
基于积累周期分段编码的汽车车窗防夹学习算法
2022-05-11 10:42冯富霞李森贵
安徽工程大学学报 2022年2期
冯富霞,李森贵
(1.安徽工程大学 计算机与信息学院,安徽 芜湖 241000;2.芜湖莫森泰克汽车科技有限公司 研发部,安徽 芜湖 241000)
在金融、医学、监控等领域时间序列数据十分常见,精确并实时地判断出序列流中的异常非常必要。异常判断常用方法有数学分布、动态时间回归、概率后缀树、预测对比[1]、强力搜索[2]等,理论依据主要有概率统计、邻近度、判断模型、回归模型[3-4]、神经网络、支持向量机等。统计方法必须符合一定的数学分布;邻近度法常使用距离或角度差判断,编码选择的不同、差异对比技术选择的不同对结果的影响较大;判断模型、神经网络、支持向量机需要大量内存和运算量;回归模型参数复杂且参数敏感。
目前计算设备的硬件配置飞速提高,加之云技术的广泛应用,如果异常判断基于以上的先进设备及技术,则不用考虑计算量、数据量。但在有些场景下硬件配置是受限制的,甚至配置很低,无法使用高复杂度的算法,如雾计算在某些场景下甚至只有雾滴孤军奋战。实时有效地判断序列流异常的需求不会因场景不同而降低,例如汽车车窗防夹判断,硬件配置极大受限,对防夹算法的运算量、存储量要求非常敏感,同时准确度、实时性要求却十分高,这促使工程人员不断优化算法。
目前防夹算法有回归拟合跟随法,文献[5]先利用逆伽马函数拟合,再利用残差的正态分布检测异常,适用于残差符合正态分布的场景。文献[6-7]使用转矩线性拟合得到残差使用阈值判断。文献[8]利用高斯滤波滤除部分噪声,采用类似积分法对脉宽曲线进行计算,将积分面积与阈值比较判断,对脉冲的始末定位,周期变化敏感。以上都基于模拟系统信号,文献[5]需要残差符合正态分布,文献[6-8]均利用信号计算车窗的机械受力,计算复杂量大,且防夹阈值确定只有文献[7]给出了复杂推算方法。
利用数据分析和机器学习的技术,通过对大量实采数据的分析,依据数据蕴含的规律设计了简单、可靠的防夹算法。前期通过对不同路况和时速下的25组数据进行分析,每组3 000~5 000左右数据量,提出了跟随周期均值显著化序列异常数据的学习算法,详见文献[9],但是后期发现判断出的防夹点混杂着少数因路况极度颠簸出现的误防夹点。文献[10-11]利用多种算法的融合实现序列数据的预测和异常检测等,其中包括了分类算法和其有效性的证实,据此,本问题的研究引入了分类算法,并且数据追加到50组深入研究,提出了改进算法。基于积累周期分段编码的汽车车窗防夹学习算法,实现了简单、有效、实时地过滤信号流中的误防夹点。
1 关键技术选择与技术局限性问题的解决
时序序列编码被广泛应用的主要有离散傅里叶变换(Discrete Fourier Transform,DFT)、奇异值分解(Singular Value Decomposition,SVD)、分段线性估计(Piecewise Linear,PLA)、符号编码。DFT基本思想是把序列看成离散量,将其分解为正弦和余弦函数的线性融合函数,从时域变换为频域空间,对序列的平稳性要求比较高;SVD通过求矩阵的特征矩阵实现序列的降维编码,着眼全局数据,空间与时间复杂度最高;PLA最简单,使用广泛,通过分段线性表示简约总序列,既保持了宏观趋势特征,又适当保留了局部细节,权衡主要由分段的长短决定,适用闵可夫斯基距离度量子序列的相似度,文献[12]证实PLA的分段聚合近似(Piecewise Aggregate Approximation,PAA)方式比DFT效率高出1~2个数量级;符号法通过离散序列的值域空间实现序列的简约编码,对于获取序列的宏观趋势规律最合适,但是局部细节信息丧失太多,如布尔编码。由于这里需要准确、精确、实时地对序列流进行区分,简单有效的需求下选取PAA编码为依据。

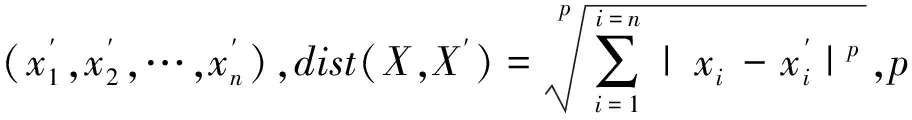
(1)幅平移与幅伸缩问题。序列的惯性决定后续子序列起始点取值的差异以及形成的幅平移,而闵可夫斯基距离法对幅平移和幅伸缩敏感。这里采用子序列的均值差值、分段斜率编码法,只保留与幅值无关的变化率,成功去掉了幅平移对结果的影响。两组幅平移子序列如图1所示。由图1可知,两组幅平移子序列,它们的形状完全相同,如果用幅值编码序列的方式进行距离对比,两者显然不同,而用拟合直线的斜率编码,它们的斜率相同,进行距离对比结果正好相同。周期分段子序列斜率编码如图2所示。由图2可知,编码(1.5,0.633,0.52)可去幅平移,编码与序列的起始点无关,子序列均值差值编码同理可以去除幅平移对结果的影响。幅伸缩正好是这里比较的依据,需要保留。

图1 两组幅平移子序列 图2 周期分段子序列斜率编码

此时距离计算与时间维度无关,即为闵可夫斯基距离公式。
2 汽车车窗序列数据特征分析与跟随周期分段编码
2.1 汽车车窗序列数据特征分析
这里的汽车车窗防夹序列数据包含霍尔信号和电压信号,先将两类数据融合成一组数据,实现数据平滑处理。序列数据正常情况下沿某一均值上下震荡,会出现均值上下浮动现象,震荡周期不均匀;防夹子序列数据幅值明显高于正常数据,属于连续小幅波动爬升过程;防夹点出现的判断是障碍物受力超出100 N,因此,实际中防夹子序列只能取到初始爬升区域,不允许放任到最高值的出现。对比周期子序列的数据变化趋势特征发现,信号序列存在3类变化趋势模式:缓爬升震荡式、递增爬升式、大幅爬升震荡式,3种模式恰好代表正常情况、防夹情况、剧烈颠簸情况,具体如图3所示。防夹子序列如果不加干预采集出的后续序列会继续增大幅度爬升。因此防夹检测即为分类问题,关键是找到分类依据和分类划分标准,同时在全局序列中抓取正常情况、防夹情况、剧烈颠簸情况的子序列。

图3 序列的3种分类
通过以上分析可知,序列数据具有惯性,相似序列幅度变化因素使防夹点的阈值无法固定,所以去除惯性因素是算法的关键,划分显著是算法高准确度的保障。前期根据跟随周期均值差值算法有效去除惯性因素,依据幅度增长积累可有效地划分出正常序列,但是防夹序列与剧烈颠簸序列间存在重叠无法区分,需要利用新分类依据和划分标准进一步完善算法,通过以上特征分析决定利用幅度增长率为分类依据探索再次分类特征。
2.2 利用幅度增长率实现异常序列的分段编码
要在前期算法的基础上,实现剧烈颠簸和防夹情况的有效区分。由于原始子序列对应的向量维数众多(大约40~60维),维数与最佳跟随周期的取值有关,数据取值范围大约在3 000~7 000,为了减小子序列距离计算的复杂度,需要进行重新压缩编码,恰当的分割长度下,斜率编码即可反应序列的宏观形态,同时又保证子序列间的局部差异特征。
为了提取带检测子序列的幅度变化特征,斜率编码的斜率计算需要对跟随周期T进行再次合理划分。在波浪式变化下,3维斜率向量恰好可以反应其形态特征。为了保障算法和跟随周期起始点的选取不敏感,向后追加了1维同等份斜率,这要求跟随周期宽度取值要合理,以免出现防夹子序列超出防夹力阈值的限制,前面防夹子序列的特征给出理由,这时即使判断出防夹,也属无效,或适当减少追加的数据量。命名此序列编码方式为4维编码S(k1,k2,k3,k4)。
斜率计算的改进。线性变化率可以用经典的最小二乘法计算,如式(1)所示:
(1)
式中,α即为k,累计求和,累计次数范围为1~T。斜率编码的目的是刻画变化趋势特征,不要求百分百的精确,这里把跟随周期T数据进行3等分分段后,每分段数据元组对数量较少,每分段可再二等分分段,每小段求均值,利用二分段的中点计算斜率改进式(1)。
设S((x1,y1),(x2,y2),…,(xT,yT)),则每分段的斜率
(2)
对比前面公式,运算量以及存储量明显降低,在这里效果等同。随机取一组T/3数据如表1所示。最小二乘法计算k为5.3,改进公式计算为5.5,例如,随机取T长度子序列编码为(1.5,0.63,0.5),如图4所示。

表1 随机取一组T/3数据

图4 T/3数据每段的二分中点计算斜率形成的斜率编码
3 正常序列、防夹编码序列和剧烈颠簸编码序列分类模型学习算法
3.1 利用跟随周期子序列均值差值编码分类正常和异常序列
利用跟随周期均值显著化序列异常数据的学习算法获取最佳的子序列划分长度T,同时得到区分异常和正常子序列的跟随周期均值差值的阈值α,T要达到符合防夹力阈值的要求。学习算法的主要思想:
(1)把训练数据集的每组整体信号序列按照周期T均匀划分。
(2)计算每组分子序列的均值,得到每组整体序列的均值编码



(3)T=T+Δt,重复(1)、(2)直到防夹子序列的涨幅积累最佳,同时正常子序列的涨幅积累要尽量与下降量抵消,α不再增加。验证等详见参考文献[9]。
分类正常和异常子序列。按照学习到的周期T划分整个待测序列,计算每一子序列的均值得到编码序列
3.2 防夹、剧烈颠簸序列分类特征阈值的训练算法与分析
4维编码S(k1,k2,k3,k4)为一个向量,在[-90°,90°]斜率变化幅度内以0°为中心,随角度变化斜率急剧变化是距离可分的,且距离成中心扩散分布状态。闵可夫斯基距离可选其不同形式,以计算简单为目的这里选欧式距离和曼哈顿距离,通过实验对比可知,曼哈顿距离优于欧氏距离。距离衡量需要有参照点和分类阈值,因此,需要事先通过历史数据学习找到合理的参照点c和距离分类的阈值供车窗防夹判断算法使用。

(1)利用跟随周期法分理出防夹和剧烈颠簸序列集,每个子序列带有分类标签l,0为剧烈颠簸分类,1为防夹分类。S异={s1{y1,y2,y3,…,y4T/3,l1},…,sn{y1,y2,y3,…,y4T/3,ln}};



选取部分数据如表2所示,进行实验验证。根据防夹序列距中心距离越收敛,剧烈颠簸序列距中心越发散,分类效果越好的原则,表中第2、第8初始点可为候选中心点,但是防夹和剧烈颠簸序列距离的最大、最小值差值分别为8.1和-5.1,若2为中心点则两类数据区分空间鲜明,而8为中心点则两类数据有交叉重合区域,最终选2为中心点。同时对比闵可夫斯基欧式距离和曼哈顿距离两种距离均值,曼哈顿距离使两类分类分离性更好,准确度更高,如图5所示。ROC图如图6所示。经过中心点选取算法和ROC分析可以获得分类模型的中心点C和分类距离阈值r。

图5 4编码防夹序列、剧烈颠簸序列距8个参照中心的闵可夫斯基欧式和曼哈顿两种距离均值

图6 4编码夫斯基欧式距离和曼哈顿距离 图7 部分防夹序列、剧烈颠簸序列分类 分类的ROC图 距分类中心C的距离分布

表2 防夹序列、剧烈颠簸序列距相应初始点为参照中心的平均距离
3.3 防夹、剧烈颠簸序列的分类特征阈值的验证
在测试集里验证2.1中学习到的阈值和分类中心的效果,分别计算测试数据编码序列与选定中心点C的距离如表3所示。距离分布如图7所示。空心点为剧烈颠簸序列与中心点距离,非空心点为防夹序列与中心点的距离,由图7可见,两类点有明显的分类特征,且防夹序列距离中心的距离全部落在阈值之内。分类距离不同阈值测试结果的评价指标如表4所示。

表3 部分测试数据编码序列与选定中心点C的距离

表4 分类距离不同阈值测试结果评价指标
3.4 车窗行进时霍尔信号序列流子序列的分类树模型


图8 霍尔信号序列流分类决策CART树 图9 车窗行进时序列流的防夹判断原理图
4 车窗行进时序列流的防夹判断算法设计
4.1 算法工作原理
算法首先需要读取并缓存待测序列流,进行异常检测,如有异常,由异常分类特征分离出防夹或剧烈颠簸,防夹情况则进行防夹处理,所有其他情况通知缓管道模块读取并更新相应数据,工作原理图如图9所示。
4.2 具体算法步骤
算法的必要数据设计需要缓存待测序列数据流,缓存数据的个数为2T,且为整数,T为跟随周期,设为s1(y1,y2,y3,…,yT)和s2(y1,y2,y3,…,yT);缓存序列编码后的一个子序列,设为s′(k1,k2,k3,k4),包含4个实数;参照中心序列(与s′相同编码的序列且有初始值),设为c(k1,k2,k3,k4);异常判断阈值为1个整数,设为α;分类判断距离阈值为1个整数,设为r。防夹算法的具体步骤:
(1)读取2T个待测序列信号预处理后,分别存入s1、s2;
(2)计算s1、s2的均值之差,如果大于阈值α,则出现异常,跳到步骤(5);

(4)进行防夹处理,跳到步骤(1);
(5)s1=s2,重新读取待测序列信号预处理后存入s2,返回步骤(2)。
由于参数T、α、c、r为离线训练得到,真正防夹算法的时间、空间复杂度小于o(3T),实验得出T为均小于80的整数。
5 结语
基于积累周期分段编码的汽车车窗防夹判断算法,利用数据本身蕴含的规律有效地提高了实时防夹检测的准确率,同时对外界干扰抵抗力良好,算法时间空间复杂度低,防夹定位稳定,对序列幅度数据的统计分布无要求;对于软件设计人员无需清楚硬件原理和复杂的车窗受力推导计算,只需关注信号的数据规律和软件设计。其简单高效、鲁棒的特点,尤为适宜实时监测硬件受限的应用场景,但是序列的时序维度要满足均匀分布的要求,例如点击事件序列流数据不适用。
猜你喜欢
山西教育·招考(2021年8期)2021-12-17
语数外学习·高中版上旬(2020年8期)2020-09-10
语数外学习·高中版上旬(2020年5期)2020-09-10
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
新高考·高三数学(2017年4期)2017-07-10
发明与创新·中学生(2017年5期)2017-05-12
理科考试研究·高中(2016年10期)2017-01-17
福建中学数学(2016年7期)2016-12-03
中学数学杂志(初中版)(2014年1期)2014-02-28
