
基于生成对抗网络的色织物缺陷检测
2022-03-17 11:31张宏伟糜红敏
西安工程大学学报 2022年1期
张宏伟,糜红敏,陆 帅,陈 霞
(1.西安工程大学 电子信息学院,陕西 西安 710048;2.浙江大学 工业控制技术国家重点实验室,浙江 杭州 310027;3.北京理工大学 医工融合研究院,北京 100081;4.西安美术学院 服装系,陕西 西安 710065)
0 引 言
在纺织品生产过程中,由于机械、纱线和加工等问题,织物表面可能会产生各种各样的缺陷。据统计,缺陷会导致织物的价格下降45%~65%[1]。因此,织物缺陷检测是纺织品质量控制的重要环节。传统的人工目测受限于人的主观影响、视觉疲劳等因素,准确率只有60%~75%[2]。随着机器视觉与图像处理技术的飞速发展,许多研究人员将其应用于纺织品缺陷检测中[3]。目前,传统基于机器视觉的织物缺陷自动检测算法主要分为频谱法、统计法、模型法等。频谱法包括傅里叶变换[4]、小波变换[5]、Gabor变换[6]等;统计法有自相关函数[7]、直方图统计[8]、形态学[9]等;模型法主要有马尔可夫随机场[10]、自回归模型[11]等。对于背景纹理简单的色织物,上述方法通过构造特征工程能够达到比较理想的检测结果。然而,难以实现花型复杂且小批量生产的色织物缺陷检测。
深度学习[12]是近年来计算机领域一个热门研究方向,已被广泛应用于人脸识别[13]、语音识别[14]、图像识别[15]、运动目标跟踪与检测[16]等方面。由于深度学习的方法能够自动学习图像深层次的特征[17],因此可以解决难以人工设计色织物特征的问题。按输入数据是否带有标签信息,深度学习可分为有监督学习与无监督学习。在有监督的织物缺陷检测算法中,JING等先后提出了基于卷积匹配双字典的网络模型结构[18]和基于深度卷积神经网络的织物疵点自动检测方法[19],实现了高准确率的缺陷检测。但上述方法训练阶段均需要大量带有标记信息的缺陷数据,而实际生产过程中很难获得大量缺陷数据,因此有监督的深度学习在对小批量的色织物缺陷检测时存在一定的局限性。
基于无监督学习的织物缺陷检测算法已有部分研究者进行了尝试,其关键点在于能否有效提取织物图像的纹理特征,从而将有缺陷样本图像有效重构为无缺陷的图片。MEI等[20]提出一种基于多尺度卷积去噪自编码(multiscale convolutional denoising autoencoder,MSCDAE)网络模型,该模型结合图像金字塔层次结构思想和卷积去噪自编码网络,对织物图像缺陷进行检测,但对于纹理复杂的色织物,该方法则容易出现过检现象。张宏伟等先后提出了基于无监督去噪卷积自编码器(denoising convolutional autoencoder,DCAE)的色织物缺陷检测算法[21]和U型卷积去噪自编码器(U-shape denoising convolutional autoencoder,UDCAE)模型[22],通过对待测图像与其重构图像的残差图像进行处理,实现色织物缺陷的检测及定位。但该方法只适用于背景纹理较为简单的色织物。为此,本文提出一种基于GAN的无监督色织物缺陷检测算法,使用无缺陷样本训练模型,将待检测图像经模型重构与图像后处理等操作,实现最终的检测目的。
1 模型的构建
1.1 模型构建
GAN是由Ian Goodfellow等于2014年提出的一种无监督深度学习模型,核心思想是二人零和博弈[23]。模型主要由生成器G和判别器D构成,如图1所示。生成器通过真实数据的潜在分布生成新的数据样本,判别器则不断区分生成的样本和真实数据。
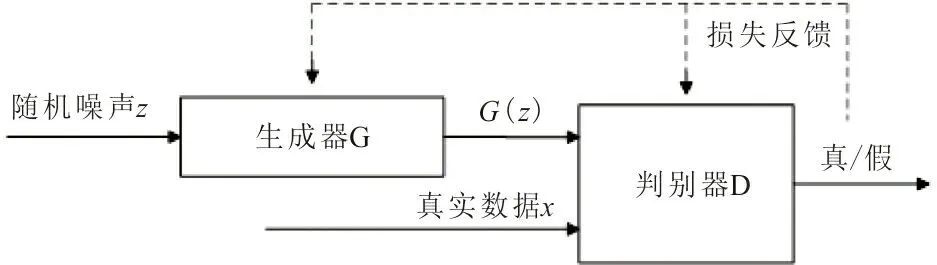
图 1 GAN的基本结构Fig.1 The structure of GAN
生成器G的输入为随机噪声z,例如高斯噪声,通过该噪声生成图片,记为G(z)。判别器D的输入为真实图片x和生成图片G(z),输出D(G(z))表示生成图片G(z)与真实图片相似的概率。如果输出为1,代表生成图片100%接近真实图片;如果输出为0,则表示生成图片不可能是真实图片。训练过程的目标函数为
Ez~Pz(z)[lg(1-D(G(z)))]
(1)
式中:V(G,D)为损失函数;Pdata(x)为真实数据分布;Pz(z)为随机噪声分布;E为数学期望;D(x)为真实数据经判别器后的输出;D(G(z))为生成的图片经判别器后的输出。
1.2 基于GAN的图像重构模型
本文构建的基于GAN图像重构模型主要包含生成器和判别器2部分。与原始GAN网络的输入相比,所构造模型的输入为加入高斯噪声后的图片,而不是随机噪声向量,因此需要对生成器做相应的改进。
为了使生成器G能够有效地重构输入的图片,构造的生成器模型依次由编码器、残差块、解码器构成,使得模型的输出与输入成为相对应的图片,模型结构如表1所示,其中表身单元格中的空白处表示“不适用”。

表 1 生成器(G)网络结构
编码器对输入的图片通过卷积操作不断进行尺寸压缩与特征提取,以获取图像中最主要的特征信息。首先利用卷积核大小为7×7的卷积层来增大感受野,然后依次使用4层卷积核大小为3×3的卷积层进行特征提取,激活函数采用修正线性单元(rectified linear unite,ReLU)。解码器部分则是利用反卷积操作将提取到的特征信息进行恢复。与编码器不同的是,解码器的最后一层使用的激活函数为tanh。此外,在编码器与解码器之间加入了9个残差神经网络(residual neural netnork,ResNet)[24],文中每个残差网络的结构如表2所示。残差网络采用了跳接结构,可以在很大程度上加快网络的收敛速度,同时还能提高网络的特征提取能力。

表 2 ResNet结构
判别器的作用是判断重构图像与真实图像之间的差距,并将判断的结果反馈给生成器G与判别器D,从而指导模型进行对抗训练。判别器D的网络结构如表3所示,从上往下依次为6个卷积层,卷积核大小为4×4,激活函数采用的是LeakeyReLU。然后经3层全连接层并通过Sigmoid激活函数输出最终的判别结果。
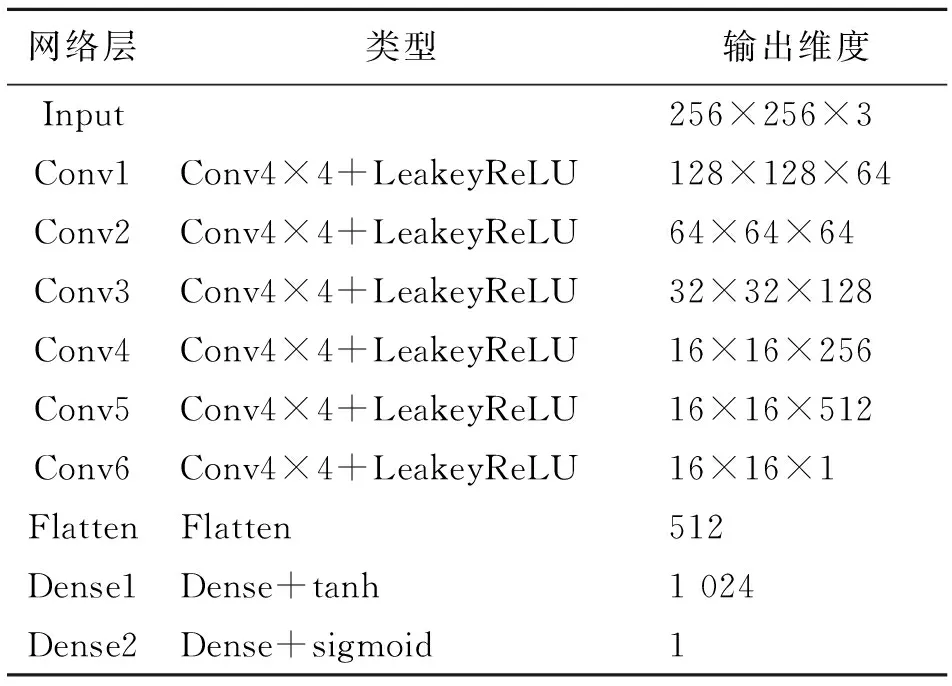
表 3 判别器(D)网络结构
模型训练时使用的损失函数由内容损失与对抗损失共同组成,内容损失用来约束生成的图像,对抗损失用来判断生成的图像与真实图像。内容损失采用L1损失函数,对抗损失采用WGAN-GP[25]损失,定义分别如式(2)、(3)所示,总损失函数如式(4)所示:
(2)
(3)
Lt=λL1+Ladv
(4)

1.3 模型训练
模型训练阶段的示意图如图2所示。模型训练具体过程如下:

图 2 GAN模型训练阶段Fig.2 Training stage diagram of GAN model
1.4 基于GAN模型的缺陷检测
训练完成后的GAN模型即可用于色织物的缺陷检测。由于训练完成的生成器能有效重构色织物样本图像,因此检测阶段只需要生成器即可,检测阶段的过程示意图如图3所示。检测时,输入为256×256大小的三通道待测图像,经生成器重构后输出与输入尺寸大小相同的重构图像。然后对待测图像与其对应重构图像均进行灰度化与高斯滤波操作,之后再计算二者的残差图。
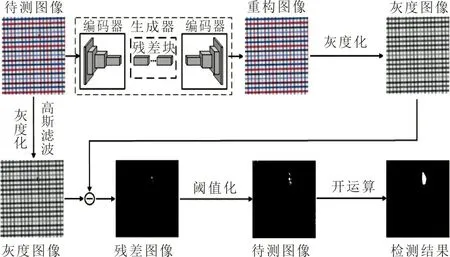
图 3 缺陷检测阶段示意图Fig.3 Diagram of defect detection stage
如果待测图像中存在缺陷,则重构图像为相应的无缺陷图像,经残差计算后,缺陷区域与重构修复后的区域存在明显的像素值差异,然后通过残差分析与数学形态学处理,将缺陷区域进行准确定位;如果待测图像中无缺陷区域,则待测图像与对应的重构图像之间的差异仅为随机噪声。具体检测流程如下:
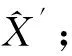
(5)
然后,计算残差图像的均值μ与方差σ,得到自适应分割的阈值T,阈值计算公式如式(6)所示,实验中k的取值为2。
T=μ+kσ
(6)
接着,对残差图进行阈值化处理,得到二值图Xbinary。如果残差图中某一点的像素值大于阈值T,则将该点像素值置为逻辑1,反之则置为逻辑0;最后,为了消除随机噪声对检测结果的影响,采用开运算处理二值图,得到最终检测结果R,即
R=(Xbinary⊖E)⊕E
(7)
式中:⊖、⊕分别为腐蚀与膨胀操作;E为结构元素。
2 实 验
2.1 实验数据集
实验所用数据集来自于YDFID-1[26]数据集。YDFID-1数据集包括3 501幅织物图像,其中3 189幅为无缺陷图像,312幅为缺陷图像。根据织物图案的复杂性,可将其分为简单格子(simple lattices,SL)、条纹图案(stripe patterns,SP)和复杂格子(complex lattices,CL)3种类型。本文从3种类型的数据集中选取了6个不同花型的数据集进行训练和测试,分别命名为SL1、SL16、SP3、SP5、CL1、CL2,每个数据集包含2部分:用于训练的无缺陷样本和用于检测的有缺陷样本,如图4所示。经整理后的实验样本数量分布如表4所示。

图 4 部分色织物样本Fig.4 Samples of yarn-dyed fabric
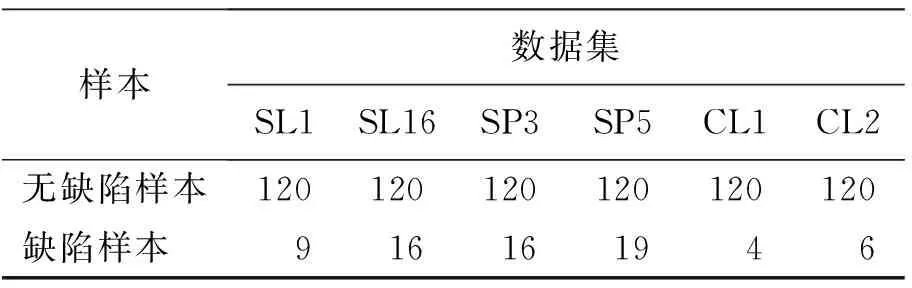
表 4 数据集样本数量
2.2 实验平台
实验硬件配置为CPU:Intel(R) Core(TM) i7-6850K CPU (3.60 GHz);GPU:NVIDIA GeForce GTX 1080 Ti (11 GiB);内存为64 GiB。软件环境配置:操作系统为Ubuntu 16.04.6 LTS;深度学习框架为Keras 2.1.3、TensorFlow 1.12.0;Anaconda3。
2.3 评价指标
为了评估模型在训练完成后的去噪重构能力,文中选择了2种目前广泛使用的图像质量评估指标,峰值信号比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)[27]对模型训练后的去噪重构结果进行定量分析。
对于检测结果,本文选取了F1-measure(记为F1)、准确率(记为A)、交并比(记为U) 3个缺陷检测算法中常用的评价指标来定量分析所提方法的检测效果,其计算公式分别为
(8)
(9)
(10)
式中:TP为正样本预测为正;TN为负样本预测为负;FP为负样本预测为正;FN为正样本预测为负。
3 结果与讨论
3.1 重构效果对比分析
为了定性分析不同模型的重构效果,本文分别从实验数据集中选取了SL1、SP3、CL2数据集进行展示,比较DCAE、MSCDAE、UDCAE以及本文所提出方法的重构效果,4种模型的重构实验结果如图5所示。

图 5 4种模型重构结果定性分析Fig.5 Qualitative analysis of reconstruction results of four models
从图5可以看到,在SL1数据集上,传统的DCAE、MSCDAE、UDCAE模型重构图像中均有缺陷区域存在,本文所提方法的重构图像中则没有缺陷区域的存在。在SP3数据集上,DCAE模型则无法有效重构花型纹理,MSCDAE模型的重构图中存在背景纹理损坏,UDCAE模型无法完全修复缺陷区域,而本文所提方法则能在修复缺陷区域的同时保证背景纹理的完整。在CL2数据集上,DCAE模型重构图像在缺陷区域有明显的纹理上的变形,MSCDAE、UDCAE模型的重构图像明显优于DCAE模型,但是也存在一些纹理上的变形,本文所提方法的重构图像相比于其他几个模型是最优的。
此外,为评估不同模型对色织物图像的重构能力,本文分别计算了各个模型下色织物与其对应的重构图之间的PSNR、SSIM值,结果如表5所示。
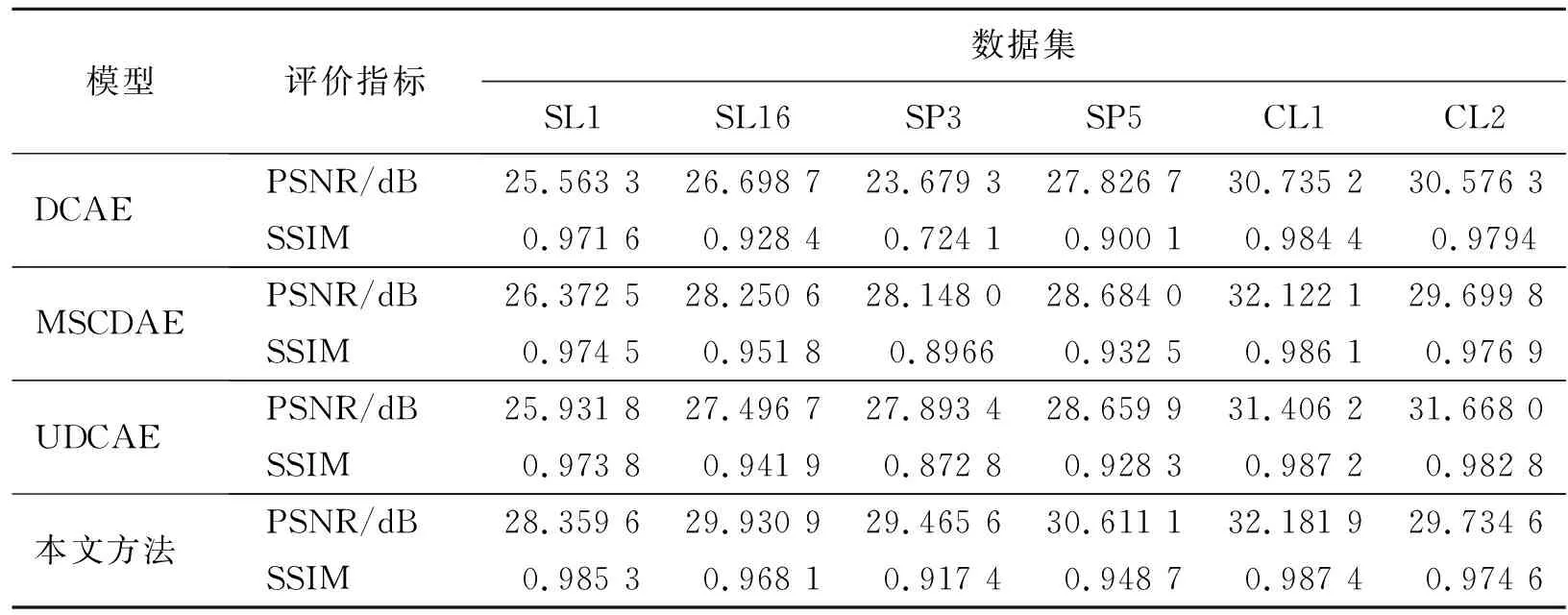
表 5 重构结果评价指标值
从表5可以看出,本文所提方法对SL1、SL16、SP3、SP5、CL1这5个数据集都有最高的PSNR与SSIM指标值,只有CL2数据集的PSNR、SSIM指标值低于UDCAE模型。而PSNR与SSIM的值越高,表示重构的图像与原始图像越接近。因此,可以认为本文所提方法能够更好地实现对色织物的重构,而重构效果越好的残差图像计算越准确,检测结果也越准确。
3.2 检测结果定性分析
依据实验中色织物数据集的缺陷检测结果,在6个数据集上对本文所提出的模型与DCAE、MSCDAE、UDCAE等模型进行定性分析,结果如图6所示。

图 6 4种模型检测结果图Fig.6 Detection results of four models
从图6可以看出,由于DCAE模型网络层数较浅,因此对于细小的缺陷检测效果不佳,例如SL16数据集;且在复杂背景纹理下的检测结果极易出现过检现象,例如SP3、CL1、CL2数据集。虽然MSCDAE模型采用了多尺度结构,但是每个尺度上的网络层数依然比较浅,导致细节保留能力不强,所以同样存在严重的过检问题,例如SL16、CL1、CL2数据集。由于UDCAE模型使用了跳接结构融合了浅层特征信息,所以重构效果要优于DCAE、MSCDAE模型,从而检测结果也更好,但对复杂背景纹理的织物同样存在过检现象,例如CL1、CL2数据集。相比之下,本文所提方法在缺陷定位准确的前提下,没有产生多余的噪声,并且检测出的缺陷区域连续性也优于其他几种模型,例如SP5数据集。综上所述,本文所提方法对色织物缺陷检测的效果明显优于DCAE、MSCDAE、UDCAE模型。
3.3 检测结果定量分析
为了定量评价本文方法的缺陷检测能力,选取DCAE、MSCDAE、UDCAE等模型,计算了每个模型、每种花型的F1、A以及U值,将其检测结果进行对比,最高值均用黑色字体标出,结果如表6所示。
从表6可以看出,对于DCAE模型,计算所有实验数据集的评价指标后,只在SL1数据集的指标A取得最高值;对于MSCDAE模型则均未有最高值;对于UDCAE模型,分别在SL1、SP3数据集的F1与U指标上取得最高值;本文所提方法则在SL16、SP5、CL1、CL2等4个数据集上的所有评价指标取得最高值,在SP3数据集的评价指标A上取得最高值。综上所述,对于背景纹理相对简单的格子类型与条纹图案类型色织物,DCAE、MSCDAE、UDCAE模型,可在部分数据集上取得较为理想的检测结果,然而当显著增加背景复杂性时,上述3种模型很难有良好的表现,但是本文所提方法则能很好地完成缺陷检测任务。因此,相比于DCAE、MSCDAE、UDCAE无监督缺陷检测模型,本文所提方法在色织物的缺陷检测上具有明显的优势。

表 6 定量分析对比
3.4 消融实验
为了验证生成器模型中间层添加残差块的数量对重构结果的影响,本文分别设置了0、3、6、9、12个残差块,在SL1数据集上进行消融实验。结果如图7所示。

图 7 不同数量残差块的重构图Fig.7 Reconstructed images with different number of residual blocks
从图7可以看到,随着残差块数量的增加,原图中大缺陷区域的重构修复效果较好,但网络层数的增加,模型的参数量以及训练时间会显著增加,对硬件的要求也越高,如表7所示。因此,综合考虑模型的重构效果以及实验硬件条件,本文最终选择在生成器模型中间层添加9个残差块。
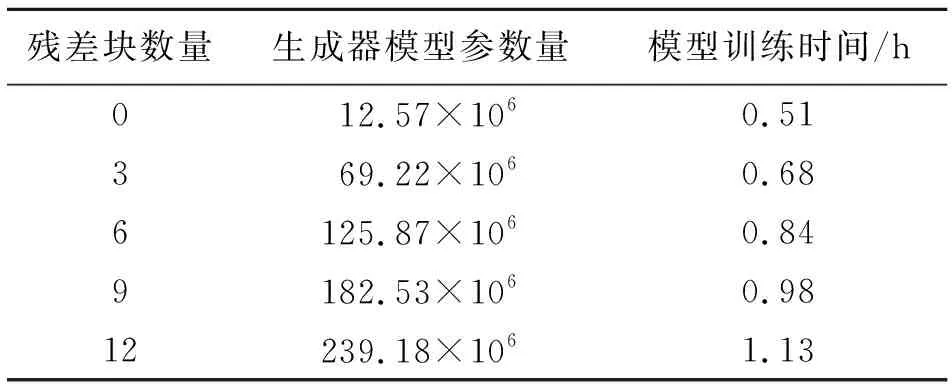
表 7 参数量及训练时间对比
4 结 语
针对色织物织造工艺流程中缺陷检测的问题,以及传统检测方法与有监督学习的检测方法存在的局限性,本文提出一种基于GAN的无监督缺陷检测模型。首先,利用无缺陷色织物样本训练模型,使模型具备对色织物图像的重构能力;然后将待测织物图像输入模型,获得对应的重构图像;最后计算待测色织物图像与其重构图像之间的残差图像,通过残差分析与数学形态学处理,实现对色织物的缺陷检测与定位。实验结果表明,本文所提出的方法在检测精度上可满足色织物生产时的验片工艺要求,为色织物的疵点检测提供了一种易于工程实践的自动化检测方案。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算机仿真(2022年7期)2022-08-22
成都信息工程大学学报(2022年2期)2022-06-14
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国纤检(2015年15期)2015-11-13
纺织导报(2009年7期)2009-07-30
