
基于误差反馈和面部后先验信息的人脸超分辨率重建
2022-04-21 03:02杨巨成左美然白亚欣陈亚瑞
天津科技大学学报 2022年2期
杨巨成,左美然,魏 峰,孙 笑,白亚欣,王 嫄,陈亚瑞
(1. 天津科技大学人工智能学院,天津 300457;2. 天津科技大学机械工程学院,天津 300222)
人脸超分辨率(face super-resolution,FSR)是一种低水平的计算机视觉任务,其目标是从低分辨率输入中恢复高分辨率人脸图像,提高后续人脸图像任务的性能,如人脸对齐[1]、人脸检测[2-3]和人脸识别[4-6].随着深度学习的发展,尽管人脸超分辨率方法提供了很多解决方案,但是这些方法依然存在以下两个问题.
一方面,目前典型的方法[7-8]利用前馈结构,从输入的低分辨率图像计算一系列中间特征,通过一次或有限次上采样操作直接增加图像分辨率到最终高分辨率结果.SRCNN[9]对输入的低分辨率图像直接进行插值上采样到最终尺寸,然后再进行特征提取和重建.FSRNet[10]设计了编码解码的结构,在编码器中对低分辨率输入进行一次上采样到中间表示,然后通过解码器对提取的特征进一步上采样到最终尺寸.此外,LapSRN[11]和EDSR[12]利用多个上采样子网络,逐步对低分辨率输入进行上采样.上述这些方法采用前馈结构,然而人类视觉系统更倾向于使用反馈连接指导任务[13].因此,这些网络由于缺乏反馈难以充分表示低分辨率输入到高分辨率结果的映射,特别是在放大倍数较大(如8倍放大)的情况下导致生成图像存在模糊、纹理粗糙等问题.
另一方面,人脸超分辨率方法的解空间随着放大倍数的增加呈指数增长,所以研究者们尝试使用强大的人脸先验约束生成高质量的人脸图像.PMGMSAN[14]使用预先训练的网络提取面部成分或解析映射图,并将先验信息输入到后续网络中以恢复超分辨率结果.然而,PMGMSAN直接从低分辨率输入中提取先验信息,使得获得准确的先验信息成为一个困难和挑战.多阶段人脸超分辨率方法[15]则将先验估计分支嵌入到超分辨率重建分支中.首先对低分辨率输入进行初步采样,然后利用中间特征估计先验信息以进行后续重建,并通过L2损失约束估计的先验信息以及由高清人脸图像生成的先验信息.由于上述方法从低分辨率输入、中间结果或特征中提取人脸先验信息,导致先验信息不准确,并且使用像素级先验损失函数如L2作为约束条件,因此难以提供强有力的约束,使得生成的图像模糊,感知质量较差.
鉴于上述问题,本文提出一种基于误差反馈和面部后先验信息的人脸超分辨率重建方法(face superresolution using error feedback and facial posterior,EFBNet),并通过一个包含通道级的面部注意力损失和相对判别器对抗损失的优化目标训练网络.首先,采用一系列上下采样操作捕获低分辨率输入到高分辨率结果之间的相互依赖性,提取多粒度特征,并提出误差反馈机制优化提取到的多粒度特征.通过上采样操作计算生成高维特征图与输入之间的误差,通过下采样操作计算生成低维特征图与输入之间的误差.误差反馈机制可以在早期自校正特征提取,并引导网络提取与面部细节相关区域的特征,以充分表示低分辨率输入到高分辨率结果的映射,生成高质量的人脸图像.然后,为了得到精确的先验信息,采用面部先验信息提取和人脸超分辨率重建相互促进的结构,从超分辨率结果而不是低分辨率输入或中间特征提取精确的先验信息,即后先验信息.先验估计分支利用重建的图像提取后先验信息,精确的后先验信息进而促进生成更高质量的人脸图像.最后,为了借助精确的后先验信息进一步提供强有力的约束,设计了一个新的优化目标,它在L2损失的基础上引入通道级的面部注意力损失和相对判别对抗损失.面部注意力损失聚焦于后先验信息周围区域的特征,相对判别对抗损失专注于锐化的边缘,生成内容精确、纹理逼真的超分辨率结果.在标准数据集上的实验表明,本方法在定量指标上达到了当前最优性能,可视化结果进一步表明该方法在清晰度、失真程度和纹理细节等方面具有显著优势.
1 模型设计
1.1 网络结构
提出了一种基于生成对抗网络的使用误差反馈和面部后先验信息的人脸超分辨率方法.其中输入的低分辨率人脸图像、超分辨率结果和高清人脸图像分别表示为ILR、ISR和IHR.生成器由两个分支组成:基于误差反馈的迭代上下采样重建分支(简称重建分支)和生成后先验信息的人脸关键点估计分支(简称关键点估计分支).判别器采用ESRGAN[8]中的结构.整个网络以端到端的方式进行训练.基于误差反馈和面部后先验信息的人脸超分辨率模型如图1所示.

图1 基于误差反馈和面部后先验信息的人脸超分辨率模型Fig. 1 Face super-resolution using error feedback and facial posterior information
重建分支包含3个部分:粗上采样模块(CUM)、基于误差反馈的迭代上下采样模块(EFSM)和全局跳跃连接.全局跳跃连接绕过粗上采样模块和基于误差反馈的迭代上下采样模块,为结果提供一个插值上采样的图像.因此,粗上采样模块和基于误差反馈的迭代上下采样模块用于恢复ILR的残差图像Ires.
由于从非常低分辨率的输入中获得先验信息不精确,因此首先通过粗上采样模块恢复粗糙的上采样结果.该模块由卷积层和像素重组层组成,输出为

其中fCUM表示粗上采样操作.1F与关键点估计分支的输出 Flandmark拼接在一起作为基于误差反馈的迭代上下采样模块的输入.Fconcat是拼接的结果.
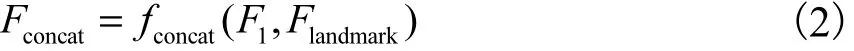
其中fconcat表示拼接操作.
在基于误差反馈的迭代上下采样模块中采用循环结构,其可以展开为T次迭代.第t次迭代(t∈T)中EFSM接收 Fconcat和上一次迭代的输出表示EFSM的最终输出,即
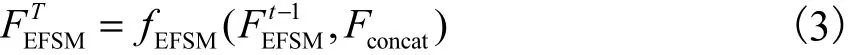
其中fEFSM表示EFSM的操作.
为了与全局跳跃连接提供的插值上采样图像匹配,使用卷积操作得到残差图像Ires,即

其中fconv表示卷积操作.
最终的输出ISR为

其中fup表示通过全局跳跃连接提供的插值上采样操作.
关键点估计分支的体系结构遵循文献[15].
1.2 基于误差反馈的迭代上下采样模块
基于误差反馈的迭代上下采样模块由一系列上下采样块组成,共N个采样块,在低分辨率和高分辨率特征图之间交替.此外,在此模块中引入密集连接充分利用特征.先前所有下采样(上采样)块的输出串联起来作为上采样(下采样)块的输入,如图1所示.这种连接能够有效地利用各种高分辨率成分产生理想的结果.
在第n个上采样块中:先前n−1个下采样块计算出的低分辨率特征图被拼接为Ln−1,并作为第n个上采样块的输入(n∈N),结构图如图2(a)所示,其定义为
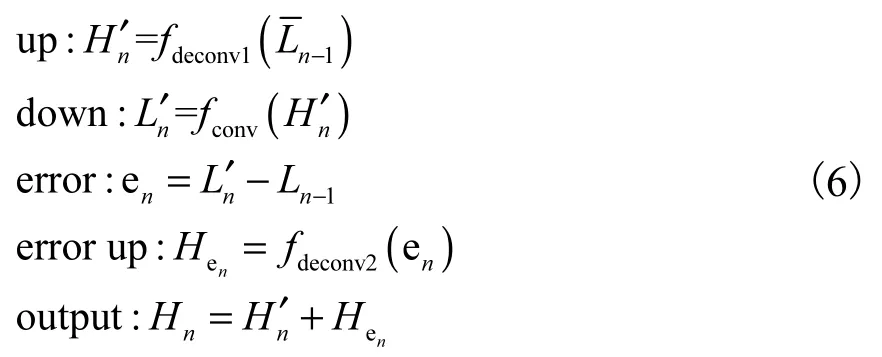
其中:fdeconv1和fdeconv2表示s倍的上采样操作,fconv表示s倍的下采样操作.
第n个上采样块将Ln−1映射到中间高分辨率集合,然后再将其映射回低分辨率集合.产生的和之间的误差再次映射到高分辨率,从而产生新的中间误差集合Hen.通过将两个中间集合相加得到该块的最终输出Hn.
下采样块的定义与上采样块非常相似,但它将高分辨率特征图映射到低分辨率空间,如图2(b)所示,定义为
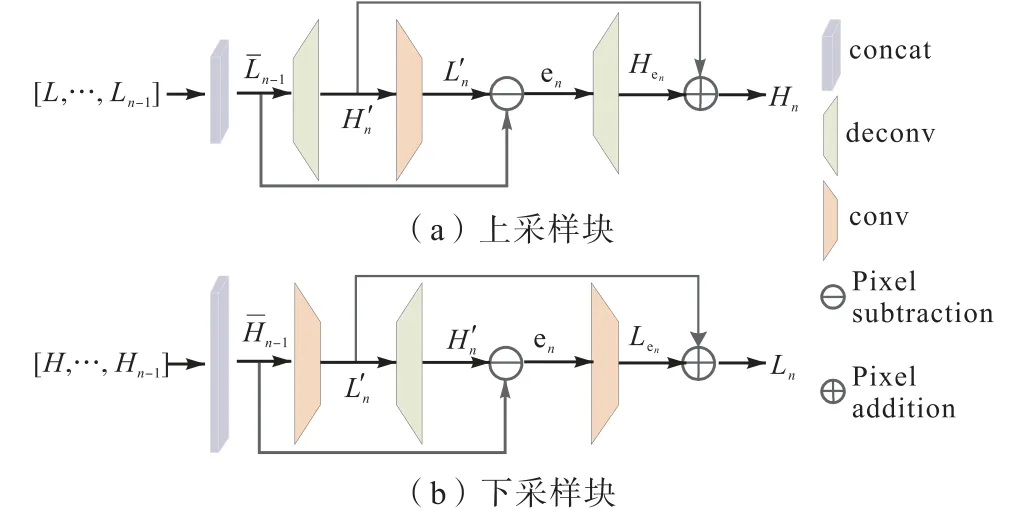
图2 上采样块和下采样块Fig. 2 Up-sampling block and down-sampling block
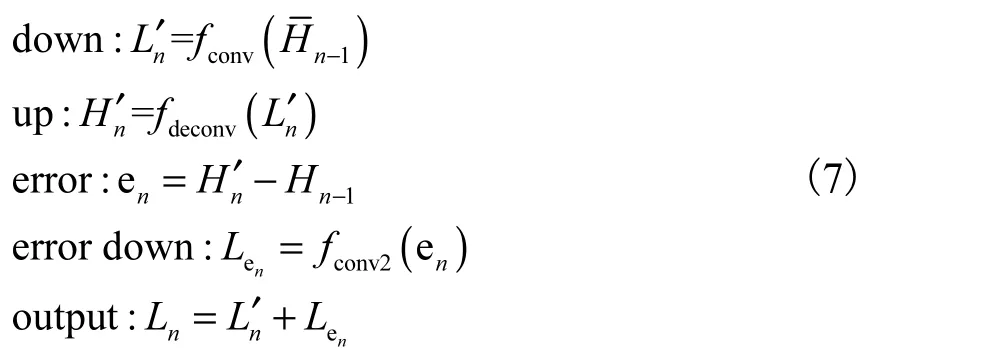
这些采样块可以理解为一种自我校正过程,该过程将误差反馈到采样层,并通过反馈误差迭代地修改中间表示,有助于引导网络更关注与面部细节有关的区域.
2 优化目标
为了提供强有力的约束,设计优化目标,该优化目标包括关键点损失、面部注意力损失、像素损失、感知损失和相对判别对抗损失.
关键点损失( Llandmark):在关键点估计分支,使用Llandmark计算在像素级最小化ISR的关键点热图LSR和IHR的关键点热图LHR之间的距离.
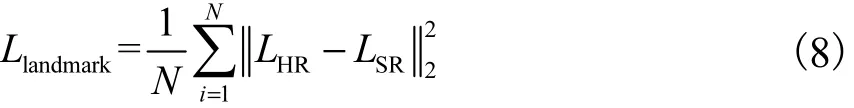
面部注意力损失( Lattention):除关键点损失外,还使用面部注意力损失关注预测的关键点周围区域的面部细节.这使关键点估计分支自适应地引导与关键点有关的特征,而不必过多关注那些特征较少的区域.
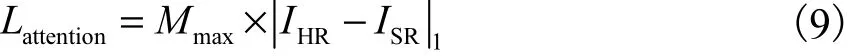
其中Mmax为LHR的通道最大值.
像素损失(Lpixel):使用L2损失作为IHR和ISR之间的像素损失.
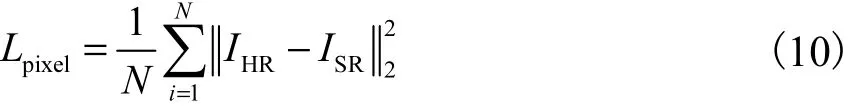
感知损失(Lperc):应用感知损失增强超分辨率图像的感知质量[10,16].采用预训练的人脸识别模型VGG19[17]提取图像特征.该损失通过减小IHR和ISR特征之间的欧氏距离提高感知相似度,其中φ(ISR)和φ( IHR)分别是通过VGG19网络提取的图像特征.
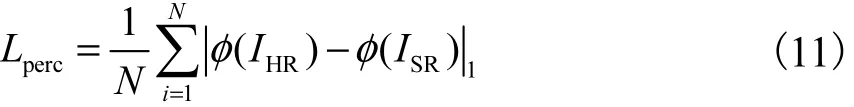
相对判别对抗损失(DL):不同于标准判别器D估计一个输入图像是真实和伪造的概率,本文采用RaGAN[18]的思想试图预测真实图像比伪造的相对更真实的概率.
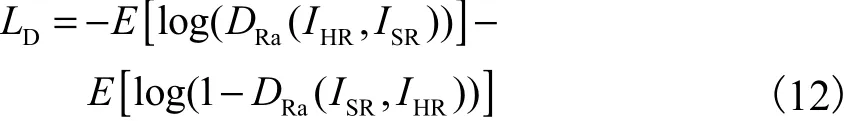
其中DRa表示RaGAN的判别器.
生成器试图欺骗判别器并最小化对抗损失Ladv.
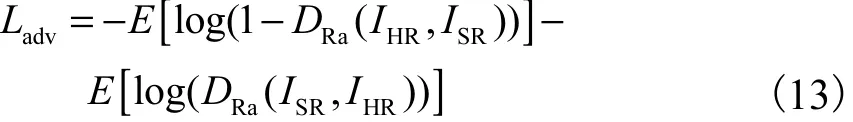
最终,生成器的损失函数定义为
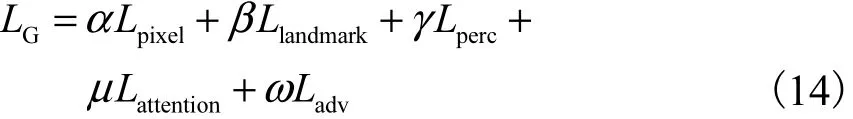
其中α、β、γ、μ、ω 均为模型的训练参数.
3 实验与分析
3.1 实验细节
数据集:模型在两个常用的人脸数据集Helen[19]和CelebA[20]进行了充分的实验.对于这两个数据集,先使用OpenFace[21-22]检测IHR的68个关键点.根据检测的关键点,在每幅图像中裁剪正方形区域以删除背景,并将像素大小调整为128×128,而无需任何预对齐.然后,将这些高清人脸图像采样到16×16的低分辨率输入.对于CelebA数据集,使用168854张图像进行训练,使用1000张图像进行测试.对于Helen数据集,使用2005张图像进行训练,使用50张图像进行测试.
实验设置和训练设置:本文提出的EFBNet模型在两个分支之间进行了4次迭代.由于Helen数据集的图像数量很少,因此对训练图像执行数据增强,训练图像随机旋转90°、180°、270°并水平翻转.模型中的训练参数分别设置为α=1、β=0.1、γ=0.1、μ=0.1和ω=0.05.该模型由ADAM优化器[23]训练,其中β1=0.9、β2=0.999和ε=1×10-8.初始学习率是1×10-4,并在1×104、2×104、4×104次迭代后逐次减半.实验基于Pytorch[24]在NVIDIA TITAN RTX(24G)上实现.
评估指标:与之前的模型相似[9-10,16],本文使用常用的评估指标峰值信噪比(PSNR)和结构相似度(SSIM)[25]评估重建性能.
3.2 与现有方法比较
在两个常用人脸数据集CelebA和Helen上将本文提出的方法与最新方法进行了比较.
对CelebA数据集的评估:将本文提出的EFBNet与其他方法在定性和定量上进行比较,其中包括一般的超分辨率方法(SRCNN[9]、SRGAN[16]和EDSR[26])和人脸超分辨率方法(FSRNet[10]和SAAN[27]).所有模型都使用相同的训练集进行训练.如表1所示,当放大倍数为8时,EFBNet在PSNR和SSIM方面均明显优于其他方法.图3为在CelebA数据集上与现有其他方法的可视化对比,其中GT代表高清人脸图像.由此可见,EFBNet借助误差反馈及时进行自校正处理,获得了更好的推理结果.精确的后先验信息和强有力的监督进一步优化面部的纹理细节,提高图像的视觉保真度.此外,在图3中,EFBNet不仅能够重建清晰的面部结构,而且具有很强的鲁棒性,对于姿势和旋转变化大的人脸具有接近真实的恢复效果.这主要得益于人脸先验估计使用超分辨率结果生成更准确的后先验信息,从而鼓励重建分支进一步增强人脸图像质量.
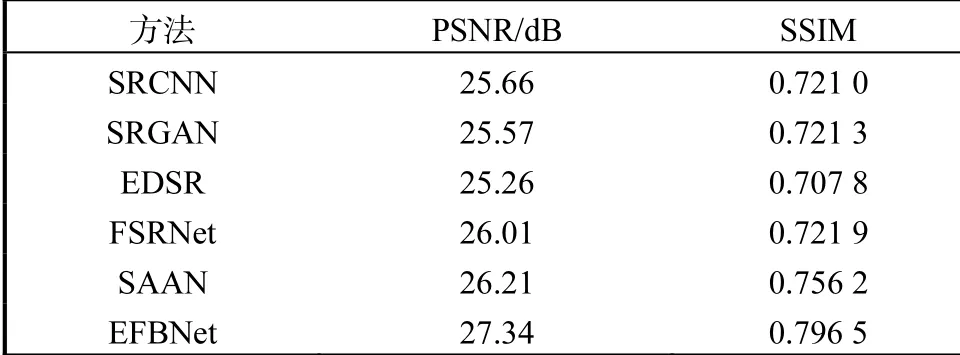
表1 在CelebA数据集的定量对比Tab. 1 Quantitative comparison on CelebA datasets

图3 在CelebA数据集上与现有其他方法的可视化对比Fig. 3 Visual comparison with state-of-the-art methods on CelebA datasets
对Helen数据集的评估:当放大倍数为8时,将本文提出的EFBNet与其他人脸超分辨率方法[10,28-29]进行了定性和定量的比较,结果如表2和图4所示,其中图4中LR代表输入的低分辨率人脸图像,GT代表高清人脸图像.从表2中可以看出,EFBNet在Helen测试集上实现了最高性能,比现有的人脸超分辨率方法(FSRNet)高2.98dB.与其他方法的可视化结果对比可看出,受益于误差反馈和提出的优化目标,EFBNet生成的人脸图像五官结构完整且更加清晰.由于引入面部注意力损失,其引导网络学习更真实的面部细节,故相较于其他方法,在眼睛、嘴巴等部位的纹理细节信息更加丰富且失真程度小.
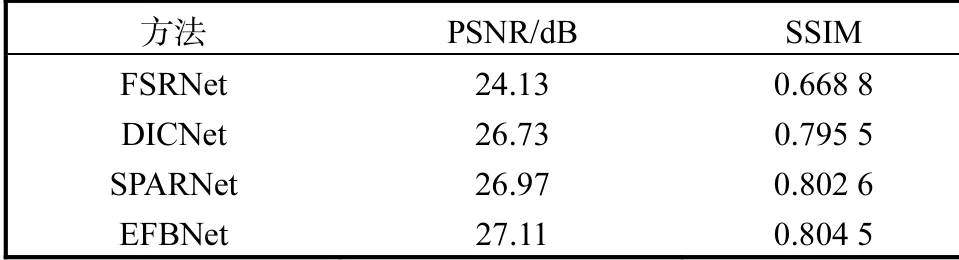
表2 在Helen数据集的定量对比Tab. 2 Quantitative comparison on Helen datasets

图4 在Helen数据集上与现有方法的可视化对比Fig. 4 Visual comparison with state-of-the-art methods on Helen datasets
3.3 对比实验
误差反馈的影响:为了说明误差反馈机制的有效性,当放大倍数为8时,对比有和没有误差反馈机制(命名为EFBNet_L)对PSNR和SSIM的影响.分别用卷积和反卷积操作替换上采样块和下采样块,则基于误差反馈的迭代上下采样模块类似于先前的超分辨率方法[30].其可视化比较如图5所示.

图5 误差反馈机制对实验结果的影响Fig. 5 Visual results using error feedback mechanism
由图5可知,本文提出的EFBNet能够保留像素级精度,同时提高面部图像的感知质量.原因是误差反馈将引导特征提取关注与面部细节有关的区域,以优化当前预测.因此,它可以实现从低分辨率输入到超分辨率结果的较优映射,以生成更好细节的人脸图像.
损失函数的影响:3个实验分析面部注意力损失和相对判别对抗损失对Helen数据集的影响,分别命名为model 1、model 2和model 3(本文的优化目标).表3为使用不同损失函数的定量对比.

表3 使用不同损失函数的定量对比Tab. 3 Quantitative results of using different loss functions
由表3可知,model 2的性能优于model 1.这是由于面部注意力损失使网络在通道级更关注面部的关键点区域,从而产生更清晰的面部图像且失真小.此外,相对判别对抗损失有助于学习更锐利的边缘和更详细的纹理.因此,model 3较model 2添加相对判别对抗损失后,定量指标几乎没有改善,但是面部图像更加逼真自然,尤其是纹理细节方面(图6).总之,model 3不仅着眼于面部关键点区域以减少失真,而且迫使网络恢复更具结构意义的面部细节以得到清晰逼真的结果.

图6 损失函数对实验结果的影响Fig. 6 Visual comparisons for showing the effects of different loss function
不同先验信息的影响:与FSRNext[10]类似,本文使用人脸对齐模型广泛使用的度量指标归一化均方根误差(NRMSE),探究先验信息提取顺序对超分辨率图像质量的影响.较低的NRMSE 值表示更好的对齐精度和更高的SR图像质量.FSRNet在中间特征中提取面部关键点和面部解析映射图指导超分辨率重建,而SAAN从输入和中间结果中自适应地提取面部语义信息作为先验信息.不同的先验信息对超分辨率图像质量的影响见表4.由表4可以看出,EFBNet方法均优于其他方法.虽然其他方法也使用面部先验,例如面部关键点和面部解析映射图等,但先验信息是从输入的低分辨率图像或中间特征中估计的.因此,这种面部先验只能为重建过程提供有限的指导,导致恢复结果存在不完整的、模糊的面部结构.不同的是,本文提出的EFBNet使用生成的超分辨率结果估计先验信息,即后先验信息,以便为重建提供更准确的指导信息,得到更清晰的超分辨率结果.

表4 不同的先验信息对超分辨率图像质量的影响Tab. 4 Influence of different prior information on the quality of super-resolution images
4 结 语
本文提出的EFBNet方法是基于生成对抗网络使用误差反馈和面部后先验信息指导网络生成高质量的人脸图像,并通过一个新的优化目标训练网络.在该方法中,人脸超分辨率重建和人脸后先验估计相互促进,以产生准确的后先验约束.误差反馈机制帮助重建分支迭代的优化中间表示.优化目标中的面部注意力损失,其基于强大的后先验信息在通道级约束解空间和相对判别对抗损失,其专注于恢复清晰的边缘纹理,驱动网络生成高分辨率的、更好面部纹理细节的图像.在公开的人脸数据集上进行的人脸超分辨率的实验显示出本文方法的显著优势.
致谢:本论文还获得了天津市企业科技特派员项目(20YDTPJC00560)和天津市研究生科研创新项目(人工智能专项)(2020YJSZXB11)的资助.
猜你喜欢
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
海外文摘·艺术(2020年22期)2020-11-18
广东教育·高中(2017年10期)2017-11-07
米娜·女性大世界(2016年8期)2016-08-17
岁月(2016年5期)2016-08-13
