
ABAFN:面向多模态的方面级情感分析模型
2022-05-19 13:29刘路路
计算机工程与应用 2022年10期
刘路路,杨 燕,王 杰
西南交通大学 计算机与人工智能学院,成都 611756
方面级情感分析(aspect-based sentiment analysis,ABSA)任务的目标是识别特定方面在文本序列中的情感极性。通常情况下对于一段包含多个方面的文本序列而言,其情感极性不一定是一致的,例如评论数据“手机的外观设计和手机界面还不错。耗电量很高,手机还没玩一会电量就跑得差不多了。”这段话中对于方面项“外观手感”而言,情感极性是积极的,而对于方面项“电池续航”而言,情感极性是消极的。
方面级多模态情感分析(aspect-based multimodal sentiment analysis,ABMSA)任务由Xu等人[1]首次提出,不同于方面级情感分析任务,其输入为多模态数据,包括图片和文本。当前社交网络或者电商平台用户在发布观点时通常不局限于文本数据,文本、图片、视频、音频等都是表达的渠道,因此以往基于文本的方面级情感分析任务已不满足日益增长的多模态数据所需。以电商平台淘宝为例,用户在购买产品并确认收货后可对该产品进行评价,很多用户在评价时不仅会用评论来描述商品的优劣,同时也会附上多张商品的图片来印证评论,因此在对特定方面进行情感分析时可以利用图片信息对文本信息进行补充或者加强。
近年来基于深度学习的方法不断刷新方面级情感分析模型的性能。在处理文本数据时,通常使用长短时记忆网络(long short-term memory,LSTM)结构,这是由于LSTM可以很好地建模文本序列数据并处理文本中的长期依赖关系。Tang等人[2]针对方面级的任务提出了TD-LSTM模型,采用两个LSTM分别建模方面词的左右上下文,这种方式考虑了方面词的作用,但是分开建模左右文本,未能很好处理方面词所在区域的上下文语义信息。Wang等人[3]提出了ATAE-LSTM,将注意力机制和LSTM结合起来让方面词参与计算,得到基于方面词的加权的上下文表示,这种结合LSTM和注意力机制的方式在处理ABSA任务时性能优异。但采用单向的LSTM结构建模文本序列时是通过之前的文本计算当前词的向量表示,对于ABSA任务而言,词向量的获取要考虑其所在的上下文,Chen等人[4]提出了RAM(recurrent attention on memory)模型,采用双向LSTM来获得文本的前向和后向表示。之前的研究都是根据方面词计算上下文表示然后执行情感分类,Ma等人[5]提出IAN(interactive attention network)模型同时计算基于上下文的方面词表示。
随着BERT模型的提出,各项自然语言处理(natural language processing,NLP)任务的结果都被刷新[6],包括ABSA任务[7]。这种基于大量语料训练出来的模型可以通过微调适应不同的NLP任务,相比于LSTM网络,这种预训练模型的性能要更好。
基于文本的情感分析任务只需要处理单模态的文本数据,多模态情感分析则还需要处理图片或者视频等其他模态的数据,当处理的视觉模态数据为视频这种序列数据时,仍多采用LSTM或者GRU等网络结构[8-9]。而当视觉模态数据为多张图片这种非序列数据时,则多采用卷积神经网络(convolutional neural network,CNN)来提取图片特征,比如VGG、Inception V3、ResNet等网络[10-11]。
基于图文的情感分析任务使用两种模态的信息通常能获得优于单模态的性能。Yu等人[12]针对基于实体的多模态情感分析任务,提出了ESAFN(entity-sensitive attention and fusion network)模型来融合文本表示和图片特征;之后引入BERT模型来处理图文数据又进一步提升了模型的性能[13]。Xu等人[1]针对基于方面的多模态情感分析任务提出了MIMN(multi-interactive memory network)模型,首先采用注意力机制获得基于方面词的上下文表示和视觉表示,然后通过多跳机制获得两个模态的交互表示。
本文在以往研究的基础上提出了基于方面的注意力和融合网络(aspect-based attention and fusion network,ABAFN)处理ABMSA任务。
BERT应用于情感分析任务通常能取得很好的性能。BERT内部主要由Transformer[14]的编码层组成,而其编码层内部主要基于自注意力结构,这种结构使得BERT可以并行化训练的同时,能捕捉到文本序列的全局信息,但也导致其很难得到文本序列词与词之间的顺序和语法关系。虽然可以通过位置嵌入来标记词的位置和顺序,但相比于传统的LSTM网络结构在获得词的上下文表示方面仍无优势。因此本文考虑将BERT和双向LSTM相结合来生成方面词和输入文本的上下文表示,从而充分利用二者的优势。
对于ABMSA任务而言,上下文和视觉表示中与方面词有关的局部信息往往对模型的分类性能有较大的影响,因此本文采用注意力机制对上下文和视觉表示进行加权,使模型能关注重要的局部信息。
本文主要做出如下两个贡献:
(1)提出了一个方面级多模态情感分析模型。首先将BERT和双向LSTM相结合获得文本的上下文表示,采用ResNet提取图片特征生成视觉表示;然后采用注意力机制获得加权后的上下文表示和视觉表示;最后对加权的上下文表示和视觉表示进行融合来执行分类任务。
(2)在方面级多模态情感分析数据集Multi-ZOL上的实验表明,相对当前已知最好的方面级多模态情感分析方法MIMN,模型在Accuracy和Macro-F1两个指标上分别提升了约11个百分点和12个百分点。
1 ABAFN模型
ABAFN模型主要由四部分组成:特征提取、基于方面的上下文表示模块(aspect-based textual representation,ABTR)、基于方面的视觉表示模块(aspect-based visual representation,ABVR)、情感标签分类模块。模型的整体结构如图1所示。

图1 ABAFN模型的整体结构Fig.1 Overall structure of ABAFN model
对于给定的包含n个词汇的上下文文本模态信息S={s1,s2,…,s n},包含m个词汇的方面项A={a1,a2,…,a m},以及包含p张图片的视觉模态信息V={v1,v2,…,v p},ABAFN模型的目标是通过V和S两个模态对方面A的情感标签进行预测。
1.1 特征提取
(1)方面词表示
首先采用BERT得到方面词的嵌入向量表示,由于通常情况下方面词由多个词组成,并且词与词之间语义相关,因此之后采用双向LSTM得到方面词的上下文表示,最后通过平均池化得到最终的方面词表示。在计算嵌入向量表示之前需要先通过BertTokenizer将方面词转化为程序可以处理的id。对于方面词表示而言,Bert-Tokenizer的输入为“[CLS]+方面词+[SEP]”。方面词表示的计算过程如下:

(2)文本上下文表示
对于分词后的文本依然采用BERT得到其嵌入表示,并通过双向LSTM获得文本的上下文依赖关系,双向LSTM输出的隐藏状态表示为最终的文本上下文表示。同方面词表示一样,分词后的上下文文本需要采用BertTokenizer将上下文转换为程序可以处理的id表示。但文本上下文表示的BertTokenizer的输入为“[CLS]+文本+[SEP]+方面词+[SEP]”。文本上下文表示的计算过程如下:


(3)视觉表示
对于输入的图片首先将其转换成RGB格式,然后提取预训练的ResNet-50网络并去掉最后的全连接层,将图片输入到ResNet网络中计算图片特征表示,将多个图片特征附加在一起得到最终的视觉表示。视觉表示的计算过程如下:

1.2 ABVR
ABVR模块的作用是获得基于方面词的视觉表示,通过注意力机制可以得到加权的视觉表示。在计算注意力分数之前需要采用全连接层将q维视觉向量映射为2d维如下:

其中,W V∈ℝ2d×q和bV∈ℝ2d分别为权重和偏差,由模型训练所得,R V2d∈ℝp×2d。视觉表示中每个图片的注意力分数根据如下公式所得:


其中,a v∈ℝ2d,W v∈ℝ2d×2d和b v∈ℝ2d分别为权重和偏差,由模型训练所得。
1.3 ABTR
ABTR模块的作用是捕捉与方面词有关的上下文表示,主要通过注意力机制实现。上下文表示中每个词的注意力分数由如下公式所得:

最后通过激活函数得到非线性的上下文表示:

其中,a s∈ℝ2d,W s∈ℝ2d×2d和b s∈ℝ2d分别为权重和偏差,由模型训练所得。
1.4 情感分类
在预测情感标签分类结果时首先将最终的视觉表示av和上下文表示as进行级联融合后得到的表示如下:

其中,f∈ℝ4d。
最后通过softmax获得分类结果,具有最高概率的标签将会是最终的结果。

其中,C设置为8,ŷ∈ℝC为情感标签的估计分布。
1.5 模型训练
最后通过优化交叉熵损失对模型进行训练:

其中,y为原始分布。
2 实验及结果分析
2.1 数据集及实验参数
模型主要在Multi-ZOL数据集[1]上进行验证。Multi-ZOL数据集来源于ZOL.com上手机频道的评论数据,Xu等人抓取了不同手机的前20页评论数据,包括114个品牌的1 318种手机,通过过滤单一模态的数据,最终保留了5 288条多模态评论数据。数据集的统计信息如表1所示。

表1 Multi-ZOL数据集的统计数据Table 1 Statistics of Multi-ZOL dataset
Multi-ZOL数据集的每条数据包括一段文本评论和多张图片,每条数据都包含1~6个方面,分别是性价比、性能配置、电池续航、外观手感、拍照效果、屏幕效果。通过将方面词与多模态评论数据配对,最终得到28 469条方面-评论对样本。每个样本都有对应的情感标签,情感标签为1~10的整数。
Multi-ZOL数据集按照8∶1∶1的比例划分为训练集、验证集和测试集。图2是三种数据集的情感标签分布。可以看到训练集和测试集中情感标签为7和9的评论样本数量为0,验证集中同样不包含情感标签为7和9的数据,因此在执行情感标签分类任务时模型设置为八分类。
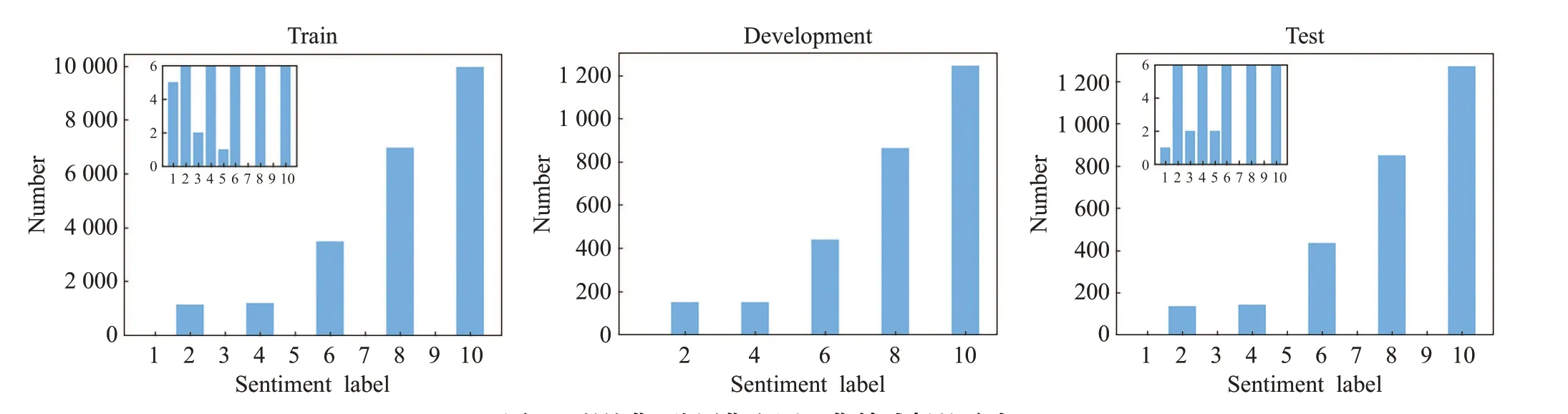
图2 训练集、验证集和测试集情感标签分布Fig.2 Distribution of sentiment labels in train set,development set and test set
模型的超参数设置如表2所示。所有参数使用Adam优化器进行更新。模型采用python语言、pytorch框架,在AI MAX集群上进行训练,使用一块GeForce RTX 3090 GPU。本文基于BERT的对照模型均采用相同的超参数设置。其中,早停轮数设置为10,指的是当模型训练时验证集连续几轮F1分数都未取得提升时停止训练,从而防止过拟合。

表2 模型的超参数设置Table 2 Hyperparameters setting of model
2.2 基线模型
ABAFN模型主要和五个基于纯文本的模型和两个基于图文多模态的模型进行了对比。此外对已提出的多模态MIMN模型,修改其嵌入层为BERT,设计了MIMNBERT模型,并测试了修改后的模型在Multi-ZOL数据集上的性能。
2.2.1 基于纯文本的模型
(1)LSTM[3]:对于输入的文本序列,采用一层LSTM学习其上下文表示,并对输出的上下文隐藏状态求平均作为最终的表示来执行分类任务。
(2)MemNet[15]:将上下文序列的词嵌入作为记忆(memory),结合方面词嵌入采用多跳注意力机制获得最终的上下文表示,相比LSTM更加快速,可以捕获与方面词有关的上下文信息。
(3)ATAE-LSTM模型[3]:该模型主要采用了LSTM结构,并将方面词嵌入和文本表示级联送入LSTM,同时在LSTM的隐藏层输出部分再一次级联方面词嵌入,最后通过注意力机制获得最终表示并进行预测,这种方式使得模型可以更好地捕捉和方面词相关的文本序列。
(4)IAN模型[5]:该模型通过两个LSTM分别获得方面词和上下文的隐藏层表示,并通过平均池化和注意力机制获得基于上下文的方面词表示和基于方面词的上下文表示,最后通过级联进行分类。
(5)RAM[4]:采用双向LSTM学习上下文的隐藏表示并将其作为Memory,并对隐藏表示进行位置加权得到位置权重Memory,然后通过对多个注意力层和GRU网络进行叠加得到最终的表示。位置加权可以使模型针对不同的方面得到相应的上下文表示。
2.2.2 基于图文多模态的模型
(1)Co-Memory+Aspect[1]:将方面词信息引入多模态情感分析模型Co-Memory[16]中作为上下文和视觉记忆网络的输入。
(2)MIMN[1]:对于上下文、方面词和图片特征分别采用双向LSTM获取隐藏表示,然后结合多跳(hop)注意力机制融合两个模态的信息进行情感分类任务。其中除第一个hop的输入为单模态数据和方面词表示外,其他hop的输入为两个模态的表示,以此学习交叉模态特征,每一hop都由注意力机制和GRU组成。
(3)MIMN-BERT:将MIMN模型中的嵌入层替换为BERT来获得上下文和方面词的嵌入表示,对于嵌入维度以及最大的文本长度等参数均设置为与ABAFN模型一致。
2.3 实验结果
(1)主要结果分析
表3 为ABAFN模型与其他模型Accuracy和Macro-F1的比较。其中前7个模型的结果取自文献[1],后两个模型的结果为集群上训练所得。
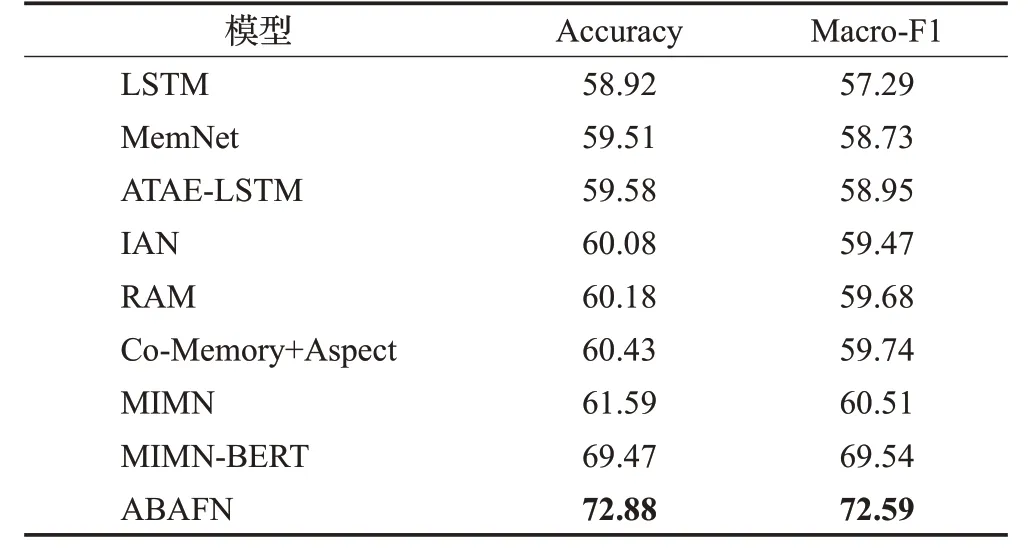
表3 ABAFN与基线模型的比较结果Table 3 Comparative results of ABAFN and baselines %
从表3中可看到基于图文多模态的模型性能普遍好于基于纯文本的模型。此外当嵌入方式选择BERT嵌入时MIMN-BERT模型相较于MIMN模型在评价指标Accuracy上提升了约8个百分点,Macro-F1提升了约9个百分点,因此可表明当模型采用预训练语言模型做嵌入时可以获得更好的文本表示,对模型的性能有很大的提升。最后可以观察到ABAFN模型相比于MIMNBERT在两个评价指标上都有3个百分点以上的性能提升,这表明ABAFN模型获取图文表示的方式以及对应的融合方式要优于MIMN-BERT。
(2)消融实验分析
表4为ABAFN的消融研究,其中ABVR为采用基于方面的视觉表示直接进行情感分类的结果,ABTR为采用基于方面的上下文表示直接进行情感分类的结果,ABAFN为融合两个模态表示的结果。
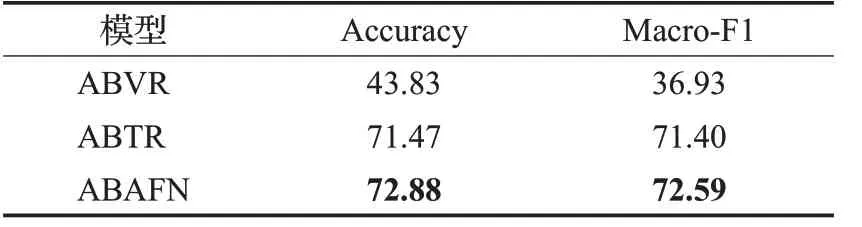
表4 ABAFN的消融研究Table 4 Ablation study of ABAFN %
可以看到多模态相比于基于上下文的单模态ABTR在Accuracy和Macro-F1上有超过1个百分点的性能提升。这是由于相比于单个模态,多模态的图片信息对文本信息进行了补充,来自多个数据源的数据可以使得模型学习到更多的信息,因此多模态模型性能往往好于单模态。
(3)案例研究
通过对测试集中的案例在MIMN-BERT、ABTR、ABAFN三种模型上执行情感标签分类的测试,可以进一步分析三种模型的性能。从表5可以看到分词后的文本前半句的情感极性是积极的,后半句的情感极性是消极的,而方面词“拍照效果”主要关注的是前半句,三种模型都可以很好地识别出与方面词相关的局部信息,做到正确的分类。从表6可以看出MIMN-BERT、ABTR、ABAFN三种模型在对情感标签进行预测时最多接近真值3,却无法正确预测出来,推测原因是从图2可知训练集中情感标签为3的数据较少,验证集中更是没有,存在一定的数据不平衡问题,因此训练后的模型很难准确识别该标签。从表7可以看到ABTR预测接近真值,但ABAFN预测值和真值相同,这说明相较于单个模态,多模态包含更丰富的信息,图片特征对改进模型的分类性能有积极的效果。从表8可以看到MIMNBERT预测错误,ABTR和ABAFN预测正确,这说明即使是仅使用单个模态的ABTR模型在一些情况下效果也好于多模态的MIMN-BERT模型,进一步表明了本文获取文本表示的方式的优异性。从表9可以看到仅ABAFN模型预测正确,这表明相比于MIMN-BERT的融合方式,本文对两种模态的信息直接进行级联融合在部分情况下能取得更好的分类性能。

表5 MIMN-BERT、ABTR、ABAFN预测正确案例Table 5 Correct prediction case of MIMN-BERT,ABTR,ABAFN

表6 MIMN-BERT、ABTR、ABAFN预测错误案例Table 6 Misprediction case of MIMN-BERT,ABTR,ABAFN

表7 ABTR模型预测错误案例Table 7 Misprediction case of ABTR

表8 MIMN-BERT模型预测错误案例Table 8 Misprediction case of MIMN-BERT

表9 MIMN-BERT和ABTR模型预测错误案例Table 9 Misprediction case of MIMN-BERT,ABTR
3 结束语
本文提出了一个方面级多模态情感分析模型ABAFN。对于中文文本数据,采用预训练语言模型BERT得到分词后文本的嵌入表示,这种基于大量语料训练得到的模型生成的词向量更好,而生成词向量的方式对模型最终的性能影响很大。BERT内部主要由自注意力机制构成,使得其无法很好地建模序列数据,而双向长短时记忆网络不仅可以很好地解决这一问题,还能够处理文本序列的长期依赖关系,因此模型中BERT的下游接一层双向长短时记忆网络。对于方面级的情感分析任务而言,关键在于识别与方面词有关的局部信息,通常采用注意力机制达到这一目的。而对于方面级多模态情感分析任务,融合多个模态的信息往往能进一步提升模型的性能。本文通过级联融合的方式融合了文本和视觉模态的信息,取得了相比于单模态更好的性能,但与此同时,这种融合方式较为简单,因此下一步可以通过探索多模态图文数据的融合方式来进一步提升模型的性能。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
甘肃教育(2020年22期)2020-04-13
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
