
基于预训练⁃微调策略的COVID⁃19 预测模型
2022-03-12 05:55万旺根
计算机工程 2022年3期
杨 莉,万旺根
(1.上海大学 通信与信息工程学院,上海 200444;2.上海大学 智慧城市研究院,上海 200444)
0 概述
2019 年末,新型冠状病毒肺炎(COVID-19)由局部爆发逐渐演变为世界性大流行,截止到2020 年12 月23 日,COVID-19 已经造成全球超过7 800 万人感染,累计超过170 万人死亡。对确诊病例数的准确预测能够帮助决策者进行疫情预防控制措施和长/短期救治方案措施的制定[1-2],这种措施的制定对于疫情的有效控制具有重要意义。
研究人员提出了大量数学模型对COVID-19 的扩散和传播趋势进行建模和预测。目前主流的传染病模型主要可以分为3 类:第1 类是经典传染病传播模型,如SIR(易感者-患病者-康复者)[3-4]、SEIR(易感者-暴露者-患病者-康复者)[5-6]等;第2 类是基于深度学习的传染病传播模型;第3 类是其他模型,使用最广泛的是复合群体模型[7-8]。经典传染病模型在复杂多变的情况下(如政策和外部条件变化)需要手工分段设计以及参数估算,缺乏灵活性且效果不佳。复合群体模型对人群之间的迁移数据要求非常高,任何原始数据的缺陷都会导致模型预测误差变大,难以在大样本的场景下进行建模。因此,在复杂多变的环境下,基于深度学习的传染病传播模型逐渐成为研究热点。然而,目前在COVID-19 研究方面存在数据量严重不足的问题,现有的监督学习方法不能很好地适应低数据量的场景,模型预测精度较低。
冠状病毒在生物学特征上具有很大的相似性,有极为相似的病症表现、传染途径以及发展趋势,将这一特性作为建模因素,能够使预测模型提前学习到病毒相关特征信息,有效辅助确诊病例趋势预测。本文构造基于预训练-微调策略的COVID-19 预测模型P-GRU。在已有数据集上采用预训练策略,使模型提前接触到更多的疫情数据,从而获得更充分的先验知识。同时,将本地人为限制政策对疫情趋势的影响考虑到模型中,在目标地区数据集中实现精准预测。
1 相关工作
1.1 COVID-19 传播预测
在COVID-19 传播预测方面,经典传染病传播模型通过数学建模来预测COVID-19 传播的趋势,如SIR 传染病模型、改进的SEIR 模型等。虽然SIR模型及其变体可以略微捕捉到COVID-19 的传播流行规律,但在实践中仍然存在一定的问题。SIR 模型及其变体模型[9]在复杂多变的实际情况下缺乏灵活性,不能结合实际环境情况因素,如医院的收治能力、不同患者的传染率等,对于政策和外部情况的变化,模型需要手工分段设计和参数估算[10],并没有考虑很多外部因素对模型参数的影响,因此在预测结果上易出现较大偏差。复合群体模型考虑了人群的流动性对传染病传播的影响,适用于研究不同地区之间的病毒传播情况,如傅家旗等提出的P-SI 模型[7]结合人口流动变化对COVID-19 传播过程进行预测。虽然复合群体模型在一些场景下有着不错的效果,但是一般而言,复合群体模型对不同群体的迁移数据要求非常高,原始数据的细微缺陷都会导致模型预测产生很大误差。目前该研究更多局限在小样本的情况下,且未考虑潜伏期的影响,对于大样本等实际疫情复杂的情况,建模难度较大。
基于深度学习的预测模型通过多层非线性结构学习低维特征,形成更抽象的高维表示,具有强表达能力。CHIMMULA 等使用长短期记忆(Long and Short Term Memory,LSTM)网络预测加拿大疫情的结束日期[11],模型的短期精度为93.4%,长期精度为92.67%。ARORA 等使用LSTM 及其变体对印度的阳性病例数进行预测[12],该方法的日预报误差小于3%,周预报误差小于8%。虽然采用LSTM 能够较好地预测确诊人数的整体趋势,但LSTM 对某一参数的变化不敏感,如对于国家政策实施而导致某段时间内确诊人数激增的情况难以进行有效预测。此外,HUANG 等提出用卷积神经网络(Convolutional Neural Network,CNN)来分析和预测确诊病例的数量[13]。然而,上述深度学习方法均没有考虑到复杂多变的因素对疫情的影响。YANG 等考虑到部分外界因素对疫情的影响,结合社会经济特征,基于门控循环单元(Gated Recurrent Unit,GRU)研究美国的流行病数据和疫情时间序列,进而对未来疫情传播趋势进行预测[14]。但监督学习对数据量的要求较高,数据量不足会导致模型预测效果不佳。
1.2 预训练模型
预训练模型是业内为解决目标问题而构建的已训练好的模型。通过使用在其他问题上训练过的模型参数作为当前任务模型参数的起点,能够避免重新建立模型。在深度学习成为人工智能领域的主流方法后,预训练模型被成功应用于各类计算机领域任务,如图像分类、物体检测等[15]。在自然语言处理领域,近几年预训练模型发展迅速,在大部分自然语言处理子任务中均取得了较高水准,包括序列标注、分类任务、句子关系判断以及生成式任务[16]等。其中,预训练-微调策略具有很强的可扩展性,在支持一个新任务时,只需要利用该任务的少量标注数据进行微调即可有效完成当前任务。
在COVID-19 数据集中,当前任务数据量不足会导致预测模型效果不佳,而不同地区的数据特征较为相似,因此,本文考虑采用预训练-微调策略解决数据量不足这一问题。
2 P-GRU 预测模型
本文构建基于预训练-微调策略的COVID-19 预测模型P-GRU。通过预训练策略,在一定程度上解决数据量不足导致预测模型精度降低的问题,并为预测模型提供更丰富的初始化参数,从而使模型提前学习到COVID-19 的病毒本质规律,在新的数据集上进行微调后,针对确诊病例发展趋势具有较高的预测精度。
2.1 定义
2.2 预训练-微调策略
预训练-微调策略表示为:

其中:pretrain 作为一个函数,表示预训练策略;fine_tuning 也是一个函数,表示微调过程。在源地区数据集A 上经过预训练得到Modelpretrain,Modelpretrain在目标地区数据集B 上进行微调,得到最终模型Modelfinal,利用Modelfinal即可对目标地区的确诊病例数进行预测。
在预训练过程中,本文模型也考虑了本地人为限制政策对疫情趋势的影响。经过预训练后,保存训练好的预训练模型。利用在源地区中提前学习到的COVID-19 病毒本质规律,为后续的趋势预测提供一个更好的初始化参数,将训练好的模型和目标地区的疫情数据输入到GRU 预测模型中,并在目标地区中经过微调后得到最终模型,利用此模型进行预测即得到在目标地区中的确诊病例预测结果。预训练策略示意图如图1 所示。

图1 预训练-微调策略示意图Fig.1 Schematic diagram of pre-training and fine-tuning strategy
2.3 预测模型
通常利用回归学习任务来解决预测问题,本文的预测模型包含一个用于趋势预测的GRU 网络。GRU 网络通过适当地合并历史信息来处理序列数据,并且能够有效地简化结构,相比于LSTM 网络更加高效。本文预测模型架构如图2所示,主要由嵌入模块、递归模块和输出模块实现。

图2 P-GRU 预测模型架构Fig.2 Framework of prediction model P-GRU
预测模型有两类输入:一类是影响因素,另一类是流行病时间序列数据,如确诊病例数。影响因素通过嵌入模块作为GRU 的隐藏状态的初始状态,流行病时间序列数据通过GRU 的输入端输入模型,模型在时间序列上实现一个滑动窗口,使用带有最近历史信息的固定长度(L)序列来预测每个后续时间点。同时,为了使模型中的预测任务具备更好的合理性及可解释性,滑动窗口固定长度的设定与COVID-19的潜伏期相关。输出模块则输出预测值。另一个具有时变特征的输入特征是本地限制政策[17]。由于本地限制政策的限制,在不同因素下,疫情的演变是不同的,因此本文在模型中加入本地限制政策的影响因素,如果在滑动窗口的长度L内有人为政策的限制,那么在隐式特征中加入本地限制政策的特征位,以一种隐式的方式考虑本地限制政策对疫情演变的影响。上述过程可由式(3)~式(6)表示:

在式(3)中,Embedding 表示嵌入模块的实现,hid0表示递归模块的初始状态;在式(4)中,GRU 表示递归模块GRU 神经网络的实现;式(5)表示将静态特征与本地限制政策的动态特征进行连接;在式(6)中,y't+1表示模型输出的预测值,Wpredict表示最后一层输出全连接层权重。
3 实验与结果分析
3.1 实验设置
3.1.1 数据集
本文实验使用谷歌云平台数据集,包含与COVID-19 相关的每日时间序列数据,遍布全球20 000 个不同位置。实验采用的数据周期为2020 年1 月1 日—2020 年11 月26 日。实验中选取了印度和美国两个地区的数据,在印度地区数据集上进行预训练,在美国地区数据集上进行微调。作为输入的特征数据影响因素[18-20]包括静态特征数据和动态特征数据影响因素。静态特征数据影响因素包括当地人均GDP、人口统计数据、当地人的平均寿命等,动态特征数据影响因素包括COVID-19 病例数据(每日感染病例、累计感染病例、死亡数据)、政府干预政策数据等。同时,还有很多其他与疫情传播有关的因素[21]。
3.1.2 评价指标
模型预测性能评价指标使用平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和均方根误差(Root Mean Square Error,RMSE)。MAPE 将精确度量化为一个比率,并可以确定为每个时间帧比率的绝对误差百分比,即实际值减去预测值除以实际值;RMSE 则能够衡量观测值与真实值之间的偏差。MAPE 和RMSE 的计算公式分别如式(7)和式(8)所示:

3.1.3 对比模型
通过与当前主流模型进行比较,以客观充分地验证本文模型的有效性。实验选择CNN 模型、循环神经网络(Recurrent Neural Network,RNN)模型、LSTM 网络模型、GRU 模型和无预训练策略的P-GRU 模型(No-pretrain-P-GRU)作为对比模型。
1)CNN 模型使用权重共享的概念,其训练较为容易,且重要特征更能被有效提取[22]。1D CNN 可以用于时间序列分析,也可以用于分析具有固定长度周期的数据。当希望从整体数据集较短的片段中获得重要特征,且该特征在数据片段中的位置不具有高度相关性时,1D CNN 是非常有效的。
2)RNN 模型包含跨时间分布的隐藏状态,这使其能够处理可变长度的连续数据[23],因此在预测应用中最为常见,但RNN 的主要缺点是不能解决梯度消失或者梯度爆炸的问题,而且由于只涉及前一时间步[23]的隐藏激活功能,因此只能存储短期记忆。
3)对于预测任务,LSTM 被认为是最可行的解决方法之一,其可根据数据集中存在的各种突出特征来预测未来趋势变化。LSTM 是一种特殊的RNN,主要解决了长序列训练过程中的梯度消失和梯度爆炸的问题[24]。LSTM 模型能够将过去的隐藏状态传递到后续阶段中,相比于普通的RNN 模型,能够在长序列中获得更好的效果。
4)GRU 是循环神经网络中的一种,和LSTM 一样,也是为了解决长期记忆和反向传播中的梯度问题而提出的,LSTM 和GRU 都是通过各种门函数来将重要特征保留下来,这样就保证了信息在长期传播时也不会丢失[25]。而且,GRU 相对于LSTM 少了一个门函数,GRU 只剩下两个门,即更新门和重置门[26-27],重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。因此,GRU 的参数量少于LSTM,整体上GRU 训练速度快于LSTM。
3.1.4 参数设置
在印度数据集上预训练时:嵌入模块将4 维特定的静态特征稀疏编码为100 维度的向量;递归模块是使用单层的具有100 维隐藏状态的GRU 层,其采用嵌入层的嵌入结果作为第一个初始状态,将长度为7 的滑动窗口状态下的总确诊病例数以及每天的本地限制政策作为输入,若7 d 内有限制政策,则在隐式特征中加入标志位1,若在7 d 内没有本地限制政策,则在隐式特征中加入标志位0;输出层采用全连接层进行预测,通过最近7 d 携带的历史信息来预测后续时间点的病例数。实验使用Adam 优化器以1e-4 学习率训练模型,损失函数采用RMSE。
在美国地区数据集[28]上进行微调时,与印度数据集上预训练部分基本一致,但是递归模块初始状态的输入除了嵌入层的嵌入结果,还将印度数据集上的预训练模型结果也作为模型的一部分初始状态。
3.2 结果对比
分别利用CNN、RNN、LSTM、GRU、No-pretrain-P-GRU 以及P-GRU 这6 个模型对美国数据集进行预测,并分别比较RMSE 以及MAPE。确诊病例数归一化后的模型RMSE 以及MAPE 结果如表1 所示。可以看出,在所有模型中,本文模型的RMSE 和MAPE 最小,由此表明其相比于其他模型更适合用于预测COVID-19 传播趋势。
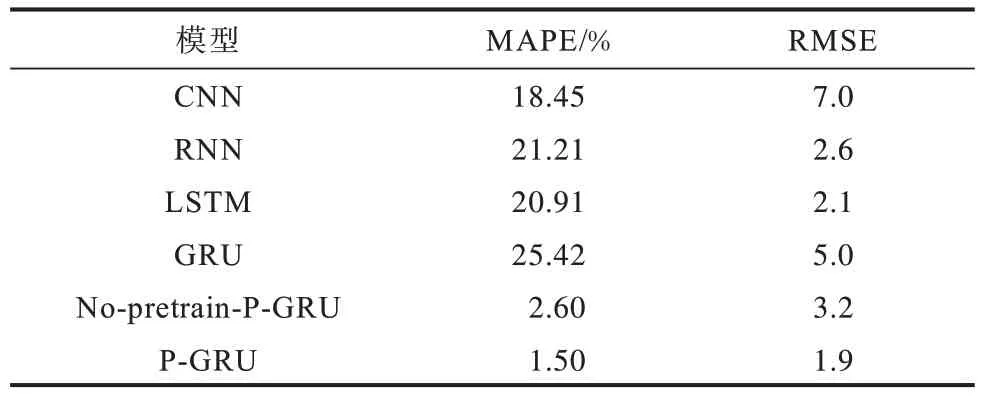
表1 不同模型的预测性能对比Table 1 Comparison of prediction performance between different models
4 结束语
本文提出一种结合预训练-微调策略的COVID-19预测模型P-GRU,并在美国地区数据集上与CNN、RNN 等模型进行均方根误差和平均绝对百分比的性能对比。实验结果表明,本文模型基于监督学习,能在一定程度上解决数据量少而导致的模型精度不足问题,有助于提高确诊病例趋势预测性能。对于变异新冠病毒的传播,也可采用本文提出的预训练-微调策略对疫情传播趋势进行预测。下一步将深入分析外生因素对COVID-19 传播的影响,并将其他与疫情传播相关的因素作为特征加入模型,如口罩的流行率、人们的防护意识等,进一步提升模型对于新冠肺炎的预测精度。
猜你喜欢
乐器(2021年1期)2021-09-10
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
作文评点报·低幼版(2020年25期)2020-07-23
环球时报(2020-06-05)2020-06-05
电子制作(2019年13期)2020-01-14
广西民族研究(2014年6期)2015-05-05
右江医学(2014年1期)2014-03-22
右江医学(2014年1期)2014-03-22
商场现代化(2009年16期)2009-06-22
