
基于动态运行特征的空中管制扇区分类研究
2022-04-21 12:42张启钱徐礼鹏张赛文
重庆交通大学学报(自然科学版) 2022年3期
张启钱,徐礼鹏,张赛文
(南京航空航天大学 民航学院,江苏 南京 211106)
0 引 言
在航班总量不断增长的外部环境下,民航空域资源供给不足所引起的航班和空中交通管理问题日益凸显。从空中交通管制扇区运行动态特征出发,对扇区展开分类研究,通过分析不同类别扇区的运行特性,可找出当前制约我国空管效能提升的瓶颈问题。
国内外空管业都在不断探索空域和扇区的管理方法及相应的自动化技术,以期促进空中交通的安全、高效的运行。R.CHRISTIEN等[1]通过K-means方法根据交通流指标和空域结构指标进行扇区分类研究,改进了扇区容量评估模型,提高了管制员工作负荷评估和扇区容量预测的精度;B.HILBURN[2]在COCA (complexity and capacity)项目中同样提出建立扇区容量模型对扇区进行分类的构想。NextGen的研究项目正在探索“通用空域”的概念[3],为支撑“通用空域”的研究,有学者从扇区交通运行模式出发,识别不同的扇区,用于评估“通用空域”概念所需的运行相似性[4]。A.CHO等[5]基于扇区间共同结构特征,对360个高空扇区进行了整体式与分步式分类;S.MALAKIS等[6]通过决策树和样本场景的分类规则,对空中交通场景开展分类研究;高兴[7]提出了面向动态容量的区域扇区分类,按静态和动态因素进行扇区分类;王红勇等[8]、温瑞英等[9]运用K-means等方法对空中交通复杂程度进行评级,划分出不同的扇区复杂性模式;董襄宁等[10-11]基于扇区结构和飞行流量等特征,发现区域和近扇区的复杂性指标中静态指标的共性都强于动态指标;丛玮等[12]从扇区航班分布和动态两个维度着手,使用K-medoids算法进行了基于交通态势的扇区聚类方法研究。
综上,现有研究对扇区动态运行特征分析较少,且选用硬聚类算法进行类别划分,存在一定程度的不合理性。基于此,笔者通过ADS-B(automatic dependent surveillance-broadcast)数据,提取具有时变性的动态因素,并归纳出适应扇区分类研究的普适性指标,采用改进的核模糊C均值聚类算法等机器学习算法,对选取的97个样本扇区展开管制扇区分类研究。
1 指标构建
扇区是空中交通管理的基本单元。因扇区静态物理结构因素与动态交通流因素不同,不同扇区运行特征存在差异,计算获取能反映扇区运行特征和状态的指标数据是扇区分类研究的基础。
1.1 ADS-B航迹数据概述
航空器通过ADS-B系统向所有安装ADS-B接收机的航空器或者地面台分发实时空中交通数据,即ADS-B数据。数据中包含了时间戳记、航空器呼号标识、航空器类型、航空器三维位置信息(飞行高度、经度、维度)、航行方向、起飞机场和目的机场等信息。直接反映真实运行状况的ADS-B数据能够为基于动态运行特征的空中管制扇区分类研究提供科学的数据来源。
1.2 空中管制扇区分类指标
航空器数量是空中交通特征中最常被引用、研究和评估的一个指标。但航空器密度指标只能片面反映扇区运行情况和管制员工作负荷。因此,衍生了动态密度、内秉性等更多的复杂性相关研究,提出了更多的复杂性指标如:在不同飞行阶段(平飞、上升、下降)的航空器比例、扇区内航向发生改变的航空器数量(比例)、管制飞行时长(里程)、交通混合程度、航空器冲突次数等。这些复杂性指标为空中交通管制环境提供了比单一的航空器密度指标更加全面的评估方法。
综合扇区自身物理结构特点和动态交通流特征,通过对ADS-B数据解析计算,基于已有扇区分类相关研究成果[1,7,12-13],考虑数据形式、可获取性、用户可接受性等,选取9个指标数据用于扇区分类研究,如表1。
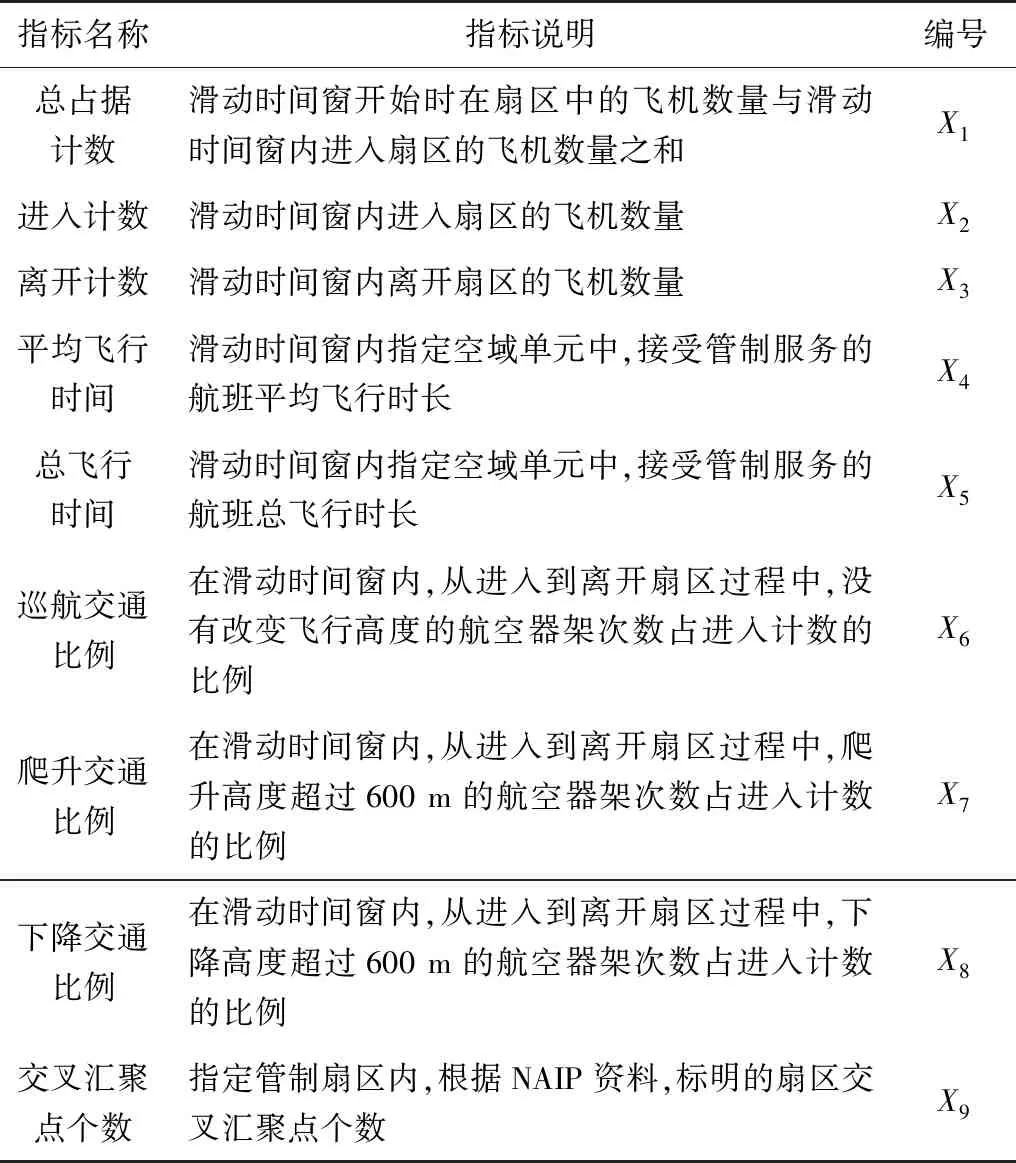
表1 初始指标集Table 1 Initial index set
2 分析方法
在系统聚类法或K-means聚类法等传统硬聚类算法中,每个样本被严格划分到某一类中,在处理一些复杂数据的类别划分上存在不合理性。区别于硬聚类,模糊划分允许每个样本属于具有不同隶属度的多个聚类,隶属度的取值范围是[0,1],一个样本对于所有类别的值之和为1。基于此,采用改进的核模糊C均值聚类算法对扇区分类进行研究。
2.1 核模糊C均值聚类(KFMC)算法
随着模糊C均值聚类(fuzzy C-means,FCM)算法在各个研究领域的不断应用,学者们发现FCM算法对噪声和异常值敏感。此外,FCM算法采用欧式距离构造目标函数,聚类效果很大程度上依赖于聚类样本的空间分布。针对这些问题,学者们提出了基于核函数改进的模糊C均值聚类KFCM(kernel fuzzy C-means)算法。KFCM算法的基本原理是将原空间的样本,通过核函数映射到高位特征空间后,再利用FCM算法指导聚类[15]。
通过非线性映射Φ:x∈X⊆Rd→Φ(x)∈F⊆RH(d≪H),将样本X从一个低维空间映射到高维空间F。对于所有的x,y∈X,X⊂Rd,若函数K满足K(x,y)=〈Φ(x),Φ(y)〉=Φ(x)TΦ(y),则称函数K为核函数,其中Φ是从输入空间X到特征空间F的映射, 〈Φ(x),Φ(y)〉 为Φ(x),Φ(y)的欧式内积。
KFCM算法的目标函数如下:
(1)

采用拉格朗日乘子法求解目标函数JKFCM的极小值,推导出KFCM算法的隶属度和模糊聚类中心迭代式如下:
(2)
(3)
2.2 改进的核模糊C均值聚类(GA-KFCM)算法
KFCM算法通过将样本映射到高维空间,突出样本间的差异性,可获得较好的聚类效果,使算法对噪声和孤立点具有较好的鲁棒性,克服了FCM算法不适合多种数据分布的缺陷。但KFCM算法仍然没从根本上解决FCM算法对初始化聚类中心敏感的问题,聚类中心的随机初始化会影响到算法聚类性能,不能保证聚类结果收敛到全局最优解。基于此,笔者基于遗传算法改进KFCM算法得到GA-KFCM算法,结合遗传算法的全局搜索寻优能力在特征空间中搜索适当的聚类中心,弥补KFCM算法缺陷,获得理想的聚类效果[16]。
2.2.1 GA-KFCM算法适应度函数
遗传算法中的适应度函数可用于评价个体的性能优劣,也被称为评价函数。适应度函数通过对所求解问题的目标函数进行分析,根据优化方向构造而成。聚类是将给定的样本数据,按某种目标函数划分成若干个类的过程[14],对于KFCM算法而言,目标函数取得最小值时对应的聚类效果最好。根据目标函数值越小个体适应度越大原则,定义GA-KFCM算法适应度函数如下:
(4)
2.2.2 GA-KFCM算法基本算子
遗传算法通过选择,模拟自然界中的“优胜劣汰”,适应度高的个体被遗传到下一代的概率大。目前主要的选择方法有:轮盘赌选择法、排序选择法和随机联赛选择法等。采用非线性排序选择法,按照适应度大小对个体进行排序,然后根据顺序分配个体被选择的概率。非线性选择概率分布为:
f(z)=q(1-q)z-1,z=1,2,…,n
(5)
式中:q∈(0,1)为指定参数。
遗传算法通过交叉操作可得到适应度较高的新个体,并通过变异操作保持种群多样性。一般交叉概率建议取值范围为0.40~0.99,变异概率建议取值范围为0.001~0.100。但固定的概率取值会直接影响算法效果,因此采用自适应思想,动态确定交叉概率fcr(t)和变异概率fmr(t)为:
(6)
(7)
式中:pcr0为初始交叉概率;pcm0为初始变异概率;T为最大进化代数;t为当前进化代数。
2.2.3 GA-KFCM算法流程
GA-KFCM算法具体流程如下:
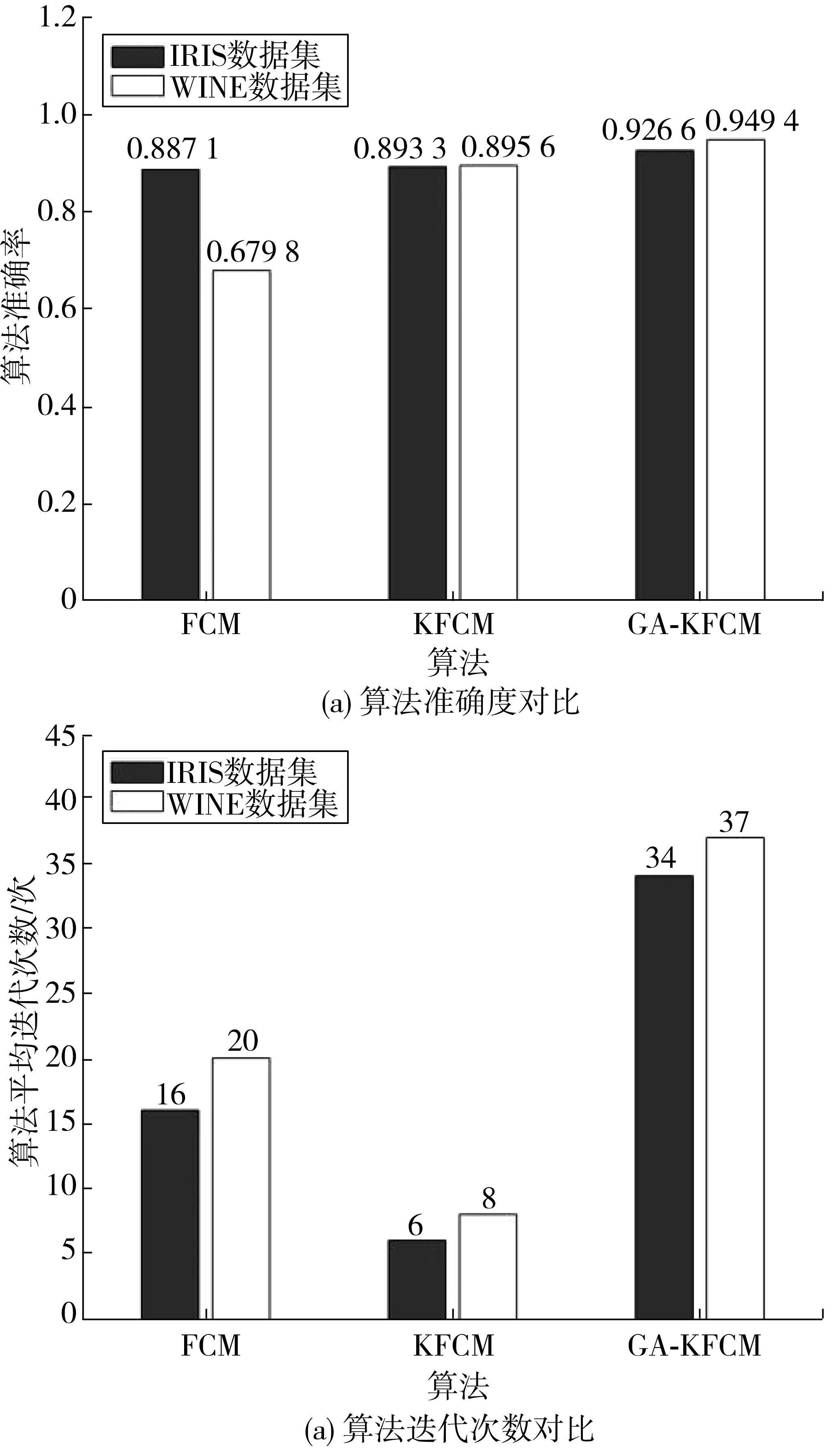
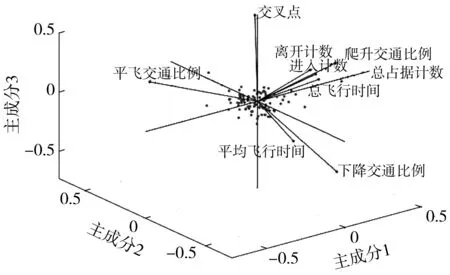
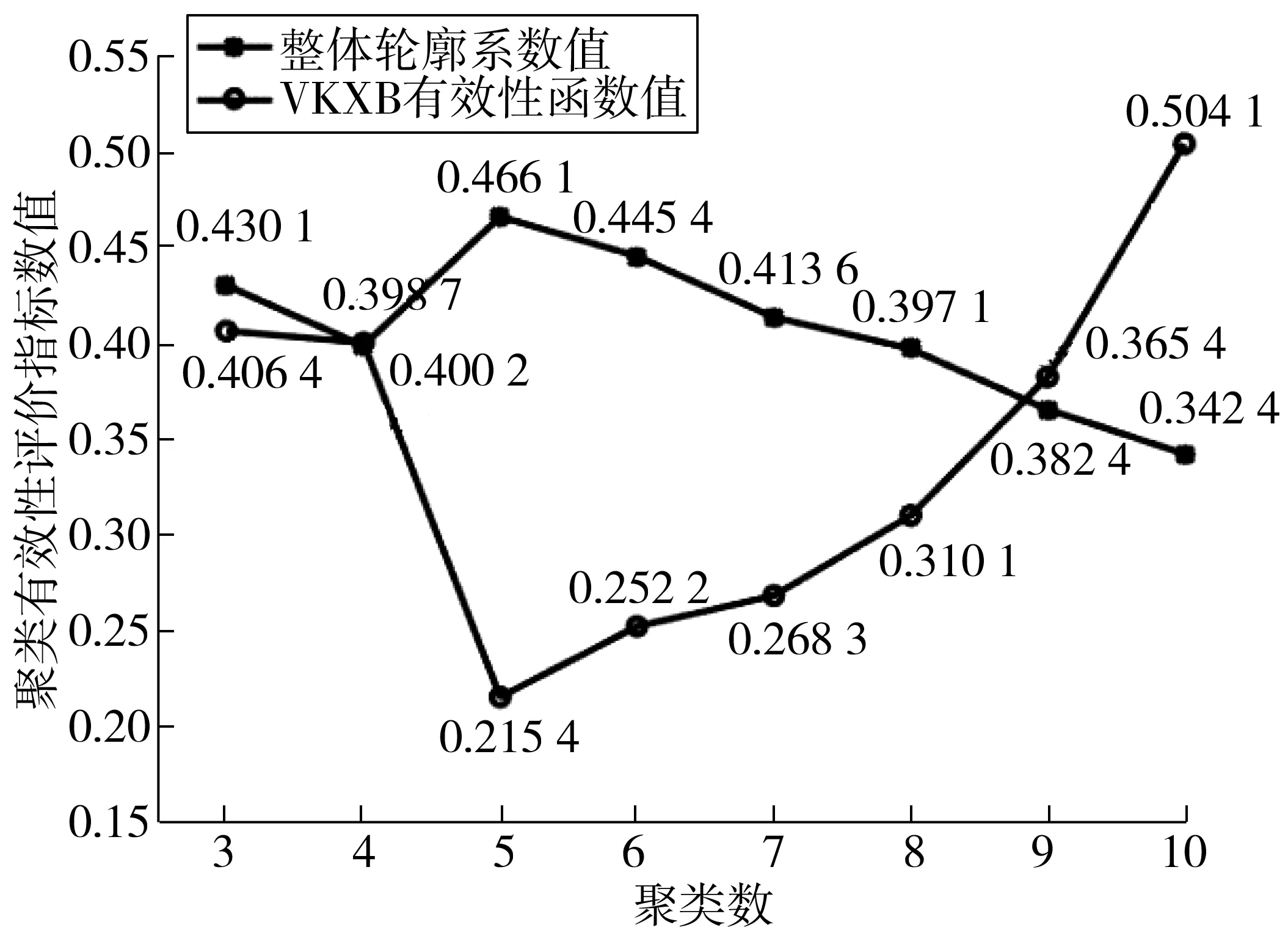
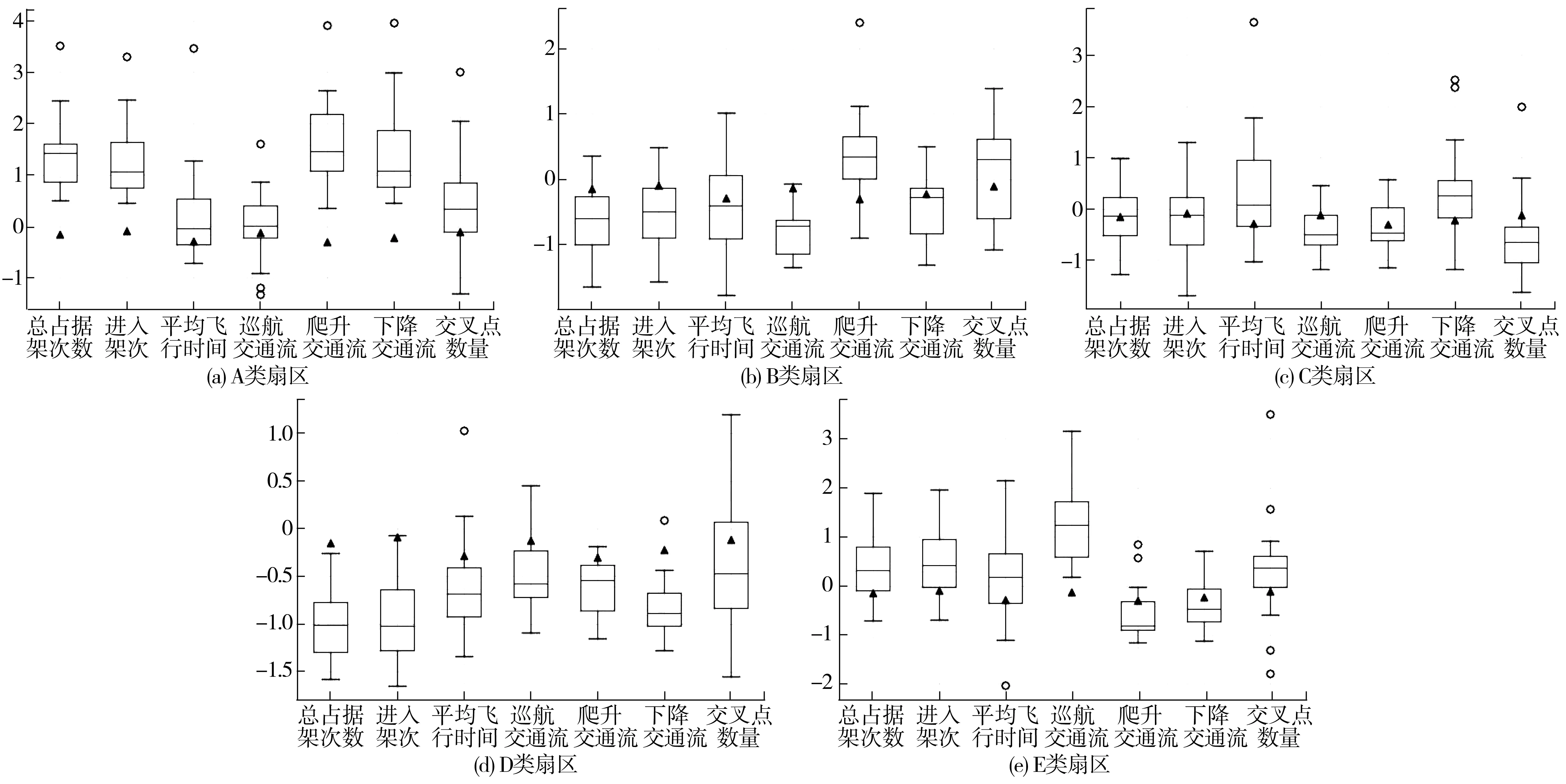
步骤1设定高斯核函数尺度参数σ,确定聚类数c(1 步骤2设置遗传代数t=0,模糊聚类代数k=0。随机产生n个聚类中心矩阵,形成初始种群。 步骤3计算种群中每个个体JKFCM,f(U,V),f(z),fcr(t),fmr(t)。 步骤4对t代种群进行选择、交叉、变异操作,形成第t+1代种群。 步骤5判断是否满足终止条件。不满足则返回步骤3;如满足,则解码获得最优聚类中心。 步骤6根据最优初始聚类中心对样本数据进行聚类分析。 步骤7输出结果。 选取UCI机器学习测试数据库中的IRIS和WINE数据集作为输入样本,针对FCM,KFCM和GA-KFCM 3种算法进行分析验证实验,通过对比不同算法结果,评价算法的聚类性能,检验算法的改进效果。设置GA-KFCM算法参数为:n=50,T=100,pcr0=0.6,pcm0=0.1,δ=0.001,σ=150,k=100,c=3,m=2,ε=0.000 01。将每种算法在IRIS和WINE数据集上运行30次,以平均结果进行对比。3种算法的正确率和算法迭代次数比对结果如图1。 根据实验结果得出如下结论: 1) GA-KFCM算法在两套标准数据集上的聚类准确率较FCM算法提高了4.62%和26.96%。但由于GA-KFCM算法在聚类之前需要先通过遗传算法进行最佳聚类中心寻优,导致算法总体迭代次数较多。 图1 FCM、KFCM、GA-KFCM算法性能对比结果Fig. 1 Comparison results of FCM、KFCM、GA-KFCM algorithmperformance 2)引入了核函数的GA-KFCM算法和KFCM算法在准确度上优于FCM算法,在高维数据集上更加明显。 3)KFCM算法在准确度上的表现与GA-KFCM算法相近,但实验过程中发现KFCM算法输出的聚类结果不稳定,算法准确率存在一定浮动。而GA-KFCM算法根据遗传算法输出的搜索结果作为初始聚类中心,每次执行后GA-KFCM算法的结果均是在最佳目标值附近,具有较高的鲁棒性。 模糊聚类算法需要预先指定聚类数目c,不同c值对应的模糊划分结果和质量不同。聚类有效性指标能够正确评价聚类结果,帮助确定最佳聚类数。采用整体轮廓系数和核空间的VKXB指标来确定最佳聚类数。 轮廓分析可以用来研究聚类簇间的分离程度,轮廓系数定义为: (8) 式中:ai是第i个点与同簇内的其他点之间的平均距离,用于量化簇内凝聚度;bi是第i个点与其他簇内各点之间的平均距离,用于量化簇间分离度;轮廓系数S(i)的值落在 [-1,1]的范围之间。 S(i)值越大,说明第i个点分类越合理,负值表示样本可能指定给了错误的簇。因此,可以通过计算样本数据在不同的聚类数目下的聚类结果所对应的整体轮廓系数值,来反映当前聚类的效果,整体轮廓系数值定义为: (9) Xie-Beni有效性函数是目前应用最广泛的模糊聚类有效性指标,定义为: (10) 在GA-KFCM算法中,需要将VXB推广到核空间,对应的核化Xie-Beni有效性函数VKXB为[17]: (11) 当VKXB取得极小值时可得样本数据最佳划分。 根据2019年民航空域发展报告,2019年日均流量前20位扇区有90%集中在华东和中南地区,约扇区94%呈增量趋势。华东和中南地区是我国最繁忙的空域,具有很强的典型性,选取华东和中南地区107 个管制扇区内2019年4月11日—18日中00:00—24:00的ADS-B雷达航迹数据作为数据源。通过整理解析ADS-B数据,计算获取得到能够客观刻画管制扇区整体运行特征的动态交通流指标,最终获得具有有效指标数据的97个管制扇区(89个区域扇区,8个进近扇区),采用GA-KFCM算法进行扇区分类研究。 基于ADS-B数据,提取管制扇区的9个特征因素作为扇区分类的初始变量。为提高数据质量,避免因选取的原始指标变量在数量级和单位不同,对结果可靠性造成负面影响,需采用 Z-Score规范化将原始数据作正态分布处理[18]。 通过主成分分析(PCA),将多个变量转换为少数几个主成分(综合变量),用于反映原始变量的大部分信息[19],消除指标信息重叠的影响,从而得到聚类算法输入特征向量。 表2 主成分提取结果Table 2 Principal component extraction results 表2中的主成分能解释的原样本中约80% 的信息量,依据主成分选择原则,选择这3个主成分进行后续研究。 实验得到的各主成分系数表达式数据见表3。根据表3中数据分析可得:主成分1在总占据计数、进入计数、离开计数和总飞行时间4个指标上有明显且相近的正载荷,为0.948~0.981,定义为扇区运行交通流量成分;主成分2在巡航交通流比例上有较明显的正载荷(0.916),在爬升交通流比例及下降交通流比例上有明显的负载荷,分别为-0.713和-0.621,定义为航空器飞行姿态成分;主成分3可定义为扇区的空域结构成分。 表3 主成分系数表达式矩阵Table 3 Principal component coefficient expression matrix 9个特征指标在3个主成分方向上的投影情况如图2。 图2 主成分空间投影图Fig. 2 Principal component space projection 聚类数c取[3,10]区间内的整数,对样本数据进行8组聚类分析实验,并分析不同聚类数c下对应的聚类有效性评价指标数值,再结合相应的空管背景,综合确定聚类最佳数目。不同聚类簇数取值下聚类结果有效性评价指标结果如图3。由图3可知:当c=5时,整体轮廓系数值最大为0.466 1,VKXB=0.215 4取得极小值为。根据最佳聚类簇数,确定基于动态运行特征的空中管制扇区分类研究的分类个数为5。 图3 不同聚类数目对应的聚类有效性指标值Fig. 3 Cluster validity index values corresponding todifferent cluster numbers 根据确定的最佳聚类数,结合聚类结果的可解释性,确定c=5。在实际应用中,模糊指数m的最佳取值范围为 [1.5, 2.5 ][20],选择常见取值m=2。算法经35次迭代至目标函数收敛,得到最终聚类结果,将97个样本扇区划分为运行特征鲜明的A、B、C、D、E类共5类。各类样本扇区指标数据箱线分析如图4。 图4 扇区运行特征指标数据箱线分析Fig. 4 Box line analysis on sector operation characteristic index data 除箱线图的标准元素外,样本扇区总体的每个指标变量的中位数都以实心三角形符号表示,从而可以将簇中某个指标变量的分布与所有分析的样本扇区的中位数进行比较;盒须外的数据被认为是异常值,用黑色圆圈表示。每个运行特征指标的标准化值已在y轴上显示,消除了表示中的比例问题。 扇区总体运行特征体现出的复杂性从A到E逐渐降低,各类扇区详细运行特征有: A类扇区:交通流量大,总占据架次数远大于所选取的样本扇区中值,该类扇区的日均航空器进入架次为900~1 500架次,平均飞行时间中等,交叉汇聚点个数较多。扇区内航空器主要高度改变情况为垂直方向上有高度改变的航空器比例占进入架次的72%以上,属于兼顾大流量和中高垂直方向复杂性的扇区,扇区整体运行状况繁忙,呈复杂态势,管制员负荷较高。 B类扇区:从交通流量维度看,该类扇区总占据架次数和进入架次数偏低。巡航交通流远低于样本扇区中值,意味着扇区内存在大量垂直方向上的高度调配,占到进入该扇区航空器约80%的比例,且集中于航空器的爬升。同时,扇区内航空器平均飞行时间较短,导致调配裕度偏小,空域环境复杂交叉汇聚点数量较多。根据分析得出,B类扇区的运行瓶颈并不是扇区内的交通量,而在于大量的垂直过渡带来的垂直方向上调配难度和潜在冲突,呈现出的高复杂性态势和管制压力。 C类扇区:交通流量在所选样本扇区里处于中等水平,进入该类扇区的航空器超过六成产生了垂直方向上的高度变化,且主要集中为下降交通流。平均飞行时间较大,且扇区内交叉汇聚点个数较少,管制调配裕度较大。整体运行状态由于中等的流量和垂直方向复杂性,仍然呈现较复杂和繁忙态势。 D类扇区:交通流量小,平均小时进入流量为15~25架次,瞬时管制压力较小;在高度过渡方面,该类扇区所管制的航空器中,平飞航空器所占比例和垂直方向产生上高度改变的航空器所占比例持平。尽管扇区交通流量低,垂直方向复杂性一般,但扇区内航空器平均飞行时间较短,管制员存在一定调配压力,扇区运行状态呈中等复杂态势。 E类扇区:在交通流量上分布较广,扇区日均进入流量为450~1 300架次不等;从箱线图巡航交通流的统计可以看出,航空器基本都是以平飞姿态通过该类扇区,产生高度过渡的航空器不足1/3;交叉点数量中等,平均飞行时间较长,调配难度小;运行压力主要与交通流量相关,垂直方向上的复杂性较低,总体运行复杂态势一般,管制压力较小。 根据2019年空域发展报告统计数据,流量增幅最大的扇区分别是成都区域08扇区(26.51%)、合肥区域01扇区(11.59%)和合肥区域04扇区(11.22%)。 选取合肥的区域01、区域02、区域03和区域04号扇区中2019年4月11—18日的历史运行数据进行仿真实验。通过AirTop快时仿真软件评估得到的管制员工作负荷和扇区容量结果,结合实际运行情况,对管制扇区分类研究结果进行验证。 根据3.3节中扇区分类结果,合肥区域01、04号扇区分别属于E类和A类扇区,合肥区域02、03号扇区同属于D类扇区。图5为合肥区域01号~04号扇区1 h管制员工作负荷与航空器进入架次关系拟合图,图中实线为拟合曲线,虚线为置信区间。 图5 管制员工作负荷与航空器架次关系拟合图Fig. 5 Fitting diagram of relationship between controller workloadand aircraft sorties 如图5(a)可知:合肥区域01号扇区小时进入架次集中分布在25~40架次,根据管制员工作负荷阈值70%回归得到扇区小时容量为53架次,且从图上可以看出管制员工作负荷波动范围较小。8 d历史最高小时进入架次为45时,仅对应63%管制员工作负荷,表示扇区运行仍有潜力可挖。因此,该扇区符合E类扇区的复杂度一般,工作负荷主要来源于交通量的运行特征,扇区分类结果合理。 由图5(b)、图5(c)可知:根据管制员工作负荷阈值70%回归得到的区域02、03号扇区小时容量分别为31、28架次。扇区历史运行中存在着大量超过管制员工作负荷阈值70%的进入架次数据点,处于高负荷运行状态;同一架次数下对应的管制员工作负荷区间波动明显。由此可以得出,合肥区域02、03号扇区运行的复杂程度和管制压力及调配难度与B类扇区一致,分类结果合理科学。 由图5(d)可知:合肥区域04扇区小时进入流量集中分布在33~50架次之间,扇区交通流量较大。管制员工作负荷存在一定程度上的波动,说明在同一进入架次数值下对应的运行情况有较大不同。根据管制员工作负荷阈值70%回归得到的扇区小时容量为43架次,对比历史运行情况,扇区超容明显。因此,将合肥区域04扇区分为大流量且运行较复杂的A类扇区是合理的。 基于扇区ADS-B数据,选取的我国较为繁忙具有典型性的中南地区和华东地区的区域和进近共97个管制扇区,采用基于遗传算法改进的核模糊C均值聚类算法进行分类研究,研究结果表明: 1)不同交通流和物理结构反映出来的运行特征,对应着扇区内指挥调配的差异。基于运行特征的扇区分类研究,有助于减少管制员在相似运行特征扇区之间转换工作时所需的培训。同时为管制扇区的分类专项管理提供理论基础。 2)结合聚类有效性指标和聚类的可解释性,将97个管制扇区划分为5种不同类型,扇区运行特征在不同扇区间存在明显差异,表明了模糊聚类算法相比于传统硬聚类算法在处理扇区分类这种现实问题方面的有效性。同时采用遗传算法寻找最优聚类中心的方法,对传统的核模糊聚类算法进行了优化,提高了算法划分的准确程度。 3)选取合肥4个区域扇区进行扇区管制员工作负荷与进入架次的拟合分析,各扇区的运行特征与拟合结果的匹配程度验证了扇区分类结果的合理性。各类扇区不同的交通流反映出来的运行动态特征,是将航空器空间行为和扇区繁杂程度及管制员工作负荷进行关联比较的有效途径。结合管制运行实际情况,对运行态势复杂的高负荷运行扇区可以进一步优化其空域结构、科学调整扇区数量和使用方式,以期增加调配裕度,降低管制难度,使各扇区间工作负荷更趋均衡。同时对尚未饱和的扇区,深挖内部潜力,充分利用空中交通管制资源。以求实现容量、流量、人员之间的最佳匹配,全面提升扇区空域运行品质。2.3 GA-KFCM算法优化验证实验
2.4 最佳聚类数确定

3 扇区聚类实例分析
3.1 聚类变量选取


3.2 确定最佳聚类数
3.3 扇区聚类结果
3.4 分类结果验证

4 结 论
猜你喜欢
计算机技术与发展(2022年7期)2022-08-02
南北桥(2022年2期)2022-05-31
西华大学学报(自然科学版)(2022年2期)2022-03-17
科技信息·学术版(2021年1期)2021-12-17
科学与财富(2021年33期)2021-05-10
航空维修与工程(2021年1期)2021-04-12
青年生活(2020年31期)2020-10-14
科学与财富(2019年6期)2019-04-04
电脑知识与技术(2018年12期)2018-07-12
电脑知识与技术·经验技巧(2017年9期)2018-02-24
