
煤矿事故案例命名实体识别方法研究
2022-03-16 03:59潘理虎赵彭彭龚大立闫慧敏张英俊
计算机技术与发展 2022年2期
潘理虎,赵彭彭,龚大立,闫慧敏,张英俊
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024;2.精英数智科技股份有限公司,山西 太原 030006;3.中国科学院 地理科学与资源研究所,北京 100101)
0 引 言
煤炭是中国能源体系的主要组成部分,煤矿安全生产管理始终是经济社会安全稳定的重要工作。据统计,中国2004-2020年因煤矿事故导致的死亡人数达到了40 000,煤矿事故已经成为威胁煤矿安全生产的最大挑战。煤矿事故的预防是保障煤矿安全、稳定生产的重要手段。得益于知识图谱理论和技术的发展,煤矿事故的预防可通过整合多源、异构的煤矿事故案例信息,构建煤矿事故领域知识图谱,通过与现有的煤矿领域核心知识图谱融合,构建煤矿安全生产知识图谱,对煤矿事故、人员、设备、操作及环境进行智能化管理来实现。煤矿事故领域命名实体识别(named entity recognition,NER)是构建煤矿事故领域知识图谱的基础工作。
NER任务的目的是找出文本序列中特定标识符的开头和结尾,并将其进行分类,是自然语言处理的一项基本任务。基于规则的方法和基于统计机器学习是早期NER识别任务的常用方法。其中基于规则的方法依赖于人工构建规则库来解决特定领域的实体识别任务,费时费力且可移植性差,因此使用率越来越低,逐渐被基于统计机器学习的方法所替代;基于统计机器学习的方法出现了隐马尔可夫、条件随机场(conditional random field,CRF)、层叠马尔可夫及多层条件随机场等经典模型,这些模型面向海量的标注数据进行训练,最大程度摒弃了对于人工的依赖,取得了较高的准确率,但是存在泛化能力不强的缺点。近年来深度学习和图形处理器(graphics processing unit,GPU)的发展极大地促进了自然语言处理技术的升级,与基于规则和基于统计机器学习的方法相比,深度学习拥有速度更快、泛化能力更强的优点,因此神经网络模型成为解决命名实体识别任务的主流方法。由于循环神经网络(recurrent neural network,RNN)的线性结构与文本序列天然对齐,RNN在命名实体识别任务中应用广泛,双向长短时记忆网络(bi-direction short and long term memory networks,Bi-LSTM)作为RNN的变体,以其独特的门控结构解决了RNN的梯度消失和梯度爆炸问题,Bi-LSTM也成为了解决NER任务的典型代表。尽管基于RNN实体识别方法取得了不错的成绩,但是RNN的序列依赖结构决定其无法充分利用GPU的并行计算能力,导致模型的训练时间过长,造成计算资源的严重浪费。为了充分利用GPU资源,缩短训练时间,学者们将卷积神经网络(convolutional neural networks,CNN)应用于NER中。尽管CNN与RNN相比有明显的计算优势,但受限于卷积核的大小,CNN抽取长距离特征的能力弱于RNN。
目前,面向煤矿事故领域的命名实体识别工作存在以下难点:第一,没有煤矿事故领域的命名实体标注语料;第二,煤矿事故案例没有统一的书写规范,存在大量口语化表达;第三,相同实体表述不同,如“顶板冒落”、“片帮冒落”、“冒落”、“顶、边帮冒落坍塌事故”都是指同一事故类型,但是表述却不一致;第四,实体长度不一,识别难度较大;第五,煤矿事故案例文本涉及大量的专业词汇,如“煤与瓦斯突出事故”、“瓦斯爆炸”、“顶板垮塌”等。
针对以上问题,基于带有Dropout和自适应矩估计的迭代扩张卷积(iterative dilated convolution with dropout and adaptive moment estimation,IDCDA),该文给出了一种命名实体识别模型ALBERT-IDCDA-CRF,主要工作包括以下几个方面:(1)构建了煤矿事故领域实体标注语料CoalMineCorpus;(2)使用ALBERT预训练语言模型获取文本序列的字向量表示,提升原有字向量的表达能力,解决实体表述不一致的问题;(3)针对长实体问题,采用四个相同结构的迭代扩张卷积模块提升传统CNN的特征抽取抽取长距离特征的能力;(4)研究了结合Dropout和自适应矩估计(adaptive moment estimation,ADAM)的卷积神经网络优化算法解决过拟合问题。
1 煤矿事故领域标注语料集构建
1.1 煤矿事故领域语料集构建
煤矿事故案例主要包括时间、地名、煤矿名称、事故原因、事故类型、伤亡情况及救援过程等,是关于煤矿事故的重要数据。该文以从煤矿安全生产网、煤矿安全网、国家煤矿安全监察局等网站发布的煤矿事故案例作为原始数据,预处理后得到规范的煤矿事故案例数据集,以句末点号为标志对数据集进行句子级划分。针对煤矿事故领域实体边界模糊问题,结合煤矿领域专家的意见及实际应用需求对煤矿事故领域命名实体进行分类,在字级别对数据集进行标注,构建了包含时间、地名、煤矿名称、事故类型四类实体的语料集CoalMineCorpus。
1.2 煤矿事故领域实体分类及标注
使用DATE、LOC、ORG、ACC分别表示时间、地名、煤矿名称、事故类型四类实体,采用“BIO”标注体系进行实体标注,其中“B-”表示实体开始,“I-”表示实体的中间和结尾部分,“O”表示其他,所定义的标签集合如表1所示。
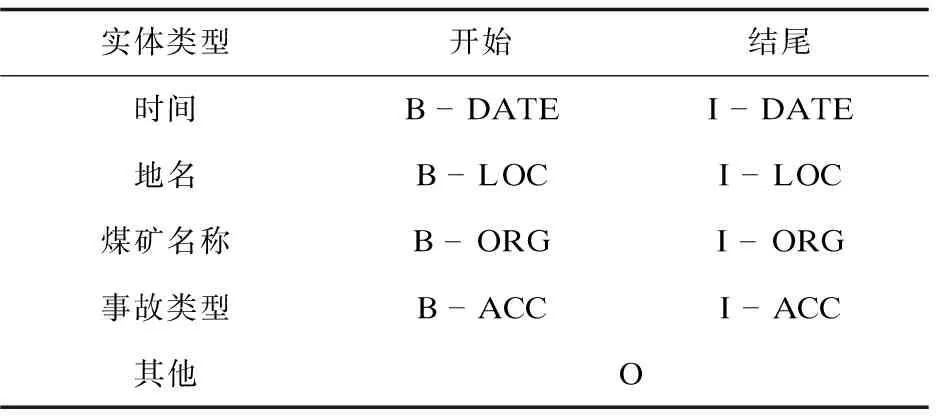
表1 实体标签集合
为了保证实体标注的准确性,该文使用支持多人同步进行标注工作和结果对比的YEDDA标注软件完成序列标注。在实体标注过程采用双人标注同一文档的方式,标注完成后对结果进行对比,避免实体标注不一致问题;其次标注完成后请煤矿领域专家对标注结果进行检查来避免实体标注错误。以“云南曲靖祠堂坡煤矿顶板冒落事故致5死2伤”为例,标注结果如表2所示。

表2 序列标注结果
1.3 CoalMineAccident标注语料集统计
应用1.2节的实体分类及标注方法对煤矿事故案例数据集进行处理,得到可用于煤矿事故领域的命名实体识别研究工作的煤矿事故领域标注语料集CoalMineCorpus,每类实体数目统计如表3所示。

表3 CoalMineCorpus语料集实体数目统计
2 命名实体识别模型
2.1 模型框架
ALBERT-IDCDA-CRF模型结构如图1所示,包括词嵌入层、CNN层和CRF层三个部分。模型的输入为字向量序列,因此需要把煤矿事故案例文本数据嵌入到向量空间,将字符转变为一定维度的字向量。该文使用ALBERT预训练语言模型融合文本序列的上下文语义信息,将得到的字向量序列输入CNN层,CNN层采用四个迭代扩张卷积(iterative dilated convolution,IDC)模块来完成特征抽取,将四个模块的结果叠加作为CNN层的输出,使用结合Dropout和ADAM优化器的卷积神经网络优化方法来解决神经网络的过拟合问题。最后使用条件随机场作为解码器,通过在数据集中学习标签的依赖关系,利用维特比算法进行推理,从而获得最佳的标签顺序,对最终结果进行修正。笔者将在以下各节对三部分内容进行详细介绍。

图1 ALBERT-IDCDA-CRF网络结构
2.2 词嵌入层
词嵌入层使用ALBERT预训练语言模型获取字向量表示,ALBERT为多层的双向Transformer结构,Transformer是一个仅使用注意力机制的机器翻译模型,由Encoder和Decoder两部分组成,ALBERT仅使用其Encoder部分,Encoder由六个相同的层堆叠组成,每层主体结构为多头注意力机制和全连接前馈网络两个子层。
多头注意力机制(multi-head attention mechanism)是ALBERT最重要的部分,可视为h
个独立注意力的拼接,如图2所示。
图2 多头注意力机制结构
首先利用公式(1)对Q
、K
、V
进行线性变换,重复h
次,其中Q
、K
、V
为字向量:
(1)
将h
个结果输入放缩点积注意力(scaled dot-product attention),利用公式(2)计算作为放缩点积注意力的结果:
(2)
最后将h
个结果利用公式(3)拼接后作为多头注意力的最终输出:
(3)
为了保证模型在提升训练效率的同时保持充足的文本表示能力,ALBERT采用嵌入层参数因式分解和跨层的参数共享策略来减少参数量,并且添加句间连贯(sentence ordering objectives,SOP)子任务,通过预测句子间的顺序来增强模型的理解能力。
2.3 CNN层
2.3.1 扩张卷积(dilated convolution,DC)
在自然语言处理中,CNN通常是一维的,通过卷积核在向量序列上的移动来完成卷积操作,实现特征的抽取。传统卷积神经网络如图3(a)所示,卷积核大小为3×3,感受野大小为3×3,提取长距离特征的方法为增大卷积核大小或加深网络层数。如堆叠3层图3(a)所示的CNN进行卷积操作,在步长为1的情况下,虽然感受野增大为7×7,但会使模型参数量变大,导致训练时间增加。扩张卷积执行相同的卷积操作时,通过设置不同的扩张率来扩大有效的输入宽度以增大感受野,从而卷积得到更多特征,捕获更多的上下文信息。图3(b)为扩张率为4的扩张卷积,感受野增大为15×15。由此可知,扩张卷积可以在不增加网络层数的同时实现感受野的扩散,从而缩短了训练时间。

(a)传统CNN (b)扩张率为4的扩张卷积
2.3.2 迭代扩张卷积(iterative dilated convolution,IDC)
简单堆叠多层图3(b)所示的扩张卷积可以有效整合序列的全局信息,但会造成局部信息的缺失,使卷积结果缺乏相关性,如图中灰色区域的特征并没有被提取到。而对于上下文关系紧密的NER任务而言,丢失一部分特征会对模型准确率产生很大影响。
该文采用四个如图4所示的迭代扩张卷积模块来避免丢失特征连续性,其中上一个迭代扩张卷积模块的输出是下一个模块的输入,最后将四次迭代的结果叠加作为最终的输出。每个模块由三层扩张率分别为1、1、2的扩张卷积组成,通过设置不同的扩张率来抽取多尺度上下文特征,前两层使用扩张率为1的扩张卷积来避免局部信息丢失,保证特征提取的准确性;最后一层将扩张率设置为2,使卷积核的感受野扩大为7×7,提升模型提取长距离特征的能力。

图4 扩张率分别为1、1、2的三层扩张卷积模块


(4)
将式(4)的结果输入网络进行迭代,可以得到第k
次迭代时第一次循环结束的结果:
(5)
第k
次迭代中第j
次循环结束的结果为:
(6)
定义堆叠函数Stacking(),叠加四次迭代结果,可以得到最终的卷积结果C
:
(7)
2.3.3 损失函数及网络优化
针对神经网络的过拟合问题,该文采用结合Dropout和ADAM优化器的卷积神经网络优化方法。在全连接层和输出层之间加入Dropout层,以概率P
随机选择一部分神经元,使其暂时停止工作,概率P
为:P
=(P
=1|x
)=
(8)
其中,P
=1表示样本a
生成1的概率值,B
表示所有i
类神经元中属于a
的数量。同时采用交叉熵损失函数衡量模型预测结果的好坏,公式为:
(9)

在训练阶段调整ADAM优化器的学习率对损失函数进行优化,通过最小化交叉熵来提升模型的性能。
2.4 CRF层
CNN层虽然可以有效整合煤矿事故案例文本的上下文信息,但不能考虑实体标签之间的先后顺序,如“B-LOC”只能出现在地点实体的开头,而不能出现在其他位置;而CRF可以在数据集中学习标签的依赖关系,利用维特比算法进行推理,对CNN层的输出结果进行修正,从而获得最优的标签序列。因此,该文选择CRF作为模型最终的输出层。
给定一条煤矿事故案例文本序列:W
=(w
,w
,…,w
),经过CRF可以得到一个预测标签序列:X
=(x
,x
,…,x
),定义其预测分数为:
(10)
其中,为标签由x
转移到x
+1的概率转移矩阵,N
为第i
个词语被标记为标签y
的概率。最后利用维特比算法即可得到当前文本序列W
的最优标签序列。y
=argmax(P
(W
,X
))(11)
3 实验设计及结果分析
3.1 实验语料及评价标准
该文采用自构的CoalMineCorpus语料集作为数据集,采用信息检索系统通用评价标准作为评价指标,即准确率(Precision,P
)、召回率(Recall,R
)和F测量度(F-measure,F
),概念公式如式(12)所示。
(12)
其中,n
为预测为真且正确预测的实体个数,M
为预测为真的实体个数,N
为标准结果中的实体个数。3.2 超参数设置
通过多组对比实验,分析了不同超参数设置对模型识别效果的影响,得到ALBERT-IDCDA-CRF模型最优的超参数,如表4所示。其中过滤器大小为3×3,字向量维度为100维,训练次数和Batch size设置为100、20。在训练过程中,将Dropout的概率值设置为0.5,测试阶段设置为1。

表4 ALBERT-IDCDA-CRF模型超参数
3.3 实验结果分析
3.3.1 实验1:不同学习率下ADAM优化器对ALBERT-IDCDA-CRF模型F值的影响
考虑到ADAM优化器的数学特性,若学习率过大或者过小都会导致交叉熵损失函数难以收敛,因此通过将学习率设置为0.02,0.03,…,0.09进行实验,不同学习率下ALBERT-IDCDA-CRF模型的F值变化如图5所示。

图5 ALBERT-IDCDA-CRF模型F值变化
观察图5可知,当学习率位于[0.02,0.05)时,模型的F值与学习率呈正相关关系;当学习率位于[0.05,0.07],F值趋于稳定;当学习率大于0.07,F值呈下降趋势。因此在后续实验中将学习率设置为0.05。
3.3.2 实验2:ALBERT-IDCDA-CRF在不同优化器下的性能对比
为了分析不同优化算法对模型识别性能的影响,分别采用随机梯度下降(stochastic gradient descent, SGD)、自适应梯度算法(Adagrad)、ADAM三种优化算法对ALBERT-IDCDA-CRF模型进行优化。实验结果如表5所示,可以发现当采用ADAM优化器时,模型的准确率、召回率和F值明显优于其他两种算法,因此后续实验采用ADAM优化器对模型进行优化。

表5 不同优化器下模型性能对比 %
3.3.3 实验3:ALBERT-IDCDA-CRF与其他模型的比较
由表6可知,在采用相同特征抽取模型的情况下,分别使用ALBERT和word2vec生成字向量,当使用ALBERT预训练语言模型生成词向量时,BILSTM-CRF的F值由76.64%提升到86.20%,IDCDA-CRF的F值由74.11%提升到90.65%,分别提高了9.56%和16.54%,说明使用双向Transformer结构的ALBERT预训练语言模型生成的字向量具有更好的文本表示能力,包含的语义信息更加丰富。同时ALBERT-IDCDA-CRF取得了最高的准确率、召回率和F值,和BILSTM-CRF和IDCDA-CRF相比F值提高14.01%、16.54%,比识别效果最好的ALBERT-BILSTM-CRF提高4.45%,可见该文所使用的迭代扩张卷积特征抽取能力最强,并且略优于经典的双向长短时记忆网络。

表6 不同模型性能对比 %
由图6不同模型训练时间对比结果可以看出,该文采用的方法解决了传统命名实体识别方法训练时间过长的问题,与BILSTM-CRF、IDCDA-CRF、ALBERT-BILSTM-CRF相比时间变化分别为-133 s,+148 s,-1 501 s(正为时间增加,负为时间减少),和ALBERT-BILSTM-CRF相比,训练时间缩短一半,和IDCDA-CRF相比,虽然训练时间有所增加,但P、R、F值却大幅提升。

图6 不同模型训练时间对比
上述对比分析结果表明,所采用的ALBERT-IDCDA-CRF神经网络模型在各项评价指标上有明显提高,训练时间也大幅缩短,是进行煤矿事故案例命名实体识别的最佳模型。
4 结束语
以自构的煤矿事故领域实体标注语料集CoalMineCorpus为研究对象,该文提出了面向煤矿事故案例的ALBERT-IDCDA-CRF命名实体识别模型。该模型词嵌入层通过使用轻量级预训练语言模型ALBERT来产生更高质量的词向量,提升命名实体识别的性能;CNN层使用四个迭代扩张卷积模块来提升CNN抽取长距离特征的能力和缩短模型的训练时间,采用结合Dropout和ADAM的优化算法解决模型的过拟合问题;最后采用CRF对标签序列进行约束,提升预测结果。通过多组对比实验,验证了ALBERT-IDCDA-CRF模型在煤矿事故领域命名实体识别任务中的有效性。
在未来的研究工作中,将进一步扩大语料集CoalMineCorpus的规模,将实体标注工作规范化,考虑采用融合字、词特征的词向量提升模型性能,抽取更多有应用价值的实体。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
中国新通信(2017年9期)2017-05-27
科学与财富(2016年30期)2017-03-31
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
