
国内外网页存档理论与实践研究历程与特征分析
2022-03-30 23:23初彦伯王萍李依凝李佳恒
现代情报 2022年4期
初彦伯 王萍 李依凝 李佳恒



作者简介:初彦伯(1996-),男,博士研究生,研究方向:专利情报分析、专利情报挖掘。李依凝(1998-),女,硕士研究生,研究方向:信息资源管理。李佳恒(1994-),男,博士研究生,研究方向:信息资源管理。
通讯作者:王萍(1965-),女,教授,博士生导师,研究方向:信息资源管理。
摘 要:[目的/意义]存档网页具有凭证价值、情报价值及档案价值。对国内外网页存档研究历程进行梳理,以期对我国实践项目的发展及后续研究提供借鉴及参考。[方法/过程]对1993年至今的国内外网页存档文献进行研读,参照OAIS模型,将国内外网页存档研究整体划分为4个阶段,分别为初始研究阶段、纵深发展阶段、功能全面提升阶段、智慧型实践项目探索阶段;将各阶段发展概况及研究历程进行梳理,归纳阶段性研究热点及特征。[结果/结论]网页存档实践项目以理论与实践并行的方式发展。同时,向智慧型实踐项目不断探索。理论模型、系统框架、技术革新、资源采集方式、归档资源评估、资源开发利用及人工配置七者交融并互相促进,共同将存档网页资源推向深层化应用。
关键词:网页存档;网页保管;存档网页利用;网页资源长期保存
DOI:10.3969/j.issn.1008-0821.2022.04.014
〔中图分类号〕G250.1 〔文献标识码〕A 〔文章编号〕1008-0821(2022)04-0153-15
Abstract:[Purpose/Significance]The archived webpage has credential value,information value and archive value.The research process of home and abroad webpage archiving is sorted out,in order to provide reference and reference for the development and follow-up research of practical projects in my country.[Methods/Process]Referring to the OAIS model,and foreign web archive documents from 1993 to the present were studied,the domestic and foreign web archive research were divided into four stages,which ware the initial research stage,the in-depth development stage,the comprehensive function improvement stage,the exploration stage of the smart practical project;the development overview and research process of each stage are sorted out,and the characteristics of the staged research were summarized.[Results/Conclusions]The web archive practice project is developed in a parallel way of theory and practice.At the same time,continues to explore smart practical projects.Theoretical model,system framework,technological innovation,resource collection method,archive resource assessment,resource development and utilization,and manual configuration are blended and mutually promoted,and jointly push the archived web resources to deeper application.
Key words:web archive;web hosting;archived web utilization;long-term preservation of web resouces
随着互联网的普及、互联网技术的日趋成熟,互联网中的“网页信息资源”已经成为全球最大的信息资源库。中国互联网信息中心2021年2月3日发布的《中国互联网发展状况统计报告》中的统计数据显示,截至2020年12月,我国网民规模达到9.89亿,较2020年3月增长了8 540万,互联网普及率达70.4%,我国互联网行业在抵御新冠疫情和疫情常态化防控方面发挥了积极作用,为我国成为全球唯一实现经济正增长的主要经济体做出了重要贡献[1]。网页信息资源是一种动态增长的、易逝的且不可再生的“原生性”网络文献[2],研究表明一个网页的平均寿命只有44天[3],网页中的高价值资源一旦消失便难以复原,将会给国家和社会文化资源的持久保存和历史传承造成难以挽回的损失。为此,需要学界更多关注并研究网页存档问题,实现网页信息资源长期保存与持续利用。
所谓网页存档(Web Archive,简称WA),又称“网络存档”,是指一种在“原生性”网络信息资源的整个生命周期内对其进行有目的的评价、选择、采集、描述、元数据表示、存储、发布和维护等一系列工作以确保其当前可用和未来价值增值的管理活动[4]。近年来,国内外相关领域的专家学者投入了大量的精力和时间成本开展网络存档研究工作,不断完善网络存档的理论研究并积极推进实践探索,相关研究内容众多,研究主题庞杂,研究质量差异,使得有必要更好地了解国内外网络存档的研究现状,对国内外网络存档研究进行系统梳理,以期对我国相关研究提供借鉴和参考。
1 研究方法
本文采用文献调研法,国内文献选取中国知网(http://www.cnki.net/)为国内文献检索平台,选择高级检索方式,检索条件的篇名中分别包含“网页存档”“网络存档”“网页保存”“网络信息资源长期保存”“Web Archive”“Web Archiving”等关键词。国外文献通过检索Web of Science、Scopus等外文文献数据库,关键词“Web Archive”“Web Archiving”“Internet Archive”等,经过整理最后得到全部文献637篇,其中国内文献294篇,国外文献343篇。
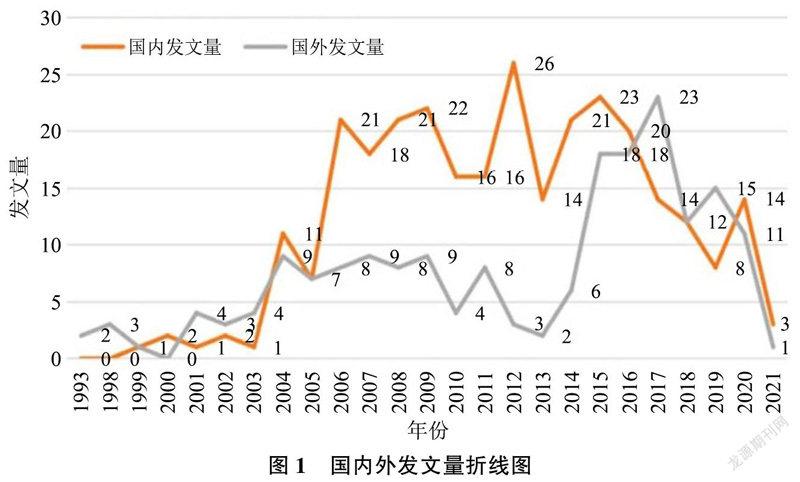
国外最早出现本关键词相关文献是1993年,国内是1999年。国外最早的文献是1993年C,SIMMONDS发表的SEARCHING INTERNET ARCHIVE SITES WITH ARCHIE-WHY,WHAT,WHERE,AND HOW一文。国内外在1993—1999年共发文5篇,2000—2004年共发文17篇,2005—2012年共发文159篇,2012至今共发文456篇。由此可见,与“网页存档”相关主题地研究是以递增的趋势发展,说明一直以来都是国内外众多学者研究的重点,从1993年至今的总体发文量曲线图如图1所示。
可以发现,国内文献总量为294篇,其中有25篇为硕士论文,没有相关主题的博士论文,说明国内对网页存档的研究还不够深入。国内总文献量呈递增趋势,说明在国内越来越多的专家学者投入精力完善网页存档的研究工作,随着网络技术研究的深入,未来会在此领域有大量新的研究文献发表。
国外从2003年开始文献量大幅递增,这与各个国家纷纷投入网页存档实践项目有直接联系。随着实践项目的不断发展及完善,在采集、归档保存及长久保存过程中所使用技术的不断更新,针对网页存档过程中涉及的核心技术进行深入研究的文献将变多,由此文献总量呈明显递增趋势。随着公众认知增加、获取途径增多,新的未知问题将会不断涌现,未来网页存档将仍然是国外学者研究的热点。
在前述基础之上,研读国内外相关主题文献,挑选时区研究重点主题,并结合现有研究进行阶段划分。网页归档实践项目的进展影响研究主题的更新,所以,本文还采用网站调查法和案例分析法,使用IIPC(国际互联网保存联盟)官方网站获取最新资料。通过对国内外网页归档实践项目的具体研究,从整个网页归档的流程,其中包括:采集方式、采集频率、技术方法、存档内容管理、系统平台搭建、开源工具研发、责任体系构建、法律及权利等角度作为出发点,系统归纳并总结阶段性研究热点,为划分本文网页存档研究的阶段提供了重要依据。
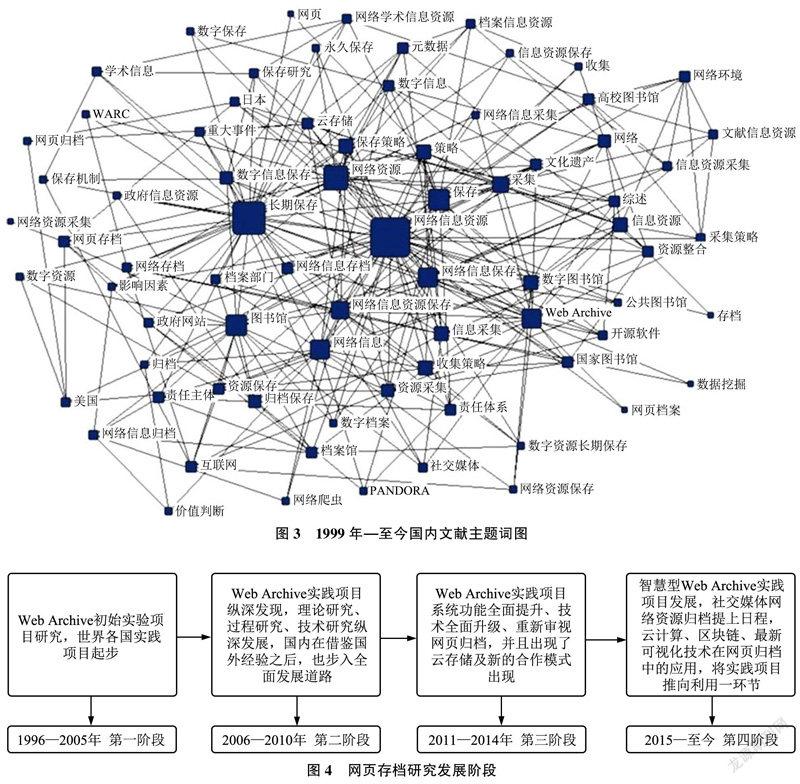
虽然网页存档的理论研究始于1993年,但实践研究则始于1996年。本文将网页存档研究历史进程共划分为4个阶段:第一阶段(1996—2005)为网页存档初始项目研究,第二阶段(2006—2010)为网页存档研究纵深发展,第三阶段(2011—2014)为网页存档系统功能全面提升研究,第四阶段(2015—至今)为探索智慧型网页存档实践,图2及图3是1993年、1999年至今的国内外相关文献主题词共现图。
本文在对国内外近年相关研究文献和网络存档项目调研的基础上,参照OAIS模型,将各阶段归纳为采集、管理、保存、利用4个主要阶段[5],对每个阶段的研究进行细分。如图4所示,以时间流逝线为主线,对1996年至今的网页存档相关主题研究进行全方位梳理。
2 网页存档实践项目发展概况
纵观整个网页存档研究历史进程,1996年Internet Archive[6]的提出正式意味着网页存档实践项目的兴起。同年,澳大利亚建立Pandora项目[7],开发了“PANDAS”数字信息存档系统,项目保存澳大利亚境内在线出版物,包括社会科学和自然科学、政治、宗教文化等方面的资源,建立与各州立图书馆的合作关系,在系统开发上,主要在数字对象存储系统、数字对象管理系统及数字对象存档系统3个领域进行主要投入[8]。同年,瑞典建立Kulturarw3项目[9],收集瑞典顶级域“se”下的Web服务器及部分其他服务器的资源。
1997年北欧图书馆在借鉴Kulturarw3项目的实践经验后,启动NWA项目[6],并成立专门的技术小组负责制定长期归档资源的保存、访问等技术规格,逐步建立与北欧各国图书馆、整个欧洲地区的网页存档合作机制。同年,美国国会图书馆建立Minerva Prototype项目[10],对长期保存资源的数字化、元数据、选择与采集、可获取等问题进行试验,通过与Internet Archive项目合作,获取“Wayback Mechine”及采集技术,为收集的网页资源进行索引,同时提供短期的数据存储服务,用户可以按照网站、日期或类别获取资源。
1999年新西兰国家圖书馆启动网页存档项目,对政府、历史、医学、音乐、政策等主题进行选择性采集[11],保存的资源内容支持网址搜索、关键字搜索、字母搜索、主题浏览。2000年捷克国家图书馆建立WebArchiv项目,提出基于重大事件的采集方式。2001年挪威国家图书馆启动Paradigma项目,通过法定存缴框架对长期保存的资源进行框定,并提供获取服务[12]。同年英国国家档案馆开展网页存档项目并采取选择性、事件、主题的收集方式对境内网站进行保存。在此项目中,部分内容可追溯至1996年的英国中央政府网站[13]。
2002年中国Web信息博物馆(Web Infomall)由北京大学主持开发,项目包括历史网页存储系统及回放系统两部分,使用网址链接的方式,浏览永久保存的网页[14]。2003年我国网页存档实践项目WICP(Web Information Collection and Preservation,网络信息采集与保存)正式启动,按照表层网及深层网分别进行收集与保存,分别以镜像存档及专题存档的方式,通过ODBN(On-line Database Navigation,网络数据库导航项目)进行收集、整理、编目保存等操作之后,最终形成网络导航展现使用。
2003年IIPC(国际互联网保存联盟)成立,对世界范围内的网页存档实践项目都有重要的推动和借鉴作用。软件技术方面的成果已收获颇丰,开发了一系列工具,均是开源的、拓展性强、适用于不同的环境、适用于不同系统的保存[6],已可以满足各国网页存档项目的部署应用基本需求。2006年起,国内学者在中文网络信息资源的采集策略、法律、资金、组织与管理机制、中文网络信息档案馆建设等问题方面提出更为先进的构想[15]。提出资源风险识别、深网采集、保存制度的深化、资源收集策略的更新、建立地方网络信息保存中心等建议。
截至2010年,国外网络信息资源的采集与保存工作,已经完成由技术支撑实践运行。尤其在采集和保存策略的开拓和实践两方面,积攒了大量的实践经验,网页存档实践项目参与主体、研究方式、项目状况、保存内容、技术标准、系统工具、法律政策、经济效益、合作机制等方面都有了不同程度的发展和完善;相比之下,我国还存在一定距离,充分借鉴国外的经验的同时,发展适宜我国国情的网页存档项目尤为重要。
2011—2015年,由技术驱动的网络存档,拉开系统功能全面升级的序幕,研究内容聚焦于重新审视网页存档的初衷、系统架构、软件技术、法律法规、责任体系等。除此之外,出现了新兴技术的崛起,例如,将云存储技术应用于网页归档及新合作模式下的网页归档。并且出现了一系列解决方案,例如采集内容部分发现的学科分布不平衡、部分内容缺乏权威性或学术价值、个人创作者选择标准的应用不清晰等。
网页存档实践项目整体已经完成从实验、部署应用以及系统平台的全面升级。2015年起,开启探索智慧型网页存档实践项目的新篇章,基于社交媒体的网页存档如雨后春笋般出现,自媒体类APP、微博等社交软件的兴起,对网页存档实施主体提出更大的挑战。在此阶段,突出主题是“存档资源开发利用”,以存档资源为原始数据进行的研究逐渐变多,并有持续上涨的趋势。例如:区块链、云计算等新技术在网页存档中的应用[16]将网页存档项目推向了智慧型阶段,区块链技术可以增强数据安全性、提高自动化认证能力、节约保存成本、提高审计效率且适用于协作保存网络环境下,海量数字资源长期保存可信性认证模式[17]。同时,也出现了基于信息生命周期管理理论,重点分析网络归档生命周期模型的结构、内容及优势的相关研究[18]。新合作模式、新技术、新系统架构的设想、资源深层开发利用4个主题的出现,标志着智慧型网页存档阶段正式开启。
3 研究历程及代表性观点
3.1 资源采集
2000年我国就有学者提出建立网上资源库的设想[19],认为创建网上信息资源库,收集和保存网络产生的信息资源能在“时间、空间和经济行为”三者之间进行有效配置。这一想法启发了杨道玲[20]提出网络资源要及时、系统的采集,应建立完善的数字资源呈缴本制度,以立法形式确保产生的网络资源置于国家控制下。2003李春明等[21]在以上研究基础之上提出为保证采集内容的准确性,应先基于区域进行模糊抽取,再基于正则表达式进行精确抽取,两种方法需要同时进行。
2004年赵俊玲[22]在提出在资源采集环节需要采用选择性采集、全域采集等多种方式混合采集资源,在对美国国会图书馆开展的Minerva项目研究中,加深自己的研究,提出基于重大事件的采集方式,以此,能够反映事件的全貌。同年,我国学者提出,对重大事件,如非典、人民代表大会进行专题的收集[23],以上观点不谋而合。难以收集资源所有历史版本及隐藏的或动态资源的难题一直困扰着网络资源采集,Hiiragi W等[24]提出一个网络归档的系统模型,按照提供网络资源的个人或组织确定的资源归档策略来收集资源的,从技术上解决了此问题。2015年Gossen G等[25]通过整合社交网络和聚焦网络抓取来提高网络收藏的新鲜度,提出通过一个新的集成的爬虫,将网络和社会媒体无缝地整合在一起,从而为一个感兴趣的主题收集新鲜的、相关的网络和社会网络内容。
2016年陈为东等[26]在社交媒体资源进行网络存档的基础之上,从采集工具的角度出发,提出社交媒体采集工具分为捕获形式、插件技术、专门针对某一资源或社交媒体、保存对象、其他种类共5类,从API独立性、采集内容、适用对象、是否开源与是否免费5个指标比较了捕获形式下以API获取信息的7种工具。2017年张卫东等[27]通过对欧盟FP7框架下发展成熟且具有代表性的社交媒体信息采集与保存项目ARCOMEM采用的信息采集机制、采集标准、采集策略和采集方法等方面予以深入剖析,提出了建立多元的组织协作采集机制、制定科学规范的采集标准、运用多目标驱动的采集策略、开发智能化的采集方法,提出需要资源保存风险评估及控制的技术做出进一步研究。
3.2 资源管理
关于采集数据管理问题,2006年陈清文[28]提出在管理方面,软件、硬件、人力等因素需要经济费用支撑,应该重视经济效益,在长期保存管理策略也提出了提高全民意识、制定有关网络信息资源长期保存的法律、建立网络信息长期保存的责任制、并提出网络信息资源呈缴制。王志庚等[29]在2007年提出各國项目管理数据所采取的措施不同,例如数据交换。因此,需要联合制定存档数据管理的统一标准,但在当时我国WICP的总量较小,还没有开展系统的数据管理研究和实践。
在2008年,作者对网络信息呈缴制的研究继续深化,提出将网络信息资源纳入呈缴之列,呈缴制度应该明确呈缴者的权利和义务并建立符合我国国情的呈缴制[30]。2011年杨智勇等[31]提出要从4个方面进行网页资源长期保存的管理分别是:更新技术、数字迁移技术、仿真技术及自动管理技术。
3.3 资源保存
2004年赵俊玲[19]在分析国外实践项目基础上提出,之后的研究应该是从保存策略和保存机构之间的合作模型进行研究,在自己的研究基础之上分别在2004—2005年之间,从保存资源的著作权和网络信息资源保存的框架入手进行研究[32]。2005年卢宏[33]在以上研究基础上,提出有关研究者须尽快制定网络文献著录规范,构建学科核心网站和学术信息网络资源评价体系。2006年陈清文[34]提出了长期保存的技术策略:保存“过时技术”法、迁移、建立长期保存系统。Yang G等[35]从长期保存具有良好可信度、唯一性和估值信誉的数字内容的角度,讨论了在网络服务器上保存单调递增的数字内容的策略。
2007年Kim Y S[36]提出在网页归档过程中,除了技术方面问题,归档内容真实性、版权等法律问题同样重要,因此,需要了解网络技术和法律的特征。2012年赵生辉[37]提出中国少数民族语言网络信息资源保存体系,分为信息来源层、数据集成层、集成服务层,提出少数民族语言网络信息资源长期保存应该按照档案化管理、多元一体和信息共享理念。2012年廖思琴等[38]根据OAIS框架,分析了云存储元数据在保存型元数据中的位置,根据国外数字资源长期保存元数据框架和实践项目分析了政府网络资源保存型核心元数据,并重点分析了云存储元数据,包括元素定义方法和定义工具。
2015年王志刚[39]提出图书馆需要数字技术作为发展力量,特别是在风险评估以及风险控制领域尤为突出,需要在实施网页归档过程中,对数字图书馆网络信息进行风险评估非常有必要。2016年孙红蕾等[40]首次提出“互联网+”时代下,在对互联网信息资源长期协作保存基本含义分析的基础上,阐释互联网信息资源长期协作保存的价值所在,并提出了包括组织机制、责任机制、保障机制、运行机制、激励机制在内的互联网信息资源长期协作保存机制。
3.4 资源利用
2005年,Thelwall M等[41]通过调查发现网页归档项目的实施存在国际偏见,而这种偏见是由于不同的全国平均网站年龄和超链接结构所造成的,提出研究人员在未来使用档案时需要尽量规避此问题。2007年国外学者Mohr,Gordon[42]提出现存工具Heritagrix、Web Crawler/Harvester、Wayback Mechine回放工具和Nutchwax档案全文索引工具和查询实时程序,一个标准的网络资源档案WARC也开发完成,下一步应该是提高国际合作的密切程度,以此将提高现有工具利用率。2010年龙正义[43]提出以利用为核心的网页归档项目,实际上最早提出“利用”方面的是Internet Achieve所述“离开了利用谈保存是没有意义的”,在提供网页信息利用方面,应当在法律允许框架下,尽可能的开发系统、网站或者平台供人们检索使用,现有的“Wayback Mechine”可以浏览自1996年至今的1 500亿个网站。
2013年,王芳等[44]提出存档资源要实现多元化应用,但与功能和服务都日益变大的空间相比,距离多元化的应用还是存在距离,存在法律伦理、可利用性和限制、以大数据方式利用技术需求等问题。2015年王萍等[45]对国外主要Web Archive项目存档资源应用的基本情况进行梳理,总结和分析当前网络存档资源开发利用的途径,立足于网络技术的不断发展和演变,以及未来对网络存档资源的应用需求,对其开发利用的发展趨势进行展望。
2019年黄新平[46]对欧盟第七框架计划资助的LiWA、BlogFoever、ARCOMEM、ForgetIT 4个发展成熟的社交媒体信息长期保存项目实施情况进行系统梳理,并从项目内容、开发技术和实践应用3个维度对其进行比较分析,为我国社交媒体信息长期保存项目的建设与应用提供借鉴。同年,将云计算应用于政府网络长期保存项目中,提出能够高效率、低成本地实现海量政府网页的在线归档和集成管理[47]。
3.5 技术研发
2003年Kawano H[48]将网络挖掘技术应用于网页存档过程中,使用文本网络挖掘技术基于Mondou网络搜索引擎和网络机器人来实现。2004年Wang W等[49]提出基于网络档案的网络考古学,由此产生的网络档案不仅是历史网页的集合,而且包含了丰富的信息,借助研究工具Waoa(网络考古档案馆官方网站)来挖掘档案,解决了文件类型的多样性、文件形式及脚本语言、网站更新频率、域内的链接结构等技术问题。同年,Fattah M A等[50]从互联网档案馆中存在的平行文本中自动提取英阿双语词典的两种算法从而提升内容准确度。Goodkin J等[51]提出一个获取和打包网络信息,并可以在多个存储器中归档的模型,该模型是Echo Depository项目的一部分,该项目是由美国国会图书馆与企业合作为期3年的数字保存项目。
2007年,Kim H等[52]提出网络存档的过程取决于采用的采集方法的类型、数据的组织和存储、数据的完整性和范围,实现了为密集网络存档开发元数据。Wu P H等[53]提出在用户使用网络档案时,能够访问完整和连贯的收藏内容很重要,因此提出了一种基于网络注释系统的设计原则来组织网络档案的方法,用来标注网络档案,该系统保留了编目过程的证据和上下文。2008年Wang L C[54]从元数据格式和内容结构两个角度探讨网络档案策略。在对元数据格式的分析中使用案例分析法,分析了它们的信息组织规律。其次,研究了起源档案原理及其在档案著录控制层次中的应用。2009年Crook E[55]提出,随着档案及归档能力提高,网络归档仍然面临着新技术和Web2.0应用两大亟需解决的难题。
2011年Saad M B等[56]提出现有网络档案大多以断断续续的形式出现,提高网络档案的连贯性尤为重要,作者从技术角度提出,在期望页面几乎没有变化的时间段,基于模式爬行站点,引入了一种新颖的导航方法,使用户能够在给定的查询时间浏览最一致的页面版本。2013年Phillips M E等[57]对归档的PDF资源进行分析,提出在归档整个工作流程中用于文档特征的提取工具,新工具将提供选择内容和建立收藏新的方式。同年,Jatowt Y A[58]提出了一个页面历史的交互式探索系统并演示了一个名为页面历史浏览器(Phe)的应用程序,用于总结和可视化网络页面的历史。Phe描绘了页面发展的概况,描述了其典型的内容随着时间的推移,并让用户从不同的角度观察页面历史。
2016年张炜等[59]基于区块链理念及相关技术,提出一种增强数据安全性、提高自动化认证能力、节约保存成本、提高审计效率且适用于协作保存网络环境下海量数字资源长期保存的可信性认证模式。2018年Pavlos F等[60]针对存档网页部分不可以利用这一问题,提出了一个rdf/s模型和一个分布式框架,用于构建描述网络文档内容的语义语义信息(层),并满足现有语义层可以满足现有关键字系统不能充分满足的信息需求。
3.6 系统框架
2006年国外学者Lor P等[61]提出了一个基于社会正义和人权的道德框架用来指导网络存档。同年,Choi K H等[62]介绍了韩国图书馆的网页存档系统,该系统的工作流程和处理过程是基于网站和网络存档的个人数字资源被有选择地收集。2007年刘进军[63]构建了一个中文网络信息资源保存的流程,其流程具体分为信息收集、加工、存储、服务4个阶段。2008年Anand A等[64]提出一个全球规模的基础设施来收集、归档和对收集的数据进行历史分析的分布式体系结构,从构建网络档案文本分析的工作中获得启发并提出Everlast,一个可扩展的分布式框架,用于下一代网络档案和档案上的临时文本分析,该系统建立在一个松散耦合的分布式架构上,可以部署在大规模的点对点网络上。
2011年杨元香[65]从价值的来源、属性和影响因素阐述价值概念,并在此基础上引申出归档网络信息价值的概念,论述了归档网络信息价值判断的重要性,从信息生产者的需求动力、信息服务商的服务和为用户提供共享的资源等方面说明归档网络信息价值判断的意义。2012年Noh Y H等[66]提出韩国网页存档项目“绿洲”首先应对网络数据进行定义,制定收集原则、收集方法、收集频率。其次,改进归档的目标资源。最后,提出选定目标材料数据库及制定合作存档政策的必要性。
2015年,Banos V等[67]使用网络内容管理系统(Wcms)实现将内容安全转移到网络档案馆以便保存,解决了部分网页资源不能完整归档的难题。同年,吴振新等[68]构建了国际重要科研机构Web存档系统,在采集端实现三层扩展,通过增加采集客户端功能提高存档流程自动化程度,通过增加的WARC文件内容解析功能抽取更多信息,实现索引及检索服务的扩展,系统扩展后的采集存档框架初步具备分布式、可扩展、全自动化的特点。
2016年胡吉颖等[69]开发了网络信息存档WARC文件的解析与索引系统,以此充分挖掘科技网站存档资源价值,实现向用户提供了丰富的科技网站存档数据信息,提高用户检索访问效率的目的。2018年吴硕娜等[70]通过分析了网络归档生命周期模型的结构、内容以及显著优势,对该模型进行前端和后端扩展,最终得到网络生命周期管理模型,从内容和技术要求上为网络信息资源管理提供了详细指导,有利于更好地发挥网络信息资源的价值,延续网络信息生命。
4 阶段性研究特征分析
4.1 第一阶段(1996—2005)
在此阶段,国内外网页存档发展涉及较为广泛,这是因为实践项目刚兴起,带来较多可以进行研究的切入点。国外在对网页归档过程中的采集工具、采集方式、归档资源组织、网站评估、索引网站、保存系统的开发、升级等问题的研究较为突出。国内研究则多数以国外较成熟的实践项目为研究对象,充分论述国内实践项目的同时,多角度进行分析,为我国的网页归档实践项目的发展提供建议;整体研究呈现增长的趋势,维度趋于横向拉宽。
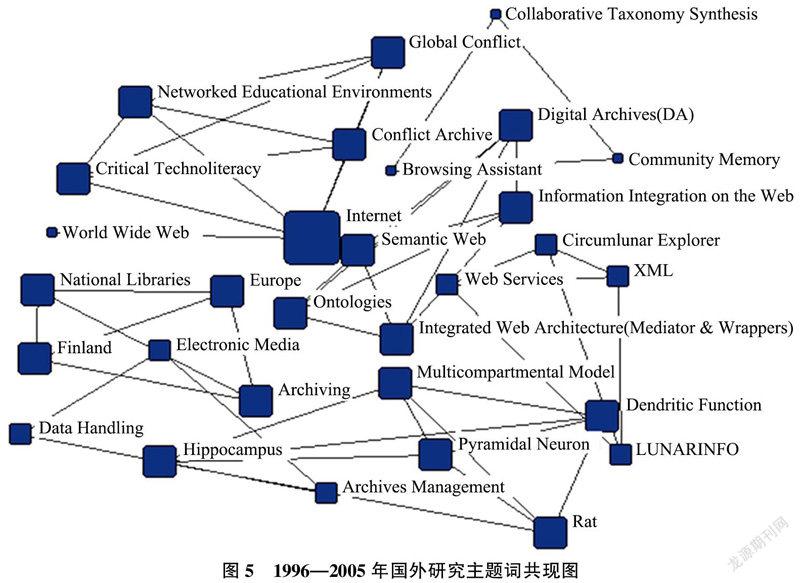
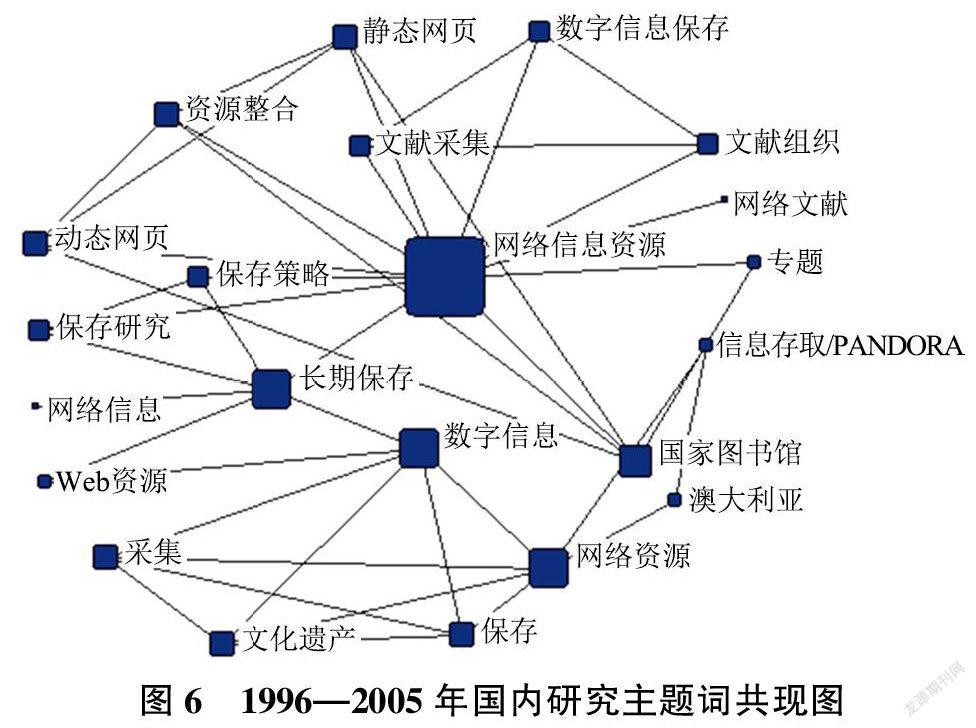
由1996—2005年每一年的发文数量逐渐变多,研究代表性思想呈现逐渐朝着整个实践项目各阶段进行深入研究的趋势,研究的范围逐渐变广,有趋于深入研究的趋势,随着时代的变迁会带来新技术的革新,研究的成果将会呈继续增长;在理论研究方面,国内的理论研究较多,技术方面的研究较少。国外相反,对技术问题研究较国内更深入也更前沿。为了直观了解本阶段国内外研究热点主题,如图5及图6为主题词共现网络。
1)资源采集:国内的研究,对于网络资源采集方式進行较为具体的刻画,以选择性采集、全域采集及主题事件采集等多种采集方式并行的方案受到推崇;首次提出“呈缴本制度”,以确保采集到的资源在国家的管控之下。
2)资源保存:国内从资源自身属性、保存内容的著作权及信息资源保存框架入手,对资源保存策略开展试探性研究,首次出现对于“归档资源评价”的相关研究。
3)技术研发:国内对于技术研发较少;而国外热度较高,出现将文本网络挖掘技术、网络考古、新算法等技术应用于网页存档实践项目,从而解决了网页存档过程中文件种类多样化、脚本语言障碍、域内链接结构等技术难题。
4)系统框架:国内外的系统框架聚焦于资源采集部分框架搭建,是因为此阶段对于网页归档资源的采集研究较多,出现基于采集方式的系统框架及社会正义与道德框架,以此指引网页存档实践活动。
4.2 第二阶段(2006—2010)
第二阶段,技术相关研究越发深入;国外此阶段的重点是技术的研发研究,包括系统架构升级、保存网络分布式体系结构、存储框架及存档质量等。国内的研究,除借鉴国外的实践经验之外,对我国网页存档项目的个性化建议也出现较多研究成果,对“责任体系”的研究为重点。在此阶段,国内外对于存档流程研究更为细化,趋近于完善的网页存档应用型项目。
1)资源采集:我国学者对于国内重大事件进行专题收集,以此反映事件全貌,国外研究从技术角度解决了采集过程中,难以收集资源所有历史版本及隐藏的或动态资源的难题。
2)资源管理:国内研究开始涉足元数据及元数据管理,从软件、硬件、人力、资金等方面完善网页存档实践项目,对于“呈缴制”的研究进一步深化,呈缴制度应该明确呈缴者的权利和义务并建立符合我国国情的呈缴制。相较于国内,国外此阶段的研究重点在系统研发及系统框架搭建。
3)资源利用:国外学者研究聚焦于促进工具的利用,从而促进资源利用。国内研究有相似之处,提倡使用“Wayback Mechine”并且在法律允许范围内,尽可能开发系统,在技术上国内的实践项目需要技术发展。
4)技术研发:国外对于技术研发实现一次峰值,在开发元数据、元数据的应用、编目归档内容的方法等进行的研究较多,也出现了一些设想,例如在面对Web2.0时代的解决方案,技术革新需要紧随时代发展的步伐。
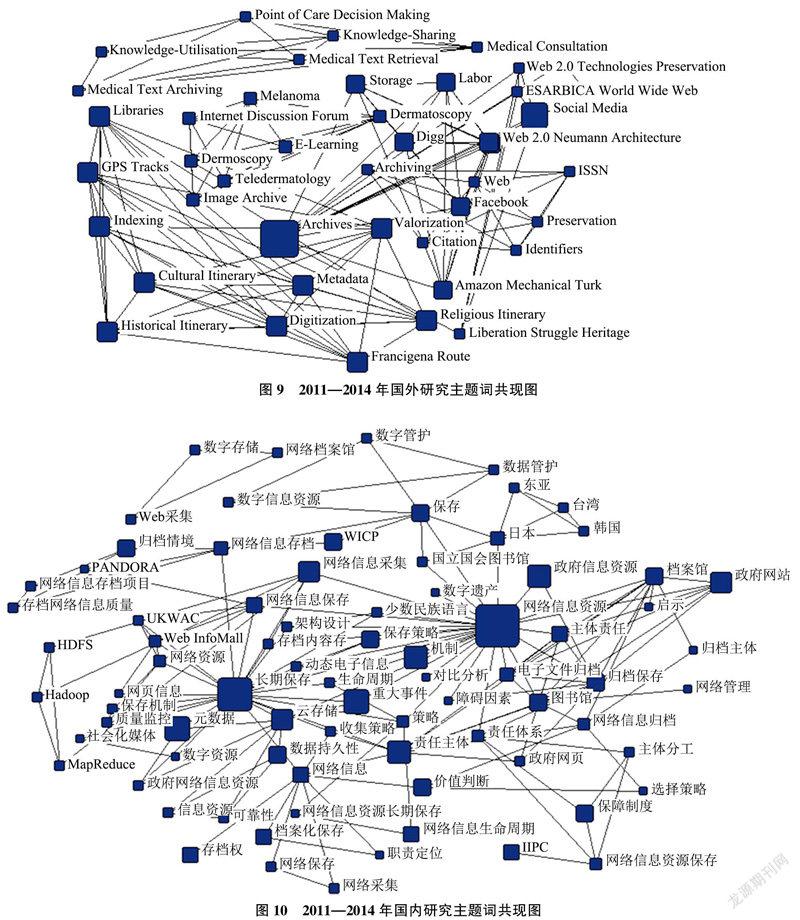
4.3 第三阶段(2011—2014)
相较于第二阶段而言,第三阶段是对采集、管理和保存过程中的技术进行全面的革新,国内在系统升级、爬虫技术、网络空间等方面研究都具有了显著提升,除此之外,对法律法规,责任体系和保存体系提出较多理论层面的建议;归档资源价值评估的研究成为凸显词,有变成热点的趋势。国内外均提出归档资源的价值评估。国外多从算法等角度进行优化,国内从资源采集阶段进行资源选取层面的研究,高价值归档网页的指向为资源的利用,国内外已经出现了由技术支撑网页归档项目的趋势,以及网页资源利用为核心的技术指向;国内外对于归档网页的利用研究已经出现了较成熟的想法,学者们对于资源的利用研究迫在眉睫,从理论层面和实践层面可以看出,国内外的研究已经将资源利用提上了日程。
1)资源管理:国内研究也涉足技术角度,在数字迁移技术、仿真技术、自动管理技术及技术更新等方面对归档资源进行管理的研究较多。国外在本阶段研究的重点系统框架搭建方面。
2)资源利用:国内外对于资源利用在“浅层资源利用”方面研究较多,实现归档资源多元化应用,还需要解决法律伦理、可利用性和限制、利用技术需求等问题。
3)技术研发:国外研究主要体现在解决归档资源断断续续、用户无法查询特定时间段内的归档资源的问题。除此之外,在归档资源的展示层面,也提出较创新的观点。国内此阶段对于技术研发还没有涉足太深,因为国内网页存档实践项目起步较晚,还需要进一步学习和完善。
4.4 第四阶段(2015至今)
此阶段,新技术的应用对研究方向有重大影响。国内外的研究主要体现在,包括云计算、云存储、区块链以及最新可视化技术应用于网页存档流程,以此,实现高效率、低成本地对海量政府网页的在线归档和集成管理、自动化认证能力、提高审计效率等;社交媒体的网络存档兴起,国内外的研究出现较新颖的社交媒体网络资源采集,更偏重社交媒体网页归档的技术解决方案,而国内以研究国外新技术的综述较多,提出的建议较有创新性;资源利用的研究占据较大比重,大多数研究都是围绕资源利用展开,而在网页资源的采集和管理方面,对于采集的技术全面革新,主要提出网页资源的可获取性,且经过评估后的可利用性网页资源,在保存方面也提出更加智慧的解决方案,例如低成本、高效率完成海量信息的全景映射和更加完善的资源保存框架。
1)资源采集:国内外研究重点体现在社交媒体存档资源的采集,在采集机制、采集标准、采集策略和采集方法等方面予以深入剖析,在国内首次提出以“协同”的方式实现多源组织合作,但从技术方面对归档资源进行评估方面,还需要国内学者继续深入研究。
2)资源管理:国内研究在资源管理方面,主要体现在:互联网+时代带来新的资源管理方法,多方“协作”的主题词成为本阶段凸显词。国外在此阶段,资源管理方面研究较少。
3)资源利用:国内研究对于“存档资源利用”更进一步,聚焦于资源应用需求及开发利用途径两方面,除此之外,对于社交媒体的网页存档,聚焦于项目内容、开发技术和实践应用三方面。虽然,新技术应用于网页存档实现了优化项目,但也带来了更多挑战,国内对于资源利用还需要进一步挖掘。
4)系统框架:此阶段,国内外系统框架的搭建围绕“安全信息”及“归档价值”两方面展开,自动化技术应用与系统框架的搭建,解决存档数据信息不全面、用户访问效率较低的问题。除此之外,对于“归档价值”也出现了从技术和内容两方面进行解决的构想。
5 结 语
网页存档是人类网络信息资源长期保存的重要任務,时代的发展带来了众多新技术的革新问世,这也给实践项目带来了巨大挑战。首先,网页存档实践项目针对每个国家都带有特色的烙印,采集工具、采集内容、资源管理、保存方式、利用侧重点、技术开发方向、系统平台建设、法律法规标准迥异,各具特色。其次,作为网页存档实践项目责任主体,长期保存体系的构建者,又要为广大用户提供服务,需要在系统功能方面满足用户需求的同时,在法律允许的范围内,遵守知识产权以及隐私权等相关法律约束。随着各国网页归档实践项目的发展,项目过程中的各个流程都将会进一步得到深入研究。系统梳理以往的研究具有重要作用,对于日后网页存档理论及实践有启示意义。
对各国家图书馆或档案馆而言,网页存档实践项目是技术与资源及人工共同结合的一项工程,网页存档实践项目发展的方向,始终是指向“资源深层开发利用”环节,提高资源利用率是最终核心问题。理论模型、系统框架、技术革新、资源采集方式、归档资源评估、资源开发利用及人工配置,七者交融但又相互促进。后续的相关研究中,可以根据这五方面特点,开展更为深入的探索。
参考文献
[1]中国互联网络信息中心(CNNIC).第47次中国互联网络发展状况统计报告[R].2021-02-03.
[2]阳广元.国内外Web Archive研究综述[J].图书馆杂志,2014,33(10):88-94.
[3]杨道玲.Web资源保存现状与思考[J].图书馆杂志,2004,(10):32-36.
[4]阳广元.国外Web Archive研究进展及启示[J].图书馆工作与研究,2016,(6):18-21.
[5]黄新平,王萍.国内外近年Web Archive技术研究与应用进展[J].图书馆学研究,2016,(18):30-35.
[6]Developers.Internet Archive[EB/OL].https://archive.readme.io/docs,2021-09-08.
[7]Pandora[EB/OL].http://pandora.nla.gov.au/,2021-09-08.
[8]李华,吴振新,郭家义,等.Web Archive发展历程与发展趋势研究[J].现代图书情报技术,2009,3(1):1-10.
[9]National Library of Sweden.Kulturarw3[EB/OL].https://www.kb.se/hitta-och-bestall/hitta-i-samlingarna/kulturarw3.html,2021-09-08.
[10]Library of Congress.Minerva[EB/OL].https://www.loc.gov/services-and-programs/,2021-09-08.
[11]National Library.New Zealand Web Archive[EB/OL].https://natlib.govt.nz/collections/a-z-of-all-collections/nz-web-archive,2021-09-08.
[12]Paradigma[EB/OL].https://netpreserve.org/about-us/members/nasjonalbiblioteket-national-library-norway/,2021-09-08.
[13]UKdomain[EB/OL].https://netpreserve.org/about-us/members/national-archives-uk/,2021-09-08.
[14]趙丽琴.我国网络信息保存研究述评[J].图书馆学研究:应用版,2011.
[15]杨道玲.中文网络信息资源保存问题探讨[J].档案学研究,2006,89(3):39-42.
[16]黄新平.基于云计算的政府网站网页在线归档管理平台构建研究[J].中国档案,2020,559(5):67-67.
[17]张炜,董晓莉.以区块链促进协作保存网络环境下信息资源的可信性[J].国家图书馆学刊,2018,27(5):89-98.
[18]吴硕娜,黄新荣.Web归档生命周期模型的发展研究[J].数字图书馆论坛,2018,173(10):43-47.
[19]刘家真.创建我国网上信息资源库的构想[C]//中国图书馆学学术年会,2000.
[20]杨道玲.Web资源采集与保存研究[D].武汉:武汉大学.
[21]李春明,吕伟.网络信息资源专题存档试验研究[J].国家图书馆学刊,2004,(2):34-37.
[22]赵俊玲.国外关于网络信息资源保存的研究[J].中国图书馆学报,2004,30(3):80-83.
[23]赵俊玲.美国国会图书馆网络信息保存项目Minerva及启示[J].图书馆建设,2005,(5):40-42.
[24]Hiiragi W,Sakaguchi T,Sugimoto S,et al.A Policy-Based System for Institutional Web Archiving[C]//International Conference on Asian Digital Libraries.Springer,Berlin,Heidelberg,2004.
[25]Gossen G,Demidova E,Risse T.iCrawl:Improving the Freshness of Web Collections By Integrating Social Web and Focused Web Crawling[J].ACM,2016.
[26]陈为东,王萍,王益成,等.面向Web Archive的社交媒体信息采集工具比较研究[J].图书馆学研究,2017,(13):10-16.
[27]张卫东,黄新平.面向Web Archive的社交媒体信息采集——基于ARCOMEM项目的案例分析[J].情报资料工作,2017,(1):94-99.
[28]陈清文.网络信息资源保存研究综述[J].山东图书馆学刊,2006,(1):18-21.
[29]王志庚,郝守真.网络文献保存的实践和课题[J].国家图书馆学刊,2004,(2):23-29.
[30]陈清文,黄田青.网络学术信息资源呈缴保存制度研究[J].图书馆,2008,(3):36-37.
[31]杨智勇,曹航.网页资源长期保存的标准和技术研究[J].档案,2011,(3):41-44.
[32]赵俊玲,杜国芳.著作权法对网络信息资源保存的影响分析[J].现代情报,2005,25(5):72-74.
[33]卢宏.参考文献中引用网络信息资源的思考[J].图书情报工作,2005,(5):121-123.
[34]陈清文.网络信息资源长期保存的采集策略与方法[J].情报探索,2006,(12):47-48.
[35]Yang G,Bin R,Yue R.Reputation-based Contents Crawling in Web Archiving System[C]//International Symposium on Operations Research and Its Applications;ISORA08.Hiroyuki Kawano@Nanzan University,Aichi 4890863,2008.
[36]Kim Y S.A Study of Legal Issues for Web Archiving[J].Journal of the Korean Society for Library and Information Science,2007,41(3).
[37]趙生辉.中国少数民族语言网络信息资源的保存体系研究[J].情报资料工作,2012,(2):59-64.
[38]廖思琴,周宇,胡翠红.基于云存储的政府网络信息资源保存型元数据研究[J].情报杂志,2012,31(4):143-147.
[39]王智刚.数字图书馆网络信息资源保存风险评估及控制技术研究[J].信息系统工程,2015,(2):12.
[40]孙红蕾,郑建明.互联网信息资源长期协作保存机制研究[J].图书馆学研究,2017,(10):20-25.
[41]Thelwall M,Vaughan L.A Fair History of the Web Examining Country Balance in the Internet Archive[J].Library & Information Ence Research,2005,26(2):162-176.
[42]Archival Tools to Match the Web:Open,International,Comprehensive[C]//International Conference on Asian Digital Libraries.Springer,Berlin,Heidelberg,2007.
[43]龙正义.网页长期保存的策略与方法研究[J].档案管理,2010,(3):20-23.
[44]王芳,史海燕.国外Web Archive研究与实践进展[J].中国图书馆学报,2013,39(2):36-45.
[45]王萍,黄新平,张楠雪.国外Web Archive资源开发利用的途径及趋势展望[J].图书馆学研究,2015,(23):43-49.
[46]黄新平.欧盟FP7社交媒体信息长期保存项目比较与借鉴[J].图书馆学研究,2019,460(17):4-11.
[47]黄新平.基于云计算的政府网站网页在线归档管理平台构建研究[J].中国档案,2020,559(5):67-67.
[48]Kawano H.Web Archiving Strategies By Using Web Mining Techniques[C]//Communications,Computers and Signal Processing,2003.PACRIM.2003 IEEE Pacific Rim Conferenceon.IEEE,2003.
[49]Wang W,Chen D I,Lin S.Web Archaeology Research on Several Chinas Main.com Websites1.
[50]Fattah M A,Ren F,Shingo K.[IEEE International Conference on Information Technology:Coding and Computing,2004.Proceedings.ITCC 2004.-Las Vegas,NV,USA(2004.04.5-2004.04.7)]International Conference on Information Technology:Coding and Computing,2004.Proceedings.ITCC 2004[J].2004,2:298-302.
[51]Goodkin J,Cobb J,Pearcemoses R,et al.Technical Architecture Overview:Tools for Acquisition,Packaging and Ingest of Web Objects Into Multiple Repositories[C]//ACM.ACM,2006.
[52]Kim H J,Lee H W.Development of Metadata Elements for Intensive Web Archiving[J].Journal of the Korean Society for Information Management,2007,24(2):143-160.
[53]Wu P H J,Heok A K H,Tamsir I P.Annotating the Web Archives-An Exploration of Web Archives Cataloging and Semantic Web[C]//International Conference on Asian Digital Libraries(ICADL 2006).Nanyang Technological University 31 Nanyang Link,2006.
[54]A Study on Web Archives Design:The Description and the Format Approach[J].Archiving Conference,2008.
[55]Crook E.Web Archiving in a Web 2.0 World[J].The Electronic Library,2009,27(5).
[56]Saad M B,Pehlivan Z,Gangarski S.Coherence-Oriented Crawling and Navigation Using Patterns for Web Archives[C]//TPDL2011;International Conference on Theory and Practice of Digital Libraries.LIP6,University P.and M.Curie,4 Place Jussieu 75005,Paris,France;LIP6,University P.and M.Curie,4 place Jussieu 75005,Paris,France;LIP6,University P.and M.Curie,4 place Jussieu 75005,Paris,France,2011.
[57]Phillips M E,Murray K R.Improving Access to Web Archives Through Innovative Analysis of PDF Content[C]//2013:186-192.
[58]Jatowt A,Kawai Y.Special Section on Data Engineering Page History Explorer:Visualizing and Comparing Page Histories.
[59]张炜,董晓莉.以区块链促进协作保存网络环境下信息资源的可信性[J].国家图书馆学刊,2018,27(5):89-98.
[60]Pavlos F,Helge H,Vaibhav K,et al.Building and Querying Semantic Layers for Web Archives[J].International Journal on Digital Libraries,2018:1-19.
[61]Lor P,Britz J.A Moral Perspective on South-North Web Archiving[J].Journal of Information Science,2004,30(6):540-549.
[62]Choi K H,Jeon D J.A Web Archiving System of the National Library of Korea:OASIS[C]//Digital Libraries:Achievements,Challenges and Opportunities;Lecture Notes in Computer Science;4312.National Library of Korea,Seoul,Republic of Korea,2006
[63]劉进军.中文网络信息资源保存权益主体分析[J].图书馆学研究,2007,(12):26-28.
[64]Anand A,Bedathur S,Berberich K,et al.EverLast:A Distributed Architecture for Preserving the Web[C]//ACM.ACM,2012.
[65]杨元香.归档网络信息价值判断研究[D].湘潭:湘潭大学,2012.
[66]Noh Y H,Go Y S.A Study on Improving the OASIS Selection Guidelines[J].Journal of the Korean Biblia Society for Library & Informationence,2012,23(3):217-222.
[67]Banos V,Manolopoulos Y.Web Content Management Systems Archivability[J].Springer International Publishing,2015.
[68]吴振新,胡吉颖,张智雄,等.基于IIPC开源软件拓展构建国际重要科研机构Web存档系统[J].现代图书情报技术,2015,31(4):1-9.
[69]胡吉颖,吴振新,谢靖,等.构建面向WARC文档的全文索引系统[J].现代图书情报技术,2016,32(5):91-98.
[70]吴硕娜,黄新荣.Web归档生命周期模型的发展研究[J].数字图书馆论坛,2018,173(10):43-47.
(责任编辑:郭沫含)
