
一种改进的Kubernetes 弹性伸缩策略*
2022-03-17 10:17李洪赭李赛飞
计算机与数字工程 2022年2期
沐 磊 李洪赭 李赛飞
(西南交通大学信息科学与技术学院 成都 611756)
1 引言
随着虚拟化技术和云计算技术的快速发展,基于Hypervisor 传统虚拟化的云计算技术因为其较低的资源利用率等一系列问题,已经逐渐被以Docker[1]为代表的基于容器虚拟化的容器技术所代替[2]。相比于传统虚拟化技术,Docker 容器技术通过复用本地操作系统来提高启动速度,减少开销。同时因为Docker容器技术简化了应用的部署工作,受到广大开发者的欢迎[3]。然而在面对大规模集群的容器组时,对这些容器进行管理会显得非常困难。Kubernetes[4]是Google 的Borg[5]开源版本,Docker 容器集群编排调度系统,使用Master-Slave模型[6]为容器化应用提供资源调度、自动化部署、服务发现、弹性伸缩、资源监控等服务[7]。其中弹性伸缩是通过监测用户指定的评价指标,使用阈值的方式对应用进行水平扩容和缩容,以保障应用的服务质量和最大化地节省资源。
针对Kubernetes 的弹性伸缩技术的研究大致可以分为两类,第一类采用方法或者预测模型对未来资源的利用率进行估计或预测。文献[8]针对扩容和缩容时的不同特点,分别提出了快速扩容算法和逐步收缩算法,通过在工作负载增加时快速创建多个pod 和在工作负载降低时逐步缩容的方式保障应用的服务质量。文献[9]使用了基于动态参数的指数平滑法对资源利用率进行预测,通过预测式扩容和响应式扩容相结合的办法解决Kubernetes扩容时的响应延迟问题。这些处理方法虽然简单,但是在提高资源利用率和预测精度上仍有不足。第二类是针对Kubernetes 内置的弹性伸缩策略进行改进和优化。文献[10]提出了一种基于负载特征的弹性伸缩策略,该策略根据负载特征对应用进行分类,求出应用的整体负载并使用ARIMA 模型对负载进行预测,使用预测值和负载值共同作为判断伸缩的条件,以减少扩缩容时的伸缩抖动现象。该策略提出的根据负载特征衡量复合型应用负载的方法未考虑各种资源的重要性差异和资源极度不均衡情况下的服务质量问题。
综上所述,虽然目前针对Kubernetes 弹性伸缩策略中存在的问题的研究已经比较全面,但是仍有改善的空间。本文通过对Kubernetes 内置的伸缩策略进行分析,针对单一衡量指标和预测问题提出了一种改进的弹性伸缩策略。该策略给出综合负载率CLR(Comprehensive Load Rate)的计算方法,使用CLR 作为弹性伸缩的指标。同时使用ARIMA-Kalman 预测模型对资源进行预测,提高预测精度。
2 Kubernetes默认伸缩算法及分析
Pod 是Kubernetes 资源控制的基本单位。Kubernetes 通过HPA(Horizontal Pod Autoscaler)实现Pod的自动伸缩[11]。HPA 控制Kubernetes伸缩原理图如图1所示。
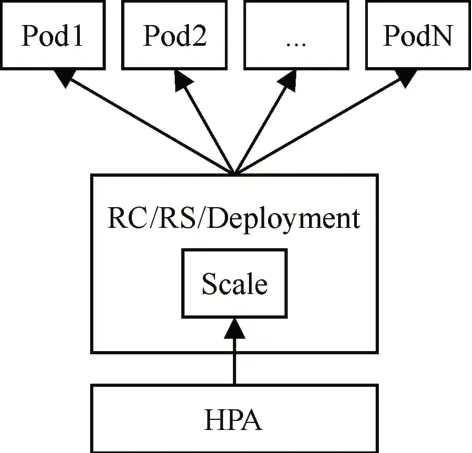
图1 Kubernetes扩缩容原理图
在部署应用时会设置某项资源监测指标和该资源的目标平均使用率阈值TAU。则该指标的伸缩阈值计算公式为
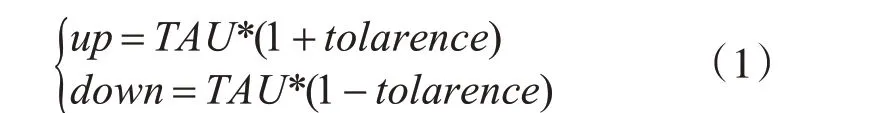
其中tolarence系统默认值为0.1,设置该参数是为了防止应用出现频繁地扩容和缩容。up和down分别是伸缩的上下限阈值。假设当前共有k个该应用的pod,HPA 通过轮询的方式获取当前该pod集合中所有的该资源使用量Ui,求得当前资源利用率和CAU为

其中request代表该pod 中资源的分配量。如果k*down≤CAU≤k*up,则不需要扩缩容,否则需要进行扩缩容操作,计算公式为

以上是Kubernetes 实现伸缩功能的流程概述。从上面的分析可以看出。虽然Kubernetes 内置的水平伸缩的算法比较简单,但是存在两个比较明显的问题:单一衡量指标和响应延时。在面对复杂应用系统时,应用涉及多种资源类型的消耗可能会随着时间和业务的变化而发生变化,单一衡量指标无法准确地衡量应用整体负载的情况。当应用面对突发的负载变化时,在pod 扩展之前的应用服务质量无法保障,甚至可能会发生应用因为负载太高而崩溃的现象。
3 本文伸缩策略优化
针对上文所说的单一衡量指标和响应延时问题,本文提出了一种改进的弹性伸缩策略。该策略通过监测记录pod 各个指标,计算出当前pod 的综合负载率CLR(Comprehensive load rate),将CLR 作为pod伸缩的衡量指标。同时使用ARIMA-Kalman模型对CLR进行预测,提前进行伸缩以保障服务质量。
3.1 衡量指标确定
影响应用服务质量的因素有许多,包括CPU、内存、网络、磁盘I/O 等多个基础指标。假设当前pod 节点涉及的资源种类为n,Ci表示节点上第i种资源的使用率Ci为

其中Ri表示节点上资源i的分配量,Ui表示pod 对资源i 使用量。记Cmax为各种资源利用率的最大值,为了减少计算的复杂度,当某项资源利用率低于下限阈值时,认为该资源的利用率对应用负载几乎没有影响,则该资源的利用率将不作为计算综合负载CLR 的参数。如果Cmax低于下限阈值,则令CLR=Cmax。如果Cmax高于上限阈值,则资源可以被认为是应用的性能瓶颈,为了保证服务质量,防止出现只有一种资源消耗非常高,其他资源利用率相对较低导致综合负载率没有达到扩容阈值的情况,同样令CLR=Cmax。由经验,设定下限阈值dl=0.4,上限阈值ul=0.95。
假设当前应用涉及的n种资源利用率中有k(k>0)个资源利用率满足dl<Ci<ul且Cmax<ul,则CLR为

根据以上公式,最终计算出当前pod 的CLR,该CLR 指标在简化计算复杂度和保证应用服务质量的前提下,全面反映出当前pod 节点整体负载水平。
3.2 ARIMA-Kalman负载预测模型
3.2.1 ARIMA预测模型
差分自回归平稳滑动平均模型(ARIMA)是时间序列预测方法,是博克斯和詹金斯提出的一种基于时间序列预测方法。该模型将非平稳时间序列转化为平稳时间序列,让因变量对其滞后值及随机误差项的现值和滞后值进行回归[12]。ARIMA(p,d,q)模型的数学表达式如下:
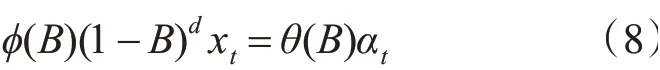
其中p为自回归阶数,d为差分次数,q为移动平均阶数。B为后移差分算子,xt为原序列,αt为均值为0,方差为δ2的正态白噪声序列。ϕ(B)和θ(B)计算方法如下:
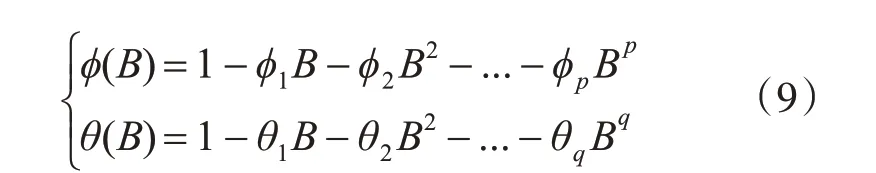
ϕ(B)为p阶AR 多项式,ϕi(i=1,2,…,p)为该多项式的待估系数;θ(B)为q阶MA 多项式。θj(j=1,2,…,q)为该多项式的待估系数。
ARIMA 模型的优点在于只需要有限的样本序列,就可以建立精度较高的预测模型。但是该模型存在低阶模型预测精度低,高阶模型参数估计难度大的缺点[13]。
3.2.2 Kalman滤波算法
Kalman 滤波是一种获取变量的最佳估计,将过去的测量估计误差合并到新的测量误差中来估计将来的误差,来对系统状态进行最优估计的算法[14]。其线性离散的Kalman滤波方程如下:

其中x̂k|k-1为从tk-1时刻对tk时刻的预测值;Kk为tk时刻的卡尔曼增益矩阵;Pk是tk时刻xk的状态估计协方差矩阵。
卡尔曼滤波算法采用递归的形式,不需要全部的数据,只需要根据tk时刻的测量值修正tk-1时刻的估计值,具有动态加权修正的特性[16],具有较好的预测精确度。但是Kalman 滤波算法需要状态方程和测量方程才能保证有很好的预测精度。
3.3 ARIMA-Kalman预测模型
针对以上对ARIMA 预测模型和Kalman 滤波模型的描述,可以看出这两种预测模型都存在不足。本文通过使用ARIMA-Kalman算法,将两种预测模型结合。利用ARIMA 模型建立低阶预测模型,将该低阶模型处理后计算Kalman 滤波模型的状态方程和测量方程,使用Kalman 迭代方程进行预测。
对于CLR 序列集合X(t) ,令x1(t)=x(t) ,x2(t)=x(t-1) ,… ,xp(t)=x(t-p+1);α1(t)=α(t) ,α2(t)=α1(t-1) ,…,αq(t)=αq-1(t-1) 。则ARIMA预测模型如下:

该组合算法的具体步骤如下所示。
1)数据采集
利用工具对各个指标进行采集并处理,按照上文中综合指标CLR计算方法对数据进行计算,得出时间序列X(t)。
2)平稳化处理
为了保证数据的平稳化,对采集到的数据信息利用平稳性检验方法ADF 检验进行判断。如果是非平稳数据,通过差分进行平稳化处理至ADF 检验满足要求。
3)ARIMA模型参数确定
ARIMA(p,d,q)预测模型中,d代表在数据平稳化的处理过程中差分的次数。p和q确定的方法有多种,本文中使用固定步长,遍历求出最小AIC 信息准则时p和q的值,从而确定ARIMA 模型的参数。
4)Kalman滤波模型预测
根据ARIMA 建模求得AR 模型和MA 模型的待估系数,确定Kalman 系统的状态方程和测量方程。利用式(12)~(16)递推求出系统最新估计值。
4 实验
4.1 实验环境
为了验证本文提出的改进的弹性伸缩策略,搭建了两个相同的Kubernetes 集群环境,Kubernetes的版本都是1.16.2,每个集群包含一个Master 节点和两个Slave节点。其中一个集群使用内置的弹性伸缩方法,另一个集群使用本文提出的弹性伸缩策略。集群的详细配置如表1所示。

表1 实验环境配置
4.2 实验数据
本文的实验数据使用2018 年阿里巴巴公开的生产环境采集的部分容器资源使用率信息。该数据包括CPU 利用率、内存使用率,网络以及磁盘IO等多个维度的资源使用情况。由于该数据集数据量庞大,本文选取出同时使用两种及两种以上维度的资源维度的容器数据作为算法计算的基础数据。由于该公开的数据采样的时间间隔不相等,去除时间间隔较近的点并对个别时间间隔较长的数据中间使用均值补差进行补充,使时间间隔大致相等。
4.3 实验步骤及结果分析
本文提出的改进的Kubernetes 的伸缩策略需要从功能性和准确性两个方面进行实验验证。所以实验应该包含两个部分:1)使用JMeter 工具对Kubernetes 的pod 进行压力测试,分别记录两个集群的pod 的数量变化情况并进行对比。验证本文的伸缩策略在应对负载变化时的预测伸缩效果。2)使用公开容器负载信息,计算出CLR序列。分别使用指数平滑法,ARIMA 预测模型和ARIMA-Kalman 预测模型进行预测并对这三种预测模型的预测精度进行评估。
首先在两个实验环境中分别部署一个相同的Web 应用,伸缩阈值设置为60%,容忍度设置为默认的0.1。利用JMeter 工具进行模拟并发访问请求,每隔1min增加并发请求数量并检查当前pod的数量。其中使用本文伸缩策略的实验环境使用Prometheus获取pod的资源信息并计算CLR进行预测。具体数量变化情况如图2所示。
从图2 中可以看出,相比内置的伸缩策略方法,本文使用的方法可以提前针对负载的变化趋势进行预测式的弹性伸缩,从而解决Kubernetes 内置的伸缩策略的响应延迟问题,保障了服务的质量。
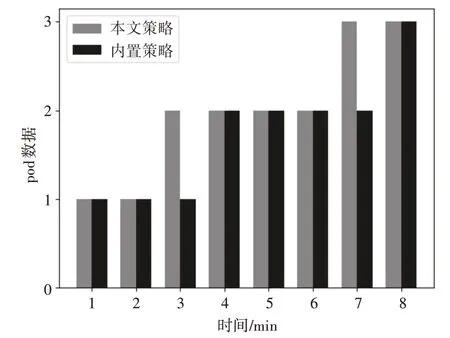
图2 pod数量变化图
为了比较本文使用的ARIMA-Kalman 预测模型和其他模型的精度,使用阿里巴巴的生产环境容器公开数据集的负载信息数据作为基础数据。简单处理后计算出CLR,将CLR 作为模型预测的输入。分别使用绝对误差(MAE)、平均绝对误差(MSE)、平均绝对均方误差(MSRE)这三种最常见的衡量指标对文献[5]中使用的指数平滑法以及文献[6]使用的ARIMA 预测模型和本文使用的ARIMA-Kalman预测模型进行评估。
每个容器的处理后的采样数据约为650~800个,统一选取前550 个信息节点作为训练数据,后100 个数据作为预测。指数平滑法,ARIMA 预测模型和ARIMA-Kalman 的预测误差图已经分别如图3所示。
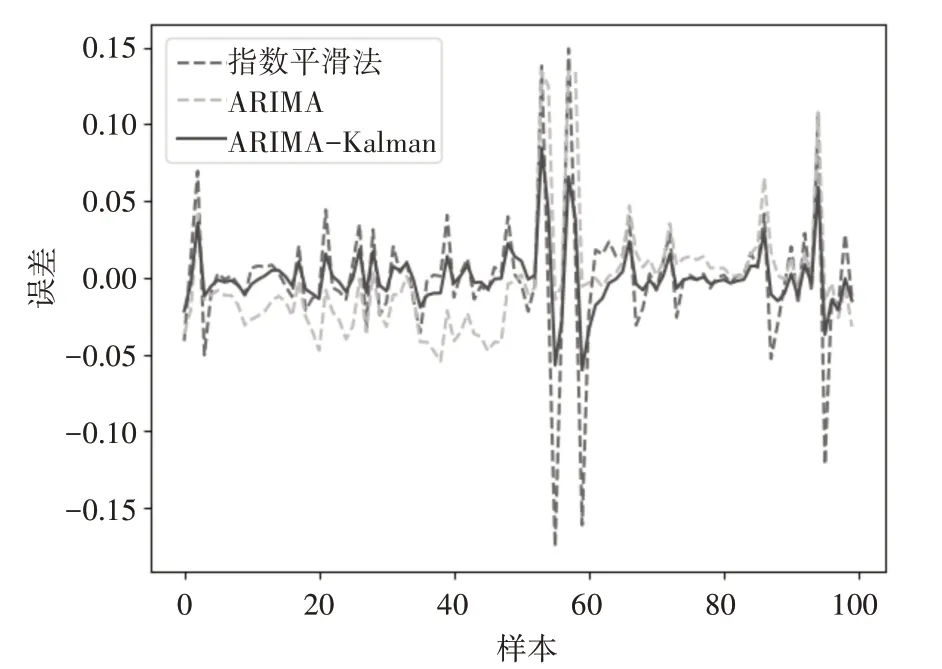
图3 模型预测误差比较图
由图3 可以直观看出,ARIMA-Kalman 的误差相对其他两种方法更小。由于ARIMA 模型的参数确定过程计算量较大,不适合对数据模型进行动态更新,只适合做短期预测,本文一次性预测100 个数据点,所以整体误差较大。指数平滑法由于使用了所有历史节点的信息,在使用中会消耗更多的内存资源,而且没有考虑到数据变化的规律性。ARIMA-Kalman模型通过建立低阶的ARIMA模型确定状态转移方程,使用Kalman 模型进行更新迭代预估,其精确度相比ARIMA 和指数平滑法较大的提升。表2是对这三种模型的评估。
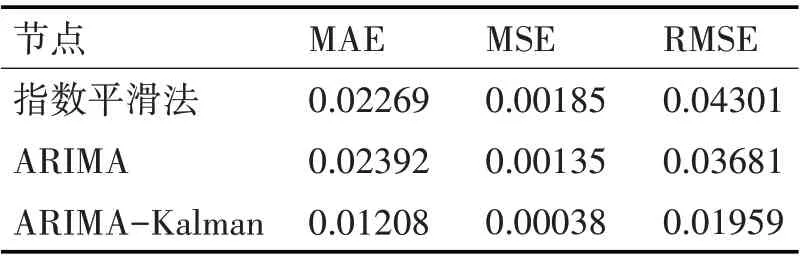
表2 各模型评价指标对比
可以看出,相比于指数平滑法、ARIMA 模型,本文所使用的ARIMA-Kalman 预测模型的预测精度更优。在面对负载变化的情况,能够准确地进行预测。
5 结语
本文针对Kubernetes 内置的弹性伸缩机制的单一衡量指标和响应延迟的问题,提出了一种改进的弹性伸缩策略。该策略通过定义统一负载评价指标CLR,有效衡量出复杂应用的整体负载水平。同时通过上下限阈值的设置,简化了计算的复杂度并且保证了服务的质量。使用ARIMA-Kalman 预测模型对应用当前CLR进行预测,提前伸缩以保证服务质量。实验证明,该预测模型相比于指数平滑法和ARIMA预测模型具有更高的精度。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
建材发展导向(2021年19期)2021-12-06
军事文摘·科学少年(2021年9期)2021-10-13
科技研究·理论版(2021年20期)2021-04-20
智能制造(2020年11期)2020-02-08
妇女生活(2018年7期)2018-07-14
智富时代(2018年1期)2018-03-26
智富时代(2018年1期)2018-03-26
环球时报(2017-06-27)2017-06-27
中国化妆品(2017年12期)2017-06-27
