将数据入库进行压缩过滤,进而通过数据可视化生成一个显而易见的热力图,再对各个科室的医生进行对比。此项技术可应用于多个行业,如企业发展趋势、社会舆情管控、市场基础调研等。由于Python的第三方库非常丰富,采用re、urllib、BeautifulSoup、Matplotlib等多方法库对数据进行爬取、分析。此技术适合解决处理数据提取分析问题,可在多个行业领域推广。
2 算法设计原理
本程序用Python作为开发语言,Pycharm作为开发工具,Excel用于保存数据,春雨医生作为爬取对象。
2.1 搜索引擎的原理
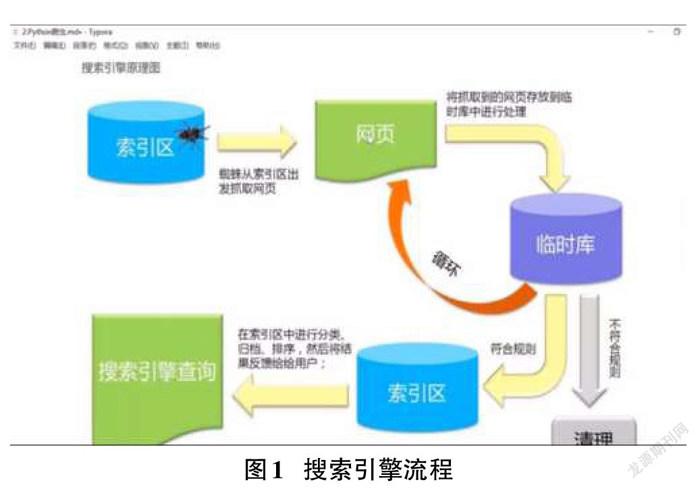
通过编写爬虫程序,获取到网页内容,把内容放入一个临时库进行处理,如数据的压缩、过滤等,经过处理的数据再存储到新的数据库里,把这些数据做出索引,每个索引对应常见的列表和内容,当用户想要输入关键字时,索引可以快速定位到数据库里的数据,提供给用户并形成一个界面,这就是搜索引擎的功能,每次搜索并不是让爬虫现在去爬一次,而是从爬虫爬好的数据里,去提取出来。该原理前半部分是爬虫,后半部分是数据可视化(图1)。
2.2爬虫
网络爬虫又叫作网络蜘蛛,它是一种按照特定规则,自动捕获网站信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略。网络爬虫并非一项新技术,可以说至少有二十年的历史。随着当下存储价格的波动、计算能力的提高、云计算的发展,其商业价值也会不断攀升,这就需要我们对爬虫技术加以创新优化,再加上互联网发展这么多年有很多数据的沉淀,所以在这个过程里面,爬虫现在可以被我们更多的人所使用,完成更多的特定行业的、特定需求的功能。爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
2.3数据可视化
随着移动终端的广泛普及,大家不仅仅希望把数据存起来,更希望数据能被人们理解,这些数据可能很抽象,专家才可能看懂里面的规律。为了更多的决策管理人员能更好地判断接下来要发生的事情,所以数据可视化的需求变得很广泛了。数据可视化有折线图、柱状图、饼状图、热力分布图等等,可以分析增长的速度、比例、地区的分布等等,用到了Flask(用于做网站)、Echarts(一个多种图表开源的框架)、Matplotlib(基于Python的图表绘图系统)。
3 算法设计
3.1准备工作
3.1.1网页基础信息介绍
需要用到HTML、CSS、JS的基础知识和URL分析,春雨医生网站包括600条医生信息,分30页,每页20条。每页的URL的不同之处是最后的数值page=page+1;借助F12来查看网页的源代码,在Elements下找到需要的数据位置。点击Network后,生成对这个网站发起请求的过程,小的线条为浏览器向服务器放送的请求。刷新该网页,只要下面的内容是我们想要的,就点击停止,日志将不再记录,再点击第一个请求,也就是从最左边数第一个线条,返回了请求的大小、规格等,最后点击该请求,生成了一个含有头部消息的页面,该页面含有请求的路径Request URL、请求的方式Request Method、状态码Status Code、移动端地址Remote Address、返回的头部Response Headers(我们发给服务器的头部信息,告诉服务器返回的内容,应该适配什么样的条件,而服务器给的信息在Response里)、用户代理User-Agent(获取浏览器信息,表明是什么版本的浏览器,并且可以接受什么样的浏览器)、cookie等。
3.1.2编码规范
1. # coding=utf-8 可以在代码中包含中文
2. # if__name__==“__main__”: 用于测试程序
3.1.3引入的库
from bs4 import BeautifulSoup #网页解析
import re #正則表达式
import urllib.request,urllib.error #制定URL
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
import matplotlib.pyplot #绘图
import seaborn #matplotilb的子类,分析热力图
import pandas #內置的一个类dataframe 建立二维矩阵
(第三方库在系统里没有需要引入, win键+r弹出运行窗口,输入cmd生成黑色框,再输入pip install +库名,即可完成下载安装。)
3.2 爬取数据
3.2.1 爬取方法
首先建立一个datalist数组,用于保存获取到的数据。由于春雨医生的每页都有规律,只需在网址后边改页数即可,利用for循环遍历所有网页,这里需注意索引值i是int型,需要强制类型转换为str,再调用askURL函数保存获取的源码。使用BeautifulSoup定位特定的标签位置(用到了html.parser解析器,在用soup.fill_all()按照一定的标准把想要的数据一次性查找出来,形成一个列表),最后使用正则表达式找到具体内容(由于找到的数据可能很多,第一个数据才是我们想要找到的,所以在方法后边加[0])。
3.2.2 urllib
Python一般使用urllib2库获取页面,对每一个页面,调用askURL函数获取页面内容,定义一个获取页面的函数askURL,传入一个url参数来表示网址,打开网页找到源代码里的Network中User-Agent,用键值对的方式保存在头部字典head里(模拟浏览器头部信息,向服务器发送消息),接下来用urllib2.Request生成请求,urllib2.urlopen发送请求获取响应,read获取页面内容,当然在访问页面经常会出现错误,为了程序正常运行,加入异常捕获try…except…语句。
def askURL(url): #获取html内容的函数
head = {
"user-agent": "Mozilla / 5.0(Windows NT 10.0;Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 88.0.4324.96 Safari / 537.36 Edg / 88.0.705.53"
#模拟登入
}
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
3.2.3正则表达式
正则表达式是对一种规格的描述或表达,描述的是一种字符串匹配的模式。简而言之,用具备一定特征意义的表达式对字符串进行检查,将符合条件的子字符串提取出来。获取html字符串后,对提取的数据进行特征提取,使用正则表达式语法进行编译,完成数据的提取。就不用将html字符串转换成html文档或页面,然后再用到xpath和bs4再进行提取了。
单字符:点(.)匹配某个字符串:match(表达式,匹配对象)只能匹配某个,从起始位置进行匹配并返回的结果是object; 若匹配不到,不会报错,返回None。点(.)匹配任意某个字符,\d匹配任意某个数字,\D除了数字外均可匹配,/s匹配空白字符。
多字符:星号(*)匹配零个或者多个字符,没有星号就从起始位置进行匹配,匹配到第一个;有星号从起始位置进行匹配,匹配[ ]内容零次或多次。问号(?)要么匹配0个,要么匹配1个。{m}匹配指定个数都是从起始位置匹配由左到右{m,n}匹配m到n个。
需要在函数外创建正则表达式对象,表示规则(字符串的模式),用到了re.compile()方法,注意字符串的表示用单引号,因为源码中会有双引号,这样不会对它造成影响,在字符串前面加r,就不会把字符串进行错误的解析了。其中获取的内容(.*?)点表示1个字符、星号表示0个或多个字符。
findName=re.compile(r'<span class="name">(.*?)</span>')
#定义正则表达式规则,爬取医生姓名
finGrade = re.compile(r'<span class="grade">(.*?)</span>')
#定义正则表达式规则,爬取医生级别
def getData(beseurl): #创建爬取解析数据函数
datalist=[] #爬取完把数据整合进datalist数组
for i in range(1,31):
url=beseurl+str(i)
html=askURL(url)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="doctor-info-item"):
# print(item)
data=[] #把單个医生信息保存在data数组里
item=str(item)
name = re.findall(findName,item)[0] #按规则选择第一个字符串赋值给name
data.append(name)
grade= re.findall(finGrade,item)[0]
data.append(grade)
datalist.append(data)
print(datalist)
return datalist
3.3 保存数据
保存形式多样,这里我们利用python库xlwt将抽取的数据datalist写入Excel表格。如果是保存在当前文件夹下“./加名字.xls” ,如果保存在文件系统里“.\\加名字.xls”,以utf-8编码创建一个Excel对象,创建一个Sheet表,再往单元格里写入内容,先写列名,再写元素,最后保存表格。
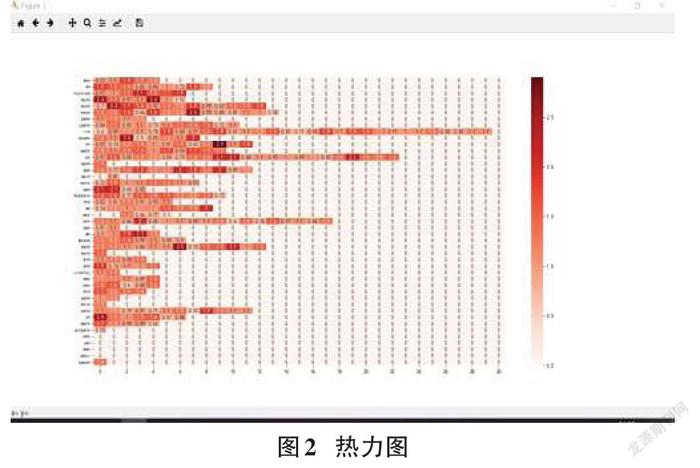
3.4热力图
热力图是数据视觉化的呈现,它最典型的是色彩传递信息,它可以以最直观的方式显示出医生的综合评分,以不同颜色的区域对医生评分进行标示,显示医生的姓名和评分,帮助患者快速找到合适的医生,提高问诊质量。
本文采用基于Python的绘图库matplotlib来实现热力图。
热力图的建立分为三步,第一步对数据预处理,爬取到的医患聊天的医生对话框数量和患者对话框数量之比,加上医生的级别(主任医师0.5,副主任医师0.3,普通医师和主治医师0.1)所得的分数为医生最后的评分。第二步为建立矩阵(横坐标为科室容纳的最大医生人数,纵坐标为各个科室,元素),第三步绘图(图2)。
4 结束语
爬取大量信息后对数据进行分析显然更适合网络信息时代对数据的处理,能够更好地实现信息共享,根据网民需要提供更有针对性的信息,使用该技术进行线上就医,符合国家“互联网+医疗”的发展政策,更大程度上节约了患者时间成本,不受时空限制,为患者提供医生准确专业的信息。不足点在于本次采集的医生数量较少,存在偶然性。此外,对医生推荐时,是单个患者进行推荐,时间成本较高。
参考文献:
[1] 何源.脑电波数据传输的服务器设计与实现[D].杭州:浙江工业大学,2017.
[2] 陈饶.面向电力行业的在线商业智能工具设计与实现[D].北京:北京邮电大学,2019.
[3] 孙景雪.基于机器学习的第三方追踪和反广告拦截检测系统[D].西安:西安电子科技大学,2019.
[4] 李敏.Edge浏览器安全风险与防御技术研究[D].北京:北京邮电大学,2018.
[5] 徐玉祥.基于动态自适应权重的个性化微博推荐系统研究[D].合肥:合肥工业大学,2017.
[6] 叶佳鑫,熊回香,蒋武轩.一种融合患者咨询文本与决策机理的医生推荐算法[J].数据分析与知识发现,2020,4(Z1):153-164.
【通联编辑:王力】
收稿日期:2021-04-06
作者简介:崔智博(2000—),男 ,辽宁沈阳人,大连外国语大学本科生,获得IBM颁发的高级软件工程师证书,2020年蓝桥杯大赛省赛一等奖+国赛优秀奖,2020年辽宁省大学生计算机系统与程序设计竞赛二等奖,2019年大学生创新创业项目“图书馆座位有效预留一体系统”(省级)成员,2021年大创“融合患者咨询文本的医生推荐算法研究”组长(正在进行),2021年大创“结合机器学习,缓解心理疾病患者病情急性发作问题” 组员(正在进行),主要研究方向为程序设计。
3414500589236
猜你喜欢
艺术与设计·理论(2016年4期)2017-01-16
中国新通信(2016年21期)2017-01-06
科技传播(2016年19期)2016-12-27
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
