
基于多模态生成模型的半监督学习
2022-04-21 03:03陈亚瑞张芝慧杨剑宁王浩楠
天津科技大学学报 2022年2期
陈亚瑞,张芝慧,杨剑宁,王浩楠
(天津科技大学人工智能学院,天津300457)
在过去很长时间里,研究者的注意力主要集中在监督学习的问题上,换句话说,研究者主要基于标记数据训练分类器.随着大数据时代的到来,数据呈现爆炸式增长,从海量数据中获得每个数据的标签是比较困难的.“标记数据少,而未标记数据多”在大数据时代是越来越普遍的现象.
若利用监督学习方法,仅使用已有的少量有标记样本,不仅模型的泛化能力较差,而且浪费了大量未标记样本中的信息.半监督学习是一种介于监督学习和无监督学习之间的机器学习方法[1].半监督学习是充分利用样本中“廉价”的未标记样本,让学习器不依赖外界交互、自动地利用未标记样本提升学习性能[2].
在各类半监督学习方法中,基于生成方法(generative method)的半监督学习受到了研究者的极大关注[3].生成方法是基于生成模型(generative model)的一类方法,该类方法假设数据是由潜在的模型“生成”的.这个假设能通过潜在模型的参数将未标记数据与学习目标联系起来,其中未标记数据的标记可看作模型的缺失参数.深度生成模型[4-5],如变分自编码(variational auto-encoding,VAE)模型、生成对抗网络(generative adversarial network,GAN)等,通过将生成模型与多层神经网络相结合提高模型的表示能力,同时实现对图像的自动生成,在图像、视频处理方面有着重要的应用.
VAE是当前机器学习领域经典的深度生成模型之一,该模型于2013年由Kingma等[6]提出.该模型主要由推理模型和生成模型两部分组成,推理模型的作用是通过变分推理模型将高维数据降到低维特征空间中,生成模型的作用是从低维特征中重构出原始高维数据.VAE可以对原数据进行重构,同时可以利用其生成模型生成新的数据样本,但该模型很难生成特定的图像样本.
Sohn等[7]在VAE模型基础上提出了条件变分自编码(conditional variational auto-encoding,CVAE)模型. 该模型是一种监督学习方式,通过分别在VAE推理模型和生成模型的输入变量中加入标签变量的方式,实现生成特定图像.这种做法不仅丰富了特征空间的结构,而且还使得模型可以生成指定样本.Kingma等[8]提出基于深度生成模型的半监督学习模型(semi-supervised learning with deep generative models,SS-DGM).该模型将CVAE拓展到半监督学习领域,训练过程中充分利用少量标记样本与大量无标记样本.该模型在处理标记样本时,对于推理模型部分,以样本与标签连接作为输入,以连续隐向量作为输出;对于生成模型部分,以隐变量和标签连接作为输入,此时输出为重构样本.该模型在处理无标记样本时,将标签看作隐向量,对于推理模型部分,以样本作为输入,以连续隐变量和标签隐变量作为输出;对于生成模型部分,以推理模型的输出作为生成模型的输入,此时输出重构样本.
相比条件变分自编码方法,本文提出一种基于多模态生成模型的半监督学习(semi-supervised learning based on multimodal generating model,SS-MGM)算法.模型将样本看作数据的一种模态,将样本和标签联合在一起的形式称之为多模态信息,在生成模型中生成样本及其标签.
对模态的理解不仅仅限于以上定义,在生活中,人类无时无刻不在与各种信息互动,而每一种信息的来源或者形式都可以被称为一种模态,也就是人们的感官即触感、听觉、视觉和嗅觉都可以定义为模态.而多模态是指对两种或两种以上感官的融合进行信息处理[9].SS-MGM模型在处理标记样本时,对于推理模型部分,以样本和标签作为输入,以连续隐变量作为输出;对于生成模型部分,以上述连续隐变量作为输入,同时输出重构样本及重构标签.SSMGM模型在处理无标记样本时,对于推理模型部分,以样本作为输入,以连续隐变量和标签隐变量为输出;对于生成模型部分,以隐变量作为输入,输出重构样本及重构标签.SS-MGM模型不仅在推理模型可以得到标签,在生成模型也可以得到标签概率.最后在MNIST数据集和FASHION_MNIST数据集上通过对比实验,验证SS-MGM模型有效提高了预测标签精度.
1 变分自编码
变分自编码(VAE)一经问世就备受人们的关注与讨论,模型创新性地结合了变分生成模型和深度神经网络,形成了深度生成式网络结构[6].模型用大量样本对模型进行训练,之后只需使用模型的生成器部分,可以自动生成大量训练样本.变分自编码作为深度生成模型的典型代表之一,在图像生成和数据生成等方面有着重大影响,具有重要的研究价值.
对于变分自编码模型,令x表示观测变量或样本,z表示连续隐变量,p(x,z)表示模型的联合概率分布.联合概率分布可以表示为生成模型形式:其中p(z)是隐变量先验分布,是条件概率分布,θ是模型的参数.生成过程的概率图模型如图1所示,图中白色圆圈代表隐变量z,灰色圆圈代表观测变量x,圆圈之间的黑色实线表示生成过程,箭头代表生成方向.
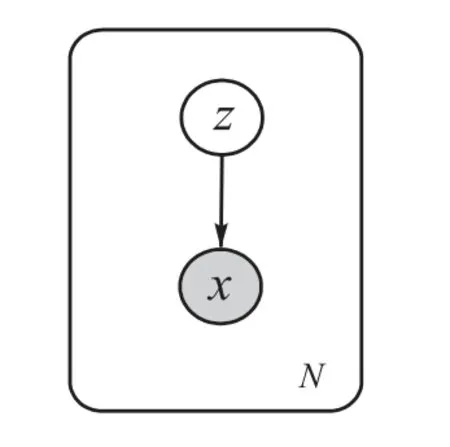
图1 VAE概率图模型Fig. 1 Probability graphical model of VAE
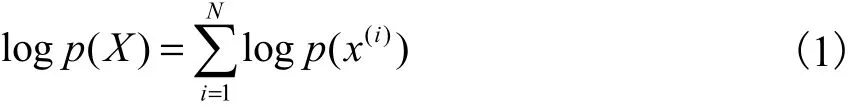

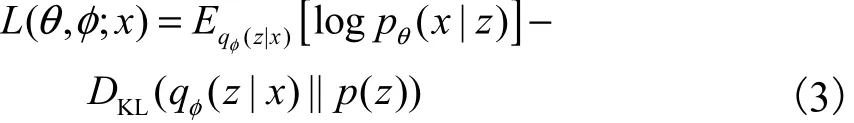
Kingma等[6]提出一种重参数化方法求解变分下界的优化问题.对于隐变量z通过引入标准多维高斯分布进行重参数化,即
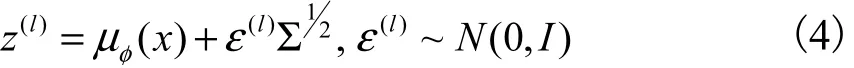
基于重参数化的变分下界的表示形式为
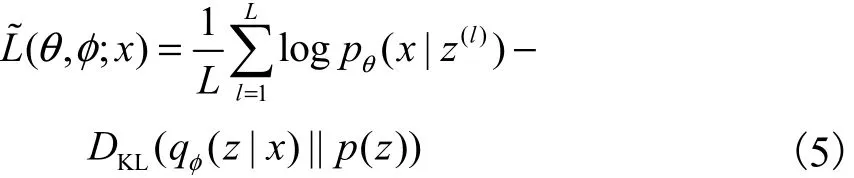
最后选用随机梯度下降方法[11]对模型的参数进行优化更新.
2 条件变分自编码
VAE是一种无监督学习方法,无法生成特定类别的数据,基于这个研究需求,Sohn等[7]提出条件变分自编码(CVAE),该模型在VAE[6]的基础上对推理过程和生成过程都加入标签变量y.CVAE包含3种变量,为观测变量x、连续隐变量z和离散类变量y,联合概率分布为
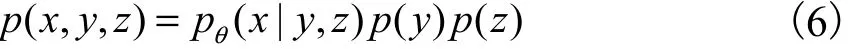
其中:p(z)为隐变量的先验分布,p(y)为标签变量先验分布, pθ( x|y,z)为条件概率分布,θ为模型参数.生成过程的概率图模型如图2所示.
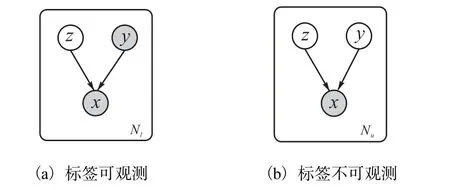
图2 CVAE概率图模型Fig. 2 CVAE probability graph model
与VAE原理类似,CVAE通过最大化变分下界实现最大化对数边际似然.在标签可观测的情况下,引入变分推理模型,模型的变分下界为
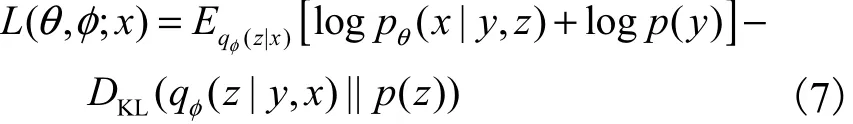
模型参数{θ,}φ的优化同样使用重参数化技巧[6],即
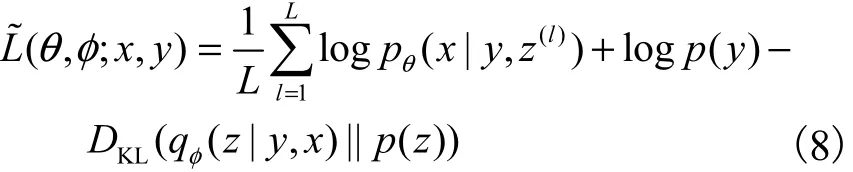
在标签不可观测的情况下,y视为隐变量,将变分推理模型分解为得到变分下界为
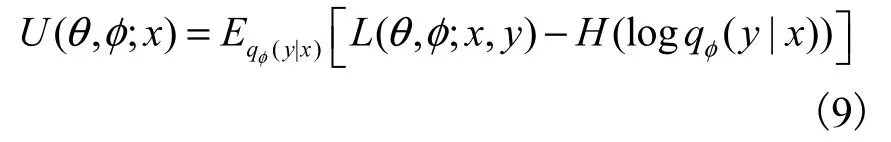
重参数后的变分下界为
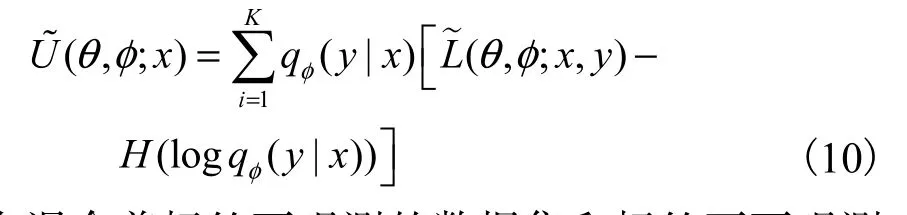
在混合着标签可观测的数据集和标签不可观测的数据集中,由于变分推理模型qφ( y|x)只在标签不可观测的数据集上训练,所以在最终优化目标中添加交叉熵损失.此时CVAE的变分下界为
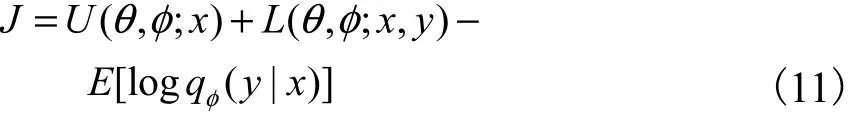
最终通过随机梯度下降算法求解优化问题.
3 本文算法的构建
本文提出一种基于多模态生成[9]的半监督学习模型.首先给出多模态生成模型表示形式,然后分别分析相应的监督学习及无监督学习过程,最后提出多模态半监督深度模型.对于少量“有标记样本集”lD及 大 量“未 标 记 样 本 集” Du,令,其中l表示标记样本个数,,其中u表示未标记样本个数,并且l≪u.
多模态概率生成模型的联合概率分布为
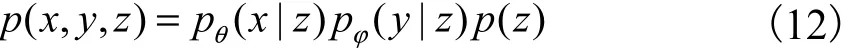
其中:p(z)表示隐变量z的先验概率分布,通常选择标准高斯分布,即表示标记的类条件分布,即是它的参数表示图像的条件概率分布,θ是模型的参数.生成过程的概率为
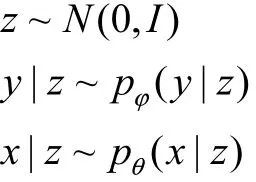
3.1 基于多模态生成的监督学习
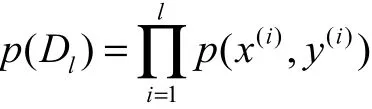
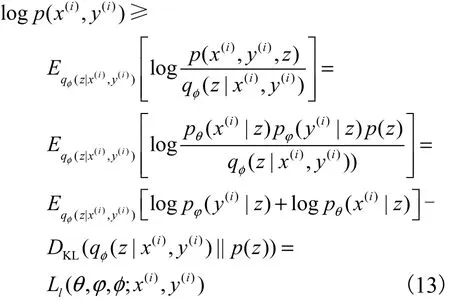
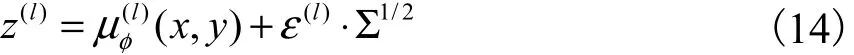
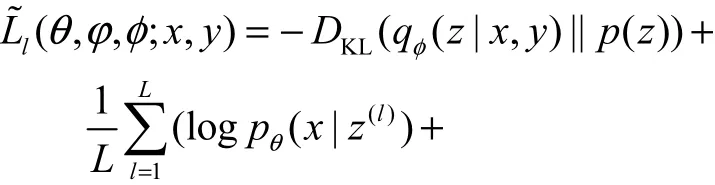
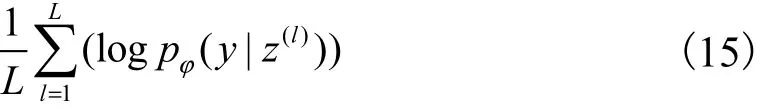
图3为SS-MGM对带标记的样本学习的概率图模型,实线表示生成过程,虚线表示推理过程.

图3 SS-MGM在监督学习下的概率图模型Fig. 3 Probabilistic graph model of SS-MGM under supervised learning
整个标记数据集lD的变分下界可以采用批处理方法完成.即从数据集lD中随机取K个样本数据作为一个批次,构造基于一个批次的完整数据集的变分下界
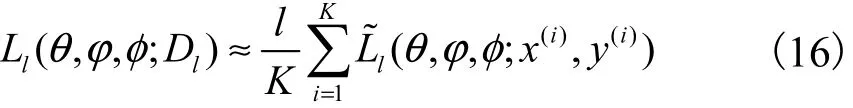
具体算法如算法1所示.
算法1:基于多模态生成的监督深度模型学习过程.
输入:数据集lD,K=1000,L取值为1.
输出:模型参数{θ,ϕ}φ, .
随机初始化参数θ,ϕφ,.
REPEAT:
DO{
将lD随机打乱,从中取出K个样本作为一个批次.
DO{
1. 将一批次样本输入到推理模型,得到隐变量的均值μ和方差Σ.
2. 从噪声的高斯分布中采样出ε(l).
3. 根据重参数化公式,对均值μ和方差Σ进行重参数化技巧采样.
4. 重参数化后的隐变量,输入到两个生成模型分别生成数据和标签概率.
5. 计算变分下界.
6. 对变分下界取负值后得到损失函数.
7. 结合Adam Optimizer优化器最小化损失函数.
8. 更新推理模型和生成模型的参数{θ,ϕ}φ, .
}WHILE(数据集全部取完).
}WHILE(参数{θ,ϕ}φ, 收敛).
终止算法.
RETURN参数{θ,φ,φ}.
3.2 基于多模态生成的无监督学习
对于大量未标记数据集uD,由于标签变量y是未知的,将其视为离散隐变量,此时模型中有z和y两个隐变量,后验分布形式为.精确求出后验分布具有一定难度,所以引入变分推理模型.通常变分推理模型分解为.数据x的变下界为

其中H(.)是熵.变分下界 Lu(θ,ϕ,φ;x)的优化需要近似qφ( y|x)的期望,所以选择对y的可能值进行求和.图4为SS-MGM算法在无监督学习下的概率图模型.
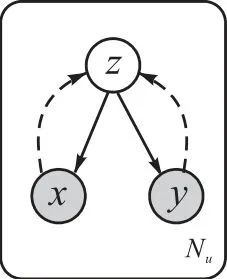
图4 SS-MGM算法在无监督学习下的概率图模型Fig. 4 Probabilistic graph model of SS-MGM algorithm under unsupervised learning
重参数化后的变分下界为
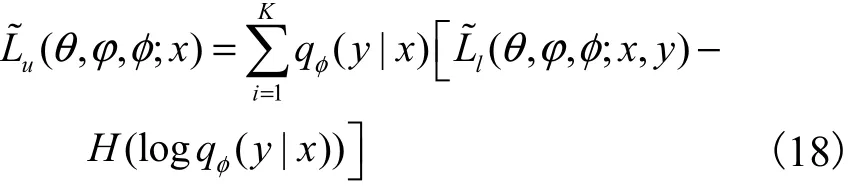
数据集uD可以采用批处理的方法构造边缘似然函数,从包含u个数据点的数据集中随机取出K个数据作为一个批次,构造基于一个批次的完整数据集的变分下界
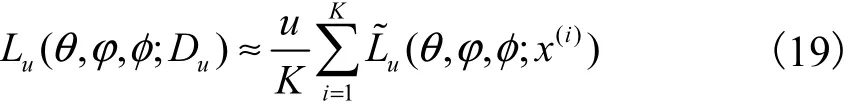
述如算法2所示.
算法2:基于多模态生成的无监督深度模型学习过程.
输入:无标签数据集uD,K=1000,L取值为1.
输出:模型参数{θ,ϕ}φ, .
随机初始化参数θ,ϕφ,.
REPEAT:
DO{
将uD随机打乱,从中取K个样本作为一批次.
DO{
1. 一批次样本输入到分类器qφ( y|x)预测得到标签y,将样本与预测的标签相连接输入到推理模型得到隐变量的均值μ和方差Σ.
2. 从噪声的高斯分布中采样出ε(l),对均值μ和方差Σ进行重参数化技巧采样.
3. 重参数化后的隐变量z,输入到两个生成模型分别生成数据x和标签概率y.
4. 计算变分下界.
5. 对变分下界取负值后得到损失函数.
6. 结合Adam Optimizer优化器最小化损失函数.
7. 更新推理模型和生成模型的参数{θ,ϕ}φ, .
}WHILE(数据集全部取完).
}WHILE(参数{θ,ϕ}φ, 收敛).
终止算法.
RETURN参数{θ,φ,φ}.
3.3 本文算法
对 于 少 量“有 标 记 样 本 集” Dl={( x(1), y(1)),( x(2), y(2)),… ,( x(l), y(l))}及 大 量“未 标 记 样 本 集”Du={x(l+1), x(l+2),… , x(l+u)},整个数据集 Dl∪Du的目标函数可视为两个样本集的目标函数之和,即
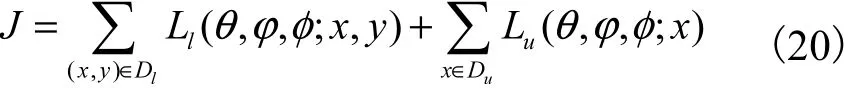
由于推理模型 qφ( z|y,x)在整个数据集下训练,而推理模型qφ( y|x)只在没有标记的数据中训练,这样不利于学习网络参数,所以在标记数据中增加训练qφ( y|x).重参数化后的统一目标函数为
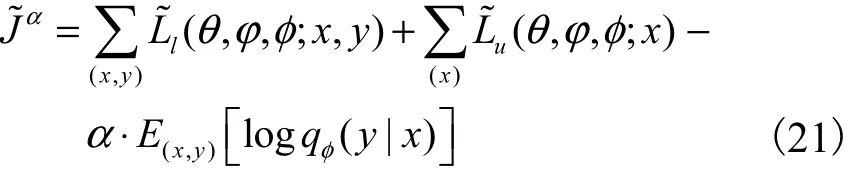
其中α 是控制标签数据集在总数据集中的权重,在实验中设置α=0.1N.
设H1个标记数据和H2个没有标记数据为一个批次,构造基于一个批次的完整数据集的变分下界为
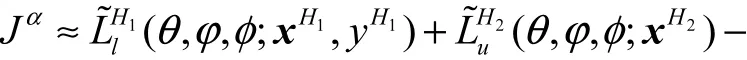
算法3:基于多模态生成的半监督深度模型学习过程.
输出:模型参数{θ,φ,φ}.
随机初始化参数θ,φ,φ.
REPEAT:
DO{
将 Dl∪Du随机打乱,从中取1个样本.
将uD随机打乱,从中取99个样本,将这100个样本作为一个批次.
DO{
1. 标记样本输入到推理模型得到隐变量的均值μ和方差Σ.
2. 从噪声的高斯分布中采样出 ε(l),对均值μ和方差Σ进行重参数化技巧采样.
3. 重参数化后的隐变量z,输入到两个生成模型分别生成数据x和标签概率y.
4. 同时无标记样本输入到分类器qφ( y|x)预测得到标签y,将样本与预测的标签相连接通过推理模型得到隐变量的均值μ和方差Σ.
5. 从噪声的高斯分布中采样出 ε(l),对均值μ和方差Σ进行重参数化技巧采样.
6. 重参数化后的隐变量z,经过两个生成模型生成数据x和标签概率y.
7. 对标记样本和无标记样本计算变分下界.
8. 对变分下界取负值后得到损失函数.
9. 结合Adam Optimizer优化器最小化损失函数.
10. 更新推理模型和生成模型的参数{θ,ϕ}φ, .
}WHILE(数据集全部取完).
}WHILE(参数{θ,ϕ}φ, 收敛).
终止算法.
RETURN 参数{θ,ϕ}φ, .
4 实 验
实验采用MNIST数据集和FASHION_MNIST数据集进行验证.MNIST数据集是一种手写字体识别数据集,包含60000张训练图片和标签以及10000张测试图片和标签.每张图片由28×28=784个像素点组成,通常用一个数字数组表示这张图片.标签是介于0~9的数字,标签数据用“one-hot vectors”的形式表示.
FASHION_MNIST数据集是一种时尚产品图像数据集,包含10种类别,一共70000张物品的图片.它的大小、格式以及训练集、测试集的划分与MNIST数据集完全一致.
4.1 生成图像效果实验
通过SS-MGM模型与CVAE模型[7]在生成图像方面的对比,验证SS-MGM模型在生成图像方面的有效性.首先数据集中有50000个样本,将其分为50个批次,一个批次共有1000个样本输入到模型中,即K=1000.其次选用多层全连接神经网络实现模型参数,其中变分推理模型和生成模型都采用4层神经网络,每层网络有500个隐藏节点.最后隐变量的维度选择z=50,激活函数选用softplus函数.
在实验中,数据x的维度是784维,而标签y的维度是10维.当它们直接连接输入到推理模型进行降维处理时,由于两者维度相差较大,隐变量z的结构中包含标签y的信息较少,这种连接方式会影响模型的精度.所以将不同维度的数据和标签分别经过不同的神经网络处理到相同的256维,之后两者再连接输入到推理模型.
(1)当z的维度设为50时,训练50000个全带标签的MNIST数据集和FASHION_MNIST数据集,任意取10个z值,给定标签0~9,CVAE生成的10张图片分别如图5和图6所示.

图5 MNIST数据集下CVAE生成的图片Fig. 5 Images generated by CVAE under MNIST datasets

图6 FASHION_MNIST数据集下CVAE生成的图片Fig. 6 Images generated by CVAE under FASHION_MNIST datasets
(2)当z的维度设为50时,分别训练50000个全带标签的MNIST数据集和FASHION_MNIST数据集,任意取10个z值,SS-MGM模型生成10张图片以及对应生成图片标签的概率,如图7、图8和表1、表2所示.
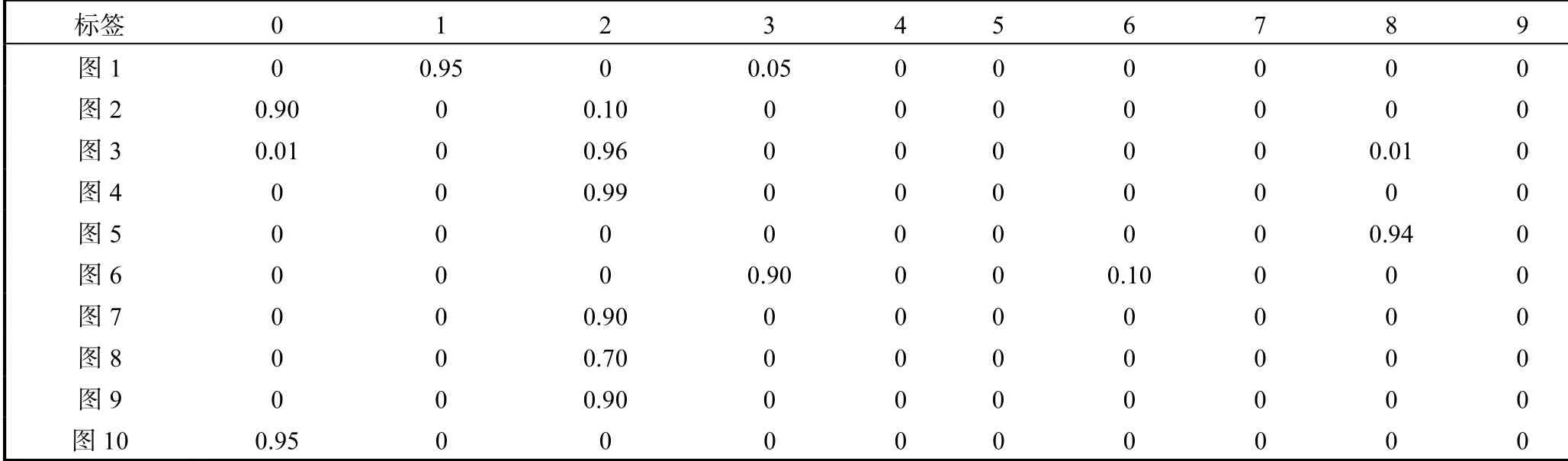
表2 FASHION_MNIST数据集下SS-MGM模型生成的图片对应概率Tab. 2 Corresponding probability of images generated by SS-MGM under FASHION_MNIST datasets
从上述两组对比实验可以看出,SS-MGM模型与CVAE模型[7]相比,SS-MGM模型在生成图像方面有着不错的清晰度,并且SS-MGM模型生成的标签有着较准确的概率,同时可以看出SS-MGM模型生成标签概率的作用.例如对于图7中的第2张图片,由于图片看着既像数字8又像数字1,容易造成失误,但是通过查看SS-MGM模型输出的对应图片的标签概率可以避免这个失误,见表1中的第2行概率,这张图片是数字8的概率是0.70,是数字1的概率为0.30.
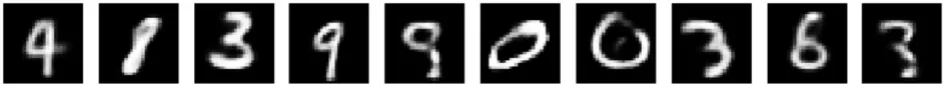
图7 MNIST数据集下SS-MGM模型生成的图片Fig. 7 Images generated by SS-MGM under MNIST datasets

图8FASHION_MNIST数据集下SS-MGM模型生成的图片Fig. 8 Images generated by SS-MGM under FASHION_MNIST datasets
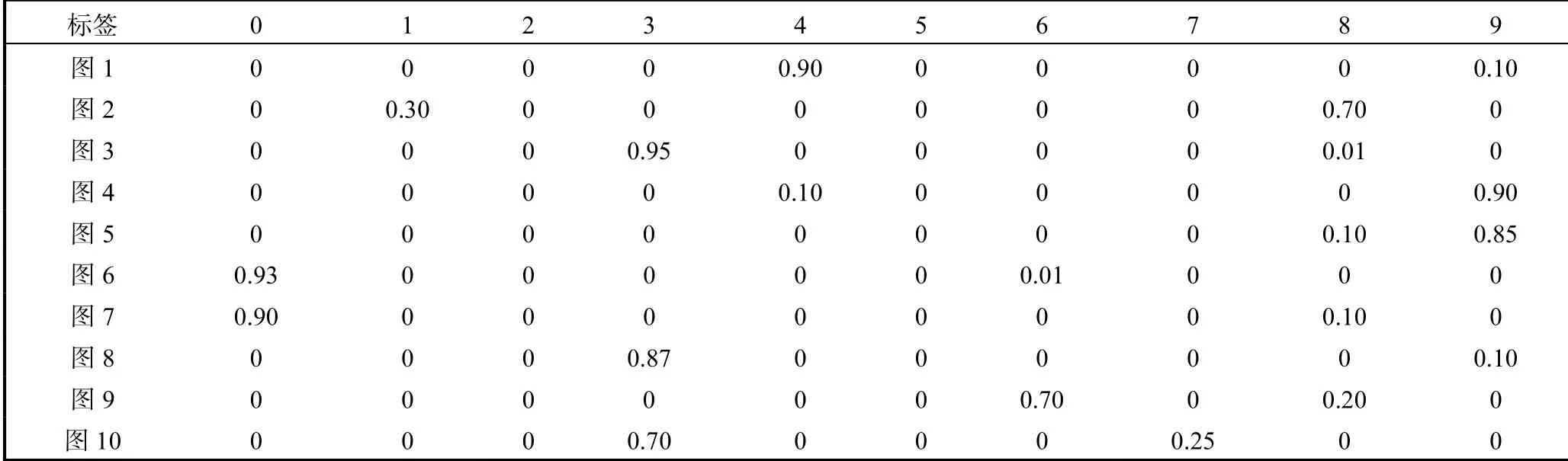
表1 MNIST数据集下SS-MGM模型生成的图片对应概率Tab. 1 Corresponding probability of images generated by SS-MGM under MNIST datasets
4.2 半监督精度对比实验
为了验证SS-MGM模型具有较高的预测精度,选择与SS-DGM模型[8]进行对比预测.选用多层全连接神经网络实现网络参数,其中变分推理模型和生成模型都采用4层神经网络,每层网络有500个隐藏点.本实验选择激活函数为tanh,两个模型分别在标签数为100、600、1000和3000以及隐变量维度分别为100、50和16的环境下进行预测标签精度对比,在MNIST数据集和FASHION_MNIST数据集的具体情况见表3和表4.
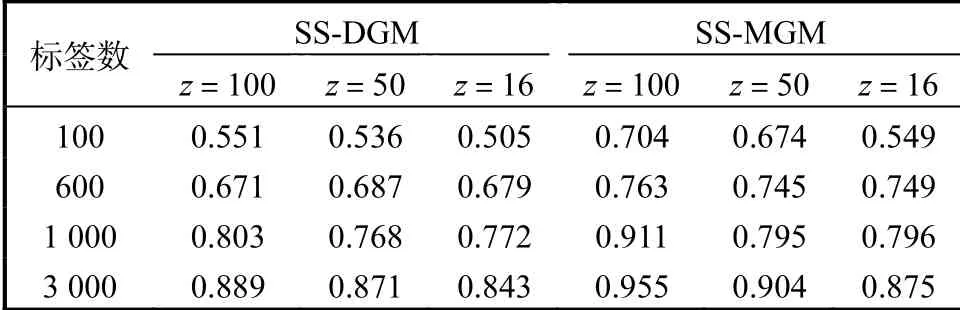
表3 MNIST数据集下两种模型预测标签精度对比Tab. 3 Comparison of prediction label accuracy of two models in MNIST datasets
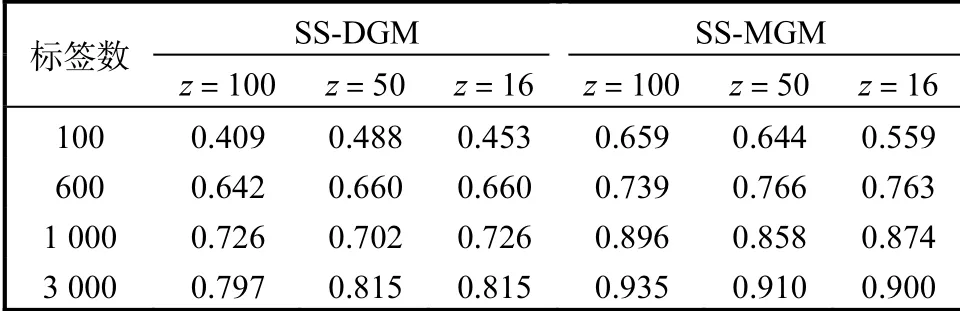
表4 FASHION_MNIST数据集下两种模型预测标签精度对比Tab. 4 Comparison of prediction label accuracy of two models in FASHION_MNIST datasets
在MNIST数据集和FANSHION_MNIST数据集上,SS-MGM模型比SS-DGM模型[8]具有更好的预测标签能力,并且可以看到预测的精度随着标签数据量的增大、隐变量维度的增加而提高.
5 结 语
本文提出一种基于多模态生成模型的半监督学习算法.模型在处理标记样本时,标记样本和标签作为推理模型的输入,输出隐变量,隐变量作为生成模型的输入,输出样本和对应标签概率.处理无标记样本时,标签看作是离散隐变量,推理模型的输入是样本,输出为隐变量和标签.隐变量作为生成模型的输入,输出样本和对应标签概率.可以看出:基于多模态概率生成模型的半监督学习模型不仅可以给出模型标签,同时可以给出该标签的概率.并且,经过实验证明该模型有效提高了预测标签的精度.另外,虽然在标记样本量较少(如100个)的情况下,SS-MGM模型预测标签的精度高于SS-DGM模型的预测精度,但是SS-MGM模型在标签量极少情况下预测的精度还是较低,不能体现出半监督学习的能力.因此,如何在极少量标记样本集中提高预测能力是后续研究的方向.
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
成长·读写月刊(2018年8期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
新高考·高二数学(2014年7期)2014-09-18
电影新作(2014年1期)2014-02-27
