
基于BiLSTM与注意力机制的剩余使用寿命预测研究
2022-03-27 11:56赵志宏杨绍普李乐豪
振动与冲击 2022年6期
赵志宏, 李 晴, 杨绍普, 李乐豪
(1. 石家庄铁道大学 信息科学与技术学院,石家庄 050043;2. 石家庄铁道大学 省部共建交通工程结构力学行为与系统安全国家重点实验室,石家庄 050043)
当今社会已进入工业化快速发展的阶段,对于各种机械设备的要求也越来越高,在各个应用领域剩余使用寿命(remaining useful life,RUL)预测技术都尤为重要。剩余使用寿命预测是预测某一机械设备从当前时刻保持正常运行的剩余时间或者失效时间[1]。理想情况下,剩余使用寿命预测侧重于在系统或者某一设备发生故障之前预警,给维修人员预留足够的时间,对于机械设备进行维护[2],能够降低设备的维修成本,节约维护时间。
剩余使用寿命预测方法大致可以分为两类:基于模型的方法和基于数据驱动的方法[3]。基于模型的方法主要是通过构建一个数学模型来描述机械设备的退化过程。某一机械设备的剩余使用寿命受自身制造工艺和操作环境等影响。理想情况下,构建过程不但需要经过测量后系统的实际参数,而且需要研究者对系统有充足的先验知识[4]。然而在现实中,实际情况非常复杂,出现的情况各不相同,大多数机械设备不能用简单的数学模型来预测RUL。
基于数据驱动的剩余使用寿命预测一般分为两种:机器学习方法和统计学方法。传统机器学习剩余使用寿命预测方法主要分为两个步骤:①分别在时域、频域或时频域人工提取特征;②构建剩余使用寿命预测模型[5],方法有人工神经网络[6]、灰色预测方法[7]、马尔科夫模型[8]、支持向量机[9]等。但传统机器学习的剩余使用寿命预测方法通常是浅层机器学习模型,存在着对多元复杂时间序列预测时选择模型及参数和特征提取困难、函数关系难以表达、预测结果受工况和环境影响等问题。
近年来,深度学习作为机器学习的新方法,具有强大的自动提取特征能力,被广泛应用在不同领域。基于深度学习的剩余使用寿命预测摒弃了传统剩余使用寿命预测手工提取特征的方法,通过构建一个多层的深度体系结构神经网络从获取的原始时间序列中自主的学习层次化的特征。Babu等[10]提出了一种基于卷积神经网络(convolutional neural networks,CNN)的剩余使用寿命预测方法,将卷积层和池化层应用于多通道传感器数据的时间维上,通过深层结构学习低层原始传感器信号的抽象表示,获取深层次特征信息。杨宇等[11]提出了全参数动态学习深度信念网络,在原始振动信号中提取深层特征信息,减少了训练时间,提高了预测结果精度。唐旭等[12]通过从多元时间序列中提取到的时域特征输入到长短期记忆网络(long short-term memory,LSTM)中进行剩余使用寿命预测,取得了较准确的结果。Ren等[13]利用深度自动编码器联合时频特征压缩和计算结果输入到DNN(deep neural networks)中进行剩余使用寿命预测。
以上基于深度学习的剩余使用寿命预测方法未能充分利用深度学习模型提取多元时间序列中深层特征信息。双向长短期记忆网络(bi-directional long short term memory,BiLSTM)对于处理基于时间序列的预测具有一定的优势,可以有效避免时间依赖带来的梯度消失或者梯度爆炸等问题。Mnih等[14]提出的注意力机制(Attention)被广泛应用于各个方面。注意力机制通过计算不同特征的注意力概率,对模型中的不同特征赋予不同权重,已有研究表明,注意力机制可以更好地利用提取到的特征信息[15]。
本文提出一种基于BiLSTM与注意力机制(BiLSTM-Attention)的剩余使用寿命预测模型。BiLSTM的优点是可以将前向和后向信息相结合,自动获取其中隐藏的特征信息,以提高剩余使用寿命预测能力。在剩余使用寿命预测中,BiLSTM是将获取的全部时间序列统一作为神经网络的输入,以进行特征提取。此外,本文采用了注意力机制对于各个BiLSTM输出的特征值分配不同的权重,以提高剩余使用寿命预测的准确性。将本文所提出的BiLSTM-Attention预测模型与现有的LSTM、BiLSTM模型在公共数据集上进行试验。试验结果表明本文提出的BiLSTM-Attention预测模型可以更准确地预测剩余使用寿命。
1 理论背景
1.1 BiLSTM
由于RNN(recurrent neural network)在处理时间序列存在长期依赖、梯度消失或者梯度爆炸等问题,研究人员提出了LSTM用于解决RNN出现的问题[16],但LSTM只能处理前向信息输入神经网络获取预测的结果,BiLSTM通过前向和后向信息神经网络获取预测的结果,往往在预测方面BiLSTM的预测结果优于LSTM[17]。BiLSTM结构如图1所示。

图1 BiLSTM结构图
在前向层某一时刻ti(i=1,2,…,n)正向计算,将获得的时刻ti前向隐含层的输出保存,得到Mf,Mf计算公式如式(1);在后向层ti(i=n,…,2,1)反向计算,将获得的时刻ti后向隐含层的输出保存,得到Mb,Mb计算公式如式(2);然后将前向层和后向层每个时刻ti获得对应的输出相结合获得最后的输出Yt,Yt计算公式如式(3),其中wi(i=1,2,…,6)为权重
Mf=f(w1xt+w2Mf-1)
(1)
Mb=f(w3xt+w5Mb-1)
(2)
Yt=g(w4Mf+w6Mb)
(3)
本文研究的是基于时间的序列数据,通过以上分析使用BiLSTM用于提取输入数据的特征,获取隐藏在时间序列中的特征信息。
1.2 注意力(Attention)机制
注意力机制最早应用于机器翻译[18],现在已经广泛应用于各种时间序列处理[19]。注意力机制的本质为计算某一特征向量的的加权求和[20]。注意力机制有很多种实现方式,本文采用的是乘法注意力机制中的Scaled Dot-Product Attention方法,其计算主要分为3个步骤。
步骤1将query和每个key进行点积计算得到权重。
步骤2使用Softmax函数对权重归一化处理。
步骤3将权重和对应的value加权求和获得Attention。
Attention计算公式为
(4)
式中: queries,keys,values的矩阵表示Q,K,V,Q=K=V=L,L为注意力层的输入;dk为queries,keys,values的向量维度。
2 基于BiLSTM与注意力机制预测方法
本文设计的基于BiLSTM与注意力机制相结合的网络结构如图2所示。主要由批标准化(batch normalization,BN)层、BiLSTM层、注意力层和全连接层组成。BiLSTM中LSTM单元数设为64;全连接层为2层,Dense_1输出维度设置为10,Dense_2输出维度设置为1;在输入层之后和注意力层之后使用BN层。该模型既能够自动提取原始信号时序特征信息,又能够突出关键特征信息,具有较强的特征提取能力。

图2 基于BiLSTM与注意力机制预测模型图
基于BiLSTM与注意力机制预测的主要步骤如图3所示。

图3 基于BiLSTM与注意力机制预测模型流程图
首先,对于多元时间序列的预测,先通过设定周期长度获得连续的时间序列,然后依次向后滑动直至一个周期结束,此时将获得若干组多元时间序列,即为不同发动机的时间序列训练集。将原始信号经过数据处理后,输入到BN层,BN层具有一定的正则化作用,可以避免过拟合和梯度消失的问题,提高模型稳定性和泛化性、加快训练速度并提高深度神经网络的性能。
其次,BiLSTM通过学习每个时刻ti前、后向的单元信息获得各个时间步输出值,学习时间序列前向和后向之间蕴含的信息,在解决时间序列依赖性和梯度爆炸等问题的基础上自动获取全面的特征信息。
然后Attention层对时序数据信息的进一步筛选,有选择的学习模型训练过程中的中间特征,通过权重分配的方式,将其与输出序列关联起来,过滤无用信息,突出关键信息,提高模型预测结果的准确性。
最后,全连接层进行降维,得到最终的剩余使用寿命预测结果,为提高预测结果准确性,采用加权平均降噪的方法对于预测结果处理。
3 剩余使用寿命预测试验
3.1 数据集
选择公开的C-MAPSS[21]数据集进行剩余使用寿命预测试验,C-MAPSS数据集如表1所示。分为4个子数据集,使用美国国家航空航天局开发的基于模型的模拟程序C-MAPSS生成的模拟数据[22]。

表1 C-MAPSS数据集
C-MAPSS数据集存储为n×26矩阵,其中n对应于每个子集中的数据点的数量。每一行是在一个操作时间周期内获取的数据,共有26列,其中第1列为引擎号,第2列为操作周期号,第3~第5列为3个操作设置,第6~第26列为21个传感器值[23]。数据中的3个操作设置会显著影响发动机性能。假设发动机内的每个轨迹是发动机的寿命周期,当每台发动机在不同的初始条件下进行模拟时,这些条件被认为是正常条件(无故障)。对于训练集中的每个发动机轨迹,最后一个数据条目对应于发动机被宣布为不正常或故障状态的时刻。另一方面,测试集包含故障前一段时间的数据,目的是预测每台发动机测试集中的RUL。对于C-MAPSS数据集中每个子集都有测试轨迹的实际RUL值。
3.2 数据预处理
由于不同的操作设置可能导致不同的传感器值,而得到的数据代表的物理特性不同。因此,为消除数据不规范对预测效果的影响,在进行任何训练和测试之前,必须进行数据归一化处理,原始数据通过处理将限定在[0,1]内,计算公式如式(5)
(5)

3.3 评分函数
为了比较评估模型在测试数据上的性能,需要一些客观的性能度量,主要采用了两种评价指标:评分函数和平均绝对误差(mean absolute error,MAE)。
本文使用PHM2008数据挑战中的评分函数,计算公式如式(6)
(6)
式中:n为测试集中的引擎数;S为计算的评分;d=Restimated-Rreal,Restimated为剩余使用寿命预测值,Rreal为剩余使用寿命真实值。
MAE[24]:单一依靠评分函数有时会因为异常值(比如d过大或过小)的出现影响对模型整体预测性能的评价,因此需要结合MAE共同评价。MAE值越小表示结果越精确,模型越有效。MAE的使用还可以避免人为降低评分函数值的现象发生,其计算公式如式(7)
(7)

3.4 试验过程及结果分析
3.4.1 数据处理
本节主要以C-MAPSS数据集子集FD001的数据为例进行描述试验。FD001数据集分为训练数据、测试数据和测试数据对应的真实RUL,其中训练数据有20 631个运行周期样本的训练数据,测试数据有13 096个运行周期样本的测试数据。训练集和测试集记录了发动机在若干运行周期下3个操作设置值和21个传感器监测数据,其中操作设置值如图4所示。首先是对于输入的数据序列进行归一化的数据预处理,对于得到的特征值可视化,去除不随时间变换的特征以减少计算量,提高计算性能。通过操作设置值和传感器监测数据分析可知,删去在发动机退化过程中始终未改变的一个操作设置和7个传感器数据,使用18个通道数据进行分析,将获取的数据进行归一化处理,使数据大小在[0,1]内。

图4 操作设置值
3.4.2 试验结果
根据训练集的设置,提取FD001对应的测试集和测试集对应的真实RUL。分别提取FD001中的两个操作设置和16个传感器监测值组成的18个变化的待预测序列,输入到训练集得到的预测模型中进行预测,最后将训练得到的预测RUL和真实RUL输入到评分函数中进行处理,获取对应的分数。利用BiLSTM-Attention方法得到的发动机预测RUL结果如图5所示,由图5可知,运行周期数较小时预测较为准确,随着运行周期数增加,设备出现故障,预测曲线出现波动,准确性降低。FD001和FD003为单故障类型数据,FD002和 FD004为多故障类型数据,FD001和FD003预测结果与FD002和FD004相比较为准确。

图5 C-MAPSS测试集发动机的预测RUL结果
3.4.3 评价结果比较
为说明本文提出的BiLSTM-Attention预测模型的有效性和可行性,选择了LSTM、BiLSTM与已有论文中深度卷积神经网络(deep convolutional neural network,DCNN)、随机森林(random forest,RF)和支持向量机(support vector machine, SVM)预测模型在同样的C-MAPSS数据集中4组子集试验训练,获取不同预测方法得到的评分和MAE进行比较。不同预测方法评分函数、MAE对比如表2所示。从表2可知,本文提出的BiLSTM-Attention预测模型与LSTM和BiLSTM方法相比,BiLSTM-Attention预测方法在评分函数和MAE两个方面均获得较好的结果。以FD001为例,评分函数LSTM最高,依次为BiLSTM和BiLSTM-Attention,降低了77.13%;MAE中BiLSTM最高,依次为LSTM和BiLSTM-Attention,降低7.12%(见表2)。
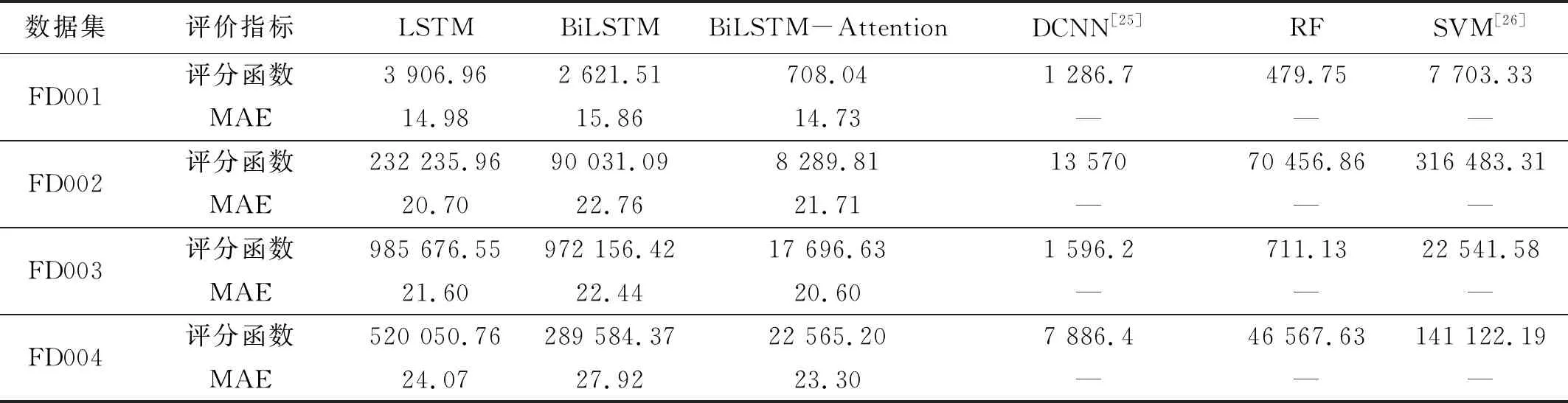
表2 C-MAPSS数据集预测结果比较
将表2与已有论文方法相比,BiLSTM-Attention预测模型的评分函数在子集FD001中低于DCNN 和SVM方法,但高于RF方法;在子集FD002中低于DCNN、SVM和RF方法;在子集FD003中低于SVM方法,高于DCNN和RF方法;在子集FD004中低于RF和SVM方法,高于DCNN方法。
通过以上结果分析可知本文提出的BiLSTM-Attention预测模型比LSTM和BiLSTM具有更好的数据特征提取能力。综上所述,本文提出的BiLSTM-Attention预测模型在航空发动机剩余使用寿命预测结果更准确。
3.4.4 不确定性试验
为了评估不确定性对传感器测量结果的影响,使用BiLSTM-Attention预测模型进行多次试验,不同子集不同评价指标波动值,如表3所示。所获得的均方根误差(root mean squard error,RMSE)和MAE显示了所提出模型的显着稳定的性能。

表3 BiLSTM-Attention不确定性试验
3.4.5 复杂度比较
为了说明本文所提出的BiLSTM-Attention预测模型与LSTM和BiLSTM预测模型相比的优点,对于以上3种模型进行复杂性对比,包括模型参数量和训练时间的对比。
模型参数量对比结果如表4所示。由表4可知,BiLSTM-Attention预测模型参数量多于LSTM和BiLSTM预测模型。模型训练时间取决与硬件情况,本文试验采用的硬件为:处理器:lntel(R) Core(TM) i5-6200U CPU @2.30 GHz 2.40 GHz;已安装的内存(RAM):8.00 GB;系统类型:64位操作系统,基于x64的处理器。模型训练时间如表5所示。由表5可知,BiLSTM-Attention预测模型训练时间多于LSTM和BiLSTM预测模型。

表4 不同预测方法参数量对比

表5 不同预测方法训练时间对比
3.5 泛化性试验
为验证本文所提出的BiLSTM-Attention预测模型的泛化能力,使用PHM2012轴承数据集[27]进行验证。该数据集包括3种工况下17个轴承水平方向和垂直方向两个加速度传感器采样得到的的全寿命周期振动数据,第1种和第2种工况各7个轴承,第3种工况3个轴承,分别命名为Bearing 1-1~Bearing 1-7,Bearing 2-1~Bearing 2-7,Bearing 3-1~Bearing 3-3,采样频率为25.6 kHz,每10 s采集一次数据,每次采样时间为0.1 s。本文验证采用的是水平方向的振动数据。本文在不考虑工况影响的情况下,使用14个轴承的数据作为训练集,将剩余的轴承数据作为测试集进行试验。以Bearing 2-6为例,轴承水平方向原始全寿命周期振动信号如图6所示。对于原始数据进行处理,行数等于加速度采集的次数,列数等于采集一次的数据长度。每行数据的标签,表示该行对应的轴承剩余使用寿命。假设第i行数据的剩余使用寿命标签为yi,表示当前时刻的剩余使用寿命与使用寿命的比值如式(8)所示。式8中m为行数,即轴承的实际寿命。经过归一化处理后的剩余使用寿命标签,可以降低不同轴承、不同工况、不同剩余使用寿命值之间的影响,提高剩余使用寿命预测的准确性。

图6 轴承全寿命周期原始信号
(8)
按照C-MAPSS数据集相同的试验方法使用基于BiLSTM与注意力机制预测模型对于PHM2012数据进行试验。Bearing 2-6在LSTM、BiLSTM和BiLSTM-Attention不同模型剩余使用寿命预测结果如图7所示。由图7可知,BiLSTM-Attention预测结果与真实值相比浮动较小,优于LSTM和BiLSTM。Bearing 2-6在LSTM、BiLSTM和BiLSTM-Attention不同模型剩余使用寿命预测评价指标如表6所示。由表6可知,BiLSTM-Attention预测结果评价指标均小于LSTM和BiLSTM。

图7 不同模型剩余使用寿命预测结果
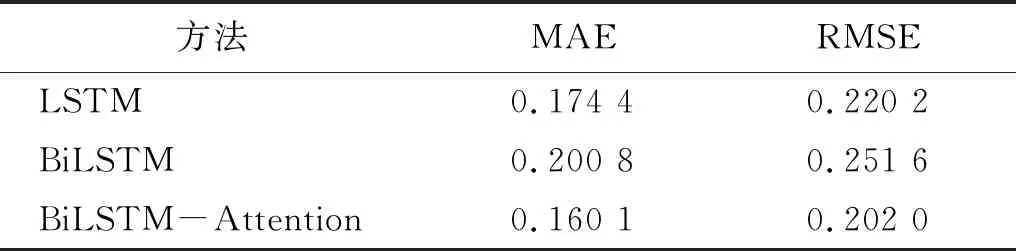
表6 不同预测方法对比
4 结 论
本文提出一种基于BiLSTM与注意力机制的设备剩余使用寿命预测模型,从多元时间序列数据中估计设备的剩余使用寿命。本文主要结论:
(1) 基于BiLSTM-Attention设备剩余使用寿命预测方法利用BiLSTM网络能够提取设备运行状态特征信息,通过注意力机制给提取到的特征信息分配不同的权重,从而更好地提取设备的健康状态信息。
(2) 注意力机制的引入能够提高深度神经网络模型剩余使用寿命预测的准确性。
(3) BiLSTM-Attention模型与LSTM、BiLSTM方法相比得到的寿命预测评价指标更好,寿命预测的准确性更高。
猜你喜欢
黄河之声(2022年10期)2022-09-27
舰船科学技术(2022年10期)2022-06-17
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
电子制作(2017年8期)2017-06-05
第二课堂(课外活动版)(2016年2期)2016-10-21
科学启蒙(2006年4期)2006-05-11
