
基于ResNet模型的儿童口吃类型识别研究
2022-03-26 07:53潘文林马孟星
云南民族大学学报(自然科学版) 2022年2期
程 振,蒋 作,潘文林,马孟星
(1.云南民族大学 电气信息工程学院,云南 昆明 650500;2.云南民族大学 数学与计算机科学学院,云南 昆明 650500)
口吃是一种交流障碍,世界卫生组织将其定义为:“一种言语节奏的紊乱,即口吃者因为不自主的声音重复、延长或中断,无法准确表达自己所想表达的内容”.口吃主要表现在说话过程中句子开头的发音困难,患者说话节律异常,表达不畅,整个过程中反复停顿.世界上约有1%的人受口吃困扰,给患者在工作和社交造成极大不便.口吃在2.5~6岁之间的儿童发病率高达5%,其中20%的儿童口吃患者,因没有被正确对待和治疗,会逐步发展为成年阶段的口吃,最终成为终生口吃.因此,在儿童早期发现并解决语言障碍问题则至关重要.目前临床医学和心理学对儿童口吃做了大量的研究,其工作集中在儿童患者口吃的病因、病理机制、心理疏导、口吃矫正方法等方面.
然而在自然语言处理领域,针对儿童口吃语音识别研究及相应语料资源的构建较少.为解决稀缺口吃语料库的问题,文中对21名5~8岁的儿童进行了语音采集,再使用语音合成技术将该数据集合成儿童口吃语料库,并对该语料库进行标注.然后基于语料库,使用ResNet模型识别口吃语段,并对识别结果进行分析.
1 相关工作
医学领域对于儿童口吃的理论研究十分深入,为自然语言处理的领域奠定了基础,但是儿童口吃语料资源的匮乏限制了儿童口吃类型识别的研究.因此,国内外研究者对口吃语音语料库的构建和口吃语音识别展开了相应的研究.
1.1 口吃语料库构建研究现状
1995年,Howell等[1]创新地开启口吃自动识别研究,并于2009年创建了伦敦大学学院口吃演讲档案—UCLASS.UCLASS包含139名参与者的音频样本,参与者是患有不同严重程度的口吃患者,年龄在8到18岁之间.目前大多数的口吃研究都围绕该语料库展开[2],但因其标注只包含采集时的地点、性别等信息,未对语音内口吃发生的时间和类型进行标注,对口吃类型的检测效果甚微.最近, Kourkounakis Tedd等[3]在2020年创建了LibriStutter语料库,该语料库是由加拿大女王大学的AIIM实验室创建,并对该语料库进行了口吃类型的标注和相应的识别研究.
针对汉语口吃语料库的工作较少,Fang[4]使用了由天津医科大学提供的50个口吃患者的400段口吃语音作为研究数据.Zhang等[5]采集了由北京林教授言语训练中心的59名口吃患者的录音作为研究数据.由于以上的口吃研究语料不针对儿童口吃研究,不能直接用于儿童口吃识别工作,因此文中将构建一个基于儿童语音的口吃语料库.
1.2 口吃识别研究现状
早期的研究中,研究者们集中在区分口吃的可行性上,对一组特定的口吃词进行训练和测试.Howell等[6]第一次尝试使用一组预定的单词训练人工神经网络定位口吃,从这些数据中提取音频的自相关特征、光谱信息和包络参数,每一个都被用作一个完全连接的人工神经网络(ANN)的输入.结果表明该模型在严重口吃下的分类效果最好,最大检测率为82%.Ravikuma等[7]使用了多种音节重复分类器,包括隐马尔可夫模型(HMM)和使用梅尔频率倒序系数(MFCC)特征的支持向量机(SVM)[8].在使用支持向量机对15名参与者进行口吃类型分类时获得了最佳结果,准确率达到94.35%.在中国口吃检测研究中,Zhang等[9]通过建立HMM的发音质量评估框架,并基于改进的算法使重复性口吃的检测错误率降低18%.在Chee[10]发表的口吃识别研究综述中表明,限于当时技术条件和算力的匮乏,HMM在口吃识别研究领域表现最佳.
近年,随着计算机算力的提升,自动语音识别(ASR)和自然语言处理(NLP)等深度学习技术的发展,深度学习在口吃分类和识别方面效果显著,逐渐成为口吃研究者采用的主流手段.其中Heeman[11]将语言病理学家的注释与对应词合并,将基线提升了7.5%.Kourkounakis等[3]在2020年使用的FluentNet对LibriStutter语料库的检测准确率达到了86.7%,在多类型口吃检测中达到最优.
传统的语音识别需要提取MFCC等特征信息训练声学模型,然后根据语言中词与词的关系训练语言模型,保证得出正确语法的句子.但由于口吃语音的特殊性和受计算机视觉图像识别的启发,本文将只关注声学模型上的特征,将语音转换成语谱图,使用ResNet模型对语谱特征提取并识别.
2 儿童口吃语料库构建
本文首先对儿童语音进行实地采集,然后采用语音合成技术生成口吃类型语音,再将其随机填充到采集的儿童语音中,模拟真实口吃语音,最后对构建口吃语音及真实口吃语音的语谱图进行相似度分析.
2.1 语音采集
本文研究所用语料是与书丸子教育有限公司合作,对21名幼儿园儿童进行语音采集所得.每名儿童被要求朗读一段幼儿园教材的文章,语音以 16 kHz 采样率、16 bit 量化的wav格式保存.
2.2 语料构建
本文构建的儿童口吃语料库是在正常儿童语音的基础上进行合成口吃语音类型的填充,填充类型包括重复音、延长音和感叹词.其中语音的重复不仅是狭义上的语音重复即快速重复某一部分,而是广义上的语音重复,即可以将语音进行重复再细分[12],具体的细分规则为[13]:音节重复(part-word repetition,PW)、字的重复(word repetition,WR)、短语重复(phrase repetition,PH).表1总结了语料库的数据类型,并给出每个类型的例子.

表1 数据类型
本文通过对所有说话者的音频进行上述口吃类型的生成,对于给定的音频文件,在每4秒的语音窗口中随机插入一种口吃类型,并进行相应的标注.儿童口吃语料库具体构建方法如下:
1)音节重复的构建:实验将样本中随机挑选出的一个字的前一小部分重复1~3次.据VAN BORSEL J[14]研究表明音节的重复很少出现在词的结尾,为保持听起来自然,每个重复声音之间会随机添加100~300 ms 的空隙.
2)声音拖长的构建:将被随机选中的字的后20%拉长5倍.由于将时间拉伸应用于音频会导致音高下降,因此需移动音高来重新调整,使其与原始音频保持一致.
3)感叹词的构建:其与上述情况不同,它需要添加原始音频中没有的填充词(例如:“嗯”,“啊”),因此不能从现有的语音中产生.本文将从收集的多个常用填充词样本中分离出单个感叹词并进行保存,从而形成一个感叹词库.为模拟感叹词类型的口吃,实验从此库中随机选取感叹词插入语音中.同时为使语音听起来更加自然,在感叹词后再加入一个短暂的间隙;最后使用与拖长音相同的调整音高方法匹配感叹词和原始音频的音高.
为实现模拟自然口吃的最优效果,本文通过上述步骤确保每种口吃类型被安插于语音中,并对每个生成的语音进行标注,使每个音频文件都有一个相应的CSV文件记录该音频的标注信息,最终获得具有125段语音的儿童口吃语料库.图1并排显示了LibriStutter语料库和构建的儿童口吃语料库相同口吃类型的语谱图,为体现两者类型相似度,本文随机各抽取100个生成的样本并计算对应语谱图的感知哈希相似度及汉明距离[15]的平均值,如表2所示.
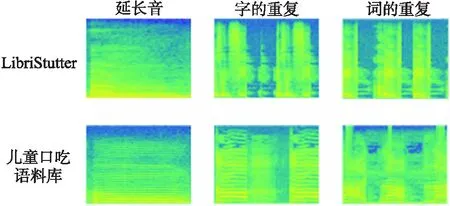
图1 语谱图的对比
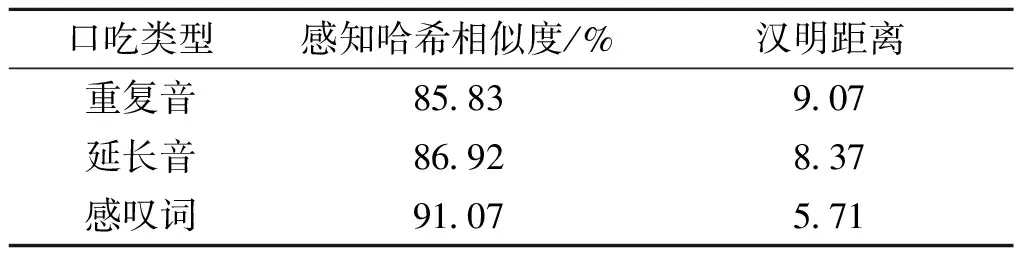
表2 LibriStutter和儿童口吃语料库的感知哈希相似度及汉明距离的平均值
3 实验
基于LibriStutter语料库和构建的儿童口吃语料库,本文将对口吃的3种类型:重复(R)、拖长(P)、感叹词(I)和正常语音(N)进行识别.为完成对口吃的分类,首先将音频转换生成语谱图,然后将其输入ResNet模型中,最后实现口吃识别.流程如图2所示.
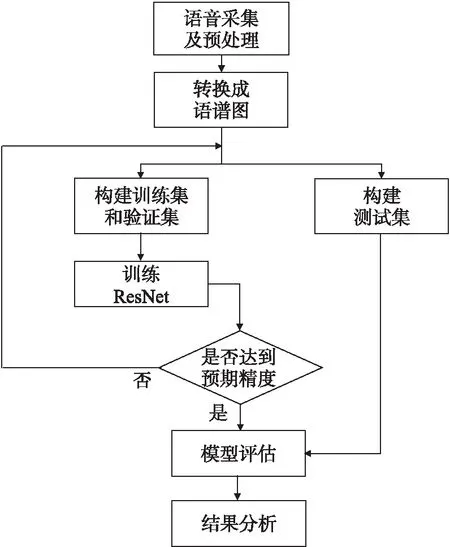
图2 口吃识别流程图
3.1 任务定义以及数据划分
本文将儿童口吃的识别任务建模为识别各类口吃的任务.输入语谱图数据M={m1,m2,…,mn},则模型需预测对应的标签N={n1,n2,…,nn},其中ni∈{RPIN}.R代表对应口吃的重复段,P代表口吃的延长段,I代表口吃的感叹词,N代表正常语音.
因为声音是时变的短时平稳信号,所以可以对语音信号进行连续的短时傅里叶变换,将语音波形信号转换成语谱图,如图3所示.标注F-5-003_R含义为第5个女生(female)的第3段音频中的重复类(R)口吃,其中横轴表示时间,纵轴表示频率,颜色的深浅代表能量的大小.

图3 F-5-003_R语谱图示例
为训练此次实验的模型,需对语音进行分段处理,如若将整段语音直接进行语谱图变化,将整段语音映射到固定大小语谱图后,每个词对应的特征分辨率将非常小,又因口吃持续时间不定,据统计一个词的发声时长约为 400 ms,对语音段经过 0.7 s、1 s、1.5 s和 2 s 等不同时长的切割尝试,最终确定2秒的段长最为适合,这样的时间间隔中既会包括口吃也会有正常语音,又不会因为时间过长而导致特征失真.将语音按时间剪切成相应的语音段,最终剪切出LibriStutter语料库中的口吃语音段 8 838 个,儿童口吃语料库中的语音段879个,共计 9 717 个2秒的语音段.最终将裁剪后的LibriStutter语料库和儿童口吃语料库的语音段分别进行标注并导出,各选取其中的60%作为训练集,20%作为开发集,20%作为测试集.口吃语音及标签的对应关系如图4所示.
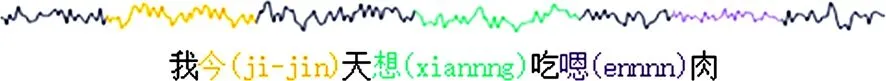
注:声音重复(黄色),延长音(绿色),感叹词(紫色)
3.2 模型设计
本实验采用ResNet模型[16]对语谱图进行特征提取,其模型由一系列残差块组成,如图5(a)所示,每个残差块可由(式1)表示为:
xl+1=h(xl)+F(xl,Wl).
(1)
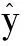
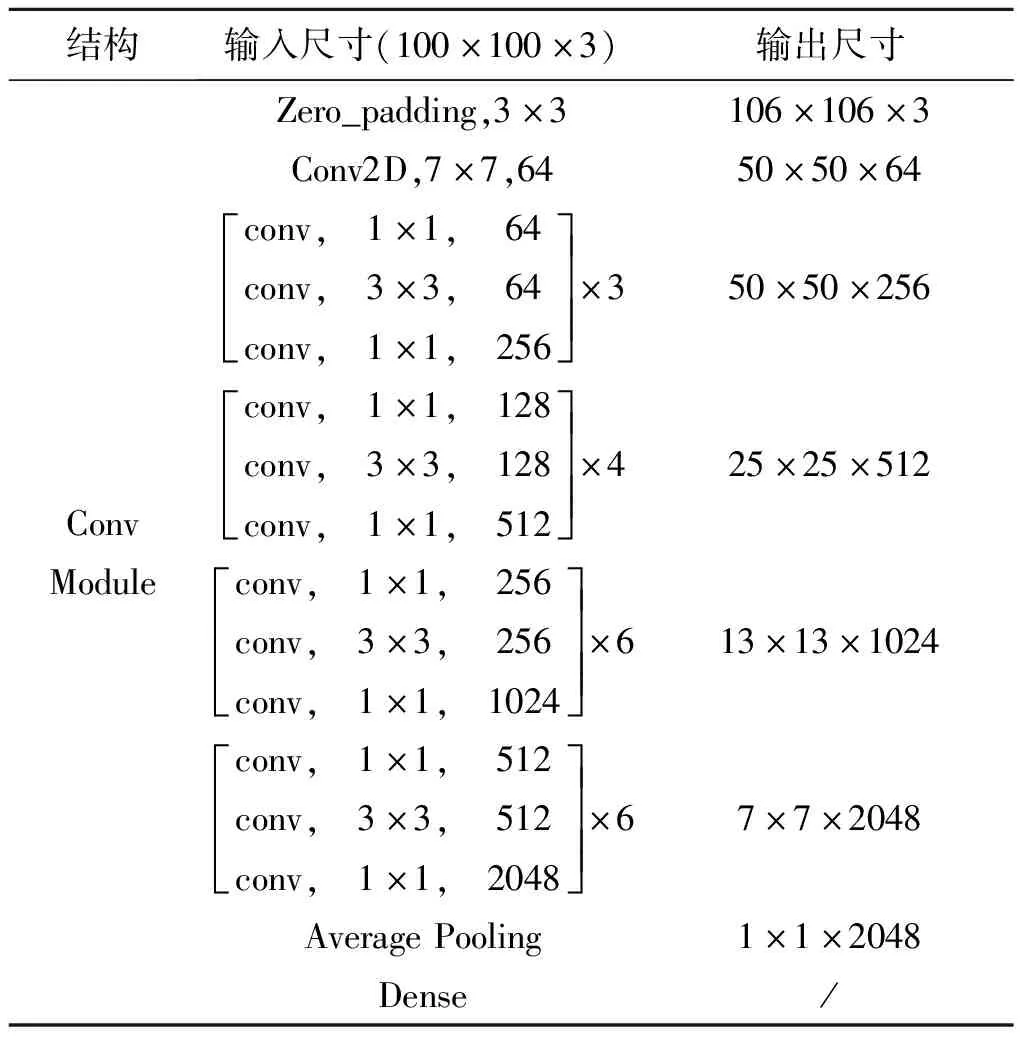
表3 网络模型参数表
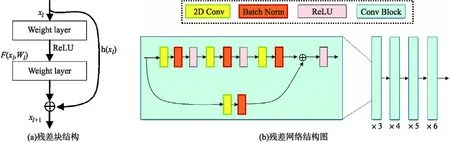
图5 残差块结构及残差网络结构图
(2)
当数据进行反向传播时,使用优化函数为随机梯度下降法(SGD),其中梯度更新步骤如(式3)所示:
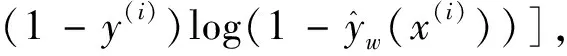
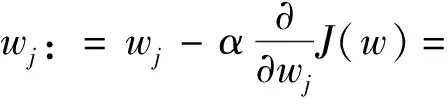
(3)
其中,J(w)是代价函数,N是样本个数,x(i)是第i个样本,y(i)是x(i)相对应的目标,α是学习率.
3.3 验结果与分析
本文实验均基于TensorFlow1.14框架用Python语言实现,实验环境:16 GB 内存的Windows10操作系统;CPU 为Intel(R)Core(TM)i3-4160 CPU @ 3.60 GHz;GPU为 8 GB 显存的NVIDIA GeForce GTX 1070 Ti.
训练前,使用PIL库的Image.open函数将图片读取并resize成100×100×3的尺寸大小,再将图片转换成计算机便于读取的二进制npy文件.训练过程中,设置模型的参数为:批次数32,轮次100;选择SGD作为参数更新方法,其中学习率 为2×10-3,衰减率为5×10-3,动量为0.9.经过100次网络迭代后模型趋于收敛.
由于使用神经网络模型识别口吃的研究工作相对较少,本文对神经网络模型的构建进行探索,本次实验分别使用AlexNet、VGG-16 以及ResNet模型,为体现实验准确性和对比的目的实验模型都使用上述相同的超参数,对儿童口吃语料库和LibriStutter两个语料库分别进行实验,其结果如表4所示.根据表中的实验结果可得,ResNet最终测试准确率稳定在93.07%和91.19%,表现均优于其他2种模型,检测准确率比FluentNet提升4.49%.

表4 口吃分类平均准确率
图6为ResNet在儿童口吃语料库和LibriStutter两个语料库上的训练情况,图中儿童口吃语料库用橙色实线表示,LibriStutter语料库用蓝色实线表示.从图6(a)中可发现,在训练初期,交叉熵验证损失值较高,且存在明显的震荡,但随着迭代次数的增加,2个语料库的损失值均逐渐收敛.从图6(b)中可得,在初期的迭代过程中仍存在震荡,但分别在第25次迭代和第10次迭代之后,儿童口吃语料库和LibriStutter库两个语料上的交叉熵验证准确率趋于稳定.从图中训练情况可知,ResNet网络在儿童口吃类型识别中能够较好地提取语谱图特征.
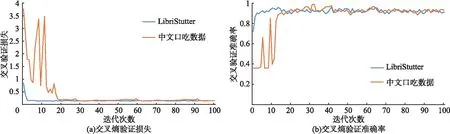
图6 基于ResNet模型的口吃语谱图交叉验证准确率及损失变化折线图
4 结语
本文为解决国内可用口吃语料库稀缺和辅助口吃类型识别问题,构建了儿童口吃语料库.使用该语料库和LibriStutter库的语音作为实验数据,以 2 s 为间隔切割语音并转为语谱图,对卷积神经网络识别口吃类型进行探究.实验结果表明,随着卷积神经网络深度的增加,模型能够有效的获取语谱图中的特征信息,在增加网络深度时使用ResNet模型残差结构的捷径反馈方式不仅能有效防止梯度消失和梯度爆炸的问题,还能够提高网络识别精度,在中文口吃数据集上的检测准确率达到了93.07%,在LibriStutter数据集上检测准确率比FluentNet提升了4.49%.在接下来的工作中,将对数据资源做进一步的扩充,以保证模型的稳健性和可靠性,并基于该资源对儿童口吃识别进行深入研究.
猜你喜欢
少儿科学周刊·儿童版(2022年9期)2022-07-09
外语学刊(2021年1期)2021-11-04
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
心理与健康(2018年1期)2018-05-14
师道·教研(2017年11期)2017-12-10
改革与开放(2010年6期)2010-06-04
祝您健康(1995年3期)1995-12-30
