
基于机器学习的页岩油藏合理焖井时间预测
2022-04-01 11:38杨红梅马磊磊冯志强
西安石油大学学报(自然科学版) 2022年2期
杨红梅,薛 敏,杨 泱,马磊磊,冯志强
(1.长治市综合检验检测中心,山西 长治 046000; 2.中国石油长庆油田 油气工艺研究院,陕西 西安 710016; 3.西南石油大学 石油与天然气工程学院,四川 成都 610500)
引 言
为了提升页岩油藏的开发效果,近年来水力压裂结合焖井的开发方式在各油田逐步得到应用[1-6]。然而在焖井开发过程中,合理焖井时间难以确定,影响因素众多,且数值模拟计算时间长,计算成本高,这些问题增加了制定合理焖井开发方案的难度[7-9]。近年来,随着机器学习方法的不断发展,油气领域的机器学习应用也快速兴起[10-16]。相较于传统数值模拟方法,机器学习模型一旦训练完成,预测新样本的时间仅需数秒,大大节省了计算成本[17],且训练完成的机器学习模型可以直观地展现输入参数对输出参数的影响程度[18],可为实际焖井方案设计提供理论参考。然而目前针对页岩油储层焖井作业,尤其是如何选取合理的焖井时间,尚未发现相关机器学习研究,机器学习模型在该问题上的适用性与准确性尚未得到验证,亟需进一步的探索研究。
为了确定页岩油藏开发的合理焖井时间,以中国西北某页岩油藏Y区块268口生产井为训练样本,建立了不同机器学习方法的预测模型,包含支持向量回归、多变量线性回归以及多层神经网络方法,并通过预测准确率对比,确定不同模型在该样本条件下的模型适用性与预测准确性。通过提取模型训练完成后的相关系数,可以了解到不同输入参数对合理焖井时间的影响。以Y区块X-1水平井为例,进行了焖井时间优化,对比优化前后的产量数据,为现场实际开发提供一定的指导意义。
1 学习样本库的生成
机器学习过程中,合理的数据模型设计与学习样本构建有助于提升模型预测的准确性。然而油田现场提供的数据体存在诸多问题,无法直接运用于机器学习模型中。首先,部分数据缺失严重,且需进行降噪处理;其次,虽然Y区块大部分生产井都进行了焖井作业,然而该焖井时间可能并非是该储层条件下的最优焖井方案,直接使用会有降低模型适用性的风险;此外,现场施工存在较多随机措施,包括关井维修、动液面调整等,这些临时性措施对于该井最终生产效果存在不确定性影响。对于数据集中关键的合理焖井时间,需利用数值模拟进行对比优选得出。
合理焖井时间的数值模拟优选,采用油藏数值模拟程序MRST。合理焖井时间优选步骤如下:①汇总所有生产井的储层物性参数与施工参数;②针对某一生产井,首先加载基础物性参数,并利用MRST提供的嵌入式离散裂缝模块,自动构建相应条数的压裂裂缝;③依照对应生产井的施工参数,进行模型其他参数自动赋值;④分别计算焖井0 d,40 d,80 d和120 d后,连续生产1 000 d的累产油量;⑤对比累产油量,寻找累产油量产量峰值点;⑥假设焖井80 d对应累产油量最高,则额外计算焖井60 d与100 d的累产油量,之后对比焖井40 d,60 d,80 d,100 d和120 d后的累产油量,继续寻找累产量峰值点,并循环该步骤4次,所找到的最终累产峰值点对应的焖井时间即认为合理焖井时间;⑦返回该井的合理焖井时间优选结果,调取下一口井的数据,循环步骤①至⑥。通过以上步骤,即可得到268口生产井所对应的合理焖井时间,可生成数据应用于机器学习模型中。
以Y区块生产水平井X-27为例,其优选步骤如图1所示。第一轮对比发现焖井80 d累产量最高,为8 123.5 t; 增加焖井60 d以及100 d的算例后,最优焖井时间为60 d,累产油量为8 199.3 t;增加了焖井50 d以及70 d的算例后,最优焖井时间仍为60 d;增加焖井55 d以及65 d的算例后,最优焖井时间仍为60 d;增加了焖井58 d以及63 d的算例后,最优焖井时间为58 d,累产油量为8 208.6 t;增加焖井57 d以及焖井59 d算例后,最优焖井时间为59 d,累产油量为8 214.6 t。因此该井合理焖井时间为59 d,对应优化后的平面含油饱和度分布如图1中所示。
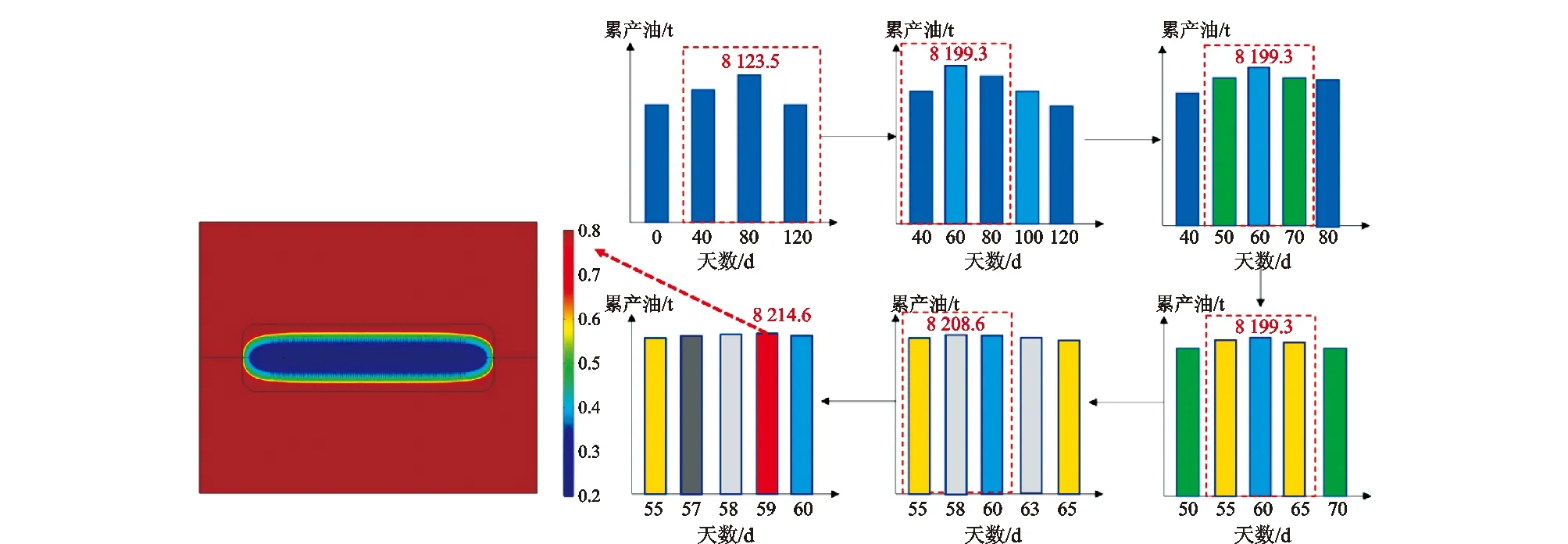
图1 Y区块生产水平井X-27最优焖井时间优选步骤与优选后含油饱和度分布
由于机器学习模型的输入参数数量有限,因此在模型构建之前,还需要进行输入参数的筛选,目的在于选出能够影响焖井效果的主要因素,筛选标准为实际提供的样本数据以及其对计算结果的影响程度。经过筛选,11个参数被选为输入参数,分别为渗透率、孔隙度、加砂量、入地液量、动液面、初始含油饱和度、油相黏度、毛管力曲线中位数、储层有效厚度、裂缝簇间距以及裂缝簇数。其中毛管力曲线中位数是指毛管力曲线在油相饱和度为0.5时的毛管力数值,用于反映整体毛管力的大小。Y区块268口生产井输入参数汇总如表1所示。机器学习模型的输出参数为生产井的合理焖井时间,因此该问题为典型的回归问题。
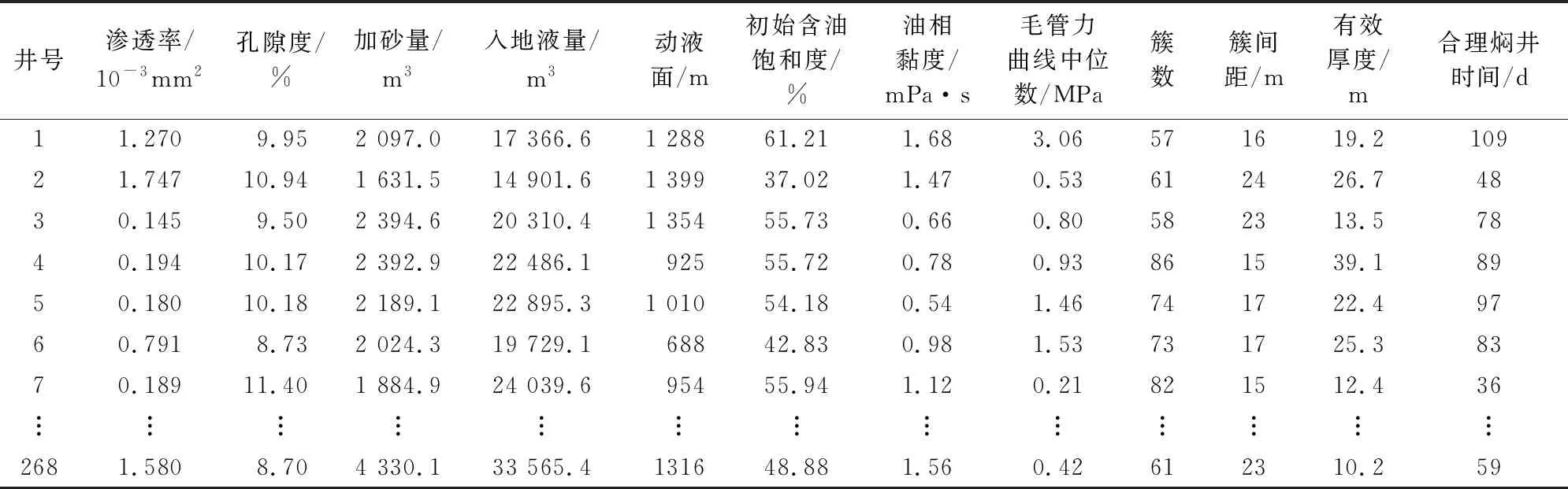
表1 Y区块各生产井的机器学习分析样本
为了减小不同输入参数之间量纲与数值的差异对于机器学习结果的影响,所有输入参数在使用之前都需进行标准化。变换表达式遵循Z-score标准化方法[17],即
(1)
式中,δ代表某一输入参数所有样本数据的均值;μ代表该输入参数所有样本数据的标准差;X代表原始样本数据;X′代表经过标准化之后的样本数据。
在得到数据集后,需要对数据集样本进行划分,分别得到训练集与测试集,以便进行交叉验证,确保模型准确性。Y区块268口生产井划分为2部分,其中200口井作为训练集,用于模型训练,余下68口生产井数据用于验证与测试,用于评估模型的预测表现。
2 基于机器学习的合理焖井时间预测模型建立
2.1 机器学习方法选择
针对多输入参数的回归问题,模型构建分别采用三种不同的主流学习方法,分别为支持向量回归(SVR),多变量线性回归(MLR)以及多层神经网络方法(MPN)。
支持向量回归是支持向量机的一种变体[19],相较于经典支持向量机方法只能处理分类问题的缺点,支持向量回归可以用于回归问题的处理。对于回归问题,其求解目标是使得模型输出f(x)与真实值y尽可能的接近。常用回归方法一般规定只有当f(x)与y完全相同时,损失才为零。相较之下支持向量回归则假设模型能够容忍f(x)与y之间存在最大误差e,当且仅当f(x)与y的差别绝对值大于e时,才计算损失。相当于以f(x)为中心,构建一个宽度为2e的间隔带,若训练样本落入此间隔带,则认为是被预测正确的,其中间隔带两侧的松弛程度可有所不同。该方法在数据集较小情况下,其预测效果往往要优于传统神经网络方法,因此具有较广的工程应用。
多变量线性回归是经典线性回归法的变体,是使用线性方程对数据集进行拟合的方法,由于工程问题往往不止一个输入特征,因此相较于传统线性回归方法,具有更为广泛的应用[20]。在该方法中,首先针对每一组输入输出数据,需要通过拟合确定最为合适的数学关系,表示为
f(xi)=α+β1xi(1)+β2xi(2)+…+βmxi(m)。
(2)
式中,xi(j)代表第i组数据中的第j个输入参数;f(x)代表该组数据计算出的输出参数;a为拟合参数;βj代表第i组数据中第j个输入参数的拟合参数。
在得到单组数据拟合结果之后,需要通过迭代得到适用于所有数据样本的函数关系拟合参数,并最终得到最优拟合结果,即
(3)
式中,E代表拟合函数;yi代表实际数值,n代表样本数量。
多层神经网络由输入层、隐含层与输出层组成,每个隐含层中包含诸多胞体。简单而言,多层神经网络通过不断自我迭代,更新隐含层中不同输入参数的权重,使得模型整体的回归准确率达到最优,该方法在较大样本数量的条件下往往具有优异的计算表现。针对单组样本的神经网络计算公式[18]为
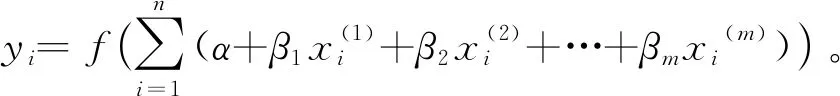
(4)
式中,f代表激活函数;yi代表模型的输出参数。
2.2 模型构建步骤与评价方法
以神经网络为例,基于机器学习方法的页岩油藏开发合理焖井时间预测模型构建方法如下:①首先,获取Y区块268口生产井的原始数据,包括储层物性参数与压裂施工参数,进行数据预处理,对缺失数据进行补充,对部分错误数据进行合理修正; ②按照上文提到的方法进行268口生产井的合理焖井时间数值模拟优选,并与处理后的各生产井物性参数、压裂施工参数共同生成机器学习数据集待用;③将数据集中的数值进行标准化处理,并划分为机器学习训练集与验证集;④设计并构建机器学习模型,其中,模型输入参数为孔隙度、渗透率、加砂量等11个参数,输出参数为焖井时间;⑤开始机器学习训练,训练过程中模型通过自我迭代,不断调整不同输入参数在模型中的权重,从而达到理想的训练准确率;⑥模型训练完成,将验证集中68口井的参数输入至训练好的模型中,得到模型预测出的68口生产井的合理焖井时间;⑦将模型预测的68口生产井的最优焖井时间与测试集中的原有数据进行对比,进而对模型预测表现进行评价。模型的具体构建流程如图2所示。其中支持向量回归与多变量线性回归模型的构建基于开源机器学习接口scikit-learn,多层神经网络模型的构建基于开源人工神经网络库Keras。
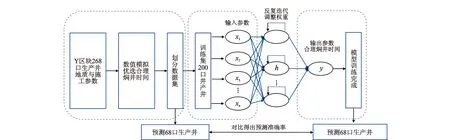
图2 合理焖井时间的机器学习预测模型构建流程
对于机器学习模型而言,模型优劣的评价主要依赖于模型准确率的高低。本文模型准确率的评价遵循决定系数R2公式[18],即
(5)
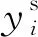
3 结果分析与讨论
3.1 不同方法预测结果评价
为了比较支持向量回归法、多层神经网络和多变量线性回归方法的实际预测效果,分别将这三种模型所预测的68口生产井的合理焖井时间与测试集中的焖井时间进行对比,计算结果分别如图3、图4和图5所示。从图中可以看出,支持向量回归法的预测效果最为理想,所有预测数据点都紧循Y=X标准线,具有较高的预测准确率,而神经网络的预测结果则略微逊色,但总体而言准确率尚可。相较而言,多变量线性回归方法预测效果不甚理想,预测数值发散在Y=X标准线两侧,预测准确率明显低于其他两种方法。
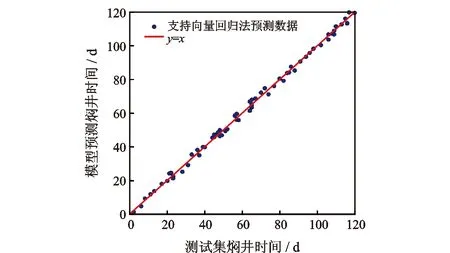
图3 支持向量回归法预测结果与测试集数据对比
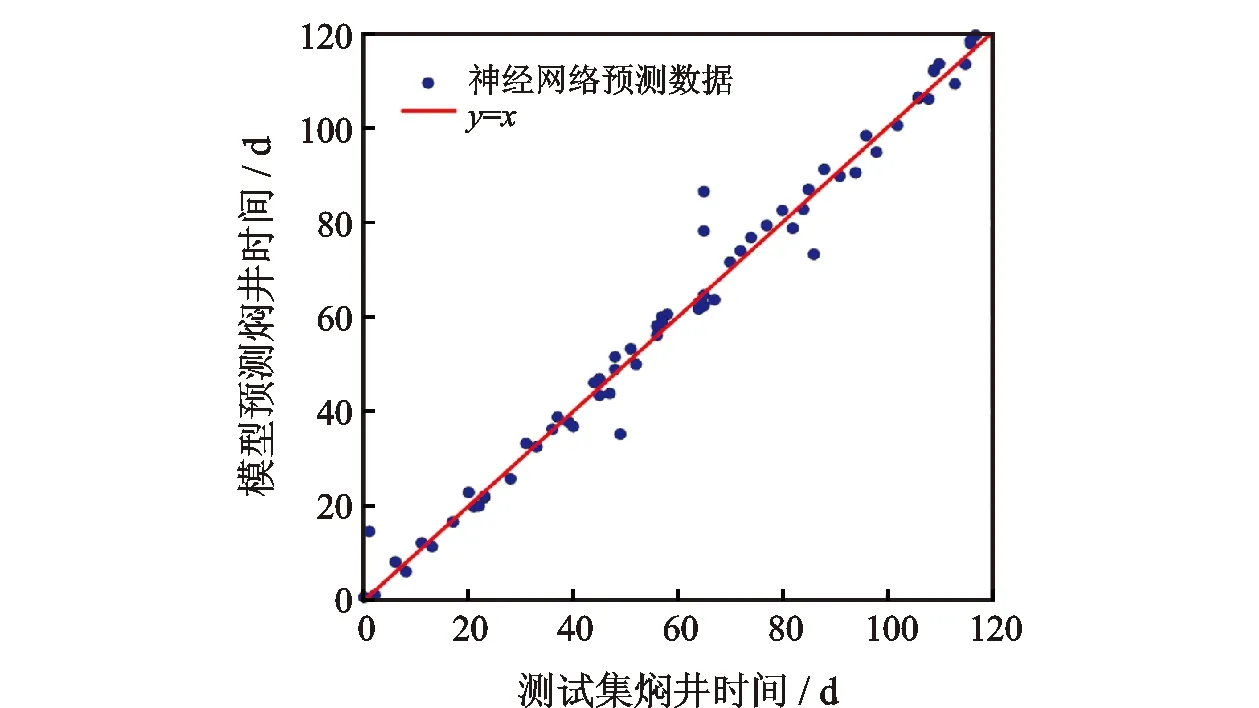
图4 多层神经网络预测结果与测试集数据对比
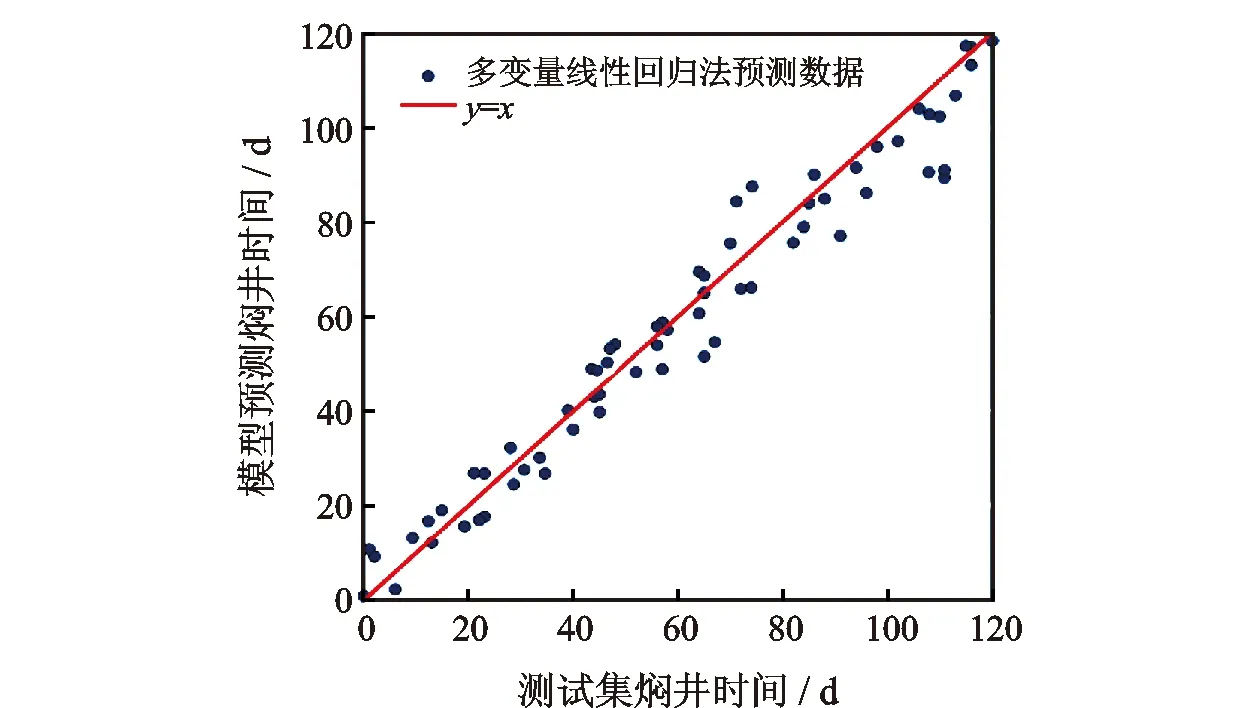
图5 多变量线性回归预测结果与测试集数据对比
表2给出了图3,图4以及图5之间的之间直观结果对比。从表中可以看出,支持向量回归、多层神经网络、多变量线性回归这3种方法在训练集中的准确率表现都较为理想,准确率均超过了97%,分别为98.6%,99.2%,97.4%,说明这3种方法都有较好的训练表现。然而,这3种方法在实际预测过程中的表现则存在差异,其中,支持向量回归与神经网络在测试集中的准确率分别为95.4%和90.3%,说明这两种方法的预测表现较为理想,神经网络的准确率要略低于支持向量回归,这主要是由于该模型的样本数量有限,若生产井的样本数量扩大,则神经网络网络的预测效果可能得到进一步提升。相较之下,多变量线性回归法在测试集中的准确率仅为78.1%,说明其预测表现较为一般,因此不推荐在该模型条件下使用。总而言之,针对页岩油井合理焖井时间的机器学习预测,支持向量回归与多层神经网络都有着较好的预测效果,具有较高的实际使用价值。
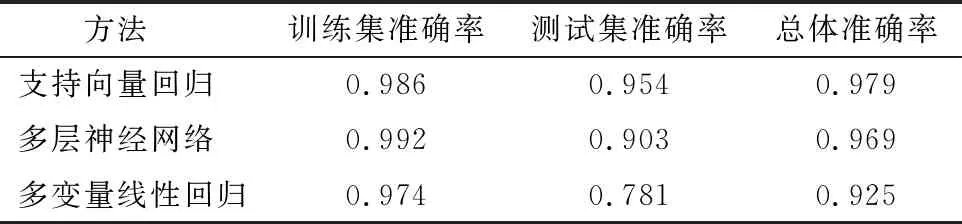
表2 Y区块不同机器学习预测方法准确性评价
3.2 页岩油藏合理焖井时间主控因素
模型训练完成后,通过提取机器学习接口scikit-learn或Keras中不同输入参数经过自我迭代得到的最终相关系数,可以了解到不同输入参数对于模型输出结果影响的大小。令所有输入参数的权重系数之和为1,若某一输入参数的相关系数越大,则说明其对输出结果的影响越大。为量化表述不同输入参数对合理焖井时间影响的强弱,按照相关系数的大小,将各输入参数进行分级处理,分别划分为主控因素、控制因素和一般影响因素,等级划分与划分依据如表3所示。

表3 影响因素重要程度划分依据
模型中11个输入参数的相关系数对比如图6所示,从图中可以看出,不同输入参数对合理焖井时间影响程度各不相同。其中,毛管力大小、入地液量和油相黏度的相关系数都超过了0.15,分别为0.202,0.170和0.159,因此这3个参数属于影响合理焖井时间的主控因素,其中毛管力大小和入地液量决定了储层中渗吸效果的强弱,而油相黏度则决定了注入液在储层中的运移难易[21-22], 这些因素都直接决定了焖井方案的效果,所以在制定焖井方案时应当予以重点关注。此外,储层渗透率、裂缝簇数以及动液面大小的相关系数都介于0.05~0.15,属于控制因素,在制定焖井方案时也应当予以考虑。相较之下,裂缝簇间距、加砂量、孔隙度、初始含油饱和度以及储层有效厚度对于合理焖井时间的影响较小,相关系数小于0.05,属于一般影响因素,在现场生产可以适当考虑。
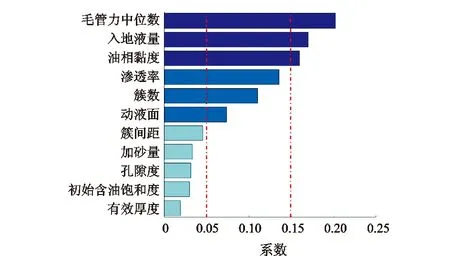
图6 不同输入参数的相关系数对比
3.3 现场实际应用
在机器学习模型完成训练,且模型预测可靠性得到了验证后,还需要将模型应用到现场实际生产中。选取中国某页岩油藏Y区块压裂水平井X-1作为优化对象,该井所需的机器学习参数如表4所示。

表4 Y区块压裂水平井X-1机器学习参数
通过井史数据可以了解到,该井在压裂施工完成后进行了43 d的焖井作业,而后开井连续生产704 d,期间产油数据如图7中黑线所示。建立数值模型,对X-1井进行产油与产水拟合以确保模型准确性,拟合后的产油曲线如图7中绿线所示。通过数值模拟焖井优化可知,该井的最优焖井时间为63 d,数值模拟焖井优化得到的累产量曲线如图7中蓝色虚线所示。将该井参数输入到训练好的机器学习模型中进行焖井时间优化,模型预测得出的最优焖井时间显示为61 d,相较实际施工中的焖井时间延长约40%,相较数值模拟优化得到的最优焖井时间,误差在3%左右。以此为依据,将数值模拟中的焖井时间调整为61 d,优化后的累产油曲线如图7中红线所示。从图中对比可以看出,数值模拟与机器学习焖井优化结果接近。进行了机器学习焖井时间优化后,生产704 d后的累积产油量较原先增长了约8.5%,具有较为可观的产量提升,体现了该机器学习模型在页岩油藏实际开发中的使用价值。
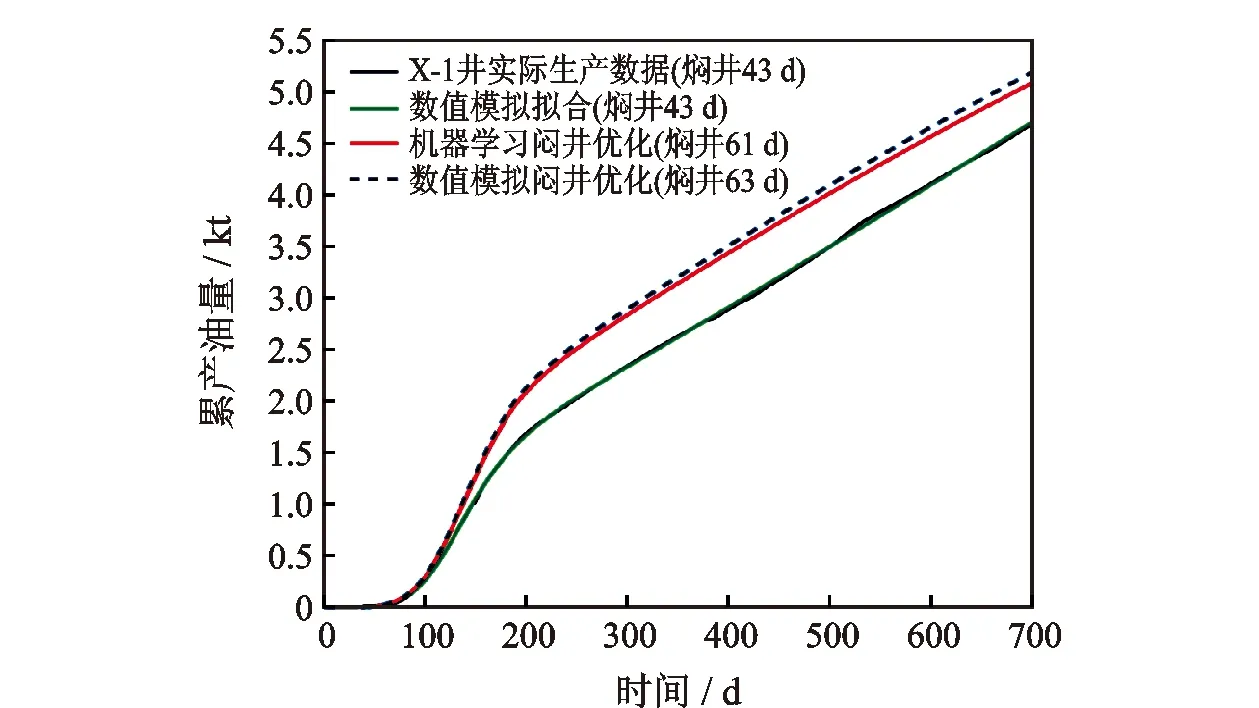
图7 Y区块压裂水平井X-1焖井时间优化前后产量对比
4 结 论
(1)支持向量回归、多层神经网络和多变量线性回归这三种方法在训练集中表现都较为理想,但在测试集中表现相差较大,预测准确率分别为95.4%,90.3%和78.1%。实际应用中,推荐使用支持向量回归和多层神经网络。
(2)毛管力大小、入地液量和油相黏度是影响合理焖井时间的主控因素,其相关系数分别为0.202,0.170和0.159; 储层渗透率、裂缝簇数以及动液面大小属于控制因素;其余因素对于合理焖井时间影响较小,属于一般影响因素。
(3)经过机器学习焖井时间优化后,生产水平井X-1在704 d的生产周期内,累产油较原先增长了约8.5%。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
环球时报(2022-07-13)2022-07-13
新高考·高一数学(2022年3期)2022-04-28
环球时报(2022-03-14)2022-03-14
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电影(2018年8期)2018-09-21
软件(2017年6期)2017-09-23
高中生学习·高三版(2016年9期)2016-05-14
