
改进蜉蝣算法及其在防火墙策略配置中的应用
2022-04-25 04:58高智强张亚加邱啟蒙邵建龙
陕西理工大学学报(自然科学版) 2022年2期
高智强, 张亚加, 邱啟蒙, 邵建龙
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
全球互联网通信的增加,在给人们的学习和生活带来众多便利的同时,也使得网络安全在科学研究和工业生产中备受关注。现在网络攻击造成的不良影响越来越大,防火墙的重要性也越来越高[1]。作为控制计算机网络安全重要的一环,防火墙的正确配置至关重要。由于在防火墙中不允许冗余策略的存在,然而根据网络的规模而定,网络中用户产生的信息数据量极大,人工进行这些访问策略的配置不仅耗费大量的时间和人力,而且容易出错[2]。
目前,机器学习和深度学习得到了广泛应用,通过使用机器学习方法用于发现和揭示数据集中的关系来进行防火墙的配置无疑是解决防火墙配置策略冗余这一问题的有效方法。在这一方面,Golnabi等[3]使用数据挖掘的技术对防火墙策略规则进行分析。Breier等[4]试图基于数据挖掘技术的日志文件提出一个异常检测的方法来创建防火墙动态规则。郝欣达[5]研究基于深度学习的异常流量检测方法并设计和实现高效的WAF防火墙。但是以上方法存在实验所要求的样本数据量极大、训练时间过长的缺点。李洪林[6]选取了ID3决策树模型并实现了在防火墙中的应用。但是ID3决策树模型存在生成效率过慢且容易过拟合的问题。
支持向量机(Support Vector Machine,SVM)作为机器学习中的重要算法,具有对训练数据集数据量小的优点,可以利用较小的训练数据得到算法模型,学习效率高,实时性好,可以用于实时检测,并且可以有效解决特征维度过高的问题和非线性问题[6]。基于此,本文基于Libsvm工具包,利用主成分分析法进行特征提取,使用改进的新型群体智能优化算法蜉蝣算法(Improved Mayfly Algorithm,IMA)优化SVM来进行防火墙日志文件的训练和策略配置。
1 相关理论
1.1 蜉蝣算法
蜉蝣算法(Mayfly Algorithm,MA)是一种新型群体智能优化算法,具有寻优性能好、收敛速度快等优点,研究价值较高。其灵感源于蜉蝣的社会行为,特别是它们的交配过程。该算法首先随机产生两组蜉蝣,分别代表雄性和雌性种群,将每个蜉蝣随机放置在问题解的空间中,由d维向量x=(x1,x2,…,xd)表示,并根据目标函数f(x)进行评价,再定义蜉蝣的速度为v=(v1,v2,…,vd),每个蜉蝣的飞行方向是个体和社会飞行经验的动态交互作用。从飞行行为和蜉蝣的交配过程来看,该算法结合了飞行算法和进化算法的主要优点[7]。
1.1.1 雄性蜉蝣的运动
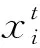
适应度值较差雄性蜉蝣的速度定义为
(1)
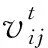
(2)
式中Xi表示pbest或者gbest,Xij表示pbest或者gbest在j维度的取值,xi表示蜉蝣个体i,xij表示蜉蝣i在j维度的取值,n是蜉蝣维度的上限。
1.1.2 雌性蜉蝣的运动

(3)
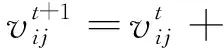
(4)
1.1.3 蜉蝣交配
交叉算子代表两个蜉蝣的交配过程:从雄性种群和雌性种群中各选择一个亲本。选择父母的方式与雄性吸引雌性的方式相同。选择可以是随机的,也可以基于它们的适应度函数。在后者中,最好的雌性与最好的雄性繁殖,次好的雌性与次好的雄性繁殖。交叉的结果产生两个后代,其产生方式为
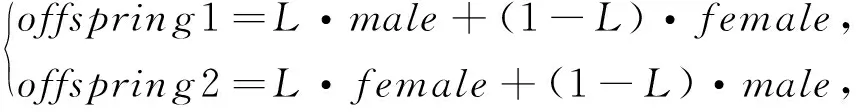
(5)
式中male是父本,female是母本,两者均为矩阵的形式;L是一个位于区间[-1,1]内的随机数,为标量;·表示矩阵运算中的数乘。
1.1.4 蜉蝣算法的流程
基本蜉蝣算法的流程如下:
步骤1 初始化雌性蜉蝣、雄性蜉蝣,设定参数;
步骤2 计算适应度值,并且排序,获取全局最优解和个体最优解;
步骤3 依次更新雄性蜉蝣、雌性蜉蝣位置,并且交配;
步骤4 计算适应度,并更新全局最优解和个体最优解;
步骤5 是否满足停止条件,如果满足则退出,输出结果,否则重复执行步骤3—步骤5。
1.2 改进蜉蝣算法(IMA)的实现
1.2.1 蜉蝣种群改进的Tent混沌映射初始化
在分析基本的蜉蝣优化算法后,发现蜉蝣算法在种群初始化阶段存在问题,基本的蜉蝣算法中初始种群采用随机过程,虽然随机过程可以保证在大多数情况下初始种群分布均匀,但个体的质量不能保证[8]。若初始化不佳,使得蜉蝣群体多样性变差,会使算法迭代增加,可能使算法陷于局部最优解,浪费计算资源。因此尝试采用混沌映射初始化种群的位置,其原理是在不改变蜉蝣群体初始化的随机本质下,利用混沌映射的分布均匀性、不可重复性、不可预测性、不确定性和遍历性特点初始化种群位置,提高种群的多样性和算法搜索的遍历性,使得算法具有较高的收敛速度和全局搜索能力。目前常用的混沌映射有Logistic混沌映射和Tent混沌映射,相比于Logistic混沌映射,Tent混沌映射产生的混沌序列分布更为均匀,由于采用了贝努利移位变换,迭代速度也更快[9]。针对Tent混沌映射序列迭代可能会落入小周期点和不稳定周期点,文献[9]在初始的Tent混沌映射中添加随机变量rand(0,1)/NT,优化后的Tent混沌映射为
(6)
式中zi表示第i次映射的函数值,初始的z1取范围[0,1]之间的随机数,rand(0,1)取区间[0,1]中的随机数,NT表示序列内的种群数量。
设所求解的维度为n,则蜉蝣群体的初始化按以下流程进行:
步骤1 随机生成n维度第一个蜉蝣个体;
步骤2 根据上个蜉蝣个体的某个维度,根据改进的Tent映射生成下个蜉蝣个体该维度的值,重复进行,直到达到种群上限;
步骤3 对所有的蜉蝣群体根据各个维度的上下限生成具体的位置,设某个维度的上限为ub,下限为lb,某个蜉蝣个体该维度的值为zi,则具体位置为
xi=lb+(ub-lb)×zi。
(7)
1.2.2 变异策略
遗传算法是一种汲取自然进化思想寻求最优解的方法[10]。通过选择、交叉、变异等遗传算子来交换种群的信息,最终得到符合优化目标的参数。而基本的蜉蝣算法结合了粒子群优化算法粒子不断更新速度和遗传算法选择、交叉的特性,并没有引入变异策略。因此,尝试引入遗传算法中的变异算子来改进基本的蜉蝣算法,使其有更多的种群多样性可以跳出局部最优。本文引入的高斯变异因子为[11]
mutation(x)=x(1+N(0,1)),
(8)
式中x为原始的参数值,N(0,1)表示期望为0、标准差为1的正态分布随机数,mutation(x)为高斯变异后的数值。
由正态分布特性可知,高斯变异的重点搜索区域为原个体附近的某个局部区域。高斯分布有较好的局部搜索能力,对于大量局部极小值的优化问题,使得算法能够高精度地找到全局极小值点,并且也提高了算法的鲁棒性[12]。
1.2.3 引入缩小系数
在基本的粒子群改进算法中,最常见的莫过于对粒子速度权重g的改变。由此得到启发,对基本蜉蝣算法中蜉蝣群体的速度权重进行迭代递减,在程序的调试过程中发现,类似的变量还有随机舞蹈系数和随机游走系数,对这些变量引入一个缩小系数,使变量的取值随迭代次数的变化而稳定递减。引入缩小系数后,前期蜉蝣群体的惯性速度、舞蹈系数和随机游走系数较大,有利于算法的全局搜索;后期蜉蝣群体的惯性速度、舞蹈系数和随机游走系数较小,有利于算法的局部搜索,且有利于引入高斯变异后的收敛。在本次实验中,所做的改进是使变量呈指数递减,缩小系数用下面的公式求取:
(9)
式中n取最大迭代次数的80%。因此在测试函数时,rf取值0.995;在防火墙应用中,rf取值0.95。
2 IMA性能测试分析
为全面评估IMA的性能,本文选取4个经典测试函数,包括单峰测试函数和多峰测试函数,其中f1、f2为单峰函数,用来评估算法的局部搜索能力;f3、f4为多峰函数,用来评估算法的全局能力和算法跳出局部极小值的能力。函数表达式见表1。

表1 测试函数
为了保证实验的合理性,引入飞行行为算法的粒子群算法(PSO)和进化算法的遗传算法(GA),将IMA与MA、PSO、GA等算法进行比较分析,种群规模设置为40,变量维度为5,最大迭代次数为500,分别独立运行30次,以实验得到的曲线绘制各算法的平均收敛曲线,如图1所示。
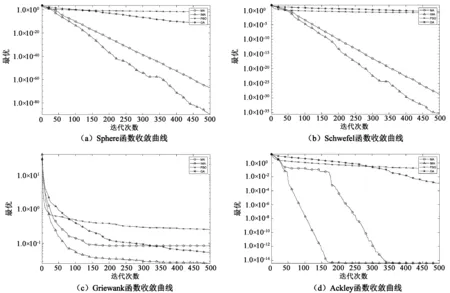
图1 测试函数收敛曲线
由图1(a)、(b)、(d)可知,相比于PSO和GA,MA算法的收敛曲线具有较高斜率,但在图(c)中可以明显看出MA全局搜索性能较差且陷入局部最优。而IMA在各个测试函数上表现最佳,达到收敛的迭代次数最少且求得的解比PSO、GA和MA更接近于最优解,说明IMA的收敛速度和跳出局部最优解的能力明显优于PSO、GA和MA。4个基准测试函数结果表明,IMA使算法以较大的斜率收敛到全局最优解附近,克服了算法早熟的问题,并使算法具有较快的收敛速度。同时引入的高斯变异有效地帮助算法跳出了局部最优解,IMA算法中蜉蝣群体的速度权重g和随机游走系数fl、随机舞蹈系数d等以指数形式随迭代次数递减有效地克服了高斯变异带来的不稳定性,使算法的全局搜索和局部搜索能力达到有效平衡,实现了算法的稳定性。但是,由于IMA单步迭代中引入了多余操作,使得复杂度和计算量略有所增加,单步迭代运行时间小许增加,这是目前IMA算法存在的最大问题。
3 PCA-IMA-SVM的防火墙策略配置模型
SVM是人工智能机器学习领域的一个邮件的学习方法,通常用来进行模式识别、分类预计回归分析[13]。其核心目标在于寻找一个最优分类超平面,处于超平面两边的数据各为一类,从而完成样本分类[14]。影响SVM性能的主要参数为核函数参数g和惩罚参数c[15]。在本实验中,IMA通过适应度函数对SVM这两个参数进行动态调整,并将优化后的SVM用于建立防火墙配置策略模型。由于防火墙日志文件具有较多的维度,为了提高SVM的分类效率,首先通过主成分分析方法对数据进行预处理,减少数据集的维度,之后对处理后的数据进行SVM分类和测试,建立分类模型。建立PCA-IMA-SVM防火墙配置策略的流程如图2所示。
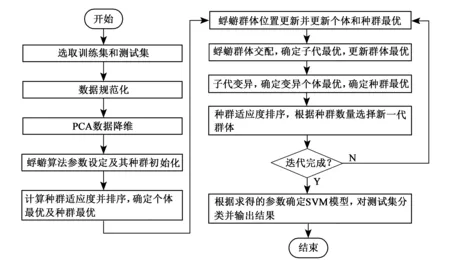
图2 PCA-IMA-SVM防火墙数据处理流程
对图2流程图的详细说明如下:
(1)选取训练集和测试集。首先从原始数据中选取一部分样本数据,并按照一定比例划分训练集和测试集。
(2)数据的规范化。在进行主成分分析之前,首先对数据集进行规范化,以m表示样本的维数,n表示数据样本的数量,对样本矩阵作变换[16]:
(10)
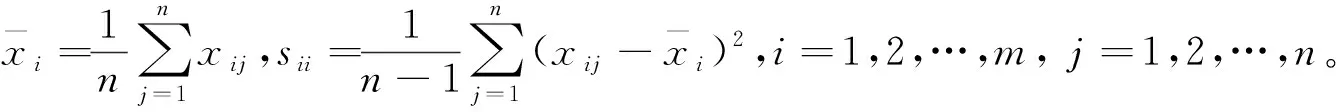
(3)PCA数据降维。由于原始防火墙配置数据的各个维度不一定完全相互独立,因此在进行参数寻优和模型训练之前需要对原始数据进行降维,以便于在提取主成分消除样本数据之间相关性的同时,减少模型的训练时间,提高模型的分类准确率。其基本原理为尽可能代表原始数据信息的条件下,将高维特征空间的数据通过线性变换映射到低维样本空间[17]。本文对原始数据进行主成分分析,将原始的11维数据转化为4维数据,主成分分析对原始数据的解释度为90.5%。
(4)蜉蝣算法参数设定及其种群初始化。对蜉蝣算法中的随机游走系数、变异概率、迭代次数等参数进行设定,对蜉蝣群体进行改进的Tent混沌映射初始化。
(5)计算种群适应度并排序,确定个体最优及种群最优。训练过程中的种群适应度值以十折交叉验证下的SVM模型准确率取值。
(6)蜉蝣群体位置更新并更新个体和种群最优。根据个体最优和种群最优来确定雄性蜉蝣的速度取值,并根据雄性的适应度来确定雌性的速度取值。以速度取值进行蜉蝣群体的位置更新,重新确定个体最优和种群最优。
(7)蜉蝣群体交配,确定子代最优,更新群体最优。雌雄个体交配,子代为雌雄个体线性组合,更新子代最优和群体最优。
(8)子代变异,确定变异个体最优,更新种群最优。对子代以一定概率进行高斯变异,确定变异个体的个体最优,更新种群最优。
(9)群体适应度排序,根据种群数量选择新一代群体。若设定的蜉蝣群体种群数量为n,则根据个体适应度的优劣程度进行排序,选取适应度值最优的n个个体为新一代种群,剔除适应度差的个体。选择后的种群重新按照适应度取值分为雌雄个体。
(10)根据求得的参数确定SVM模型,对测试集分类并输出结果。根据训练集结合IMA算法求得c和g确定SVM并对测试集进行数据处理并输出。以IMA算法求得的c和g带入SVM模型中,对测试集样本数据预测,并与其标签值进行对比,求得准确率、误报率和漏报率等指标。
4 实验
4.1 实验环境与数据集
本文的实验操作平台为Window 10,应用软件为MATLAB 2019b,基于AMD 3600处理器。实验所用数据来自于UCI,该数据是土耳其Firat大学防火墙设备一部分日志文件,数据集选取源端口、目标端口、NAT源端口、NAT目标端口、运行时间、字节数、发送字节数、接受字节数、包数、发送包数和接受包数11个影响因素作为防火墙日志文件分类指标,以防火墙的配置为分类结果,一共有允许(allow)、否定(deny)、放弃(drop)和重置(reset-both)4类。数据集共有65 532个样本,本文选取前3类部分数据进行操作,其中选取3类样本各100个,选取各类样本数据的75%为训练集,剩余25%为测试集。
4.2 结果分析
为评估IMA-SVM在防火墙配置上的应用性能,本文将该算法与基于MA算法、粒子群算法(PSO)和遗传算法(GA)构造的防火墙配置模型进行比较分析。实验中SVM模型中c和g的取值范围分别为区间[0.01,100]和区间[0.001,1000],PSO、MA和IMA的个体维度速度取各维度上限的10%,速度下限取上限的相反数。实验过程中各算法基本参数的详细设置见表2。

表2 各算法的详细参数设置
本文对各类算法进行50次迭代,每种模型独立运行30次,取结果的平均值。本文使用分类准确率(AC)、误报率(FA)和漏报率(MA)指标评估算法性能:
(11)
(12)
(13)
其中TP表示正确分类的正例,TN表示正确分类的反例,FP表示错误分类的正例,FN表示错误分类的反例。在实验中,以各类分别为正例求取各个指标参数并去平均,得到IMA算法与其他算法实验结果,见表3。

表3 IMA算法与其他算法实验结果比较
由表3可知,IMA寻优的参数能更好地优化SVM模型,防火墙策略正确配置的准确率高达97.33%,误报率最低,仅2.67%,在保证高准确率的同时也保证了低的漏报率,且算法运行时间较其他算法较快。遗传算法在准确率和漏报率方面表现最差,而且算法运行的时间开销比较大。原始的MA算法具有较好的性能,运行时间最短,但准确率略微欠佳。
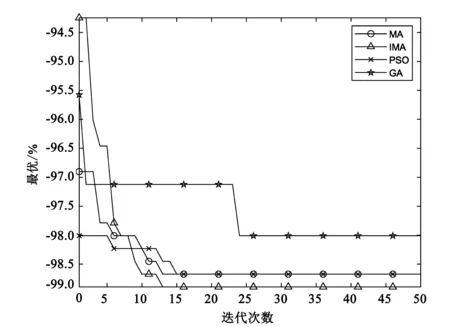
图3 各算法的最佳适应度曲线图
从迭代过程各算法训练过程中的最佳适应度的收敛曲线(图3)来看,IMA多次迭代时跳出局部最优区域,第13次迭代时收敛精度近99%,而原始的MA算法却陷入局部最优解中,在迭代前期,IMA算法曲线的斜率较高,表明算法具有更好的搜索能力和收敛速度,在训练集的训练过程中求得的SVM的模型参数最佳。而遗传算法在第24次迭代后陷入了局部最优,后期的多次迭代依旧无法跳出,表明遗传算法模型不适用于防火墙配置策略数据。而粒子群算法达到收敛的迭代次数较MA和IMA较多。综上,改进策略有效地提高了蜉蝣算法的寻优性能。
5 结束语
本文基于IMA优化SVM的惩罚参数和内核参数,将优化后的SVM用于防火墙配置策略。IMA引入了改进的Tent混沌映射初始化蜉蝣群体,引入了遗传算法中的概率高斯变异策略,并依据迭代次数动态调整蜉蝣群体的速度权重、随机游走系数和舞蹈系数。实验结果表明,改进的蜉蝣算法提高了SVM模型的参数优化结果,在保证较高的准确的同时,运行时间也得到了减少,保证了防火墙配置策略模型的快速生成。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
当代陕西(2019年15期)2019-09-02
郑州大学学报(工学版)(2018年2期)2018-04-13
小雪花·小学生快乐作文(2017年7期)2017-09-07
中国塑料(2016年11期)2016-04-16
IT时代周刊(2015年7期)2015-11-11
大作文(2015年8期)2015-10-19
自动化博览(2014年6期)2014-02-28
中国火炬(2010年10期)2010-07-25
舰船电子工程(2010年1期)2010-04-26
