
知识图谱问答领域综述①
2022-05-10 08:39郑泳智朱定局吴惠粦彭小荣
计算机系统应用 2022年4期
郑泳智,朱定局,吴惠粦,彭小荣
1(华南师范大学 计算机学院,广州 510631)
2(广州国家现代农业产业科技创新中心,广州 510520)
3(广州市增城区文化馆,佛山511300)
1 知识图谱
1.1 知识图谱的发展及定义
知识图谱(knowledge graph,KG)源自于1960年提出的语义网络,有着源自于NLP、Web、AI 等方面的基因,它通过结合数学与信息科学等学科理论与方法,以可视化形式描述其资源与载体,应用于问答、推荐等领域,其概念演化如图1所示.

图1 知识图谱概念演化
语义网络是用图表示知识的方式,图2 是一个语义网络示例,信息被表达为一组节点,节点间以有向直线相连表示关系,其优点在于表达直接且清晰明确,可用于检索与推理,但不适用于定量动态的知识.

图2 语义网络示例
本体(ontology)一词起源于希腊语,是一个哲学术语,在哲学的角度,它关注的是“存在”,而本体论则是对世界任意领域内的存在作客观描述.例如,世界是什么?太阳是什么?星星是什么?1980年,McCarthy[1]提出以逻辑概念为基础的智能系统需列出所有存在的事物并构建一个本体描述我们的世界.至此,人工智能领域开始引入哲学本体论思想内涵用于刻画知识.1989年,Berners-Lee 发明了万维网(World Wide Web,WWW),它作为视频、图片等媒体信息的最深远、最广泛媒介,标志着信息共享进入了新时代.1998年,依托万维网的语义网(semantic web)诞生,这一概念旨在将万维网上的文档添加为可被理解的语义元数据,即文档组织形式转变为以URI 标识的更小的数据碎片,同时建立本体库表征数据,使互联网成为通用信息交换媒介.2006年,Berners-Lee 提出链接数据(linked data),鼓励各信息源从文档组织形式向这种最小数据碎片形式迁移并发布这些数据作为开放数据,且尽量参考已知本体进行建模并赋予其唯一URI 用以标识,较有名的项目有DBpedia、Freebase 等.2012年,谷歌为了优化其搜索引擎提出知识图谱的概念,知识图谱由一些相互连接的实体以及它们的属性构成[2],其基础是语义网和本体论,其本质是表示实体联系的语义网络.其中,每个实体或概念用一个全局唯一ID 标识,每个属性值用于刻画实体内在特性,而关系(relation)用来连接两个实体,刻画它们之间的关联.通俗而言,知识图谱是一张巨大的图,图中的节点表示实体或概念,而图中的边则由属性或关系构成,这种图模型可用W3C 提出的资源描述框架(resource description framework,RDF)[3]表示.
知识图谱按问题领域划分,可分为通用领域和垂直领域,垂直领域知识图谱是基于特定行业数据构建的,规模虽小,但知识质量高,精度高.而通用领域知识图谱覆盖面更广,规模更大,自动化程度更高.本文归纳整理了近些年通用领域知识图谱的项目,如表1所示.

表1 开放领域知识图谱项目
1.2 知识图谱的构建
通用知识图谱为了融合规模更庞大的实体,通常采用自底向上方式构建,而垂直领域知识图谱的构建对领域知识的深度和精度有很高的要求,需要有完善的本体模式层.如图3所示,知识图谱的构建,首先需要不断的采集数据、包括结构化、半结构化、非结构化数据,知识是日新月异的,通用领域的知识图谱需要不断的扩充其实体库就需要不断的采集数据.采集得到的数据通常需要进行数据清洗、缺失值处理、异常值处理等,然后使用自然语言处理的手段提取数据中的实体、关系、属性.目前主流的实体识别方法通常使用结合BERT 和BiLSTM+CRF 的变式模型提取实体,使用基于卷积神经网络模型(CNN)来抽取关系.得到的实体词通常需要进行对齐操作,包括实体消歧和共指消歧.例如“我的手机是苹果”和“我喜欢吃苹果”中都有“苹果”一词,但所指意思不一致,这就需要进行实体消歧处理,消歧方法包括基于规则的方法、机器学习的方法、全局最优方法、基于知识库的方法、深度学习算法.抽取得到的可靠三元组数据将导入存储知识的数据库,目前主流的图数据库有Neo4j[12]、Jena[13]等.

图3 知识图谱的构建过程
2 智能问答
2.1 智能问答的发展
智能问答是自然语言处理中的重要分支,通常以一问一答的人机交互形式定位用户所需知识并提供个性化信息服务.它能让计算机自动并以精准自然语言形式回答用户所提出的问题且不同于搜索引擎.
如表2所示,智能问答的历史可以追溯至1950年,计算机科学之父阿兰·图灵为了检验计算机是否具备精准应答问题的能力,提出机器能否思考的判断方案——图灵测试,自此翻开了自然语言人机交互的篇章.20世纪60年代前后,首批问答系统问世,Green 等人[14]设计的Baseball 程序可用普通英语回答有关棒球比赛的问题,1971年月球科学大会上,LUNAR 系统[15]首次亮相,它可以回答月岩样本分析的相关问题,但这一时期的QA 系统只停留在处理领域结构化数据层面上.20世纪70年代前后,语言学的兴起、马尔科夫假设等理论的提出、数据库构建成本降低,使得问答系统构建难度也因此而降低.该时期的问答系统集成自然语言处理、知识表示等方法分析用户问题,耶鲁大学开发的SAM 系统[16]便是这一时期的产物,它引入计划的概念并使用脚本来理解问题,但是其缺点在于脚本未就绪则系统将无法工作.20世纪90年代,计算机运算能力提升,基于机器学习的自然语言处理诞生,智能问答进入了开放领域、自由文本时期.智能问答研究热点转向基于大规模文档集的问答、研究领域从限定领域延展至开放领域,研究对象从固定语料库延伸至互联网.2002年,密歇根大学开发了一个支持多语言的WQA 系统[17],用户可以使用多语言提问.同时期有影响力的问答系统还有Webclopedia[18]、LAMP[19]等.2009年,Wolfram Research 公司推出的Wolfram Alpha在线自动问答系统能给出答案与答案相关的所有信息,这一时期的系统越渐成熟,涵盖多领域多语言的知识数据,配有相应的可视化界面.当2011年IBM 公司研发的“沃森”在美国知识竞赛节目《危险边缘》中战胜两位顶尖人类选手后,基于深度学习的智能问答再次成为研究热点.

表2 智能问答项目
2.2 基于知识图谱的问答系统
近年来,随着知识图谱概念渗透到各领域,基于知识图谱的智能问答逐渐成为焦点之一,在金融、医疗、旅游、农业、电商等垂直领域,都不乏相关研究,例如李贺等人[20]构建的基于疾病知识图谱的问题系统,杜泽宇等人[21]的电商知识图谱的问答系统,由于医疗和电商等领域对该类系统的需求较大,因此完善程度也较好.这些基于知识图谱的问答系统,或利用当中的知识数据结合深度学习构建问答系统;或利用图谱的推理能力理解问题;或融合问题与三元组的信息编码至向量空间,在向量空间内完成问题相关的相似度计算任务,得出用户所需近似答案.归结基于知识图谱问答系统的构建方法有3 种,即语义解析(semantic parsing,SP)、信息检索(information retrieval,IR)、向量建模(vector modeling,VM).学术界有一种说法称主流方法只分为语义解析和信息检索,只是近年来将深度学习应用于两种传统的方法,更将VM 归结一种类似IR 的方法.在该领域,一些研究者旨在深入研究KBQA 的子任务,例如问题实体检测、关系抽取、多跳推理等,一些研究者则研究整体的通用框架,如Pei 等人[22]设计基于TransE 的中文领域知识图问答通用框架,涉及多模型融合.本文以这些任务中使用到的关键技术为侧重点对该领域技术现状以及展开阐述.
2.3 问答数据集
研究KBQA 离不开数据集,而不同数据集通常针对不同QA 任务,包括简单问题和复杂问题.一些研究者为达成研究目的还需要扩充公共数据集或独自构建数据集,如Miller 等人[23]为了验证其网络功能而提出MovieQA 数据集.但大多数研究者会选择使用公共基准数据集,既省去构建时间而专注于算法模型的设计,又便于对比同类模型.而人工标注数据集往往需要高成本人力物力,因此数据集的构建者会使用模版构建问答数据集,但仅使用模版生成问题的数据集缺乏多样性,而缺乏多样性的数据集作为训练数据时通常会降低模型对复杂问题的泛化能力,因此近年来数据集的构建者会以构建高质量数据集为目标.本文归纳整理了近些年来具有代表性数据集,如表3所示.从体量上看,数据集的规模已从千级别扩展至百万级别,其中含有复杂问题的数据集体量往往较小.从基于的知识库看,早期数据集一般基于Freebase 构建,2016年Freebase 被收购后,KGQA 数据集大多基于Wikidata和DBpedia.近3年,数据集的问题焦点放在了多样性、SPARQL 以及推理过程上.考虑到以往的数据集很少有推理过程,2021年,Shi 等人[24]基于Wikidata数据加入推理过程构建KQA Pro,它包含了多样的简单问题与复杂问题,且保证了其规模与质量,无疑是近年来高质量的数据集之一.
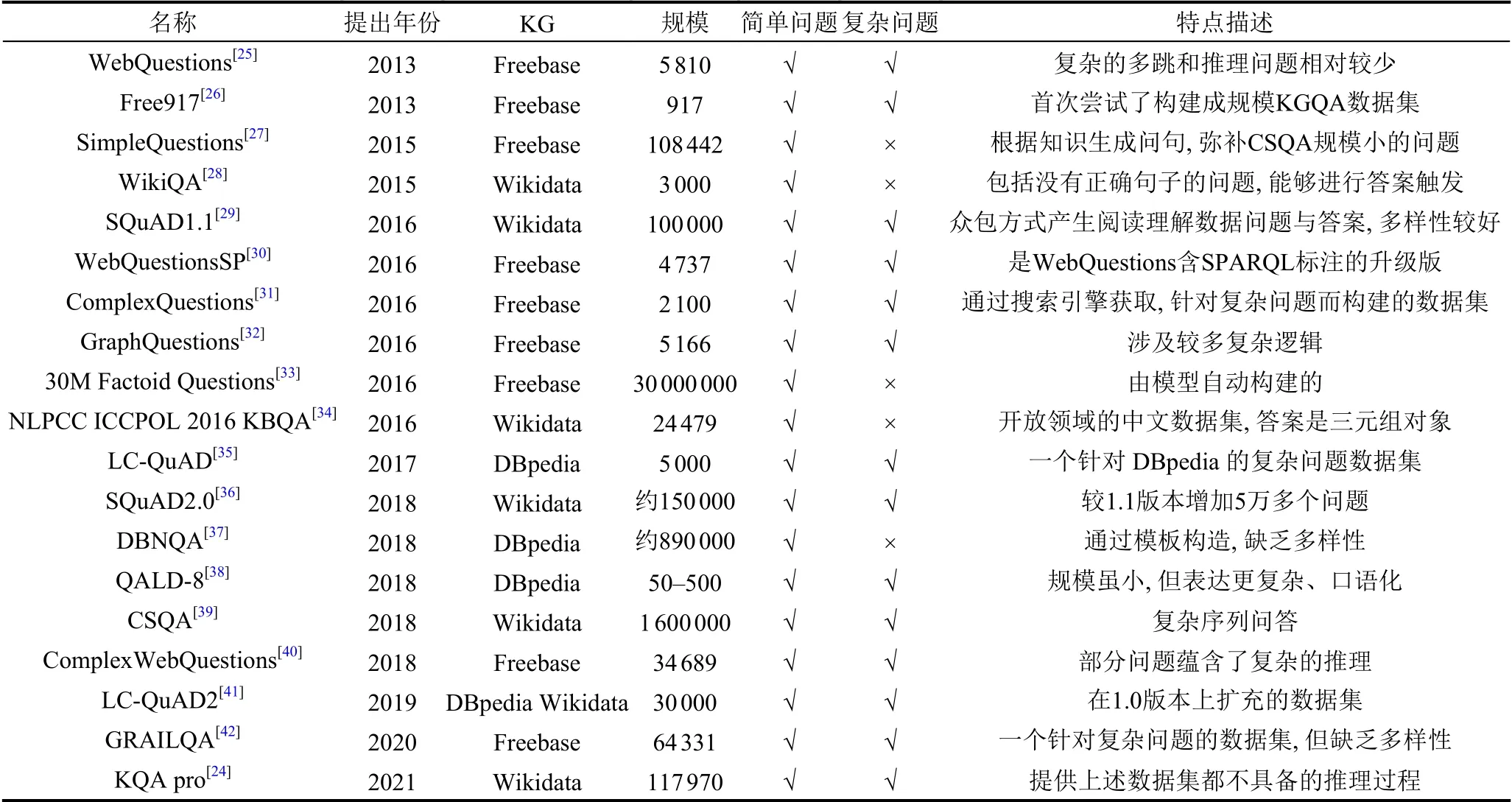
表3 基于知识图谱的问答数据集
3 构建方法
本节对目前主流的基于模板的语义解析方法、基于语义查询图的方法、基于编码解码的方法、基于检索的方法进行介绍,并对其进行归纳总结如表4所示.基于模板的语义解析方法其核心在于模板于规则的制定、语义查询图的核心在于如何用语义图来表示自然语言的句子结构、编解码的方法的核心在于构建编码模型捕获句子特征、基于检索的方法其核心在于句法的信息如何映射为特征图或句子特征转为空间向量.

表4 构建方法对比分析
3.1 基于模板的语义解析方法
语义解析方法是一种语言学方法,其思想是将非结构化的自然语言问题映射为一系列结构化逻辑形式,例如语义图和高级查询语言(如SPARQL,Cypher 等).而基于模版的语义解析方法其思想在于将问题先转换为人为预定义的规则或模版,再转换为可执行的查询.如图4所示,输入的问题首先被映射为逻辑形式,该过程通过预定义模版规则进行映射,得到实体与关系<E1,Relation,E2>,再进一步转化为图数据库的可执行查询得到知识图谱中的相应的答案.本文归纳整理了近年来在这方面的研究如表5所示.

表5 基于模板的语义解析方法的研究

图4 基于模板的语义解析流程
依赖于人工标注的逻辑形式对于大规模KBQA 任务而言成本很高,Berant 等人[27]实现了一个标准的自底向上解析器.首先利用知识库和大型文本语料库建立从问题短语到知识库实体或关系的粗映射;然后使用桥接操作基于相邻谓词生成其他谓词,将问题短语映射到知识库实体和关系.该解析器依赖于一个对数线性模型来覆盖手工构建的特性,减少了搜索的空间,并在Cai等人[43]的数据集上得到了验证.Bast 等人[44]提出了一个基于模板的模型Aqqu,该模型将问题映射到3 个模板,先从知识库中识别出与该问题的一部分匹配的所有实体,匹配可以是文字匹配,也可以是实体名称的别名.然后,Aqqu 实例化3 个模板,其中知识图谱子图以匹配的实体为中心,根据基于手工特征的排序模型,输出最佳实例以查询知识库并获得答案.然而,Aqqu 中的3 个模板对复杂问题的覆盖范围有限.为处理更多问题,研究人员尝试从数据集中自动或半自动地学习模板.Abujabal 等人[45]提出了一种名为QUINT 的自动模板生成模型,自动模版分为查询模板和问题模板.其中查询模版负责从知识库中提取规则,问题模版则依靠解析给定问题中的依赖关系产生.在运行过程中,首先将问题查询映射到一些问题模版,然后将相应的查询模版实例化为候选结果,最后在排序后输出得分最高的查询即为最终答案.为保证自动创建的问题模版的质量并得以商用,Spiegel 等人[46]提出一个模块化的MK-SQuIT 框架,通过生成和优化问题模板和查询模板自动合成数据集.Abujabal 等人[47]提出的NEQA 类似于TeBaQA[48],同样是基于模板的KBQA 系统,均使用连续学习范式回答未知领域问题.但除了使用基于相似度的模板匹配方法之外,它还依赖于用户反馈并随着时间推移而改进.另外,TeBaQA 还可以仅使用基准数据集就能轻松地应用到新的领域,在可扩展性上与之前的方案相比更有优势.
基于模板的语义解析方法其核心在于模板的构建,其优点在于过程清晰,可解释性强,但此类方法需要结合语言学的知识,无论是自动或半自动的构建方案都需要一定的工作量.
3.2 基于语义查询图的方法
依赖于预定义模版的方法可扩展性有限,而且需要较专业的语言学知识,无疑带来大量的工作量,因此出现了基于神经语义分析的方法(neural semantic parsing,NSP).它以增强解析能力和可扩展性为目的,将非结构化问题映射为语义图这种中间逻辑形式,然后再将其转换为SPARQL 查询.
图5 展示了问题“小明去过广州最高的建筑物是什么?”的一个简单的查询图结构,此类查询图通常由4 种类型的节点组成、用圆角矩形表示的主题实体、用圆表示的已存在变量、用阴影圆表示变量,用菱形表示聚合函数.其中主题实体是知识图谱中的现有实体,阴影圆节点x也称为答案节点,用于映射请求检索得到的实体,菱形节点限制了答案必须是最高的建筑物.得到如下逻辑形式:

图5 语义查询图示例

执行该查询(不包含聚合函数)将会匹配到“国际金融中心”“广州塔”等实体,再结合聚合函数可得到最终答案为“广州塔”.
本文归纳整理了近年来此类研究的内容及特点[49-60],如表6所示.
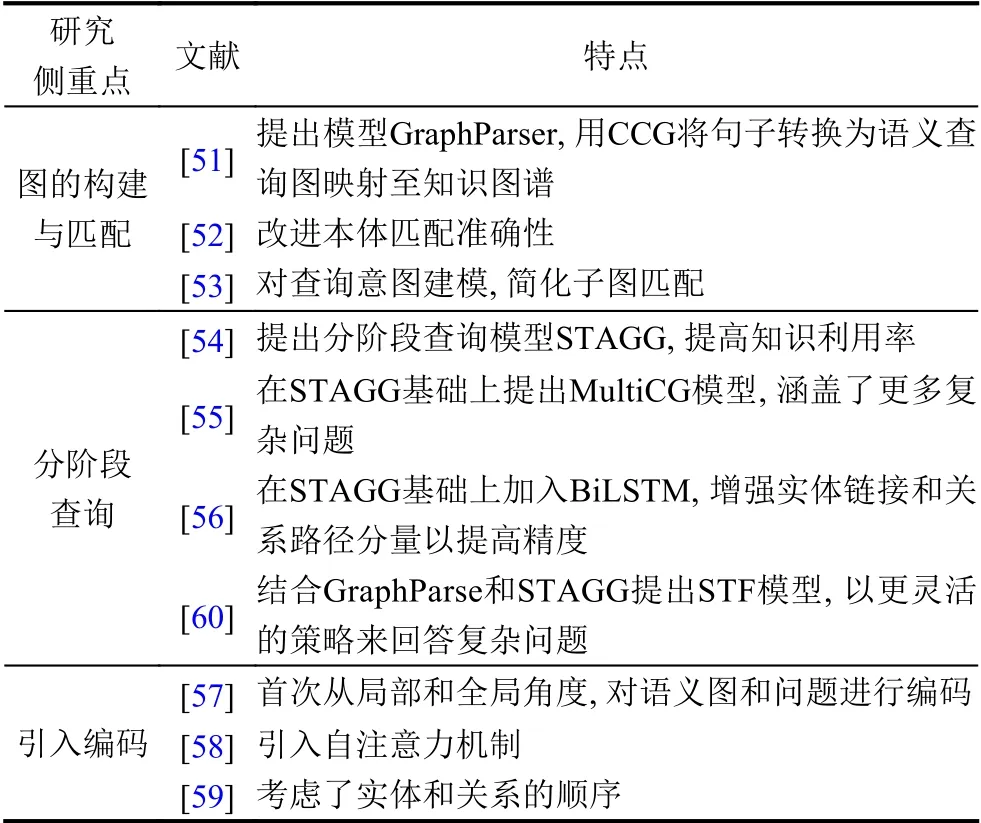
表6 基于语义查询图方法的研究
Reddy 等人[49]提出了一种基于图的语义解析器GraphParser,使用组合范畴语法(combinatory categorial grammar,CCG)将句子转换为语义查询图,通过语义查询图表示自然语言时可将图的边映射为知识图谱的关系,图的节点映射到知识图谱实体或类型等,并采用集束搜索方法得出最佳语义查询图.
2013年Kwiatkowski 等人[50]曾经指出当逻辑形式使用与知识图谱中定义的谓词不相同时,可能会存在本体匹配问题.因此他构建的解析器是从问题-答案对中学习的,使用CCG 构建语言动机的逻辑形式,改进本体匹配的准确性.后来,Zou 等人[51]提出以结构化的方式对自然语言问题的查询意图进行建模,在此基础上,将QA 任务简化为子图匹配问题,他们考虑到在线QA 系统的查询对系统成本较高,考虑改进消歧方法,便采用一种惰性方法,将歧义消除推到了查询评估阶段以提升整体性能.
为使得知识图谱的知识利用率更高,而且受到文献[49]的启发,Yih 等人[52]在Kwiatkowski 研究的基础上提出了一个名为分阶段查询图生成框架(staged query graph generation,STAGG).框架将其分解为3 个阶段的搜索问题,第1 阶段,利用实体链接工具获取候选实体及其得分;第2 阶段,STAGG 找到主题实体和答案节点之间的所有关系路径,但为了限制搜索空间,仅当中间存在变量可被固定到复合值类型节点(compound value type,CVT)时才探索长度2 的路径,否则探索长度1 的路径;第3 阶段,根据启发式规则将约束节点附加到关系路径上.每一个阶段均利用对数线性模型对当前部分查询图进行评分,并输出最佳的最终查询图来查询知识库.STAGG 在WebQuestion 基准数据集上进行实验并验证了其语义空间裁剪的有效性,不仅简化了任务难度,更提高了查询效率.但是为了限制搜索空间,STAGG 只探索有限长度关系路径,因此难以处理多跳等复杂问题.考虑到文献[52]提出的STAGG 暂不能覆盖某些复杂的约束,Bao 等人[31]在2016年提出在STAGG的基础上扩展了约束类型和算子,包括类型约束和显式与隐式时间约束,并提出了多约束的语义查询图(multiple constraint query graph,MultiCG)来解决这些复杂问题.但MultiCG 仍然在整体上继承了STAGG 框架,只是提供了更多的规则来涵盖复杂问题.为了得到更高的精度,Yu 等人[53]在STAGG 框架基础上,提出使用深度残差双向LSTM 模型(hierarchical residual-BiLSTM)来编码问题和关系路径,并计算所有问题的相似性得分,使得实体链接和关系路径两个分量相互增强以提高精度.其中关系路径是指在单词级别和短语级别与候选主题实体关联的所有关系路径,最后只保留候选主题实体中得分较高的.
只将关注点放在实体链接或约束而忽视组合语义通常不利于解决复杂问题.Luo 等人[54]认为语义图中的各语义成分只传递部分信息,即现有方法无法捕获组合语义,这是由于对不同的组件进行单独编码造成的.因此,文献[54]首次从局部和全局的角度对语义图和问题进行编码,生成全局统一的表示向量.文献[54]指出统一的矢量表示形式可以顺利地捕获了复杂问题中各语义成分信息,他们的实验在ComplexQuestion 等数据集上便验证了这一点.后来,有不少研究者在此基础上做出了改进,其中Maheshwariet 等人[55]除了对该类模型的排序方法进行了实证研究以外,还提出了一种基于自注意力机制的模型;Zhu 等人[56]提出了一种树到序列算法,考虑了实体和关系的顺序,并使用基于树的LSTM 对语义图进行编码;为了适应更多类型的复杂问题,例如具有更多隐含关系的问题,Hu 等人[57]提出了一个结合了GraphParse 和STAGG的状态转换框架(STF),以更灵活的策略来回答复杂问题,虽优于STAGG,但仍缺乏处理复杂聚合问题的能力.
基于语义查询图的方法其核心在于如何将自然语言问句用语义图来表示并映射至知识图谱的查询,优点在于能充分利用知识,但这些方法都依赖特定构建手段,在通用性上还有待提高.
3.3 基于编码解码的方法
除了使用基于语义图的方法,还有一种常用的语义解析方法,即基于编解码的方法.如图6所示,自然语言问题输入编码器和解码器后,得到适用于数据库处理的逻辑表示作为输出.
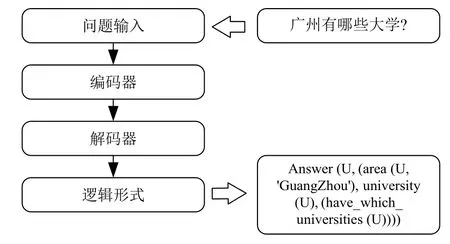
图6 基于编解码模型的方法
近年来,基于递归神经网络的编解码模型已成功应用于各种NLP 任务,如语法解析[58],因此研究者开始尝试将编解码模型也运用于KBQA 中的语义解析方法.本文整理近年来的相关研究对比如表7所示.

表7 基于编解码的方法研究
Dong 等人[59]在2016年提出的一种基于注意力机制的增强型编解码模型,学习自然语言和逻辑形式之间的对齐方式,将问题转换为逻辑形式.但其中存在一些问题,例如解码过程中可能会忽略较长的疑问词,而这是编解码模型的常见问题,可以通过Tu 等人[60]提出的显式建模解决.Xu 等人[61]指出了使用普通的序列编码器提取词序通常会忽略一些有价值的句法信息.因此,他们采用图序模型来编码句法图,而句法图表示了词序、依存关系等特征,用于捕获一些通常被忽略的句法信息.但是这种方法需要大量训练材料,不适用于多数KBQA 场景.
为了增强问题的语义,一些研究人员会把关注点放在义素上.义素是词义的最小意义单位,他们希望以更细的粒度来捕获信息以增强语义.例如,Wu 等人[62]提出一种基于义素的语义解析方法,对问题中的义素级别的信息进行编码以减少噪声,并引入了一种层次表示法对关系进行编码,尽可能的消除词语歧义.为了更高效的消除歧义并丰富问题的信息,Wu 等人[63]利用外部知识,将义素级别的信息和注释都集成到词语中,增强了模型对问题的理解.
近年来,神经机器翻译模型NMT 也被考虑应用到KBQA 的任务中,Ji 等人[64]提出结合语义相似度模型和神经机器翻译模型,将复杂问题转化为子查询,将并行执行子查询的结果组装成完整SPARQL 查询.类似的,Wang 等人[65]构建了4 种基于神经机器翻译的模型将问题转换为SPARQL 查询.
KBQA 任务往往分为多个子任务,但是为每个任务的样本做标注不仅是高成本的做法,而且存在上游任务到下游任务的传播误差问题,因此端到端的模型成为了研究的热点之一.与Lukovnikov 等人[66]和Huang等人[67]提出仅解决单跳推理的模型不同的是,Srivastava等人[68]提出一种基于BERT 模型的多任务神经网络机器翻译模型(CQA-NMT),可以应对实体链接、 多跳推理等多个子任务的挑战.他们以扩展的BERT 模型作为编码器,以Transformer 作为解码器,更好的解决了多跳问题.而且在MetaQA 数据集上进行的实验均优于PullNet[69]、EmbedKGQA[70].
当研究者将关注点放在为问题选择正确语义关系的时候往往会忽略语义解析的结构,即实体之间的连接和关系的方向.这些信息通常是解决复杂问题的关键,Sorokin 等人[71]提出GGNN 架构,使用门控图神经网络对语义解析的结构进行编码,利用Bi-GRUs 提取问题中的语义特征,匹配得出相关语义部分,再利用CNN 模型学习问题与关系之间的相似度,这种使用门控图神经网络的新颖方法有效提升了回答复杂问题的效果.
3.4 基于检索的方法
基于检索的方法旨在将自然语言问题和知识库中的实体和关系映射为同一低维空间中的特征向量,将任务转化为问题向量与知识图谱中对应关系向量之间的相似度匹配任务.根据其特征表示技术的不同,又分为基于特征工程的方法和基于表示学习的方法.本文整理近年来的相关研究对比如表8所示.

表8 基于检索的方法研究
基于特征工程的方法特点是从依存句法分析结果提取问题词等特征并转化为问句特征图后,组合主题实体子图的候选特征图,将权重偏向于关联度较高的特征.例如Yao 等人[72]提出的模型则是基于此类方法.但该方法除了对复杂问题的支持度较差以外,还需要自行定义并抽取特征,而且容易造成维度太高,计算效率低等问题.而基于表示学习方法为了解决该类问题,将问句和候选答案转换为同一语义空间的向量,将该问题转换为问句与答案的向量匹配计算问题.
Bordes 等人[73]首次提出将问句和图谱中候选实体映射至同一向量空间,但该模型忽略了词序对句子的影响,Dong 等人[74]提出的MCCNNs 模型则考虑到词序、答案类型等特征,但也存在问句向量转换为定长向量的问题,容易忽略了隐含的问句信息.因此Hao等人[75]和Qu 等人[76]利用带有注意力机制的模型来捕获隐含信息,尽管效果有所提升,但在处理复杂问题上仍有进步的空间.Bordes 等人[25]采用记忆网络(memory network)模型将问题和图谱的知识等信息存于记忆网络中,在记忆槽中选取一些相关度高的信息通过响应模块来得到答案,实验证明该方案比大多数的检索方法好.
而基于检索的方法离不开实体识别与检索.近年来,越来越多的实体检索模型比传统方法有显著改进.Naseri 等人[77]提出利用相关实体信息丰富实体的表示.Kadilierakis 等人[78]在ElasticSearch 的基础上支持了对RDF 数据集的关键字搜索.Gerritse 等人[79]利用Wikipedia2Vec[80]展开实体排名的研究.Nikolaev 等人[81]实现了名为Kewer 的系统,可以通过使用联合词和实体嵌入来对实体进行排序,并且不需要大量的文本语料库.后来,Esmeir 等人[82]基于Kewer 系统提出了SERAG,其任务是从阿拉伯知识图谱中检索语义实体.由于具有多跳推理功能,SERAG 明显优于经典的BM25 模型[83].
4 发展趋势与挑战
当前KBQA 的发展向着结合深度学习模型的方法靠拢,以解决多跳推理问题、提高模型的解释性为主要目标.
4.1 多跳推理
KBQA 中的多跳推理问题一直都是亟待解决的问题,解决方法往往是结合多元的信息来增强模型的理解力,例如Shi 等人[84]提出了TransferNet,在统一的框架中解决两种不同形式的多跳问题,且在MetaQA 数据集中实现了2 跳3 跳问题的100%准确性;Qin 等人[85]提出利用多个推理路径信息来解决多跳问题;Wu 等人[86]结合知识图谱中的数据作为上下文信息,结合注意力机制构建REN 模型.但面对不同的问题数据集时,解决多跳问题的模型在数据集上的扩展性仍是需要考虑的问题.
4.2 策略组合
随着近年来深度学习的发展,基于语义解析的方法和基于检索的方法正逐渐走向组合化,以STAGG为例,近年来出现的许多KBQA 算法都试图将这两种范式进行组合,从而使它们能够兼具两者的优点.信息抽取方式中提出的主题子图的概念与人类思维方式相似,语义解析方式可以更好地把握问题中的约束信息.因此,如何设计一个可以更好地整合这两种范式的优秀神经网络是未来的趋势.
4.3 数据质量
KBQA 的性能在很大程度上取决于知识图谱的质量和问题数据集的质量,但是现有开放式知识图谱的大小和完整性依然需要与时俱进.因此,知识图谱高效自动化建设将是KBQA 领域重要的研究方向之一.具备自动挖掘隐藏关系的能力将有助于系统及时准确地更新内容.另外,近年来流行的记忆网络,也证明了充分利用知识图谱先验知识也是重点研究方向之一.
4.4 可靠性与可解释性
尽管端到端模型的引入降低了人工成本,但是在端到端模型中,许多方法通常会忽略模型预测的不确定性,因为基于端到端的方法将所有决策留给模型本身,其中的不可解释性可能会使高性能KBQA 系统也变得不可靠,Zhang 等人[87]提出了一种基于贝叶斯神经网络(BNN)的端到端KBQA 模型,实体及其上下文和候选谓词均由Bayesian-BiLSTM 编码,其实验取得的成效说明在未来提高模型的鲁棒性,增强模型的可解释性也是该领域的一个必不可少的研究方向.
5 结束语
知识图谱囊括的知识数据与日俱增,自动问答需求充斥着社会各个领域,然而基于知识图谱的问答系统仍有许多技术难点亟待攻破.未来,基于知识图谱的问答系统应以构建回答准确率高、可解释性强、稳定可靠的模型为目标,不断迭代更新KBQA 领域的技术.
猜你喜欢
建材发展导向(2022年20期)2022-11-03
军事文摘(2022年16期)2022-08-24
建材发展导向(2022年12期)2022-08-19
舰船科学技术(2022年11期)2022-07-15
建材发展导向(2021年20期)2021-11-20
考试与评价·高二版(2020年2期)2020-09-10
新城乡(2018年6期)2018-07-09
长江学术(2015年1期)2015-02-27
中国报道(2009年12期)2009-01-15
