
基于深度自编码器网络的压盖缺陷检测
2022-03-16 03:36张洪波隋文涛李长安逯海滨
计算机技术与发展 2022年2期
张洪波,隋文涛,袁 林,李长安,逯海滨
(山东理工大学 机械工程学院,山东 淄博 255000)
0 引 言
口服液是一种中药制剂,在国内得到了众多消费者的青睐,有巨大的消费市场。由于口服液产品在生产中设计多道工序,受生产工艺的影响,不可避免地会产生一些缺陷产品。如果这些缺陷产品在生产环节未能检测出来,不仅会影响产品质量,更有甚者会严重危害消费者身体健康,其中,压盖质量尤为重要。在口服液灌封过程中,药液灌入口服液瓶中,由压盖机自动贴合至瓶口,由于存在机械系统不稳定等因素,压盖过程会出现一定偏差,造成压盖不良等情况,瓶盖可能会出现划痕、刮花、表面卷曲、压盖破损等缺陷,因此需要将它们检测出来并剔除。现如今,口服液生产厂家使用的口服液瓶盖一般为铝塑撕开盖,整体分为两个部分,上部分为塑料材质的撕开盖,下部分为铝制的压盖部分。如图1所示,图(a)为正常压盖图像,图(b)为划痕缺陷,图(c)为压盖卷曲缺陷,图(d)为压盖破损缺陷,图(e)为压盖不良缺陷,图(f)为完全未压盖缺陷。

图1 缺陷示意图
最传统检测方法一般采用人工检测,但随着传统机器视觉检测方法的迅猛发展,很快被淘汰。因机器视觉检测具有成本低、效率高等优点而被广泛应用于口服液生产检测环节。近些年,一些国外、国内公司生产的灯检机大多也基于传统机器视觉检测。湖南大学刘学兵基于传统机器视觉检测方法,提出了一种基于水平截距投影的方法提取瓶盖下边缘点作为缺陷检测信息,并提出了边缘点均值和方差两种数据特征作为缺陷判断数据。虽然传统机器视觉检测虽说已经取得了不错的检测成果,但只能针对特定的一类产品,若企业更新包装则需重新编写特定程序。近几年,深度学习在计算机视觉、自然语言处理、语音识别等领域都取得了较好的成果,在缺陷检测领域,基于深度学习的检测方法也在迅猛发展,Allen Zhang等人使用深度学习网络在沥青表面自动进行像素级路面裂缝检测;CV Dung等人提出了基于深度学习技术的基于视觉的混凝土表面裂缝自动检测。这些深度学习检测方法虽然在检测方面很有效,但其都需要人工进行数据标注。在工业生产中,一是缺陷产生具有不确定性,二是缺陷产品相比于正常产品比例极低。因此,异常检测中的无监督检测逐渐受到关注。
Bergmann P提出了一种基于结构相似性与自编码器结合的无监督缺陷分割,用于织物缺陷检测,经验证该方法可以有效地检测织物缺陷;合肥工业大学罗月童等提出了一种卷积去噪自编码器检测芯片表面弱缺陷,实验验证了该方法在芯片表面弱缺陷检测中有良好效果。综上所述,深度学习在缺陷检测方面取得了良好的效果,但还未有基于无监督学习的检测方法应用在口服液瓶压盖质量检测中,另外口服液压盖缺陷具有缺陷与背景对比度低、缺陷较小等特点,又给传统检测方法带来了挑战。因此,该文设计一种无监督学习的深度卷积去噪自编码器网络模型用于口服液瓶压盖质量检测,为口服液压盖质量检测提出一种新思路、新方法。
1 方法概述
1.1 自动编码器原理
自编码器(Autoencoder,AE)是一种无监督学习方法。所谓无监督学习,就是不需要对目标提前标注的深度学习方式。自编码器是通过训练来达到重构数据自身的一种人工神经网络,即一种典型的输入等于输出的无监督神经网络模型。自编码器通常包含三个部分:编码器(Encoder)、隐藏层、解码器(Decoder)。在自编码器的训练过程中,输入经过编码这一过程后,编码器对输入数据进行编码压缩,并且将输入数据压缩映射为一特征向量,该特征向量虽然维度较低,但其包含着输入数据的隐藏特征信息,解码器会根据特征向量重构出输入数据,先编码再解码这一过程即可学习到输入数据的密集表征。在自编码器三个部分中,隐藏层是最重要的部分,因为数据的密集表征远比输入数据维度低,相当于用更少的特征去表达输入数据,这使得自编码器可以用于降维压缩,这在图像分类上有重要意义,其原理图如图2所示。

图2 自编码器原理图
编码过程就是编码器通过函数f
将原始输入数据x
=[x
,x
,…,x
]映射到隐含层h
,解码过程是解码器通过解码函数g
将隐含层作为输入,得到重构数据z
=[z
,z
,…,z
],其公式表达如下:h
=f
(W
x
+b
)(1)
z
=g
(W
h
+b
)(2)
式中,W
和b
分别是编码器的权重和偏置,W
和b
是解码器的权重和偏置。自编码器在训练过程中,使得重构数据与原始输入尽量逼近,从而表明隐含层学到了原始数据另外一种潜在的表达方式。因此,给定一个数据集x
=[x
,x
,…,x
],自编码器通过最小化以下函数来优化模型参数θ
:
(3)
其中,L
为重构函数,一般使用平方误差损失函数或者交叉熵损失函数。1.2 模型介绍
上文介绍了简单的自编码器的原理,该文使用卷积去噪自编码器进行口服液压盖质量检测。卷积去噪自编码器(convolutional denoising autoencoder,CDAE)中的去噪就是在自编码器的基础上,在编码器与解码器中使用卷积神经网络并人为添加噪声对输入数据进行训练。其中输入数据为x
=[x
,x
,…,x
],首先对输入数据引入噪声:
(4)


(5)
式中,L
为重构函数,通常情况下,一般为逐像素误差测量函数,如L
损失函数,其具体公式如下:
(6)
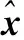
L
损失函数计算的是两幅图像之间的像素距离,其缺陷十分明显,当重建图像中,目标物体的边缘具有定位误差时,原始图像与重构图像之间的像素距离增大,计算两者之间的残差图时,会出现大量残差,但此时重构图像中目标物体结构特征与原始图像中目标物体相同。针对上述问题,该文提出使用基于结构相似性(structural similarity,SSIM)作为优化模型的损失函数。SSIM通过比较两幅图像之间的三个参数进行计算,包括:亮度(Luminance)、对比度(Contrast)和结构(Structure),三个参数计算公式如下:
(7)
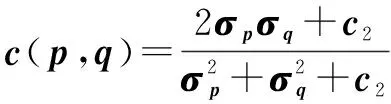
(8)
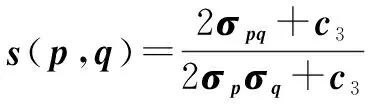
(9)
式中,p
和q
为两个大小为M
×N
的图像块,μ
为p
的均值,μ
为q
的均值,σ
为p
的方差,σ
为q
的方差,σ
为p
和q
的协方差,c
与c
为两个常数,避免公式作除零运算,一般取c
=c
/
2。每次计算的时候都从图片上取一个M
×N
的窗口,然后不断滑动窗口进行计算,最后取平均值作为全局的SSIM。SSIM(p
,q
)=[l
(p
,q
)·c
(p
,q
)·s
(p
,q
)](10)将α
,β
,γ
设置为1时,可得到:
(11)
SSIM通过考虑亮度、对比度和结构信息,而不是简单地比较单个像素值,相对于L
函数,在重建过程中对小的定位误差不太敏感,并且SSIM函数作为损失函数,检测出的缺陷表现在目标物体结构的变化,而不是像素强度之间的差异。卷积去噪自编码器结合了卷积神经网络中的卷积层池化层操作来进行特征提取,能够很好地保留图像的空间信息,又能够进行无监督式学习,训练速度更快。该文使用基于卷积神经网络(CNN)和多层感知器(MLP)组合的去噪自编码器码器,其结构如图3所示。

图3 模型结构
模型具体参数如下:
(1)输入为128×128×1像素单通道PNG格式灰度图像。
(2)编码器:包含4个卷积层、4个最大池化层和4个多层感知器。池化层统一为最大池化层,可以最大限度保留瓶盖上的缺陷。编码器具体结构见表1。

表1 编码器结构信息
(3)解码器:解码器与编码器的相反版本。包含4个多层感知器、4个上采样层和4个卷积层。4个卷积层中,卷积核Kernel都设为3×3。
(4)输出为128×128×1像素单通道PNG灰度图像。
在编码器与解码器中,除了解码器最后一层Conv4-Deconder使用Sigmoid作为激活函数,其余卷积层与MLP层皆使用Relu函数作为激活函数。另外在训练中,为防止过拟合,分别在编码器Conv2与Conv4后,以及解码器Conv1与Conv3后,增加Dropout层,其值设置为0.15。
模型超参数设置如表2所示,Epoch设置为250,Batch size设置为64。经多次试验发现,当优化器设置为Adam,学习率为0.002,每次参数更新后学习率衰减值设置为0.000 01时,训练效果最好。

表2 模型超参数信息
2 实验结果与分析
2.1 数据集及处理
2.1.1 实验数据集
本次实验在采集图像过程中,每个样品每旋转30°采集一张图像。如图4所示,总计采集5 700幅图片,其中4 700幅合格产品图片,1 000幅次品图片。后期给出了图片的样例,所提供测试的图片包含了常见的缺陷,如:划痕、刮花、表面卷曲、压盖破损等,测试图像为专业人员挑选,确保涵盖压盖过程中常见缺陷,具有代表性。如图4所示,前两行为合格产品,后两行为缺陷产品,从左往右依次为压盖不良、划痕、压盖破损、压盖卷曲缺陷。

图4 数据集图像
2.1.2 数据增强
使用数据增强从现有的数据集中生成更多的训练数据,包括随机水平翻转,在0~30范围内随机旋转,随机添加噪声、随机错切角度等,将数据集扩充到10 000幅图像,包括8 000幅合格产品图像,2 000幅缺陷图像。
2.1.3 图像预处理
该文采取常用图像预处理方式对数据集进行预处理,流程如图5所示。原始图像使用高速相机拍摄的产品照片,为1 600×1 200像素24位彩色图像,首先对其进行图像预处理。为了提高算法运算速度,将图片转化为灰度图,对图像进行高斯滤波,以消除图像采集过程中不可避免的噪声,然后经尺寸变换转换为像素值128×128×1的灰度图像。经检验,瓶盖图像在128×128×1像素时,图像不失真且能最大程度保留缺陷信息。
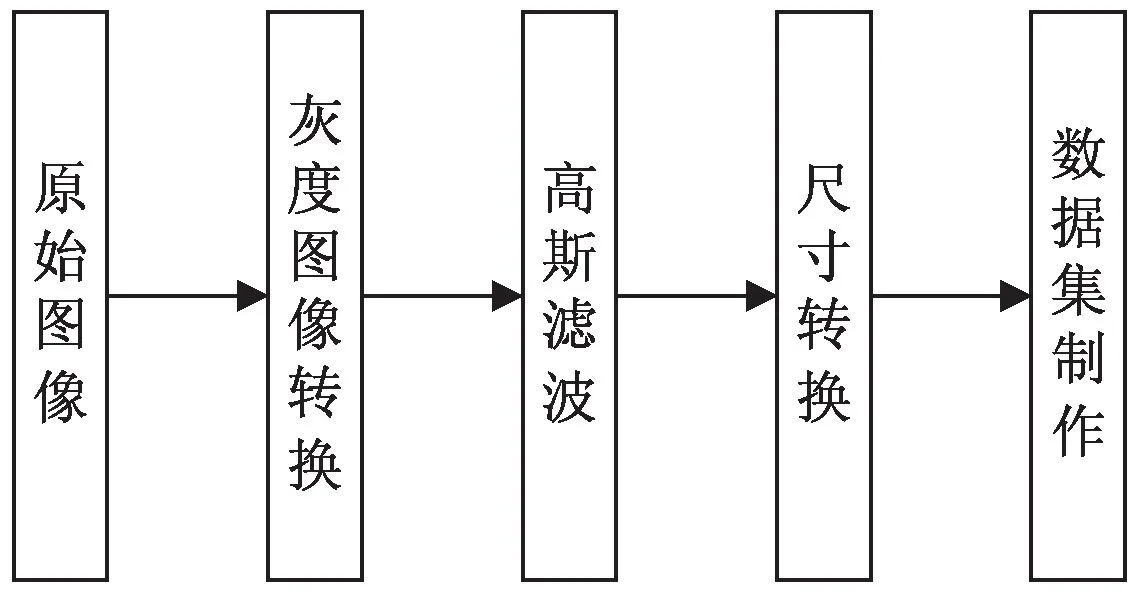
图5 图像预处理流程
2.1.4 网络训练
在网络训练阶段用于训练的图像全部为合格产品图像,在去噪自编码器中随机添加高斯噪声,并将输入的像素值部分随机设为零。经多次实验验证发现高斯噪音幅度为0.15时效果较好。添加对比试验组,使用标注后的数据集对卷积神经网络模型进行训练。
2.2 结果分析
2.2.1 损失函数对比试验
如表1介绍的去噪自编码器,该文在此分别使用SSIM函数及L
函数作为卷积去噪自编码器的优化模型损失函数,通过在数据集上进行性能比较,结果如图6所示。
图6 ROC曲线
图中展示了SSIM与L
的CDAE模型在压盖数据集上ROC曲线及其各自的AUC值,使用SSIM作为损失函数比使用L
作为损失函数的自编码器性能要好。仅通过改变损失函数,在压盖图像数据集上,实现的AUC从0.873提高到0.966。2.2.2 实验对比
本次实验采用VGG16卷积神经网络与卷积去噪自编码器CDAE进行对比实验。卷积神经网络与卷积去噪卷积自编码器在验证集上的准确率对比如图7所示。

图7 CDAE与VGG16准确率对比
在VGG16卷积神经网络进行训练时,在训练集中的表现为:30次迭代之前,正确率提升明显,在160次迭代时,准确率达到89.6%。在验证集中的表现为:在30次迭代附近,准确率迅速提高,随后趋于稳定。卷积去噪自编码器在训练集上的表现为:在30次迭代前,准确率提升较快,在120次迭代准确率达到95.2%,相较于卷积神经网络准确率提升5.6%,且收敛速度更快。
2.2.3 重构图像残差图
经卷积去噪自编码器重构的缺陷图片输出后已不包含缺陷,与输入图片相减,即可得到压盖缺陷残差图。如图8所示,第一列为输入图像,为压盖缺陷图像,第二列为残差图与输入图像叠加图像(标注区域为其对应缺陷区域),第三列为缺陷残差图。

图8 重构图像及残差图
3 结束语
针对口服液瓶盖压盖质量检测,该文提出了一种卷积去噪自编码方法代替卷积神经网络方法对压盖中产生的缺陷进行识别与定位,通过实验对比分析得出以下结论:
基于SSIM的卷积去噪自编码器网络在口服液小瓶压盖质量图像数据集上的准确率达到95.2%,相比于卷积神经网络提升了5.6个百分点,且收敛性更好。同时,卷积去噪自编码器模型可以应用在更多不同的领域,且鲁棒性更强,可以尝试将该方法应用在其他缺陷检测领域。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中国动物保健(2022年2期)2022-05-05
家庭科学·新健康(2019年10期)2019-11-18
现代信息科技(2019年18期)2019-09-10
发明与创新·中学生(2019年8期)2019-08-27
养生保健指南(2019年12期)2019-01-30
科技创新与应用(2017年26期)2017-09-12
科技与创新(2017年5期)2017-03-28
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
