
面向建设期铁路大数据的分级存储方法研究
2022-03-30 03:45廉小亲程智博王万齐吴艳华
铁路计算机应用 2022年2期
廉小亲,杨 凯,程智博,王万齐,3,吴艳华
(1. 北京工商大学 人工智能学院,北京 100048;2. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;3. 国家铁路智能运输系统工程技术研究中心,北京 100081)
我国铁路正快步迈入大数据时代[1],铁路系统的数据总量己达到10 PB数量级[2],其中,包含大量铁路路段建设期的数据[3]。然而,在传统的单节点数据存储模式下,数据访问效率和存储介质性能较低[4],因此,需要搭建一种分布式的数据分级存储系统[5],并建立相应的数据评价体系[6],来实现业务层面的数据高效分级存储。
铁路大数据的分级存储问题是当前的研究热点[7]之一。郭歌等人[8]以铁路基础设施各阶段用例为中心,通过对铁路基础设施数据进行层次化分析,形成一个可支撑铁路全生命周期应用的数据共享模型体系;王沛然等人[9]设计了一种铁路大数据服务平台存储架构,针对不同业务、不同类型的数据采用不同的数据库进行存储,并根据数据的访问频次将数据分为冷数据和热数据;彭剑峰等人[10]从铁路大数据的敏感度特点出发,从多个维度对铁路大数据进行分类分级。
本文分析了铁路建设期大数据的存储与管理需求[11],以海量建设期数据为研究对象,设计面向多源、异域、跨系统、多类型数据的分级存储架构及策略,有效提高数据的访问效率及数据库的利用率,增强平台存储性能、降低存储成本。
1 分级存储架构设计
1.1 主流大数据分级存储架构
目前主流的大数据分级存储系统通常以数据的生命周期为依据,将数据库划分为在线存储数据库、近线存储数据库及离线存储数据库,其存储架构如图1所示。

图1 主流大数据分级存储架构
在线存储数据库用来存储当前访问频率最高的热数据,以便数据申请者得到快捷、及时的响应。为保证更好的数据访问性能,在线存储数据库多采用性能较高的存储设备[12],例如固态硬盘等。近线存储数据库主要用来存储访问频次相对较低的温数据,且对访问速度要求较低,因此,近线存储设备往往具有较高的存储容量,同时,在可接受的时间范围内向用户反馈数据,主要采用磁带库或低端磁盘设备。离线数据主要用来存储访问频率最低的冷数据,这部分数据很少再被访问到,主要采用光盘、磁带库等设备[13]。
1.2 铁路建设期大数据分级存储架构
铁路建设期业务繁多,数据种类复杂[14],从数据类型角度看,包含结构化数据、半结构化数据和非结构化数据,且数据量日渐庞大,原有的大型计算机基于此类存储任务的负荷也越来越重,目前,将计算机组成集群对海量多源异构数据进行分级存储是一种可行、可靠、高效的模式[15]。本文在图1所示的分级存储架构基础上,结合铁路建设期系统的业务特征,搭建了一种基于非关系型数据库、关系型数据库及分布式文件系统的铁路建设期大数据分级存储架构,并在中间件判定该数据对应的存储级别,使得数据能够合理的存放在指定数据库中,存储架构如图2所示。
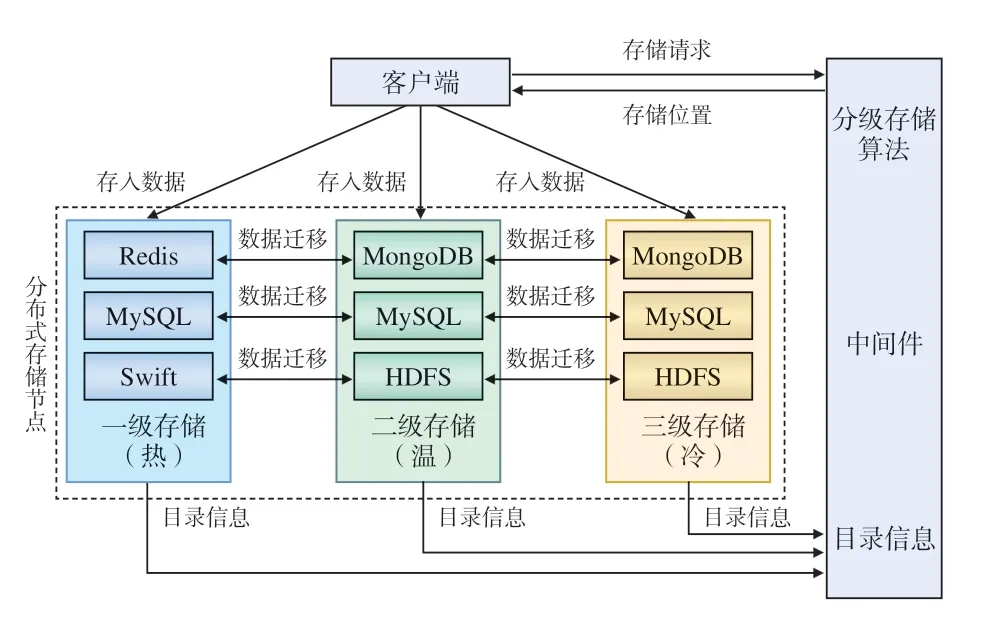
图2 铁路大数据分级存储架构
铁路大数据分级存储系统架构包括客户端、中间件及分布式存储节点3部分。其中,分布式存储节点包含三级存储,一级存储节点中包含Redis数据库、MySQL数据库和Swift分布式文件系统,以存储铁路建设期的热数据;二级和三级存储节点中包含MongoDB、MySQL数据库和HDFS,分别存储铁路建设期的温数据和冷数据。
当客户端产生的数据需要进行存储时,向中间件提交存储请求,该存储请求包含数据格式、数据大小、数据所属业务系统等基本信息,中间件中的铁路大数据分级存储算法会根据上述基本信息和当前存储系统中各级存储的目录信息计算数据价值,判定该数据对应的存储级别,并反馈至客户端,客户端即可根据存储级别确定存储位置,将数据存放至指定的数据库中,从而实现数据的分级存储。
2 分级存储算法
2.1 分级存储需求
铁路大数据中的建设期数据包含进度、质量、统计汇总、评估预测等多方面数据,具有数据量大、涵盖范围广、业务类别多、数据类型杂及产生频率高的特点,仅从单一维度对数据进行级别划分存在一定的局限性。因此,亟需针对建设期铁路数据的业务特点,建立一种多维度、综合性的铁路建设期大数据分级体系和价值评价体系,以实现铁路大数据分级存储算法。
2.2 数据价值评价体系
本文以建设期结构化数据中的数据表为评价对象,根据铁路建设期大数据特有的业务价值特点,提出以下评价指标,构建数据价值评价体系,如图3所示。一级指标为数据表的数据价值;二级指标在一级指标的基础上划分为数据表业务特征指标和数据库/数据表的自身属性特征指标;三级指标既包含定性评价指标,也包含定量评价指标,定量评价指标为数据库数据量大小指标、数据库“增”行为操作量指标、数据库“删”行为操作量指标、数据库“改”行为操作量指标和数据库“查”行为操作量指标,此类指标数值定期通过日志文件进行更新。其余的三级指标均为定性评价指标,本文采用专家评价法对其进行价值判定[16],基本操作流程为:(1)对三级定性评价指标下的四级指标进行打分;(2)对四级指标的权重值进行打分;(3)以加权求和方式得到三级指标中定性指标的结果。
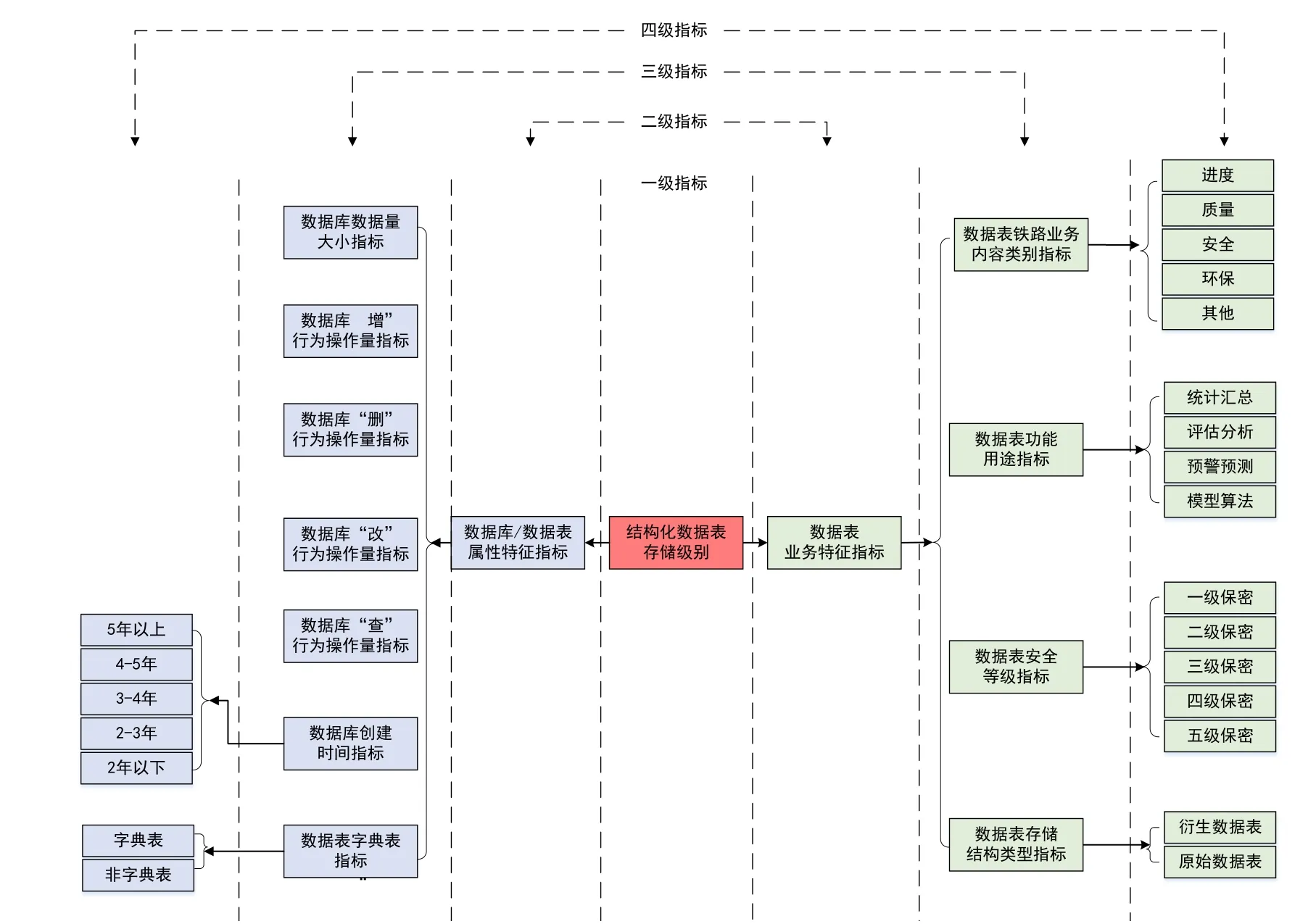
图3 建设期铁路大数据价值评价体系
2.3 基于K-means的数据价值判定算法
由2.2节可知,在数据价值评价体系中,每一张数据表均通过专家评价法和日志文件统计分析得到一组三级指标打分结果,而数据价值评价体系的一级指标为数据表的价值,因此需要建立数据表的价值与存储级别之间的非线性映射关系,并根据数据表一级指标的统计信息决定数据表所在的存储级别。
K-means聚类分析[17]是数据挖掘[18]中重要的无监督学习算法之一。与监督学习不同的是,该算法待处理的样本数据集中没有包含样本分类相关信息。聚类是把数据集中的对象划分成多个簇的过程,被广泛应用于模式分类等领域。K-means算法简单便捷、收敛速度快,在大数据分级存储中使用能有效减少计算时间、提高存储效率。故本文采用K-means聚类算法建立上述映射关系。
设定原始数据表三级指标矩阵V为:

其中,vji为第j(j=0,1,···,m−1)个数据表中第i(i=0,1,···,n−1)个三级指标的分值;m为数据表数量;n为三级指标数量。由于三级指标评价结果包含定性评价结果和定量评价结果,需要在同一评价指标维度下对各维度的数据进行归一化处理,以消除数据量纲,同时,也可减小由于数据量级差导致的聚类误差。三级指标归一化矩阵K如公式(2)所示。
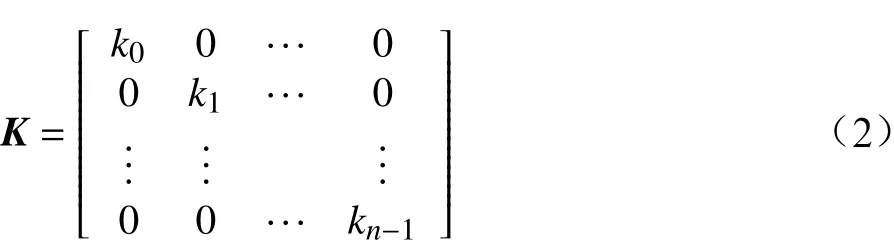
其中,ki表示第i+1个评价维度的归一化尺度因子。归一化后的三级指标矩阵X为:
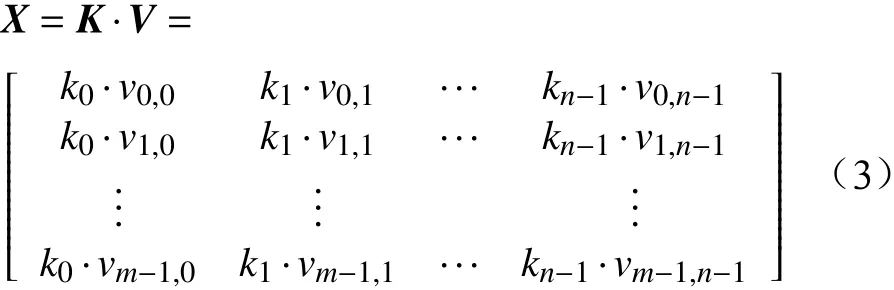
对矩阵X进行K-means聚类。由于本文搭建的数据分级存储系统中包含三级存储节点,因此,设聚类中心数量为3,聚类标签集合为{“0”,“1”,“2”},设聚类后输出结果向量为Y,K-means聚类模型为F(·),第j个数据表聚类结果为yj,则有:
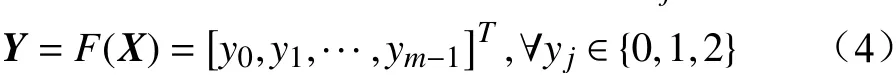
分别统计每一组聚类空间内所有样本归一化后三级指标各维度值的加权平均值Vp,如公式(5)所示。
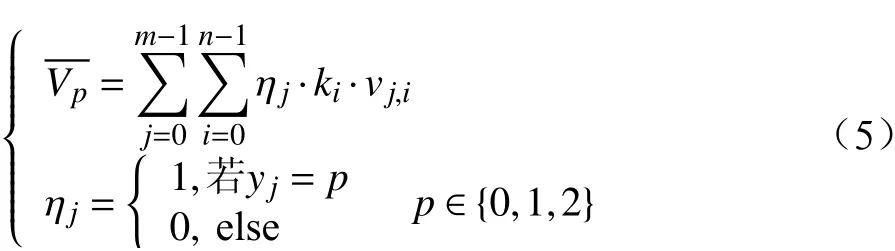
3 实验验证
为实现建设期铁路大数据的分级存储,本文搭建了基于NoSQL、RDB和DFS的分布式存储系统,以建设期铁路大数据中的结构化数据为主要研究对象,建立一套铁路大数据价值评价体系,通过Kmeans聚类算法判定各类数据相应的存储级别。其中,价值评价体系的可靠性和K-means聚类算法结果的准确性决定了本文提出方法的可行性和可靠性。
本节以脱敏后的铁路建设期数据表和相应的访问日志为实验样本,确定数据表在数据价值评价体系中各指标的专家评价结果及指标分值,利用Kmeans聚类算法判定数据表的分级存储结果。
3.1 数据价值评价体系四级指标打分结果
本文以四级指标为评价维度,721张数据表的专家评价结果(部分)如表1所示,评价结果为“1”表明该数据表具有该项四级指标特征,评价结果为“0”表示该数据表不具有该项四级指标特征。

表1 四级指标专家评价结果(部分)
3.2 数据价值评价体系四级指标权重打分结果
通过专家评价法对数据价值评价体系中的四级指标分值进行打分,打分结果如表2所示。

表2 四级指标分值专家打分结果
3.3 数据价值评价体系三级指标数值计算结果
对表1和表2的评价结果进行加权求和,并对日志数据进行统计分析,计算所有实验样本的三级指标结果,如表3所示。表3中的指标1、2、3、4、9、10、11分别指代二级指标下差异较大的各项三级指标。
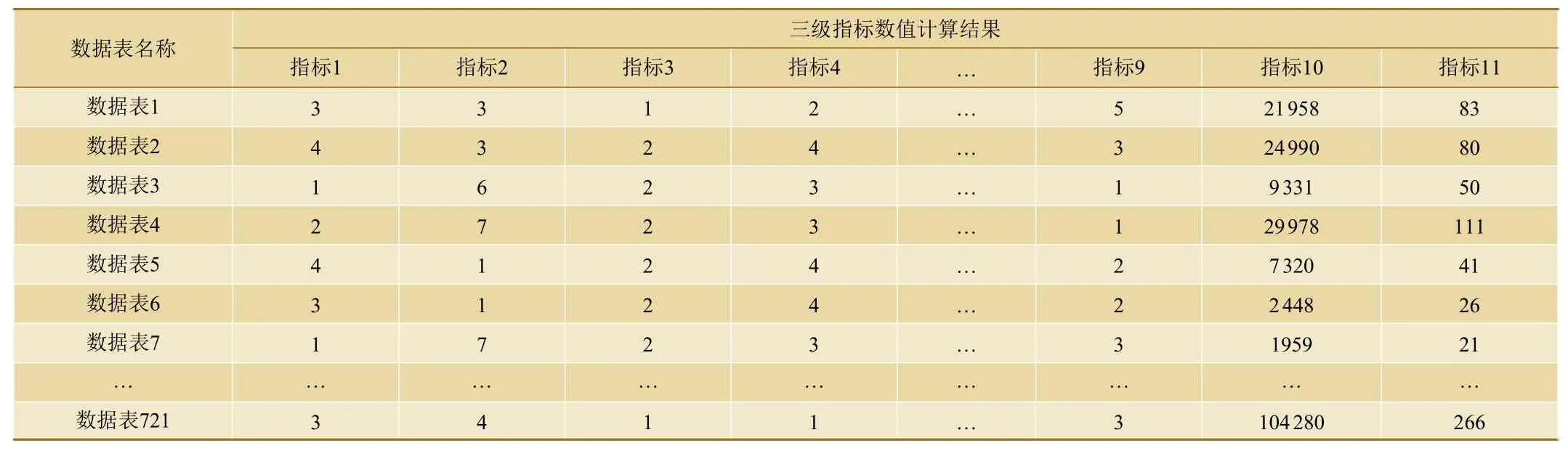
表3 三级指标数值计算结果
3.4 K-means聚类结果及分析
对表3中的三级指标数值计算结果进行归一化处理,以{“0”, “1”, “2”}作为聚类结果标签进行K-means聚类。聚类结果分布如图4所示,将数据表三级指标各指标值求和即可得到各数据表的数据价值,数据价值分布如图5所示。

图4 数据聚类结果分布情况
图5 数据价值分布情况
由图4和图5可知,标签“0”的数据价值相对分布明显高于标签“2”,标签“2”的数据价值相对分布明显高于标签“1”,未出现明显误差,验证了K-means聚类结果的准确性。
按照公式(5)分别统计每一组聚类空间内所有样本归一化后三级指标各维度值的加权平均值经计算,可知,标签为“0”的数据表应存放至一级存储节点,标签为“2”的数据表应存放至二级存储节点,标签为“1”的数据表应存放至三级存储节点。
4 结束语
本文结合了计算机领域数据分级存储的思想,设计了一种面向建设期数据的铁路分布式大数据分级存储架构和分级存储算法,实现建设期铁路大数据分级存储,提高数据的访问效率及数据库的利用效率,增强平台存储性能,降低存储成本。实验结果表明,本文提出的数据价值评价体系和分级存储算法能够有效的对建设期铁路大数据进行存储级别判定,为后续理论内容的工程化应用提供技术基础。
本文也存在一定的不足之处,例如,本文提出的数据价值评价体系中,采用专家评价法进行打分,最终的计算结果很大程度上与打分人对指标的主观判断有关联。因此,在后续研究过程中,可考虑采用主观判断和客观分析相结合的方式,共同决定评价指标的最终取值,以此提高评价体系的可靠性。
猜你喜欢
趣味(语文)(2021年10期)2021-12-28
趣味(作文与阅读)(2021年10期)2021-03-08
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
商情(2019年12期)2019-06-13
科技创新导报(2016年33期)2017-04-22
建材发展导向(2017年1期)2017-03-24
中国总会计师(2015年5期)2015-06-16
中学生英语·阅读与写作(2014年11期)2015-03-11
