
基于集成学习的上市公司高送转预测实证研究
2022-05-19 13:30张田华罗康洋
计算机工程与应用 2022年10期
张田华,罗康洋
1.上海工程技术大学 数理与统计学院,上海 201620 2.华东师范大学 计算机科学与技术学院,上海 200062
高送转指的是上市公司送红股或以资本公积金、盈余公积金的形式转增股份,合计达每10股送转5股以上。施行高送转可以加强公司增资扩股的力度,但实质是公司内股东权益结构的调整,不会对公司的盈利能力产生实质性的影响。然而,普通投资者通常认为高送转是重大利好消息。高送转概念股在除权时价格降低,填权时股票价格又上涨的变化过程深受投资者的追捧,逐渐发展为A股市场中的投资热点。有研究表明,市场处于上涨行情时投资者更加偏爱发放股票股利的公司[1]。但随着高送转概念的炒作愈演愈烈,市场中开始萌发一些乱象。比如部分公司的大股东利用高送转概念在股价上涨时高位减持股份以实现个人利益;甚至有公司在亏损的情况下依然推出高送转方案,这些行为会对投资者的合法权益造成严重损害[2]。毋庸置疑,盲目追逐高送转概念这种非理性的投资行为会使股市中的非理性投机泡沫水平不断升高,与此同时泡沫破裂的风险也不断增大[3]。沪深交易所为了对上市公司的送转股行为进行规范,维护证券市场的正常交易秩序和广大投资者的合法权益,于2018年11月发布《上市公司高送转信息披露指引》,主要指引公司合理调整回报投资者的方式,培育健康的投资理念,凭借优秀的业绩来吸引投资者的关注。本文根据上市公司的财务数据进行高送转预测实证研究,不仅能为A股市场的监管提供清晰和明确的信号,而且可为广大投资者提供较为科学的投资决策指导。
从国内相关研究来看,已有的成果主要关注上市公司高送转的内部动因、高送转股票的财富效应以及除权除息日前后上市公司的股价波动情况。文献[4]研究认为A股市场的高送转概念股是上市公司为了迎合投资者的非理性投资需求而主动施行的,且存在上市公司借助高送转来实现管理层及大股东利益最大化的现象。文献[5]对上市公司内部管理者股票的减持是否会影响公司高送转进行了实证研究,认为内部人的股票减持是上市公司实施高送转的主要动机。文献[6-9]的研究表明,股权质押是上市公司施行高送转的重要原因,当上市公司内存在股权质押,特别是第一股东质押或第一股东和其他股东共同质押时,高送转的概率更高。已有文献主要研究了我国上市公司进行“高送转”的深层动因,揭示了“高送转”背后的动机,为监管机构治理“高送转”乱象提供经验证据支持。但很少有文献讨论上市公司财务指标与高送转的关系以及利用数据挖掘技术研究上市公司是否真的有潜力进行高送转。基于此,本文旨在利用上市公司的财务数据以及历年高送转的真实情况进行高送转预测实证研究,不仅能丰富上市公司高送转预测的研究成果,对于保护投资者的权益也具有重要的实践意义。
从统计学角度来看,高送转的预测研究可以视为二分类问题。截至2020年8月,我国上证和深证A股股票分别为1 578支和2 131支,合计3 709支。经初步统计2010—2019年A股市场平均每年约270支股票实施高送转。由此可见,非高送转股票的数量远多于高送转股票的数量,即高送转数据具有明显的不平衡特性。此外,影响上市公司高送转的财务指标众多且存在着共线性等特征。针对数据中存在的上述特性,文献[10-11]的研究表明,在采样方法处理后的数据集上对财务指标进行特征选择可以有效提升预测模型的整体性能。
综上,本文旨在借助采样、特征选择以及集成学习构建上市公司高送转预测模型。首先,将Borderline-SMOTE过采样、自适应合成过采样(adaptive synthetic sampling,ADASYN)和SMOTE&TomekLink组合采样作为比较方法,分别对原始数据集进行平衡化处理;其次,将Relief特征选择与最大相关最小冗余(max-relevance and min-redundancy,mRMR)特征选择算法作为比较算法,分别对数据集做降维处理,以筛除一些冗余指标;最后,建立随机森林(random forest,RF)、极端梯度提升(extreme gradient boosting,XGBoost)和自适应增强(adaptive boosting,Adaboost)高送转预测模型对上市公司的高送转情况进行实证研究。
1 相关算法介绍
1.1 采样方法
采样方法可以缓解数据类间不平衡的问题,主要分为欠采样和过采样两种[12]。欠采样方法的主要思想是减少多数类样本的数量直到与少数类样本成一定比例,从而实现数据的平衡。欠采样能够有效提高分类器的性能,但也存在删减多数类样本的能力有限以及损失部分有效信息等不足之处。过采样方法的主要思想是通过某种人工合成的方法生成一部分少数类样本,使少数类样本的数量与多数类样本的数量相近,从而达到类别平衡的目的,过采样保留了原始数据集的全部信息。下面简单介绍本文所用采样方法的主要思想。
1.1.1 BorderlineSMOTE采样
BorderlineSMOTE[13]是基于经典的合成少数类过采样方法(synthetic minority over-sampling technique,SMOTE)[14]改进的一种算法。该算法首先利用K近邻算法将少数类样本划分为“Safe”“Danger”和“Noise”三种,然后按照SMOTE算法的线性插值原理,对分布在少数类样本边界附近(“Danger”类)的样本点过采样,从而改善样本的类间分布。
1.1.2 ADASYN采样
ADASYN[15]是SMOTE的另一种改进算法。该算法的核心思想是利用密度分布自适应确定需要生成的少数类样本的数量,根据少数类样本的学习难度分别对其进行加权分配。ADASYN可有效缩小由于类不平衡问题而带来的误差,并且分类决策边界会自适应地转移到更难学习的样本上,迫使后续的分类算法更加关注学习困难的样本。
1.1.3 SMOTE&TomekLink组合采样
SMOTE&TomekLink是将SMOTE与TomekLink结合在一起的组合采样技术[16]。其中TomekLink是一种欠采样方法[17],主要思路是:若两个样本点可以形成TomekLink连接,可能其中一个样本点远背离正常分布,也可能两个样本点都落在边界附近,删除Tomek Link可以把类间重叠的样本清洗掉,从而使互为最近邻的样本成为一类。SMOTE&TomekLink组合采样的主要思想是首先通过SMOTE算法对少数类样本进行扩充后,然后利用TomekLink技术剔除噪声点和边界点,对数据进行平衡化处理。
1.2 特征选择算法
特征选择算法通过某种评价标准和搜索策略滤除数据集中的冗余特征,以达到优化预测模型的目的。特征选择算法一般包括封装式(wrappers)与过滤式(filters)两类[18]。与封装式算法相比,过滤式算法的复杂度较低,在大规模数据集上也能表现良好,具有较强的通用性。因此,本文将利用Relief和mRMR两种过滤式算法进行特征选择。以下对其主要思想进行简单介绍。
1.2.1 Relief算法
Relief是一种过滤式特征权重算法[19],主要思想是根据特征和类别之间的相关关系赋予该特征相应的权重,特征辨别近邻的同类和不同类样本间距离的能力决定权重的大小。
Relief算法从训练数据中随机取出一个样本Ri,然后在R i的不同类样本中寻找最近邻的样本Mi,记为NearMiss;在Ri的同类样本中寻找最近邻的样本H i,记为NearHit。按照以下标准更新特征的权重值:

其中,D(A,B)表示在某个特征上样本A与样本B的欧式距离。重复上述过程m次以计算各特征的平均权重。
1.2.2 mRMR算法
mRMR[20]是一种同时考虑特征自身的相关性以及特征与目标变量之间相关性的过滤式特征选择算法。在选择特征的过程中,与目标变量相关性高的特征组合不一定能达到增强分类器性能的效果,因为特征之间可能存在多重共线性。mRMR算法的目的是选出与类别最大相关且特征间最小相关的“最纯净”的特征子集。
假设特征集S中的第i个特征用f i表示,S与类别c之间的两种最大相关最小冗余的度量方式如下:

其中,R(f i,c)用来度量特征f i与类别c之间的相关性;D(f i,f j)用来度量特征f i与f j间的相关性。已有研究表明后者比前者更为有效,因此本文选用式(2)进行实证研究。
1.3 集成学习
集成学习是指将一个问题分解到多种不同的方法中,连结多个学习器来完成学习任务。集成学习包括序列化方法和并行化方法两种。前者指学习器之间存在较强的依赖关系,需要串行生成,比如Boosting[21];后者指学习器之间没有强依赖关系,可以同时生成,比如RF[22]。下文对RF算法、XGBoost和Boosting做简要介绍。
1.3.1 RF
RF算法是一种基于决策树的组合分类器[23],其主要思想是:第一步从训练数据集中运用自主抽样法(bootstrapping)提取多个样本以创建N个训练子集;第二步对提取出的每个样本建模生成N棵决策树,进而形成“森林”;最后将这些决策树进行组合并采用投票的方式获得最终分类或预测的结果。RF算法中随机性的引入克服了单一决策模型容易过拟合的问题。
1.3.2 XGBoost
XGBoost是Boosting族中的一种提升树模型[24],具有训练速度快、能有效处理大规模数据等优点。XGBoost的主要思想是集成多种弱分类器,从而形成强分类器,不断拟合上一棵树的残差来产生新树,每加入一棵决策树模型整体的性能都必须有所提升,直到性能不再提升或下降时结束算法。XGBoost的决策函数为:

其中,f k(xi)是第k棵树在节点x i的预测值。XGBoost在预测某个样本的分数时,会根据样本的不同特征在每棵树中映射到相应的叶子节点,该样本的预测值即为每棵树对应叶节点的得分之和。
1.3.3 Adaboost
Adaboost是一种经典的提升算法[25],运用单层决策作为基分类器。该算法采用迭代的思想,每次迭代仅训练一个基分类器,在训练的过程中把预测结果中分类错误的样本权重提高,分类正确的样本权重降低,促使后续的训练过程中基分类器更加关注被错分的样本,训练完成的基分类器会加入下一轮的迭代,直到迭代次数达到预先设置的最大值或错误率充分小时才能确定最终的强分类器。
2 实证研究与分析
2.1 数据来源
本文数据来源于第八届“泰迪杯”全国数据挖掘挑战赛A题赛方提供的数据[26]。其中,基础数据包含3 466家上市公司的上市年限、所属行业及所属概念板块;年数据包含上市公司连续7年的财务指标数据及是否进行高送转等信息。本文选用制造业上市公司的财务数据对上市公司高送转情况进行实证研究,样本总数为12 204个,每个样本有363个财务指标。
2.2 数据预处理
对获得的原始数据集进行如下预处理:首先,删除被特别处理(special treatment,ST)的股票数据以及方差过小无法提供有用信息的指标。其次,对缺失值进行处理,且处理规则为,缺失程度在50%及以上的样本指标予以剔除;缺失程度在50%以下的样本指标,采用KNN多重填补法进行填补。经过数据处理后,用于建模的数据共有12 204个样本,每个样本有234个特征,其中非高送转样本(多数类样本)有10 051个,高送转样本(少数类样本)有2 153个,数据集呈现显著的类不平衡特点。最后,运用离差标准化对数据进行处理,以消除指标间量纲不同的影响。为验证本文所构建模型的有效性,将第1年至第6年的数据作为训练集,其中多数类和少数类样本分别为8 268个和1 778个;将第7年的数据作为测试样本集,其中多数类和少数类样本分别为1 783个和375个。
2.3 分类评价指标
本文所研究的上市公司高送转预测模型本质是对高维类不平衡数据集构建分类器。数据集的类不平衡特性,使得传统的用于衡量分类器性能的评价指标如精度等不再适用。因此,利用混淆矩阵(如表1所示)构造正类样本召回率rr p、负类样本召回率rr n、G-means和F-value,并将其作为评估预测模型性能的指标。设少数类样本为正类样本,多数类样本为负类样本。
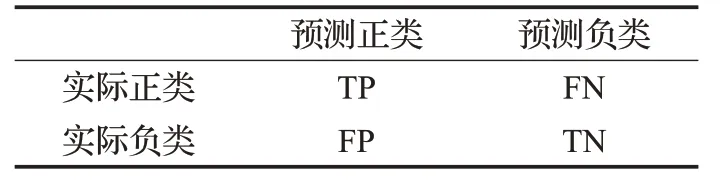
表1 混淆矩阵Table 1 Confusion matrix
TP表示正类样本被预测正确的数量,FN表示正类样本被预测错误的数量,FP表示负类样本被预测错误的数量,TN表示负类样本被预测正确的数量。根据混淆矩阵,rr p、rr n、G-means(G)和F-value(F)的定义如下:
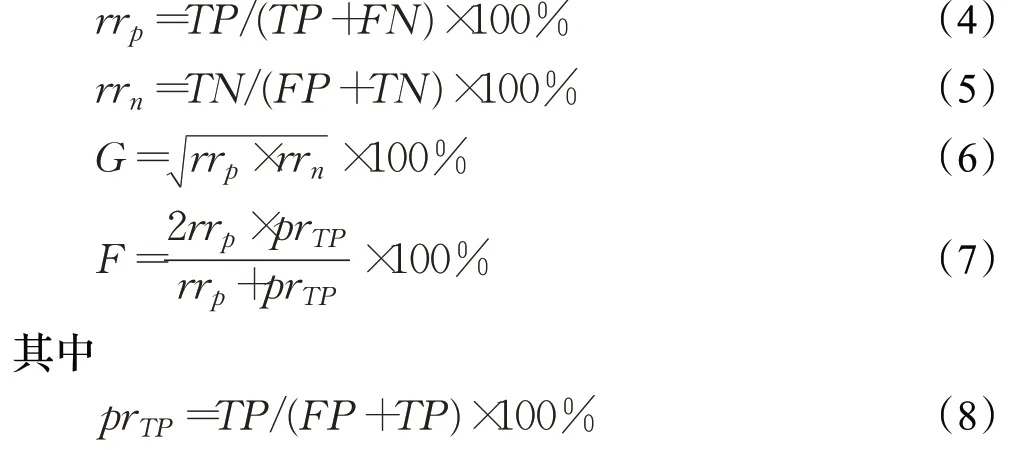
从上市公司高送转预测的角度来说,rr p指高送转样本被正确预测的概率,该值越大表示模型识别高送转样本的能力越强;rr n指非高送转样本被正确预测的概率,该值越大表示模型识别非高送转样本的能力越强。G值同时考虑了模型对于正类以及负类样本的预测性能,该值越大表明模型的综合预测能力越强。F值则考虑了模型对于正类样本的分类准确性,该值越大表明模型对于正类样本的识别能力越强。
2.4 参数设置与实验模型
参数设置是否合适直接影响到预测模型对上市公司高送转预测的准确性。本文的参数设置分为三部分:采样、特征选择以及集成算法。根据经验以及反复调参的结果,三种采样方法中,将用于合成新样本的最近邻数均设置为5;特征选择算法中,分别将Relief特征权重排序在前70和mRMR值大于10的财务指标作为比较特征集,用于构建预测模型。集成算法参数的搜索范围如表2所示。
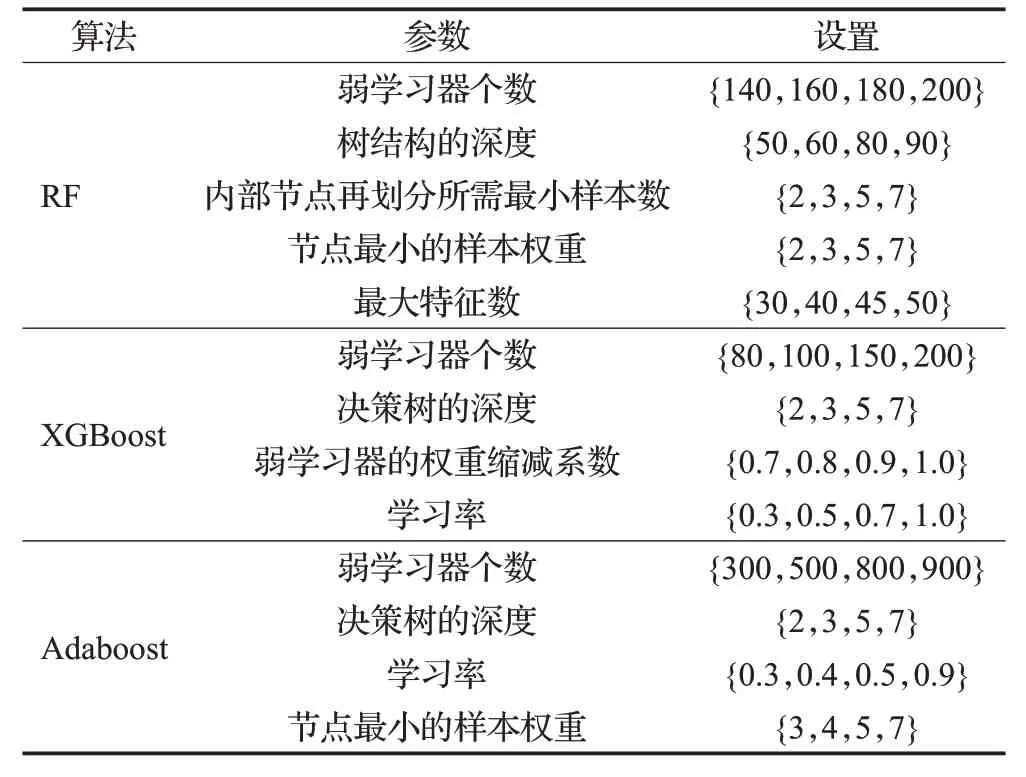
表2 集成算法参数设置Table 2 Parameter settings of integration algorithm
基于以上参数设置,本文共研究18个实验模型,模型的组合形式为“采样+特征选择+分类”,以及18个对照模型,模型的组合形式分别为“特征选择+分类”“采样+分类”“分类”。采样方法包括ADASYN、BorderlineSMOTE和SMOTE&TomekLink组合采样;特征选择算法包括Relief和mRMR;分类方法包括RF、XGBoost和Adaboost。
为了搜寻集成算法的最佳参数以及充分验证模型的有效性,根据表2设置的候选参数对不同模型进行3折交叉验证的网格搜索。由于采样的过程中存在一定的随机性,本文所有实证研究结果均为循环10次的平均值。
2.5 实证结果分析
2.5.1 预测效果分析
各模型的预测效果如表3所示。从是否采样的角度看,实验组的rr p值和G值最低分别为80.69%和85.63%,最高分别为84.96%和88.46%,平均分别为82.32%和87.47%;对照组1中的rr p值和G值最低分别为52.53%和71.74%,最高分别为64.40%和79.45%,平均分别为60.99%和77.24%。相较于对照组1,实验模型1~18的rr p值总体提高了34.97%,G值总体提高了13.24%。因此,采样方法的引入在较少牺牲非高送转样本准确率的前提下,高送转样本的准确率得到较大提升,使得预测模型的整体性能显著提高。此外,实验组的rr n值最低、最高和平均分别为89.71%、95.12%和93.03%;对照组1中的rr n值最低、最高和平均分别为97.98%、98.43%和97.95%。对照组1中的rrn值相比实验组的rr n值总体高了5.29%,这说明直接对不平衡数据建模预测结果会大幅偏向非高送转样本,导致高送转样本的准确率牺牲较大,这与本文的研究目的相悖。
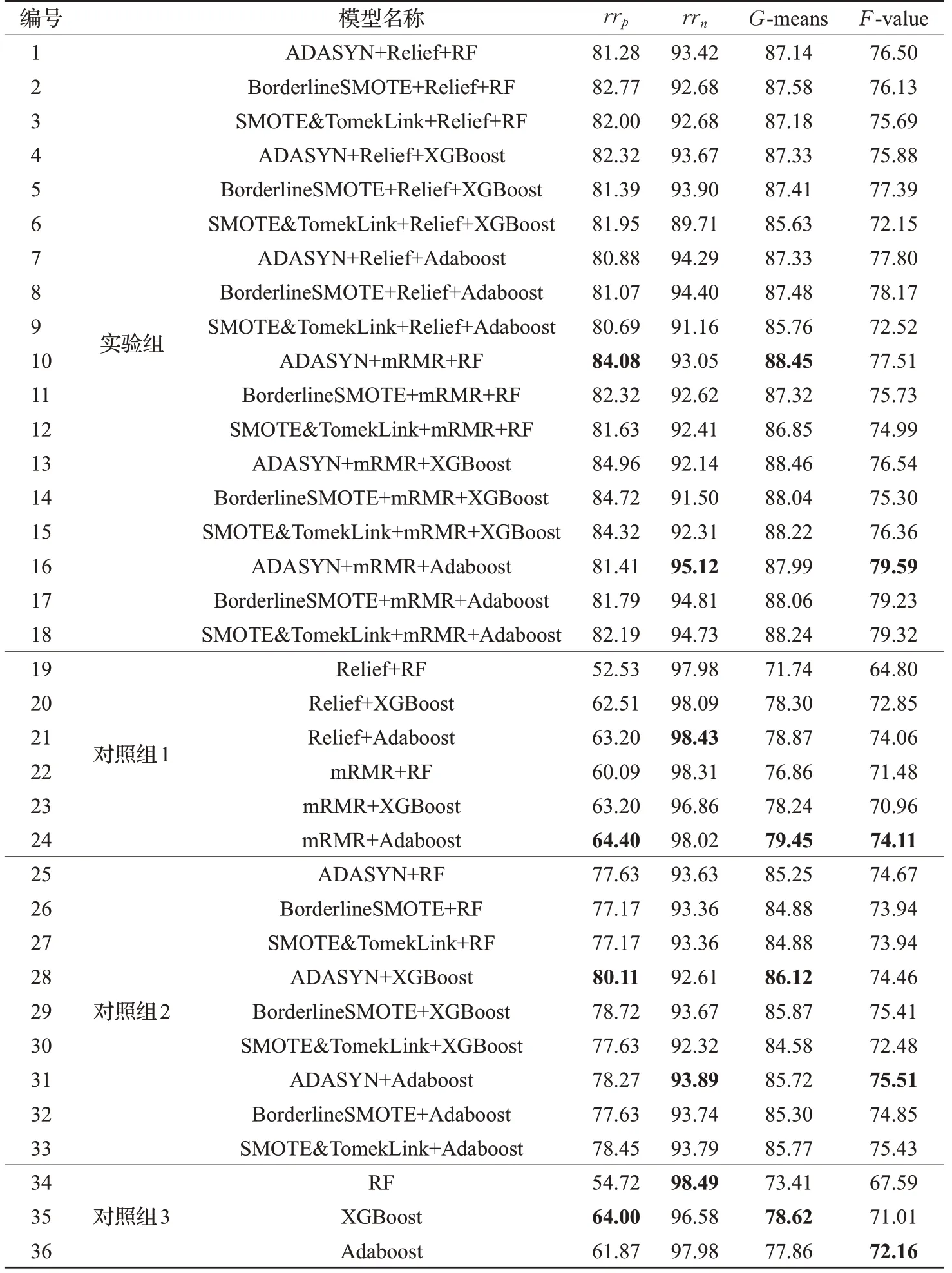
表3 模型预测效果Table 3 Prediction effect of model %
从是否进行特征选择的角度看,对照组2的rr p值和G值最低分别为77.63%和84.58%,最高分别80.11%和86.12%,平均分别为78.09%和85.37%。相比之下,实验组的rr p值和G值整体分别提高了5.42%和2.46%。可以看出,特征选择在不影响模型整体性能的前提下,提升了高送转样本预测的准确率。
比较对照组3与其他模型可发现,采样方法和特征选择算法的引入均能有效提高模型的整体分类准确率。但就提升效果来看,采样方法对模型性能的提升效果更加显著,即数据类间不平衡对预测效果的影响更大。
从分类算法的角度看,模型1~3的rr p值和G值平均分别为82.02%和87.30%;模型4~6的rr p值和G值平均分别为81.89%和86.79%;模型7~9的rr p值和G值平均分别为80.88%和86.86%。可以知道,采用Relief特征选择算法时,RF分类算法的表现最好。模型10~12的rr p值和G值平均分别为82.68%和87.54%;模型13~15的rr p值和G值平均分别为84.67%和88.24%;模型16~18的rr p值和G值平均分别为81.80%和88.10%。易知,采用mRMR特征选择算法时,XGBoost分类算法的效果最好。
在所研究的18个实验模型中,模型13(ADASYN+mRMR+XGBoost)取得了最优的rr p值和G值,分别为84.96%和88.46%;模型16(ADASYN+mRMR+Adaboost)取得了最优的rr n值和F值,分别为95.12%和79.59%。模型13的rr p值比模型16的rr p值高3.55%,但rr n值却比模型16的rr n值低2.98%。由于模型16的rr p值提升的同时也损失了一部分高送转样本的识别准确率,致使模型16的G值比模型13的G值略低,并且在实际应用中,人们更加关注模型对于高送转样本的识别能力,即rr p值的提升对于投资者的意义更大。因此,如果不同评价标准所得到的最优模型结果不一致,建议优先利用rr p值选择最优策略。综合考虑本文所研究模型的预测效果,模型13(ADASYN+mRMR+XGBoost)对上市公司实施高送转的预测效果最优。
2.5.2 特征选择结果分析
基于上述的预测效果,下面进一步分析模型的特征选择效果。所有模型选出的前10个主要变量如表4所示。通过比较可知,在ADASYN+mRMR、BorderlineSMOTE+mRMR和SMOTE&TomekLink+mRMR这3种模型中每股净资产的重要性均在第一位,每股净资产即每股股票能够代表的公司净资产值的大小,该指标的值越大表示公司的盈利能力和抗风险能力越强,财富实力也越雄厚。排在第2位的是归属于母公司的股东权益/总资产,该指标反映公司资产中由母公司投入的比重,指标值减小说明公司负债增加,相应地抵抗外部冲击的能力也会减弱。排在第3位的是归属于母公司的股东权益/投入资本,股东权益由股本、资本公积和未分配利润构成,该指标值越大表明公司的成长能力越强。排在第4、5位的是每股收益和每股资本公积。通常高累积和高业绩是公司实施高送转政策的基础,高累积指每股未分配利润和每股资本公积较丰厚;高业绩指上市公司具有较强的盈利能力,而每股收益指标恰能代表公司的盈利能力[27]。排在第6位的是资产负债率,这是评估公司负债程度的重要指标。排在第7位的是流动资产/总资产,是衡量公司营运能力的重要指标,一般来说流动资产占总资产的比重越大表明资产的流动性越高;如果流动资产比重下降,说明公司着重于长期投资,变现能力相应降低。排在第8位的是每股公积金,公积金是未来公司进行扩张的物质基础,每股公积金越高表明公司股本扩张以及转增股本的能力越强。排在第9位的是营业成本/营业收入,是反映公司盈利能力的重要指标。营业收入由成本和利润构成,营业成本在营业收入占较大比重,则公司的盈利能力较弱。排在第10位的是货币资金/总资产,货币资金是指以货币形式存在的资产,是公司经营运动的起点和终点,如果货币资金占总资产的比重高则表明公司有比较强的偿债能力和较小的经营风险。
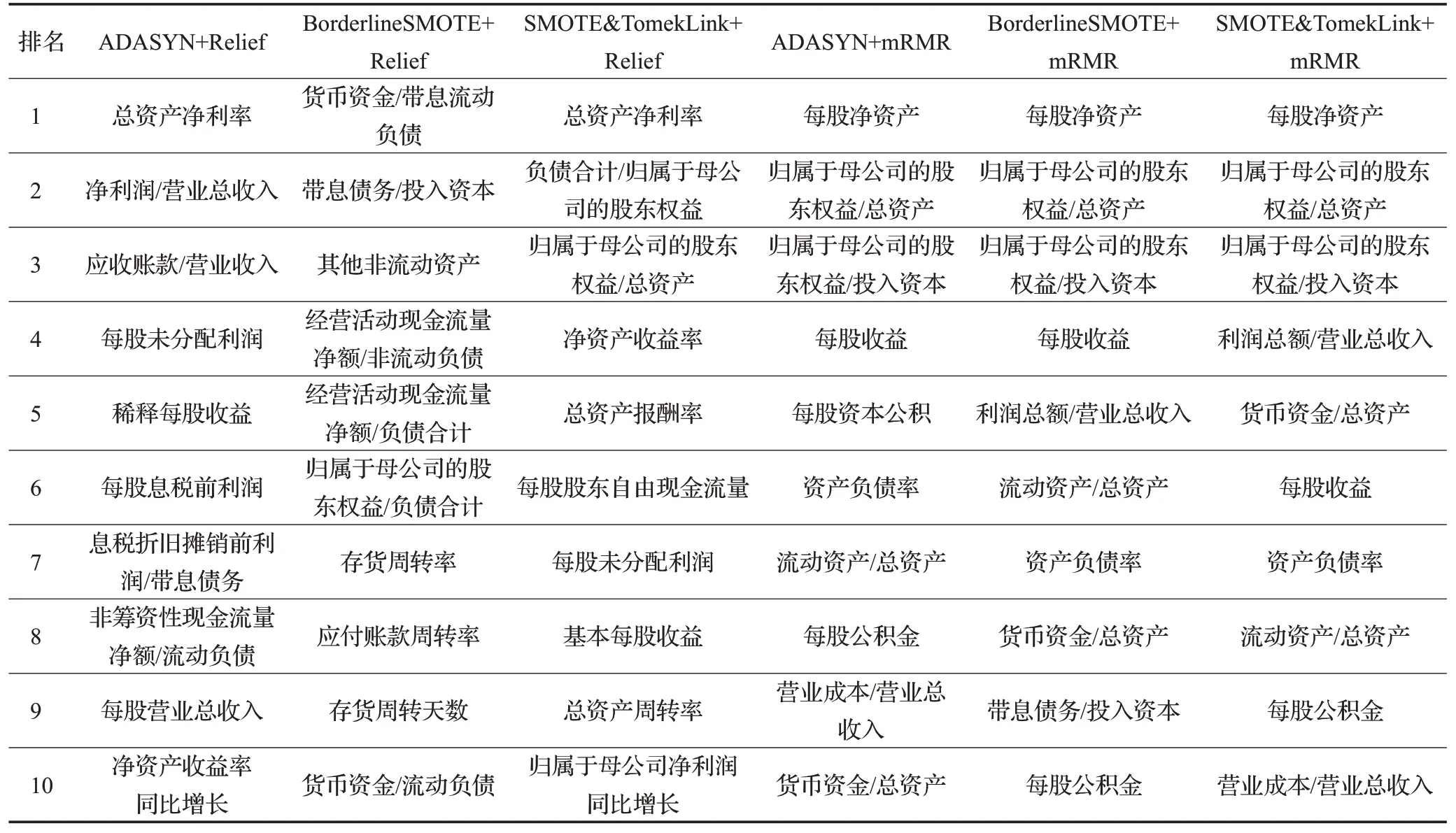
表4 特征重要性排序Table 4 Ranking of feature importance
综合上述预测结果和特征选择结果分析,ADASYN+mRMR模型选出的指标符合选择优质股的预期以及上市公司高送转的特征,能反映公司真实的财务状况。这进一步验证了ADASYN+mRMR+XGBoost模型在高送转预测中的适用性。
3 结论与建议
本文针对A股上市公司的财务数据,基于采样、特征选择以及集成学习,采用18个组合模型对上市公司高送转的情况进行实证研究。结果表明:(1)在构建预测模型的过程中,首先对数据做采样和特征选择预处理,在此基础上构建模型可以有效提高模型整体的预测性能,且采样处理对模型性能的提升效果更加显著。(2)与Relief特征选择算法相比,运用mRMR特征选择算法得到的特征子集中特征之间的相关性更小,更加符合选择优质股的条件。(3)相较于RF和Adaboost算法,XGBoost算法对于上市公司高送转的预测准确性更优。从预测效果来看,ADASYN+mRMR+XGBoost组合模型取得了最优的预测结果,rr p、rr n、G值以及F值分别为84.96%、92.14%、88.46%和76.54%。
本文的研究成果不仅能帮助投资者利用上市公司的财务数据挖掘真正有潜力的股票,而且可为金融机构以及个人投资者提供操作性较强的对上市公司高送转进行有效预测的应用工具。但仍需要指出:(1)集成学习有很多种,每种方法都有其优点与缺点,本研究仅系统地比较分析了三种具有代表性的算法。如何挖掘更有效的集成学习并构建组合预测模型是一个值得继续深入研究的课题。(2)大数据背景下,如何有效利用上市公司的财务数据和新闻媒介等文本数据来对上市公司高送转进行预测是后续研究的重点。
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
中学生数理化·高一版(2021年2期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2017年14期)2017-09-08
自动化学报(2017年5期)2017-05-14
数学学习与研究(2017年3期)2017-03-09
电子制作(2017年23期)2017-02-02
