
眼动跟踪数据集标定与标准化
2022-04-21 11:11刘天键吴成霖胡焕强
闽江学院学报 2022年2期
刘天键,吴成霖,胡焕强
(1.闽江学院物理与电子信息工程学院,福建 福州 350108; 2. 福建师范大学光电与信息工程学院,福建 福州 350117)
0 引言
眼动跟踪泛指与眼球、眼动、视线等相关的研究,主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置。眼动跟踪技术在VR、医疗、智能驾驶以及线下销售领域有着广泛的应用前景。要推广该项技术,眼动跟踪精度至关重要。虽然,目前基于红外照明设备的商业眼动仪已经能达到约0.5°的精度,但是由于设备昂贵且无法在室外使用,其应用范围受到限制。随着深度学习技术的普及,基于表观的可见光谱眼动跟踪技术成为该领域研究的热点[1-8]。该技术从大量的眼动数据中学习到视线方向,跟踪精度约为4°~5°,但与基于红外照明的眼动仪比较,尚有一定的差距,进一步提高跟踪精度成为基于表观的眼动跟踪研究领域的一个难点。由于数据集的准确标注对于模型训练的精度以及算法的比较有重要影响,因此减少数据样本噪声以提高跟踪精度是一个有前景的研究方向。
视线估计方法通常可以分为基于模型的方法和基于表观的方法[1-2]。基于模型的方法使用眼睛的几何模型,利用人眼成像的原理,通过相机获取人眼眼球的特征,随后根据获取到的特征建立与注视点的映射关系,从而实现视线估计。该方法可以进一步分为基于角膜反射的方法和基于形状的方法。角膜反射法通过外部红外光源反射到眼睛的角膜来检测到眼睛的特征。与基于模型的方法比较,基于表观的方法采用从脸部图像到视线方向进行端到端映射的方法。早期的方法采用眼睛区域图像,并且假设头部固定不动。眼动数据集的标准化是在眼动算法设计之前对数据进行预处理,以得到更加合理和准确的数据。SUGANO等提出了数据标准化方法,他们把任意姿势的眼睛图像重定向到标准化空间,以实现样本的重采样[3]。该方法能改善样本的分布但对提高视线估计精度效果不佳。随后的研究扩展到允许头部自由运动的场景,但用户与相机的距离仍基本保持不变。ZHANG等在此基础上进行了改进,他们指出尺度变化不能改变3D视线方向,修正了变换矩阵,从而使得性能大幅提升[4-5]。KRAFKA等给出了Gazecapture数据集并提出了一种2D视点跟踪方法,采用脸部、眼部图像和面部网格作为输入,通过CNN拟合输出视点位置,结果表明大规模的眼动数据可以改善视线估计的精度[6]。WOOD等提出了UnityEyes模型,一种可以快速合成大量可变眼域图像的新方法,该方法结合了一个人眼区域生成三维模型和一个实时绘制框架。虽然,可以大量产生眼动数据,但该方法需要视线估计器处理大量类似冗余的数据,从而导致训练时间的延长和损失函数优化的困难[7]。直到最近,该领域才拓展到真实应用场景,即对姿势和距离没有约束。PARK等在大规模数据集上开展眼动跟踪算法的研究,并取得了学界领先的结果[8-9]。综上所述,虽然数据标准化已在模型训练中采用,但是标准化的详细过程以及标准化后的效果还鲜有比较和讨论。经验表明,数据预处理可以对数据进行清洗,从而减低数据噪声,有效地改善后续算法的鲁棒性。
虽然增加样本数量可以提高模型精度,但大规模的样本标注需要耗费大量的人力物力,尤其是在三维视线估计领域。由于很难直接测量视线的三维向量,因此需要用视点坐标间接生成三维视线方向,造成数据集的标定复杂且耗时。然而,提高数据集的质量一直是业界追求的一个目标。目前该领域并没有一种统一的样本预处理方法,造成同一算法在不同数据集上跟踪效果的差异。虽然,文[3-6]给出了一种基于投影变换的标准化方法,但是需要已知相机模型和参数。同时,公开的数据集记录视线方向的方法各不相同,有些采用3D视线方向,有些采用2D视点坐标,并且未考虑相机与眼睛的相对位置,导致后续算法比较缺乏统一的标准[10]。为此,本文采用了一种基于反射立体视觉的相机位姿估计方法,并将该方法引入到眼动数据集样本预处理领域。该方法通过反射几何建立屏幕坐标系、相机坐标系和头部坐标系之间的关系,并将任意范围方位采集的脸部图像转换到标准化空间,完成图像的对齐和矫正。在标准化空间,对数据集样本进行投影变换,计算三维视线方向的极坐标(俯仰角、偏航角)。在标准化空间引入虚拟相机,规范化虚拟相机与眼睛的位姿,减少样本的噪声,提高视线估计的准确度。
1 数据集标准化
通常眼动数据是通过用户注视屏幕上的视点产生的。本文采用的数据集标准化是指,在进行视线跟踪算法设计之前,把眼动数据集的图片和标签数据映射到标准化空间,该空间设置为由距离脸部中心一定长度的虚拟相机采集眼动数据,以便减少图片在几何上的变化,为后续算法的比较提供统一的基准数据。然而,不同的应用场景以及不同的设备导致眼动数据集标准化非常困难并且不容易推广。在眼动跟踪过程中,由于3D视线方向能较准确的描述注视方向,文[5,8-9]选择极坐标形式(俯仰角、偏航角)作为眼动跟踪的输出,如图1(a)所示。本文同样采用这种方式描述视线方向,由2D视点坐标到3D视线方向转换较为复杂,需要进行多个坐标系之间的转换。

图1 眼动跟踪系统坐标系的变换关系Fig.1 Transformation relationship of coordinate system in eye tracking system
1.1 从屏幕坐标系(SCS)到相机坐标系(CCS)变换
这个过程主要确定屏幕与相机的相对位姿。由于屏幕和相机的朝向一致,屏幕不在相机的视野范围之内,如图2(a)所示,为了估计相机的位姿,文[11-12]采用了一种平面镜反射的方法估计相机的位姿。在该方法中,相机的运动由刚体运动退化成平面运动,外参自由度从6降到5,从相机的约束条件可以解出镜面的方位,继而得到真实相机的位姿。本文采用类似的方法,并把该方法应用到眼动跟踪数据集标定领域,由于在视线估计场景中,相机与头部的相对位移较小,引入虚拟相机,扩大了视野移动范围,再通过对应点的几何关系可以较准确的估计相机位姿。
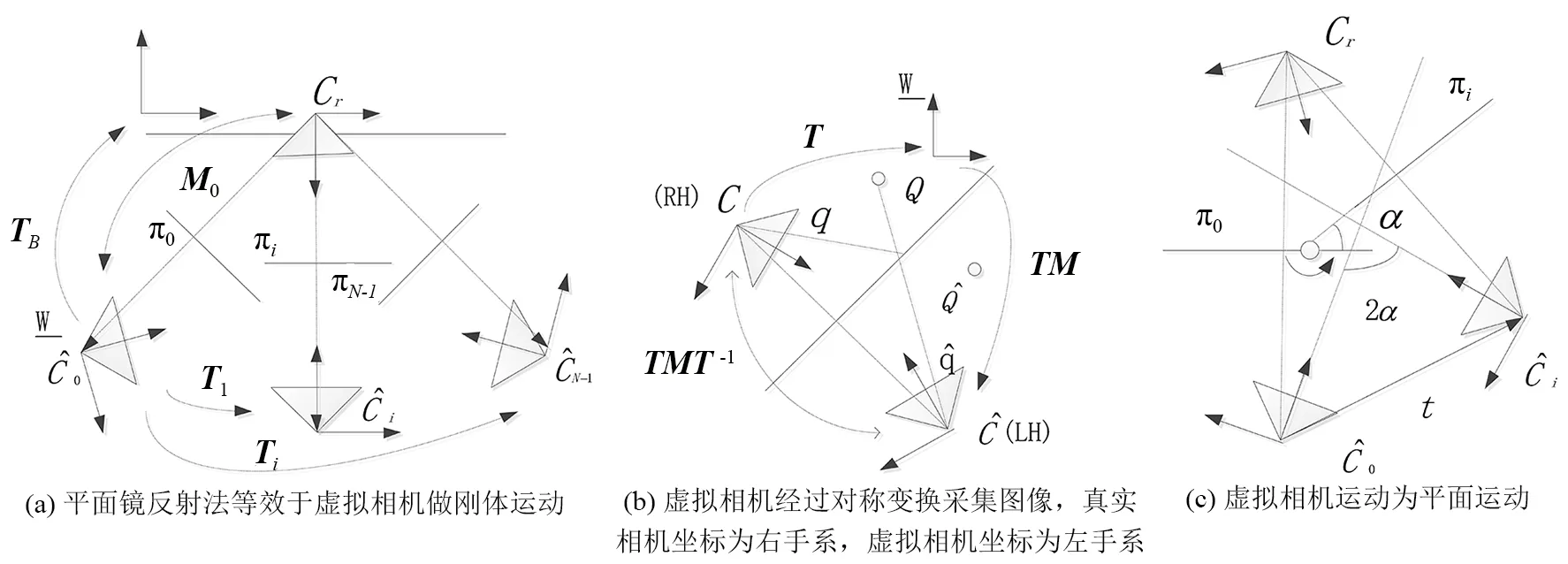
图2 基于反射立体视觉的虚拟相机运动方式Fig.2 Motion mode of virtual camera based on catadioptric stereo vision

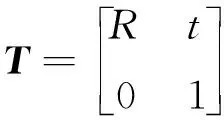
(1)
则投影变换为:

(2)
根据平面镜的对称性,则有:

(3)
两点间的齐次坐标关系为:

(4)
其中,对称变换M是自伴矩阵(满足M-1=M),且有:

(5)
把式(4)代入式(2)得:
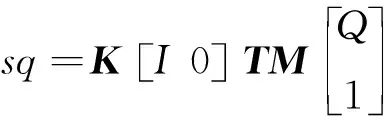
(6)

M′=TMT-1
(7)
因此,在图2(a)中虚拟相机之间的平面运动存在以下关系:
Ti=M0Mi
(8)
将式(1)、式(5)带入式(8)得:

(9)


(10)

假设虚拟相机之间的平面运动如图2(c)所示,考虑到式(9)得

(11)

(12)

(13)
式(12)、(13)为平面运动的线性约束,再由式(12)解出di,带入式(13)得

(14)
由此,可以得到系统方程
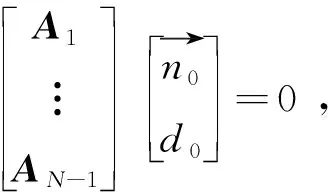
(15)
其中,子矩阵Ai的尺寸为3×4,且有
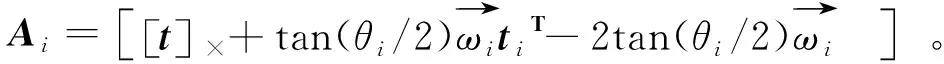
(16)
TCS=TBM0。
(17)
1.2 从头部坐标系(HCS)到相机坐标系(CCS)变换
估计3D头部姿势等效于估计相机位姿。已知头部坐标系下的n个3D坐标点,以及这些点在图像中的2D投影坐标,求解头部坐标系相对相机坐标系的位姿是一个PnP问题。该问题已经得到了有效的解决,经由Surrey脸部模型[8]可获得稠密的人体3D头部坐标,再由关键点检测算法提取图像的关键点坐标。之后,通过相机的内参和6个关键点(左右内外眼角和左右嘴角)的3D和2D坐标可以估计出相机位姿[3]。
p=KPc
(18)
p′=KnP′c=KnRSK-1p
(19)
因此,矫正后图像做射影变换W为:
W=KnRSK-1
(20)
由于伸缩变换不影响视线方向向量,所以校正后的3D视线方向为:

(21)
又由于俯仰角、偏航角的定义为坐标系朝向且(-π/2≤θ,φ≤π/2),则:

(22)
综上所述,为了获取3D视线方向,需要确定SCS、HCS相对CCS的位姿,再用虚拟相机产生标准化数据。眼动数据集标准化过程如表1所示。

表1 眼动数据集标准化过程
2 实验结果
由于标准化过程需要相机的标定数据,大多数公开数据集并未提供。MpiiFaceGaze数据集收集了15个对象的头部姿势图像并提供了相机内外参数,因此选择该数据集进行测试。从MpiiFaceGaze数据集中取出一张图像,经过投影变换后,裁剪成尺寸为224×224的全脸图片,其中虚拟相机的标准化参数为:

(23)
3D视线方向按照式(21)校正后,以式(22)计算方向的极坐标。
假设方法0为原始数据集记为none,方法1采用文[4-5]进行预处理的方法记为normalized,方法2采用本文预处理方法记为ours。在Alexnet和Resnet上采用留一法进行交叉验证,验证不同的预处理方法对模型输出精度的影响[5,8]。图3是不同处理方法数据集中图片对比,本文方法由于相机的z轴对准了面部中心,并且相机坐标系和头部坐标系的x轴平行,即数据在标准化空间进行规范化,相当于进行数据对齐操作。由于极坐标形式的视线方向不包括滚转角,校正后减小了滚转角对数据的干扰,减低了数据集中的噪声,因此提高了后续算法的精度。图4 是不同方法俯仰角对偏航角的联合分布,方法0的视线方向俯仰角在[-23°,34°]之间、偏航角在[-23°,23°]之间,方法1、2的视线方向俯仰角在[-11°,23°]之间、偏航角在[-11°,11°]之间,可见标准化后数据分布更狭窄。相比方法1,采用方法2,校正后视线方向分布更加集中和平滑。图5是在两个模型输出上结果比较,校正后在测试集上的均值和方差均优于校正前,在Alexnet模型上,15个对象测试的平均均值和方差,方法0为(6.69, 3.50),方法1为(5.20, 2.62),方法2为(5.07, 2.60)。相比方法0,本文方法的平均均值提高了24.2%,平均方差提高了25.7%;相比方法1,平均均值提高了2.5%,平均方差提高了0.8%;在Resnet模型上,方法0的平均均值和方差为(6.15, 3.23),方法1为(4.86, 2.43),方法2为(4.76, 2.33),相比方法0,平均均值提高了23.6%,平均方差提高了27.9%。相比方法1,平均均值提高了2.1%,平均方差提高了4.1%,性能更优。综合起来,相比方法0,本文方法平均均值提高了23.9%,平均方差提高了26.8%,标准化后性能提升了20%以上。

图3 MpiiFaceGaze数据集对象标准化的视线方向(单箭头)和头部姿势(双箭头)Fig.3 Standardized gaze direction (single arrow) and head posture (double arrow) of objects in the MpiiFaceGaze dataset

图4 俯仰角对偏航角联合分布Fig.4 Joint distribution of pitch and yaw angle

图5 MpiiFaceGaze数据集校正前后比较Fig.5 Test comparison before and after correction of the MpiiFaceGaze dataset
3 结论
3D视线方向可以由俯仰角、偏航角和滚转角中在任意两个确定,由于大部分情况下人的头部转动的滚转角度较小,因此在视线估计模型中大多采用俯仰角和偏航角标记视线方向。本文引入一种基于反射立体几何的标准化方法,改进和扩展了眼动数据集标准化过程,通过虚拟相机辅助相机位姿估计,并在标准化空间对图像进行对齐操作。这样,小角度的滚转角就成了干扰项,数据集校正后,把相机的z轴对准脸部中心,同时相机坐标系与头部坐标系在x轴平行,这样处理后,等同于对数据进行对齐,减少了数据的噪声,当然标签数据即头部姿势和视线方向也应进行相应的调整。总之,眼动数据集的校正与标准化是进行模型设计和算法比较之前的关键步骤,通过数据预处理可以消除头部的滚动姿势对图像的干扰,让数据分布更平滑均匀,使得后续的模型性能得以提升,提高模型的鲁棒性。同时,矫正后的图像可以更加准确匹配修正的3D视线方向,使得后续的模型比较可以统一到一致的基准数据集,对模型学习的精度和可靠性有重要影响。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20
导航定位学报(2022年2期)2022-04-11
载人航天(2021年5期)2021-11-20
语数外学习·高中版中旬(2021年11期)2021-02-14
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
大自然探索(2019年7期)2019-12-13
山东工业技术(2019年16期)2019-07-19
考试周刊(2018年15期)2018-01-21
中学生数理化·七年级数学人教版(2017年4期)2017-07-08
