
PowerPC处理器代码执行顺序研究
2022-04-01 06:56朱强
数字通信世界 2022年3期
朱 强
(中国航空工业集团公司洛阳电光设备研究所,河南 洛阳 471000)
在型号调试过程中,遇到程序的执行顺序与CPU实际执行的顺序不完全一致的问题。经过对此问题的进一步研究,发现现代处理器和编译器会对代码的执行顺序进行一定的调整和优化。本文通过对处理器的架构、流水线执行方式以及编译器的优化原则等内容进行研究,经过查阅相关手册,通过在代码中嵌入同步指令sync以及volatile关键字可以保证代码严格按照顺序执行[1]。
在进行型号调试时,某总线时序要求先对地址A进行写操作,然后再对地址B和C分别进行一次读操作。即需要严格按照如下三行代码顺序执行:

由于CPU先执行了读操作,而后执行了写操作,与预期的执行顺序不一致,造成总线时序错误。
1 CPU处理器架构
当前,为了提高CPU处理器的处理速度、指令执行的并行度,大多数CPU都采用多级流水线、乱序执行、分支预测等技术。这些技术的应用极大提高了处理能力。
1.1 流水线技术
在以前处理器设计中,处理器在执行代码时,按照编译的汇编语言代码的顺序进行执行,这样的设计称为按序执行。
PowerPC E500核采用七级流水线技术,分别是取指令1、取指令2、指令译码、指令分发、指令执行、指令完成、结果写回。
不同的指令的执行周期不同,在e500核中,比如跳转指令单元(Branch Unit)、简单运算单元(Simple Unit)的指令可以在一个周期即可完成,而多指令单元(Multiple-cycle IU)则需要4、11甚至35个周期完成。数据加载存储指令单元(Load/store Unit)执行一般需要3个周期。如图1所示。
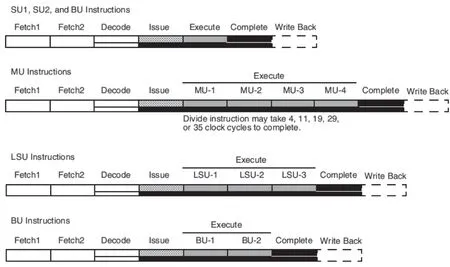
图1 PowerPC架构7级流水线架构示意图
1.2 乱序执行技术
随着处理性能要求的提高,在设计处理器时为了提高运行速度,一般会采用乱序执行技术。乱序执行技术其本质是违背了源代码按照顺序执行的原则,但是能够保证最终的运算结果与预期结果是一致的。同时,处理器还设计了多级高速缓存机制,如果在使用过程中,没有采取相应的措施,处理器最终的运算结果与我们预期的结果不同。
处理器在CACHE中取出指令,会进行相应的分析,找出相互独立的指令,并将这些相互独立的指令送到不同的逻辑单元中执行,这样提高了执行效率。而对于有相互依赖的指令,则按照顺序分别执行。
在PowerPC架构处理器中,官方文档PowerPC™e500 Core Family Reference Manual中提到,在e500核处理器中采用超标量7级流水技术,即一个时钟周期可以解析两条指令和执行完两条指令,指令的完成是按照顺序的,指令是并行执行,但是执行是可以是无序的。
需要说明的是,如果语句之间有依赖关系或者同一个时钟周期能够更新两个以上的寄存器时,则CPU不会对代码的执行顺序进行调整,官方文档对此做了说明:
在前言的案例中,如果将代码改成:

则CPU执行的顺序也会严格按照上述代码执行,这是因为前两句都是对地址0xef000000进行写操作然后再进行读操作。CPU会认为这两句是有依赖的,因此严格按照代码顺序执行。
1.3 处理器的分支预测功能
处理器为了提高同时执行指令的效率,一般会将分支条件里的指令同时取出,同时执行,等到分支条件结果计算完成后,再将错误的结果舍弃,这样可以避免多次跳转。
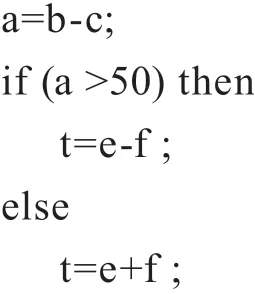
上面例子中,如果a不计算出来,t是无法继续计算的。但是实际上处理器会将三个计算同时执行,当a的值计算后再将不满足条件的结果舍弃。
在PowerPC架构处理器中同样具备分支探测和预测功能,但是处理器真正的分支执行是不可预测的,但是能够保证结果的正确性。
在某些场合下,要求CPU的代码执行严格按照汇编代码顺序执行,例如对某些硬件寄存器的读写操作,有严格的时序要求。如果CPU还是按照乱序执行,则会出现指令执行与汇编代码顺序不同步问题。
2 编译器
不仅处理器在设计时考虑乱序执行的情况,编译器同样进行乱序优化。相比处理器乱序优化,编译器乱序执行优化更有优势,因为编译器可以在很大范围内进行源代码的分析,而处理器则只能分析小部分指令,这样使得编译器能够做出更优的决策。
2.1 编译器乱序
处理器的预取单元容量和能力有限,每次分析的指令并发范围较小,但是编译器能够对大范围的代码进行整体分析,能够分析出更多的可以并发的指令,并根据处理器特点,对指令进行重排,使得处理器更容易预取和并发执行,有利于提高处理器的乱序并发执行性能。
因此,在现代的编译器中一般都具备指令乱序优化功能,同时根据指令对存储器的访问情况,对指令进行进一步优化,减少对存储器的访问,尽量控制在内部寄存器和CACHE中,提高运行速度。另外,编译器也会根据指令情况,提高CACHE的命中率,因此编译器如果开启了优化选项,实际生成的汇编代码可能与源代码的执行顺序不一致。
但是,不管是处理器还是编译器的乱序执行,都不应该改变最终的执行结果的正确性,也就是as-ifserial语义。在这种语义的要求下,这就要求对于有依赖的指令或者数据有上下文要求的操作不能改变顺序。因此,在编写单线程代码时,实际执行的结果是符合预期的。
2.2 编译器优化选项
GCC编译器有多个优化选型,这些选项可以设置,编译器优化的目的是生成的代码执行时间尽量短,代码占用的空间也应当尽量小。
编译器优化过程如下:编译器读取设置的优化参数,然后通过语法分析器对源代码进行翻译,并抽象成语法树。语法树再经过代码生成器转换为RTL,然后进行优化。最终得到优化后的汇编代码或者机器码。
例如下面的代码,主函数最后调用求和,在编译器选项为优化时,编译器直接将sum函数中的值在编译时就求出,并将结果放到r3寄存器中,而没有使用选择优化选项时,则需要在CPU中执行求和代码。
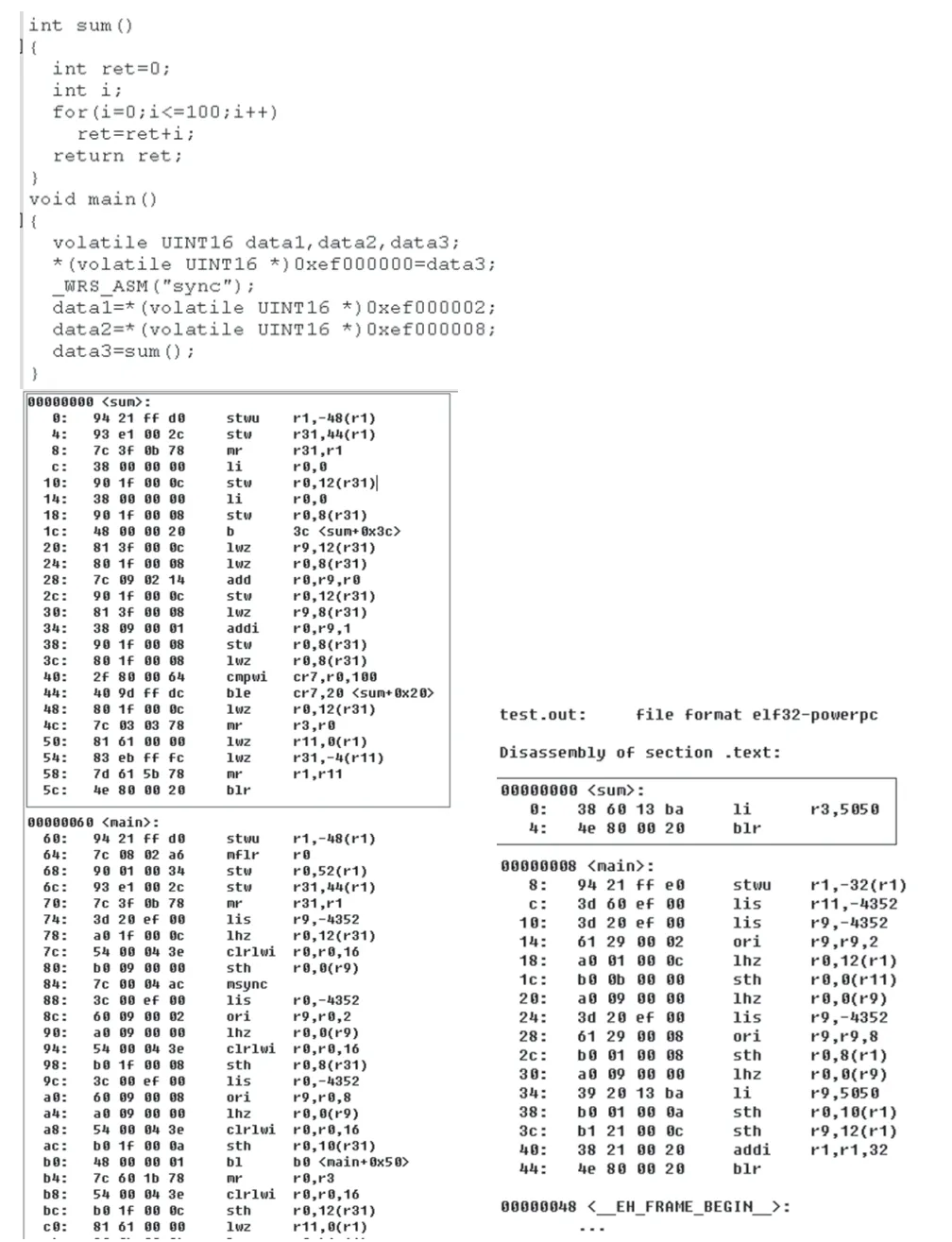
图2 编译器优化前和优化后的代码对比示意图
3 解决方案
3.1 CPU处理器层面
在PowerPC架构处理器中,官方文档提供了相应的指令,用于显式强制按照汇编后的代码顺序执行,主要包括isync(指令同步)、mbar(内存屏障)、msync(同步指令)以及eieio等。
msync指令是要求其指令之前的语句必须执行完成,才能取后续的指令。其中指令eieio是经典PowerPC架构的指令集,在book E版本以上中使用mbar指令代替eieio指令,同时也支持eieio指令。
3.2 编译器层面
对于一些不希望被优化的指令,可以通过volatile关键字来抑制,这样编译器可以不对相关的变量进行优化。
3.3 验证测试
经过以上分析,为了防止编译进行代码重排序和防止从缓冲中取数据,需要在变量前加volatile进行修饰。同时为了防止CPU执行代码时并行处理指令导致的乱序问题,需要在代码处增加同步指令。修改后代码如下:

经过测试,代码执行顺序正常。
4 结束语
(1)处理器和编译器为了提高执行效率,会对代码的执行顺序进行重组,但是处理器和编译器对整体的运算结果是有保证的。
(2)只有在时序要求严格的情况下需要显式调用同步指令,具体情况如下:①在操作某些硬件寄存器或者双口存储器时,如果有明显的读写时序要求,则应当添加同步指令,且变量需要添加volatile进行修饰。②中断和主程序都使用同一个全局变量,在定义全局变量时增加volatile进行修饰,同时主程序在进行变量的写操作时,需要关中断,然后再开中断。③在使用多线程或者多任务时共享同一个全局变量,在定义全局变量时增加volatile进行修饰,同时在进行变量的写操作时,也需要增加信号量进行写保护。
(3)在没有特殊要求的情况下,不建议使用编译器优化选项。
猜你喜欢
计算机研究与发展(2021年3期)2021-04-01
数码世界(2020年12期)2021-01-20
学校教育研究(2020年11期)2020-06-08
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
科技传播(2015年20期)2015-03-25
