
基于认知诊断和神经网络的试题得分预测
2022-03-16 03:58史浩杰贾俊铖那幸仪
计算机技术与发展 2022年2期
史浩杰,李 幸,贾俊铖,匡 健,那幸仪
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.Momenta-初速度(苏州)科技有限公司,江苏 苏州 215100)
0 引 言
随着人工智能在教育领域的应用,智能教育也走向了大众的视野。智能教育是人工智能与传统教育的结合,可以帮助教师上课、批改作业等。在教学过程中,学生成绩是评价教学质量的重要依据。然而,目前大部分智能教育方案缺少对学生试题得分的预测,光靠人工去预测需要耗费大量精力,因此, 如何帮助老师和学生对试题得分进行预测是一个非常重要的问题。
现有的试题得分预测大多数采用神经网络,它在获得规范化的学生学习状况数据表后,对数据表中的各属性值进行正交编码,构建神经网络的训练数据集,基于该训练数据集进行神经网络的成绩预测模型的构建和训练,最后将待预测的学生数据进行数据转换、规范化、正交编码及归一化处理后,输入至训练好的成绩预测模型进行学业成绩分类预测,获得学生学业成绩预测结果并通过显示单元进行显示。然而,这种得分预测只能是对学生的一个总成绩进行预测,无法精确到每一题的得分。往往相同分数的学生具备不同的能力,学生要知道自己的问题必须要知道自己具体错在哪。
要想知道学生具体的错误,首先必须要知道考试中的试题类型是什么,因为有些学生会出现会求结果但是不会写过程的情况,这就很容易导致他们在客观题上得分还不错,但是在主观题上得分却不理想。通常大部分考试中题型一般是客观题和主观题按照一定比例组成,客观题只要结果正确即可获得全部分数,否则不得分;而主观题则是答对一个点即可获得相关分数,结果并不是判断是否得满分的唯一标准。因此,在对学生进行得分预测时,必须紧密结合试题的评分标准。
该文结合认知诊断和神经网络分别对客观题和主观题进行得分预测,主要以试题考察的知识点作为影响学生成绩的主要因素,并且结合主客观评分标准来进行得分预测。目的是能够让学生理解试题相对于自己的难易程度,从而选择合适的试题练习来提高自己的成绩。
1 相关工作介绍
1.1 认知诊断模型
IRT模型:IRT模型即项目反映理论(item response theory),通过被测试者在问卷调查上的作答情况对他们的特征进行分析,从而挖掘出他们的潜在特征。IRT模型最早应用在心理学中,在应用时需要建立以下假设:(1)单维性假设,即假设在本次测试中只测试心理问题,不测试其他问题;(2)立性假设,即假设患者作答每道测试题相互独立,作答情况只和患者的心理状态有关,不存在随便乱写的情况;(3)模型假设,即患者的答案与其心理状态具有一定的函数关系。使用IRT模型对患者进行心理评估时,常用的方法是极大似然估计,在已知测试题包含的心理参数时通过患者的作答情况计算出患者最大概率的心理状态。同样该模型可以应用在教育领域,在已知试题的相关参数(考察的知识点)下,结合学生的答题情况对学生在该参数上的表现进行诊断分析。
1.2 神经网络学习方式
神经网络常见的学习方式有监督学习和无监督学习。
有监督学习:有监督学习是指给定一组训练数据集,从中学习出一个能够处理非线性数据的模型,当模型训练完成后,输入新的测试数据,可以使用该模型输出预测结果。在监督学习中,训练集的要求是需要具有特征和结果两个参数,结果一般由相关领域专家进行标注。因此监督学习常用于解决分类问题,它通过训练集进行提取特征,然后对照结果训练出一个最优的学习模型,再利用该模型将测试集输入的特征映射为对应的输出结果,再对输出结果进行合理的判断就可以实现对目标的分类,也就具备了分类未知数据的能力。
无监督学习:无监督学习是指输入数据没有被标记,也没有确定的输出结果。因为往往会有一些数据由于缺乏经验很难进行人工标注或者人工标注的成本太大,在无法知道样本数据的类别时需要根据样本数据间的相似性对样本集进行分类,使类内差距最小,类间差距最大,也就是说无监督学习不是告诉计算机怎么去分类,而是让它自己去学习如何做分类这件事。当计算机分类正确时会采取一种激励的形式,而分类错误时会做出惩罚,因此无监督学习的目标不是训练出一个分类模型,而是对其分类行为是否做出最大回报的决定。
2 问题定义及知识准备
2.1 知识准备


表1 符号的定义及描述

续表1
2.2 问题定义
客观题主要分为选择题和填空题,客观题的分数只有满分和0分。因此,如果学生缺乏试题所涉及的知识点,通常得不到该试题的分数。只有掌握了该试题包含的所有知识点,才能正确地回答问题。此外,学生也可能会存在失误把会做的题目做错,也可能把不会做的题目猜对,这些因素必须考虑在内。
主观题的评分与客观题不一样,学生每答对一个点就可以获得相应的分数,学生如果掌握了一部分知识点就可以获得一些分数,并且主观题由于没有选项让学生选择,想要猜对几乎是不可能。因此,主观题的得分预测方法与客观题并不一致。
问题定义:(1)给定学生得分矩阵,试题知识点关联矩阵,如何对客观题进行准确的得分预测;(2)给定学生知识状态矩阵和得分矩阵,如何对主观题进行准确的得分预测。3 基于认知诊断客观题得分预测方法
为解决2.2小节中的第一个问题,提出一种基于认知诊断客观题得分预测方法O-CDM(objective question-cognitive diagnosis model)。下面将介绍该方法框架和具体做法。
3.1 O-CDM方法框架
首先输入学生得分矩阵和知识点关联矩阵,然后通过极大似然估计计算出每个学生最可能的知识状态,生成学生知识状态矩阵,最后在矩阵中找到该知识状态下对应的得分,预测出学生客观题的得分,方法框架如图1所示。
图1 O-CDM框架
3.2 O-CDM具体做法
(1)首先计算学生S
对试题P
的潜在反应向量,如式(1)所示。如果学生S
掌握试题P
中涉及的所有知识点,则潜在回答设置为1;如果学生S
缺少至少一个涉及的知识点,则潜在回答设置为0。
(1)
(2)用P
(α
|Y
)表示学生S
的知识状态α
为真的后验概率,如式(2)所示;R
是学生在α
状态下正确回答试题P
的期望值,如式(3)所示;I
是学生具有知识状态α
的期望值,如式(4)所示:
(2)

(3)

(4)


(5)

(6)

(7)

(8)


(9)
(5)重复步骤(3)和(4),直到β
中每个分量都收敛。(6)学生的知识状态X
可以通过最大化学生得分的后验概率获得,其定义如式(10)所示:
(10)
(7)在获得学生的知识状态后,在矩阵中找到学生在该状态下每道试题的得分,矩阵的计算方法如式(11)所示:=*(11)
4 基于卷积神经网络主观题得分预测方法
为解决2.2小节中的第二个问题,提出一种基于卷积神经网络主观题得分预测方法S-CNN(subjective question-convolutional neural network)。下面将介绍该方法框架和具体做法。
4.1 S-CNN方法框架
以学生的知识状态X
作为输入,学生的得分矩阵作为标签,使用Relu和Sigmoid作为激活函数,用卷积神经网络进行训练并且预测主观题得分,方法框架如图2所示。
图2 S-CNN框架
4.2 S-CNN具体做法
(1)该网络模型包括输入层、卷积层、隐藏层、池化层、全连接层和输出层,整个卷积神经网络流程如图3所示。

图3 卷积流程
(2)输入层包括学生知识状态矩阵=(X
,X
,…,X
),卷积层对输入矩阵执行卷积操作(d
个卷积核,卷积核大小为u
),得到隐藏层H
= (h
,h
,…,h
-+1),h
通过激活函数Relu计算,如式(12)所示:
(12)
其中,w
表示输入层神经元i
和隐藏层神经元j
之间的权重,b
表示隐藏层神经元j
的阈值。

(13)
(4)新的隐藏层H
通过一个全连接层和一个输出层,得到主观题的预测得分y
,y
由Sigmoid激活函数计算,如式(14)、(15)所示:
(14)
y
=Sigmoid(w
×f
+b
)(15)
其中,w
表示隐藏层神经元j
和全连接层神经元o
之间的权重,b
表示全连接层神经元o
的阈值,w
表示全连接层神经元o
和输出层神经元v
之间的权重,b
表示输出层神经元v
的阈值。5 实 验
5.1 数据集
此次数据来自中科大老师提供的某所高中的高二数学期末考试成绩(http://staff.ustc.edu.cn/~qiliuql/data/math2015.rar),一共有20道题,其中有14道选择题,6道主观题,这些试题考察了集合、不等式、三角函数、对数函数、平面向量、导数、函数图像、空间直角坐标系、抽象函数、推理与论证、计算这11个知识点(已经由相关领域专家标注)。该数据集包括两个子数据集:Math1子数据集包括所有学生在选择题上的得分以及每道选择题考察的知识点(选择题的失误率设为1.68%,猜对率为25%);Math2子数据集包括所有学生在主观题上的得分以及每道主观题考察的知识点。数据集的详细信息如表2所示。使用整个数据集的80%作为训练集,20%作为测试集。

表2 数据集信息
5.2 评价指标
在本次实验中,用得分预测的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1作为评价指标,计算公式分别如式(16)~式(19)所示:
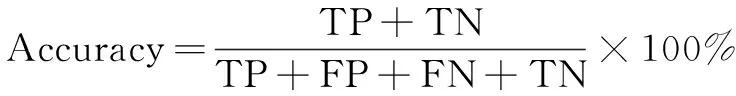
(16)

(17)

(18)

(19)
其中,TP表示正确预测学生答对试题的数量,FP表示错误预测学生答错试题的数量,FN表示错误预测学生答对试题的数量,TN表示正确预测学生答错试题的数量。
5.3 实验结果和分析
实验对比了项目反应理论模型(IRT)和协同过滤(kNN)两种试题得分预测的方法,实验结果如表3和表4所示。

表3 客观题对比结果 %

表4 主观题对比结果 %
通过实验结果可以发现,O-CDM与S-CNN方法分别在客观题和主观题得分预测上高于传统方法,因为O-CDM方法考虑到客观题存在的各种情况并且结合矩阵算法进行得分预测,而S-CNN方法能够利用卷积神经网络找到学生知识点掌握情况与试题得分之间的关联性,因此这两种方法在客观题与主观题得分预测上都具备独特的优势。
6 结束语
该文主要是根据试题的类型结合认知诊断和卷积神经网络进行得分预测,与之前的一些得分预测不同的在于考虑了平时考试试题的类型,分为客观题和主观题,预测的准确率也比较高,从而可以根据预测的得分让学生进行选择试题加强训练。但是由于题目的知识点只能用0和1表示掌握和未掌握,分析学生知识点状态也是只有掌握和未掌握,并不能表示学生掌握了多少,并且题目考察的知识点的难易程度还是没法得出。因此未来希望能够从学生知识点的掌握程度以及题目考察知识点难易程度出发,在预测出学生知识点的掌握程度后,从题目中挑选出更加合适的题目让学生进行查漏补缺,这将是一个比较难的挑战,希望能够突破,从而让教育更加完善。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小型微型计算机系统(2022年8期)2022-08-24
中学生数理化·高三版(2022年6期)2022-07-08
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
读与写·教育教学版(2017年10期)2017-11-10
中国新通信(2017年9期)2017-05-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
