
基于聚合的FlowRadar网络数据采集加速模型设计*
2022-03-22 04:12吕高锋王玉鹏杨鎔嘉
计算机工程与科学 2022年2期
吕高锋,王玉鹏,杨鎔嘉,唐 竹
(1.国防科技大学计算机学院,湖南 长沙 410073;2.78156部队,甘肃 定西 748100)
1 引言
目前,已存在多种针对大规模网络的状态属性采集方法,这些方法在流量覆盖、软硬件开销和带宽资源占用等方面各有优缺点。例如,早期的数据采集主要基于简单网络管理协议SNMP(Simple Network Management Protocol)[1],但由于SNMP通常采用轮询的方式采集设备信息,在拥有很多设备的大型网络中,轮询流量容易导致网络拥塞,并且其支持的信息量也很小。因此,Cisco推出了NetFlow协议[2,3]来实现流量监控,但会导致较高的CPU开销和内存负担。为了降低交换机或路由器的CPU开销和内存负担,基于专用芯片支持的sFlow[4]技术应运而生。随着采集技术的发展,基于Sketch的数据采集方法(如SketchVisor[5]、CountMax[6]、Sketchlearn[7]和SpreadSketch[8]等)被提出,该类方法采用更紧凑的数据结构,以固定大小的内存汇总所有数据包的流量统计信息,具有更低的资源消耗,同时只产生有界的错误率。然而,现有基于Sketch的测量方案在高流量负载下会出现严重的性能下降,将其应用于网络测量时会不可避免地带来巨大的计算开销。
随着数据平面可编程技术的不断发展,由数据包内嵌自定义统计信息的带内测量方法成为热点,同时很多Sketch方法也可以基于数据平面可编程语言P4进行快速高效的实现,大大降低了软件实现的资源开销和芯片流片的代价成本。FlowRadar[9]测量方法即以P4语言为实现基础,但与Sketch类方法对数据流进行概率采样或近似估计不同,FlowRadar使用全采样的方法提取流的五元组信息以及流、分组计数,可实现数据中心等大流量情况下的全局流分析。但是,由于在匹配流和更新计数器的过程中FlowRadar采用了Bloom Filter,导致该方法在哈希计算过程中存在较大的计算开销和随机内存访问开销。
针对上述问题,本文结合Agg-Evict(聚合-逐出)[10]快速聚合思想,通过减少FlowRadar在匹配流和更新计数器过程中哈希计算所产生的开销,减少网络设备数据统计开销,从而提高数据转发的吞吐量,满足网络海量数据量采集需求。
2 背景技术
2.1 FlowRadar采集方法概述
FlowRadar作为一种全时段全采样的数据流统计方法,解决了NetFlow无法处理海量数据流的不足。FlowRadar的设计关键点是如何在给定的有限流处理时间内,在Hash表中维护流的五元组以及流计数和分组计数,同时保持较小的占用内存和具有恒定的流处理时间。FlowRadar的流处理过程如图1[9]所示,当一个数据包到来时,FlowRadar首先提取数据包的五元组字段,同时检查流过滤器判定该流是否已经被存储在流的集合中。如果该数据包来自一个新的流,FlowRadar首先更新计数器表,这包含流异或操作、增加流计数和报文计数。如果一个数据包是已经存在的流,FlowRadar只增加报文计数。最后,FlowRadar在恒定的短时间内,定期地将这些编码后的数据信息发送到远程采集器进行解码。
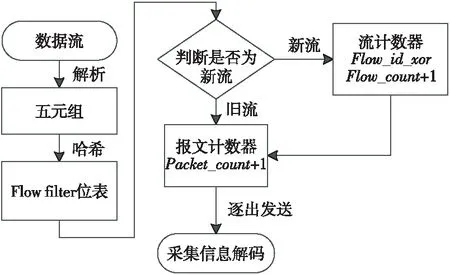
Figure 1 Flow processing of FlowRadar图1 FlowRadar流处理
FlowRadar的数据结构由流过滤器和计数器表2部分组成[9],具体如图2所示。对于如何解决在Hash过程中产生的流冲突问题,FlowRadar首先将同一流散列到多个位置(如Bloom Filter),这样其中一个单元格中的一个流与另一个流碰撞的可能性就降低了。当多个流落在同一个单元格中时,如果将它们存储在一个链接表中开销会很大,FlowRadar则使用异或函数来对同一个单元格产生冲突的流五元组信息以及计数器进行编码。因此,FlowRadar可以在多个流共享的固定大小的内存单元格中工作,并且对所有流都有固定的更新和插入时间。
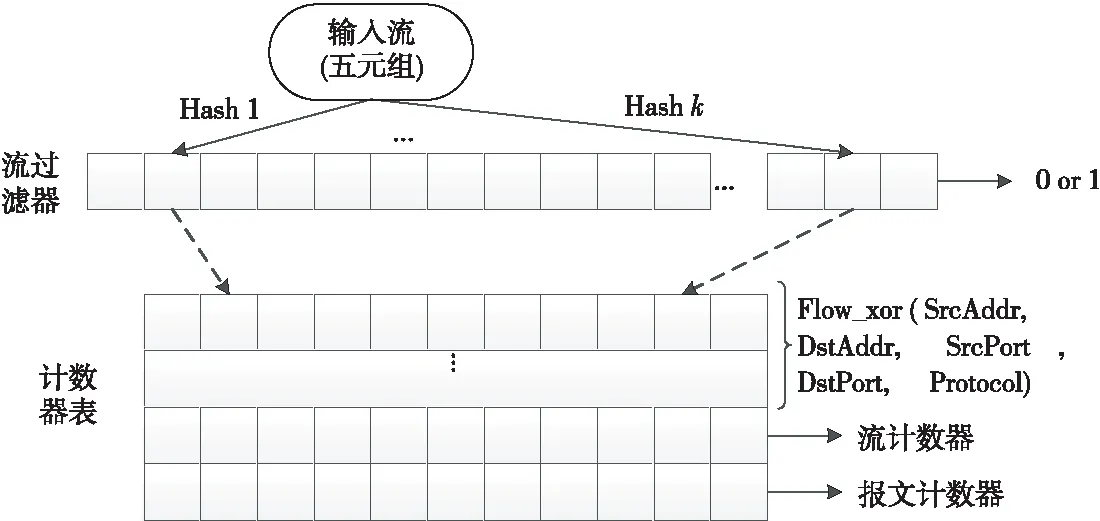
Figure 2 Data structure of FlowRadar图2 FlowRadar数据结构
2.2 Agg-Evict加速方法概述
为了进行聚合更新以节省计算和内存访问,Agg-Evict设计了如图3[10]所示的加速框架,其中聚合器包含k个KV(Key Value)数组,每个数组有l个KV对,每个KV对的Key部分存储流id,Value部分存储相应的聚合频率。

Figure 3 Framework of Agg-Evict图3 Agg-Evict加速框架示意图
该框架将网络测量分为2个阶段:聚合和逐出。在聚合阶段,框架主动针对所有入站数据包聚合流id,并将唯一的流id与其聚合频率存储在一个称为聚合器的数据结构中,同时使用一些连续的内存访问(高缓存位置)。在逐出阶段,当聚合器满时,一次将存储在其中的一些流id及其聚合频率逐出到现有的测量解决方案中,进行聚合更新,从而获得次线性处理时间[10]。但是,该方案以特定CPU的SSE2 SIMD指令进行KV查询和匹配,提高了流id哈希值与KV对的匹配判定效率,不适合于通用交换芯片或P4处理器架构。因此,本文基于协议无关交换架构,采用P4语言重新设计实现了该加速框架,并进行了实验验证。
3 网络大数据采集优化相关研究
网络大数据采集在许多方面都可以通过优化来满足日益增长的数据采集需求,例如数据流的存储检索、负载分配优化和查询优化等。
在数据流的存储优化方面,由于数据流的存储和分析需要高性能的硬件和软件,针对集中式IP流收集的方法缺乏可扩展性,易遭受单点故障,并且随着存储的IP流记录数的增加,流检索性能不断降低。DIPStorage(Distributed Storage of IP Flow records)[11]方法设计了一个可扩展的IP流记录存储平台,其体系结构建立在P2P概念之上,采用共享资源方式的分布式哈希表DHT(Distri- buted Hash Table)存储IP流记录的子集。原型系统评估显示,该方法可有效存储和检索大量的IP流记录。
在负载分配优化方面,基于Sketch的测量面临的关键挑战是如何以最少的资源利用率接受更多的并发测量任务,COSTA(Cross-layer Optimization for Sketch-based Software difined measurement Task Assignment)[12]方法设计了基于Sketch的跨层优化测量系统,在测量应用精度和资源使用之间达到了不同程度的平衡和优化。该系统利用应用层和任务分配层之间的跨层信息,估计应用层和资源使用情况,在管理层中查找具有足够可用资源的设备以分配这些应用程序。该方法将分配问题描述为一个混合整数非线性规划问题,并开发了一个两阶段启发式算法来有效地分配任务。通过对真实数据包跟踪的大量实验,证明了COSTA可以减少40%的资源使用,并可额外接受30%以上的任务,同时只有很小的准确度损失。
在查询优化方面,ShBF(Shift Bloom Filter)[13]设计了一种用于表示和查询集合的框架,可以使用少量内存快速进行3种常见的集合查询(成员查询、关联查询和多重查询)。ShBF提出在位置偏移量中对集合元素的辅助信息进行编码,而不是对集合数据结构分配额外的内存来存储辅助信息,通过对3种查询类型的ShBF进行分析建模,计算出最优系统参数。测试结果表明,ShBF在3种类型的集合查询上都有显著的性能提升。
4 基于聚合的网络大数据采集加速
4.1 基于聚合的网络大数据采集加速模型
基于聚合的网络大数据采集加速模型如图4所示,所有报文依据五元组信息归类为不同的数据流,聚合器根据报文所属的数据流进行归类统计。该聚合器的处理过程主要包括聚合和逐出2部分,通过将多次更新聚合为一次更新来降低传统大数据采集方法的计算开销。聚合后的报文再进入FlowRadar进行信息采集,最后发送到后端控制器进行解码分析。

Figure 4 Overall process of aggregation-based acceleration for FlowRadar图4 聚合加速FlowRadar总流程
4.2 报文聚合模块设计
为了减少每个报文都进行哈希计算所导致的巨大计算开销和随机内存访问开销,本文参考Agg-Evict框架设计了聚合器数据结构来主动聚合数据报文,从而更有效地处理聚合流,并且不依赖同一批数据中的数据报文访问同一条目的概率。图5展示了包含16个单元格的聚合器结构,该聚合器包含4个KV数组对,每个KV数组对包含4个单元格,每个单元格中记录了K值(报文五元组信息)和V值(分组计数器)。

Figure 5 Structure of 16-cell aggregator and P4 code图5 聚合器结构及对应代码
具体处理流程如图6中报文聚合部分所示。当数据流到达时,聚合器首先将数据流解析后的五元组通过一个快速哈希函数映射到4个KV数组对的任意一个,然后与KV数组对的4个单元格中的K值进行匹配。若匹配,则分组计数器V值增加;若不匹配,则查找空的单元格插入流的五元组K值,并将V值置1;若不匹配且无空的单元格时,则执行相应的逐出策略产生新的空KV数组对后插入。通常每次逐出的流id包含1个以上的报文数量,而传统FlowRadar方案每次只处理1个报文,因此采用聚合更新方式可减少大量计算和随机内存访问开销。
此外,在计算开销和随机内存访问开销降低方面,本文举例说明。假设网络有9个流id为f1、f2、f3、f1、f3、f1、f2、f1和f1的传入数据包。通常情况下,需要更新FlowRadar的计数器9次,即需要进行9次哈希计算和9次随机内存访问。使用聚合方法之后,首先将9个报文聚合为3个具有相同流id的报文集合:f1*5、f2*2和f3*2,然后将聚合结果导出到FlowRadar中。这样只需进行3次更新(即3次哈希计算和3次随机内存访问)。通过这种方式,在不考虑聚合操作所引入额外开销的前提下,FlowRadar的处理速度理论上可以提高3倍。
4.3 流逐出模块设计
逐出策略决定当KV数组已满时应逐出哪一条流,它决定了聚合器的聚合级别,对聚合性能具有重要影响。常见的选择策略是LRU(Least Recently Used),它为每个KV对维护一个时间戳,记录上一次更新该KV对的时间。一旦需要逐出一个KV对时,需要找到拥有最小时间戳的KV对并逐出。由于LRU每次逐出需要扫描各个时间戳,其实现开销相对较高。
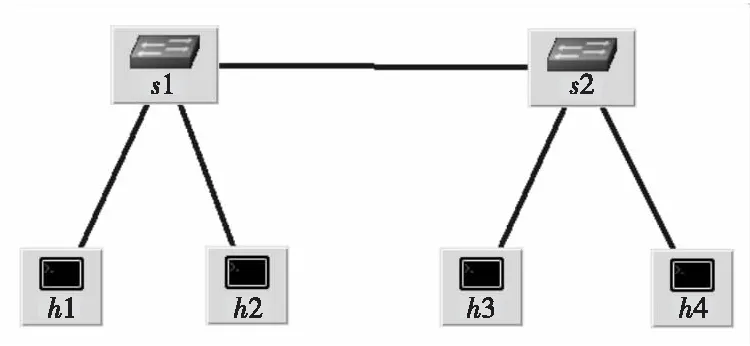
为了减少操作开销,本文采用了GRR(Global Round Robin)逐出策略。该策略对于k个KV阵列,保持一个从0到m-1(m 总体而言,不同的逐出策略不影响测量方案的精度,而只影响测量方案所看到的分组输入顺序。 被逐出的流将进入标准的FlowRadar采集结构进行流信息采集,它会将同一条流的信息通过多个哈希函数分散计入Bloom Filter的多个位置,但对于报文计数器而言,此时一次性计入的将不是单个报文,而是逐出流所包含的所有报文数目,大大减少了多个哈希函数重复计算带来的计算开销和带宽消耗。最后,FlowRadar将采集的数据提交到后端采集器进行单流解码和网络解码,后续操作与FlowRadar原始架构一致。 原型系统采用Ubuntu 14.04虚拟机进行搭建,虚拟机软硬件配置如表1所示,搭建的简单网络环境如图7所示。系统基于Mininet构建2个bmv2交换机,每个交换机接入2个终端,交换机上运行修改后的FlowRadar P4程序以实现聚合加速采集功能。 Table 1 Software and hardware configuration of the prototype system Figure 7 Topology of the test network图7 测试网络拓扑图 聚合加速模型通过降低计算开销和访存次数来提升采集性能,但上述2个指标并不能说明加速方法的有效性,因为在计算开销和访存次数减少的同时,本文所提方法在报文聚合和流逐出阶段会带来额外的开销,因此仿真实验以系统总体的吞吐量和处理延时作为评价指标。 本文在6个节点的网络拓扑中,对比测试了原始FlowRadar和聚合加速FlowRadar的网络性能,即终端h1、h2之间的网络吞吐量。实验通过iperf发送TCP流量,每隔0.5 s测量一次,测量时间为300 s,具体结果如图8所示。 Figure 8 Comparison of network throughput图8 网络吞吐量对比 由图8可知,在更大的时间尺度范围内单个的FlowRadar的测试带宽平均值为72.28 Mb/s,基于聚合的FlowRadar的测试带宽的平均值为108.87 Mb/s。从总体上看,聚合加速的FlowRadar仍比单个的FlowRadar的带宽提高36 Mb/s左右,吞吐量性能提升约50.63%。同样地,单个的FlowRadar带宽波动幅度比较小,聚合加速的FlowRadar带宽在某些时刻,由于聚合模块报文逐出时处理数据流较大的原因会有骤降的现象,但在其余时刻其带宽更加趋于稳定。 同时,本文对比测试了FlowRadar和聚合加速FlowRadar的双向网络时延,测试方式为h1 pingh2,每隔0.01 s测量一次,测量1 000个报文取平均值,测试结果如图9所示。 Figure 9 Comparison of bidirectional network delay when the time interval is 0.01 s图9 时间间隔为0.01 s时的双向时延对比 由图9可知,在0.01 s的时间间隔下,聚合加速的FlowRadar和原始的FlowRadar都存在少量的时延抖动。但是,从总体上看,在相同的网络拓扑及相同的终端和交换机中,聚合加速FlowRadar的网络时延要低于原始FlowRadar的。两者的时延在数据量增加的过程中,由于单个的FlowRadar在全时段具有对流的恒定处理时间,前期时延数据有所波动,后期趋于稳定;而聚合加速的FlowRadar则由于报文逐出过程中数据量的处理会剧增,前期时延数据同样有所波动,后期的时延还是存在波动状况。两者前期都存在数据量异常波动的原因是每次测试都要重启网络拓扑,软件环境还不是很稳定。 测试时间间隔为0.1 s的结果如图10所示。可以看出,在更大的时间粒度和范围下(0.1 s),聚合加速的FlowRadar和原始的FlowRadar的延迟时间都存在较大波动。在粗粒度的时间间隔观察下,两者的数据波动差异不明显。从总体上,在相同的网络拓扑及相同的终端和交换机中,聚合加速的FlowRadar延迟要低于原始FlowRadar的延迟。 Figure 10 Comparison of bidirectional network delay when the time interval is 0.1 s图10 当时间间隔为0.1 s时的双向时延对比 测试时间间隔为1 s的结果如图11所示,在最大的时间粒度和范围下(1 s)测试1 000个数据包的延迟,除去两者都有的个别异常剧增的延迟数据,在相同的网络拓扑及相同的终端和交换机中,聚合加速FlowRadar的延迟总体上要低于原始FlowRadar的延迟,并且两者异常波动的数据相差无几,其原因可以归结于软件环境的影响。 Figure 11 Comparison of bidirectional network delay when the time interval is 1 s图11 当时间间隔为1 s时的双向时延对比 综合以上3组测试结果来看,采用聚合加速FlowRadar的交换机处理时延总体上要低于原始FlowRadar的。但是,在时延抖动方面,在细粒度的时间维度下,基于聚合加速的FlowRadar由于采用报文聚合和逐出机制会造成较大的时延抖动;在粗粒度的时间维度下,两者的时延抖动相差不大。 本文对网络大数据采集优化方案进行了研究,基于协议无关交换架构PISA(Protocol Independent SwitchArch),采用P4语言设计实现了面向报文聚合的FlowRadar数据采集加速模型,将属于同一流的报文进行聚合,降低FlowRadar中使用多次哈希操作所导致的计算开销和内存访问次数。最后,本文基于Mininet搭建原型系统进行功能验证与性能测试,实验结果表明,聚合加速的FlowRadar在网络吞吐量和处理时延等方面的性能要优于原始FlowRadar模型。4.4 逐出流数据采集
5 仿真实验测试
5.1 测试环境与测试拓扑
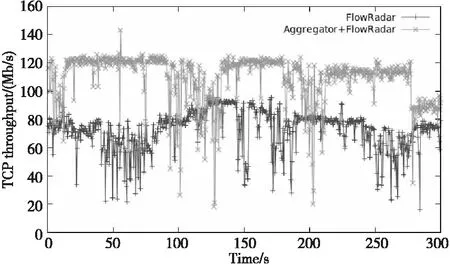
5.2 网络吞吐量对比
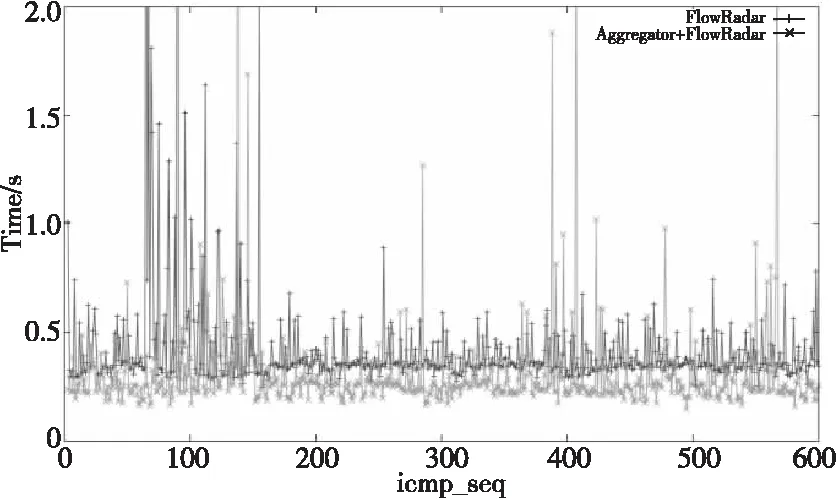
5.3 处理时延对比
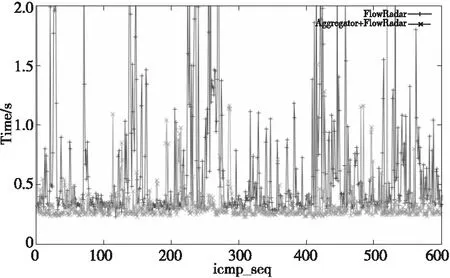
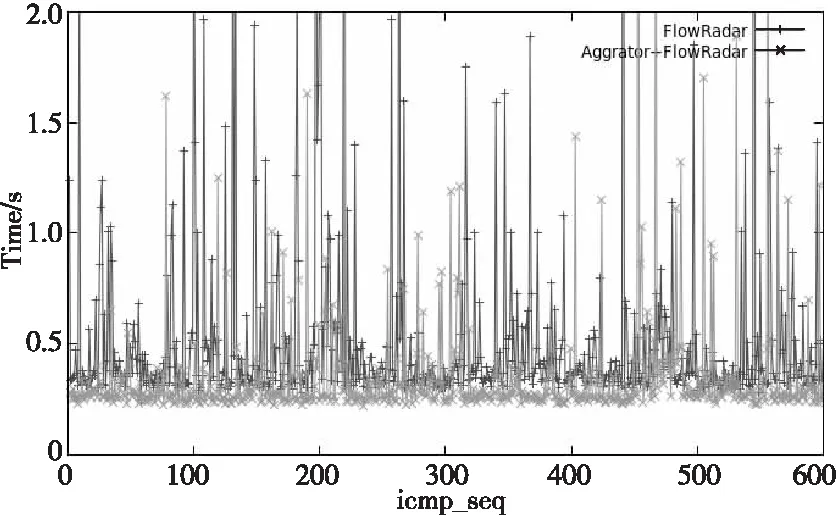
6 结束语
猜你喜欢
数据与计算发展前沿(2021年5期)2021-11-30
大数据(2021年6期)2021-11-22
电脑爱好者(2021年12期)2021-06-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年8期)2021-04-21
汽车维修与保养(2020年10期)2021-01-22
电脑爱好者(2020年20期)2020-10-22
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
汽车维修与保养(2020年11期)2020-06-09
