
基于HSM- deep 模型的高分卫星影像密集匹配
2022-04-20 06:46田生辉
科学技术创新 2022年10期
田生辉
(中铁第一勘察设计院集团有限公司,陕西 西安 710043)
1 概述
相比经典的半全局匹配算法(SGM[1]),深度学习立体匹配模型可以计算更为鲁棒的匹配代价,并具有强大的代价体(cost volume)正则化能力,因此在计算机视觉研究领域,深度学习立体匹配模型的匹配精度已经远远超过了SGM算法。目前,已经涌现出了各种各样的深度学习立体匹配模型,在kitti 立体基准排行榜上出现的更先进的立体匹配模型,很少有学者尝试将其应用于卫星影像密集匹配。鉴于高分卫星影像分辨率高、数据量大等特点,将采用了由粗到精的策略、运行速度极快、适用于高分辨率影像的HSM(Hierarchical Stereo Matching[2])模型应用于卫星影像密集匹配。
HSM模型为高分辨影像设计,参数量较少、运行轻便、可以按需输出不同尺度下的视差图。本文在详细了解该模型结构的前提下,依据卫星影像的特点对该模型进行了改进,设计了新模型HSM-deep。
2 HSM-deep 模型的结构
为了提高HSM模型的精度,避免忽略高分影像中的细小地物,输出分辨率更高的视差图,对HSM模型进行了改进,提出了HSM-deep 模型。具体改进如下:
2.1 在特征提取模块中增加更精细的特征提取层
原特征提取模块将原始图像输入3 层卷积块后会将图像的尺寸降采样为原尺寸的1/4。鉴于高分辨率卫星影像地物细节丰富的特点,本文提出的HSM-deep 的特征提取模块将原始图像输入4 层卷积块,未采用步幅为2 的卷积层,因此输出的初始特征的长宽尺寸为原图像的1/2。
原特征提取模块设计了4 个残差块以生成多尺度的图像特征,这将会使图像尺寸依次缩小1/2。因此,最终得到长宽尺寸分别为原始图像1/8、1/16、1/32、1/64 的多尺度特征,改进后的特征提取模块增加了一个残差块,生成分辨率更高的特征,最终得到了长宽尺寸分别为原始图像1/4、1/8、1/16、1/32、1/64 的多尺度特征。
2.2 在特征提取模块增加更多的空间金字塔池化层
原始的特征提取模块只在最粗略的特征图上添加了金字塔池化层,为了捕获更为广泛的全局上下文信息,改进后的模型在三个尺度的特征图上都增加了金字塔池化层。
最终改进的特征提取模块的结构如图1 所示,图中所示的结构类似于U-Net 结构,下采样之后再逐层上采样恢复原来的尺寸,上采样层与下采样层之间具有跳跃连接,即某一尺度的特征上采样与更精细尺度的特征级联作为下次上采样的输入。立方体表示特征,越高表示通道数越多,标签中带有“res_block”字样的方块为残差块,将对特征进行下采样,标签中带有“upconv”字样的方块会对特征进行上采样,标签中带有“proj”字样的方块使用1×1 卷积压缩特征通道数。

图1 HSM-deep 模型特征提取模块
2.3 加深金字塔解码器
由于HSM-deep 模型增加了代价体,因此代价体解码器的数量也相应地增加到5 个,代价体空间分辨率和视差分辨率依次增加。改进后的金字塔代价体解码器可以正则化更高分辨率的代价体,将经过正则化的更高分辨率的3D 代价体输入视差回归模块可以得到更高分辨率的视差图,这种更高分辨率的视差图更为“清晰”,能更有效地保留细小结构。
HSM-deep 模型中的金字塔代价体解码器如图2 所示(改动的部分在底部由方框标出),图中每个解码器处理不同尺度的代价体,从上到下,代价体逐渐精细。除了decoder1,每个解码器具有两个输出,分别是上采样后的代价体和压缩为1 维的3D 代价体,将3D 代价体输入视差回归模块即可输出视差图。decoder1中具有5 个conv3D,其余decoder 中具有6 个conv3D。
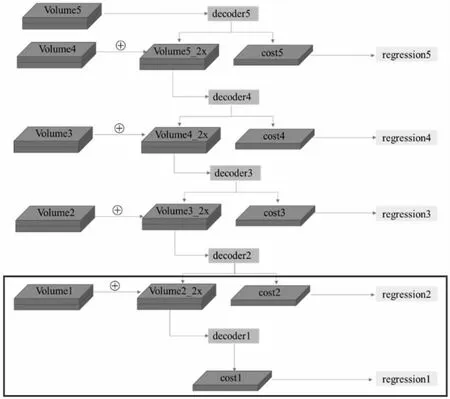
图2 HSM-deep 模型中的金字塔代价体解码器结构
2.4 视差回归模块的改进
HSM 模型采用softmax 函数归一化代价体,导致该模型只能输出正视差值。而卫星影像立体匹配生成的视差图包括负 值, 因 此 HSM-deep 模 型 使 用Normalize 函数将3D 代价体进行归一化,使得每个像素在视差搜索空间上的所有代价值在[-1,1]之间,这样得到的归一化代价体尽管不能从概率的角度解释,但是可以使视差回归模块输出负视差值。
3 实验结果与分析
3.1 实验数据
实验采用“大范围语义3D 重建比赛[3]”第二组挑战赛的数据,包含3000 多对已经核线校正过的立体像对。每个图块均为全色融合影像,尺寸为1024×1024。
3.2 实验环境
实验在深度学习服务器中进行,CPU为 Inter (R)Xeon (R)E5-2640 v4 2.40GHz,内存为128G,GPU 为NVIDIA Tesla P40,显存为24G。所有深度学习模型都基于pytorch 深度学习框架实现,采用python 作为主要编程语言。模型运行在CentOS 系统下。
3.3 评价指标
使用测试集上所有样本的平均端点误差(EPE)、三像素误差(3PE)、一像素误差(1PE)、均方根误差(RMSE)对模型(或算法)的精度进行定量评估。其中EPE 是指预测视差与真实视差的平均绝对差值(计算公式见式(1)),3PE 是预测视差与真实视差的差值小于3 的像素百分比,1PE 是预测视差与真实视差的差值小于1 的像素百分比(计算公式见式(2)),RMSE 是预测视差与真实视差的均方根误差(计算公式见式(3)),这些评价标准只在样本的有效视差处计算。此外,本文还对各个算法处理一对立体像对的时间进行了统计。
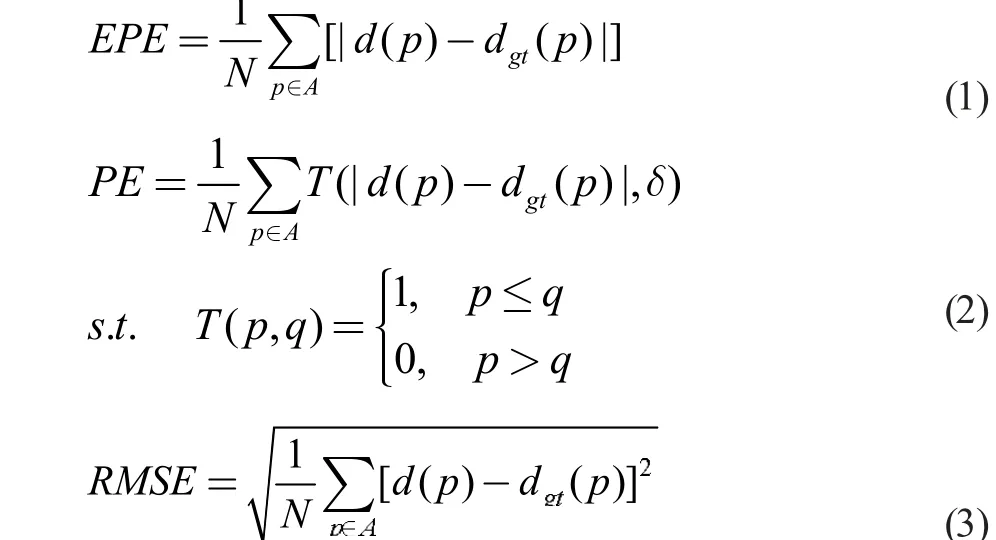
上式中,d(p)表示像素p 的预测视差,dgt(p)表示像素p 的真实视差,A 表示有效像素的集和,δ 可取1 或3。
3.4 实验结果及分析
3.4.1 模型的训练
为了进行对比分析,除对HSM-deep 模型进行训练和评估外,还将该模型与原HSM 模型、GA-Net[5]模型以及PSMNet[5]模型进行了对比。
深度学习立体匹配模型均采用Adam 进行优化(β1=0.9,β2=0.999)。所有模型的训练整体上可以分为两个阶段:先以较大的学习率使模型快速收敛,之后降低学习率,并且更改其他参数对模型进行微调。
3.4.2 立体匹配结果的定性和定量评估
相对于原始HSM 模型和GA-Net 模型,HSM-deep模型在可视效果和精度两方面有所提升。下文选择一个典型场景进行定性分析,具体可视效果见图3,该场景中存在大量的树木和小型建筑物,这是一种最为考验立体匹配算法的场景,HSM 模型明显优于GA-Net 模型和PSMNet 模型的结果,在HSM模型的结果中,地面与地物有着明显的反差,说明HSM 模型区分“前景- 背景”的能力更强。局部细节图中包含一个细小的建筑物,相比其他两种模型,HSM-deep 模型最有效地恢复了该建筑物的轮廓。

图3 GA-Net 模型、原HSM 模型、HSM-deep 模型立体匹配结果的局部对比
从定量评估结果(见表1)分析,HSM系列模型的各项指标优于其他模型。HSM-deep 模型各项精度指标相比原HSM模型均有所提升,受益于HSM-deep 模型增加了一个更精细的尺度,该模型的1PE 精度相比原模型提升明显,尽管HSM-deep 模型相比原HSM模型运行时间有所下降,但仍旧比其他深度学习立体匹配模型更快。
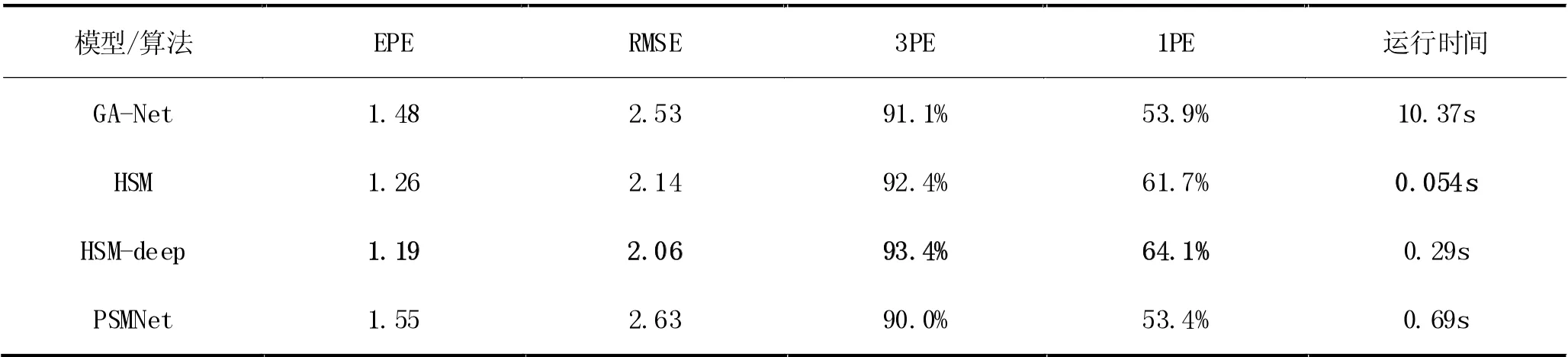
表1 各模型/算法在测试集上的定量评估结果
4 结论
将多个深度学习立体匹配模型应用于卫星影像密集匹配,对HSM模型进行改进,在特征提取模块增加了一个更高分辨率的特征提取层和更多的空间金字塔池化层,由于增加了更高分辨率的特征提取层,相应地,需要在金字塔代价体解码器中增加分辨率更高的代价体解码器,从而构建了新模型HSM-deep。HSM-deep 模型中新增的更精细的尺度用于输出更高分辨率的视差图,避免忽略细小地物。相比原HSM模型,HSM-deep 模型生成的视差图的各项精度评价指标都有所提高,且能够有效地保留许多细小结构,在视差边缘处的可视效果超越了GA-Net 模型。
猜你喜欢
计算机工程(2022年3期)2022-03-12
小型微型计算机系统(2022年1期)2022-01-21
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
计算机与数字工程(2020年11期)2020-12-23
家庭影院技术(2019年8期)2019-12-04
科教导刊·电子版(2016年23期)2016-10-31
现代计算机(2016年3期)2016-09-23
电脑知识与技术(2016年15期)2016-07-04
