
机器学习分类算法在降雨型滑坡预报中的应用
2022-05-23 09:49刘海知包红军闫旭峰徐成鹏
应用气象学报 2022年3期
刘海知 徐 辉* 包红军 徐 为 闫旭峰 鲁 恒 徐成鹏
1)(国家气象中心, 北京 100081)2)(中国气象局-河海大学水文气象研究联合实验室, 北京 100081)3)(中国地质环境监测院, 北京 100081)4)(四川大学水利水电学院, 成都 610065)
引 言
中国是世界上遭受地质灾害影响最严重的国家之一,其中滑坡占比最高,每年因滑坡造成的经济损失达5000万美元,在滑坡的主要诱因中,降雨是活跃且多变的自然因素,由降雨引发的滑坡数量约占滑坡总数的90%[1-3]。降雨引发滑坡的预测方法主要分为机理预测和统计预测,机理预测对实地数据采集要求较高,通常需要现场仪器布控,多用于单沟(坡)层面的预报,大范围的指导性预报仍以统计预测模型为主,统计预测模型可分为临界雨量模型和概率预报模型两类。临界雨量模型直接将滑坡发生与雨量判据联系起来,通过寻找各种降雨指标与滑坡发生之间的经验关系,确定临界降雨条件。在降雨诱发滑坡的临界阈值研究中,Lumb[4]和Brand等[5-6]从中国香港地区斜坡破坏与降雨条件的分析总结出局部短时暴雨引发滑坡的临界雨强。刘艳辉等[7]、丁力等[8]、陈列等[9]根据研究区地质情况,采用分区方式建立预警模型,在区域特征基础上建立预测预报模型。徐辉等[10]对多个时间尺度的降雨指标进行验证,确定各时间尺度降雨指标与滑坡关系,制定预警的降雨临界阈值。概率预报模型是基于严格统计方法对不同下垫面条件的地质灾害发生概率进行预测,韦方强等[11]利用可拓模型建立区域泥石流预测系统,马志江等[12]采用支持向量机方法对浙江庆元地区的滑坡进行预测,Dai等[13]建立的Logistic模型初步具备了对大屿山地区降雨型滑坡发生概率的动态预报能力。人工智能和模糊数学领域技术拓展了滑坡、泥石流等地质灾害的预测、预警方法,但大部分研究中诱发滑坡降雨过程偏少,即使采用滚动小时雨量,也不足以反映长时间段内降雨与滑坡发生的关系。本文利用多源融合降水近实时实况分析数据对全国数千起滑坡事件的降雨因子进行分析,结合下垫面环境因子作为机器学习分类算法的输入变量,对全国范围降雨诱发的滑坡进行概率预报。
1 数据处理
1.1 灾情数据
滑坡灾情数据的时间为2014—2020年,其中2014—2017年灾情数据主要来自于中国地质环境监测院灾情通报信息系统,2018—2020年灾情数据主要取自全国气象灾情上报系统、地质云门户网站、全国市(县)地质灾害普查以及分县调查历史数据。灾情数据包含滑坡发生时间、滑坡点位置(经纬度)以及主要诱因等。统计时,剔除灾情数据中时间信息未精确到小时、位置信息不含具体经纬度以及主要诱因不是降雨的滑坡个例,同一小时某处多次发生滑坡记为该处发生滑坡1次[14],得到降雨型滑坡样本2257例(图1)。
本文插图中所涉及的中国国界基于审图号为GS(2017)3320号标准地图制作,底图无修改。
1.2 降雨因子
降雨对滑坡的触发作用主要体现在两个方面:一是增大坡体下滑力,二是减小坡体抗滑力。突发性的、距滑坡发生时间较短的降雨过程主要通过增大静、动水压力及润滑滑面减小坡体抗滑力;连续性的、距滑坡发生时间较长的降雨过程主要通过增大坡体重量增大坡体下滑力。因此,在考虑降雨因子时,不仅要考虑临滑激发降雨,还要考虑前期有效降雨。目前,在国家气象中心及省级气象部门的滑坡预警业务实践中,一般以固定时刻(当日08:00(北京时,下同)—次日08:00、当日20:00—次日20:00)的24 h雨量作为诱发滑坡的单一预警指标,未形成连续的动态预报产品。本文以小时分辨率预报雨量和前15 d有效雨量作为降雨因子,前期有效雨量表达式[15-16]如下:
(1)
(2)
式(1)中,n为前期降雨日数,n=15。Rc为前15 d有效雨量,R0为滑坡发生当日24 h雨量,R1为滑坡发生前1 d 24 h雨量,R2为滑坡发生前2 d 24 h雨量,Ri为滑坡发生前i日的24 h雨量(i≥3)。式(2)中,α为区域最佳有效降雨系数,表征下垫面对雨水的滞留能力,由区域内岩土体总体性质决定(0<α<1),由于滑坡发生区域的地形地貌条件复杂,各区域前期有效降雨对滑坡的影响程度不完全一致,需要分区域确定有效降雨系数,以0.1为步长遍历有效降雨系数α的取值范围,代入式(1)得出不同有效降雨系数条件下的前期有效雨量,σ表示前期有效雨量均方差,将区域滑坡样本的前期有效雨量均方差与最大前期有效雨量的比值集合代入式(2)得到最优有效降雨系数。
滑坡点降雨信息的常规获取方法是选用邻近基本地面观测站的雨量记录进行估算,由于地形和经济等因素影响,地面观测站网难以密集且均匀地分布,极大限制了区域降雨时空分布估计的准确性[17-18],导致不同地点的滑坡均选用相同的雨量信息,触发滑坡的局地强降雨往往被遗漏。近年随着遥感观测技术的进步和卫星数据反演算法的改进,多源数据以其宽广的空间覆盖和高时空分辨率,逐渐成为水文研究的重要数据源。本文使用中国气象局国家气象信息中心CMPAS(China Meteorological Administration Multisource Precipitation Analysis System)0.05°×0.05°逐小时高时空分辨率多源融合降水近实时实况分析产品,其数据源包括:①地面站点观测数据,全国约6万个自动气象站经质量控制后的小时降水量数据[19]。②卫星反演降水产品,中国气象局国家卫星气象中心研发的FY-2气象卫星反演降水产品[20]、美国气候预测中心研发的全球30 min,5 km分辨率的CMORPH(National Oceanic and Atmospheric Administration Climate Prediction Center Morphing Technique)卫星反演降水产品。③雷达估测降水数据,中国气象局气象探测中心研发的逐小时0.01°×0.01°分辨率的全国雷达定量估测降水产品[21]。高时空分辨率多源融合降水近实时实况分析产品适用于精细化气象格点实况分析、模式预报检验、中小尺度极端降水事件监测、水文模型驱动等方面,可为天气预报、防灾减灾业务应用和研究提供高效、高质、高分辨率的降水产品[22-24]。
1.3 下垫面因子
滑坡发生是下垫面环境变异的结果,而下垫面环境是一个由众多因子组成的复杂系统,各类因子作用不同,综合考虑各类因子对滑坡发生的贡献非常重要。国内研究尚未严格区分滑坡敏感性和危险性,部分研究直接将二者并称为滑坡易发性评价,除选取的影响因子不同以外,选取的数学模型以及制图过程基本一致[25-26]。信息量模型是一种能定量计算各类下垫面因子对滑坡发生贡献(信息量)的统计分析方法,通过分析下垫面因子与滑坡位置关系,揭示滑坡分布规律并得到各因子对滑坡发生的贡献,结合研究区内滑坡发生的实际情况对下垫面因子进行筛选,将主要下垫面因子融合为一个表征滑坡发生难易程度的量,即为滑坡易发性(敏感性或危险性)。各下垫面因子对滑坡发生所提供的信息量值根据式(3)计算[27-28]:
(3)
式(3)中,P(Xi)是影响因子的信息量值,S是研究区面积,Si是研究区内含有影响因子Xi的面积,R是研究区内已发生灾害的面积,Ri是影响因子Xi分布区域内已发生灾害的面积。单一评价单元内的总信息量值根据式(4)计算[27-28]:
(4)
式(4)中,P为评价单元总的信息量值,m为影响因子数。各个单元网格的总信息量作为单元网格内影响滑坡发生的综合评价指标,值越大表明滑坡发生的可能性就越大。
大量对于滑坡易发性的研究常将地形因子、土壤因子、植被覆盖以及水文环境作为主要评价因子[29],本文将海拔高度、坡度、土壤类型、土地利用、植被覆盖率以及河网密度作为信息量模型输入因子(图2),计算下垫面因子总信息量。其中,表征海拔高度的数字高程模型(digital elevation model,DEM)
回家后的赛利亚审视自己未来的出路:一方面,她继承了祖母留下的卡拉米洛披肩,看到了自己与他人、家庭、民族之间的联系,这使得她理解了祖母和家人、接纳了自己的民族身份;另一方面,她以一种更加理智、全面的方式重建自己的文化身份,文化身份不再是一个非此即彼的选择,而是一个融合了多重文化的身份重建。
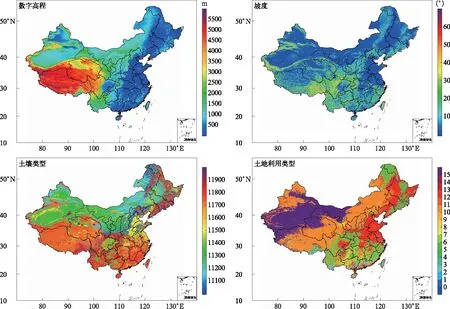
图2 下垫面类型Fig.2 Underlying surface type

续图2
来源于美国航天飞机雷达测绘任务(shuttle radar topography mission,SRTM)生产的高质量高程数据,水平分辨率为90 m,坡度数据以及河网密度数据基于DEM空间分析生成。土壤类型数据选择联合国粮农组织(Food and Agriculture Organization,FAO)、国际应用系统与分析研究所(International Institute for Applied Systems Analysis,IIASA)以及中国科学院南京土壤研究所(Institude of Soil Science,Chinese Academy of Sciences,ISSCAS)等机构共同推出的全球约1 km水平空间分辨率土壤数据库(harmonized world soil database,HWSD)1.2 版。土地利用类型数据采用中分辨率成像光谱仪(moderate resolution imaging spectroradiometer,MODIS)的L3全球约500 m年度土地覆盖产品MCD12Q1,土地类型的标识是国际地圈-生物圈计划(international geosphere-biosphere programme,IGBP)定义的17类。植被覆盖信息源于MODIS全球250 m陆地植被连续场(vegetation continuous fields,VCF)的L3数据。
由于下垫面因子的空间分辨率与降雨因子不匹配,需要通过重采样操作使其空间分辨率统一为5 km,并按照一定的分级标准将所有下垫面因子进行重分类并转换为矢量图层,利用空间相交和属性查询,提取滑坡点在不同等级因子条件下的空间分布及数量情况,在矢量数据的基础上得到不同等级对应的面积。综合6种下垫面因子,通过信息量模型得到全国滑坡易发度(图3)。由图3可知,全国有较多地方属于滑坡易发区,范围最大易发区主要位于西部高原向东部平原、丘陵过渡地带,东部和东南部丘陵地带以及天山以北地区也容易或较易发生滑坡。内蒙古东部少部分地区的易发指数偏高,这些区域海拔较高,坡度较大,土壤质地较粗糙,易发指数较大,但这些区域降雨偏少,极端性强降雨过程较少发生,实际发生滑坡较少。

图3 滑坡易发程度Fig.3 Landslides susceptibility
2 样本构建
样本集的构建流程主要包括下垫面因子和降雨因子特征库构建、正负样本采样、样本特征属性提取以及数据清洗。滑坡的空间预测可以看做二元分类过程[30],即以发生滑坡和未发生滑坡作为样本集标签进行监督学习。因此,仅构建降雨诱发的滑坡样本集(正样本,一般标记为1)是不够的,还需要构建与滑坡样本集等量的受降雨过程影响的非滑坡样本集(负样本,一般标记为0)[31],考虑对滑坡有影响的前期降雨历时范围[32-35],从降雨诱发滑坡发生的时间点倒推一段时间作为对应非滑坡样本的时间点,确保影响非滑坡样本的降雨过程存在,完成非滑坡样本的时间采样后,剔除作为非滑坡样本构建基础的滑坡样本,使两类样本集的空间位置不重复,最后对样本集进行数据清洗并去除无效值。
考虑到国家气象中心及省级气象部门滑坡预警业务中无缝隙短临预报的客观需求,将预报时效12 h 以内的时间分辨率设定为1 h,预报时效12~36 h 的时间分辨率设定为3 h。根据滑坡样本集和非滑坡样本集时空分布信息,提取相应位置的降雨因子和下垫面因子的特征属性。降雨因子包括预报雨量和前期有效雨量,即起报时间至滑坡发生时间的雨量以及起报时间前15 d有效雨量,起报时间需要根据不同预报时效从滑坡发生时间点回溯。由于降雨因子和下垫面因子存在量纲差异,对于涉及距离计算和梯度下降法求解参数的算法需要对输入样本进行归一化处理[36],防止输入绝对值过大造成收敛过慢,归一化公式为
(5)
式(5)中,Xi为特征量,Xmax(Xmin)为特征量集合最大(最小)值。归一化结果需要避免异常值的影响,百分位数是表征序列分布状态的统计指标,反映样本在整个序列中的相对位置,利用百分位数作为特征量的划分标准,一定程度上可以区分一般性和极端性,可用于识别异常值[37-43]。将输入特征量通过百分位排序,剔除第5百分位数以下和第95百分位数以上数据,后续扩充新样本时,需要重新定义Xmax和Xmin。
将下垫面因子图层、降雨因子图层分别与预报网格单元叠加,获取预报网格单元的要素值。其中,下垫面因子图层为易发度,降雨因子图层为前期降雨和预报降雨,前期降雨包括起报时间前1 d、前2 d、前3 d、…、前15 d有效雨量,预报降雨包括起报时间未来1 h,2 h,3 h,…,12 h(逐1 h)雨量以及起报时间未来15 h,18 h,21 h,…,36 h(逐3 h)雨量,共计36个图层。根据不同预报时效获取相应预报雨量图层,结合前期有效雨量图层以及易发度图层驱动概率预报模型。考虑滑坡点流域面积一般小于200 km2,而格点化降雨数据空间分辨率为5 km,每个网格面积约为25 km2,滑坡点流域面积一般不超过8个网格大小,因此,当滑坡预报点周围的网格点雨量达到临界雨量时,认为该滑坡点面雨量已超临界面雨量。
3 算法评估
区域降雨诱发滑坡的预报、预警问题是滑坡发生与否的分类问题,主要用到机器学习分类算法,分类算法所需数据的类别为已知型,主要算法包括逻辑回归、最邻近、决策树、支持向量机和线性判别分析等。利用MeteoInfo集成框架中的机器学习分类算法工具(meteoinfo machine learning,MIML)对各分类算法的效果进行测试[44-45],并与现有业务中的降雨临界阈值模型对比。临界阈值模型以降雨作为唯一预警指标(图4),通过阈值方程构建:
I=aD-b+c。
(6)

图4 降雨临界阈值模型Fig.4 Rainfall critical threshold model
将样本集按照4:1的比例分为训练集和测试集,保证训练集和测试集中滑坡与非滑坡样本比例为1:1,影响因子以一维向量形式[V1,V2,V3]作为输入项(V1表示前期有效雨量,V2表示预报雨量,V3表示易发度),滑坡发生概率作为输出项。采用K折交叉检验(K-fold cross validation,K=10)对模型进行结构调整和超参数优化,即将训练集分为10组大小相等的互斥子集,依次轮换子集10次进行试验,并分别对6种机器学习分类算法的预测精度和泛化能力进行对比评估。准确率(accuracy,ACC)表示测试集中分类正确的样本量占总样本量的比例,可评价模型的预测精度,受试者工作特征曲线(receiver operating characteristic curve,ROC)是反映敏感性和特异性连续变量的综合指标[36,46],ROC下方面积 (area under the curve,AUC)可评价模型的泛化能力。由表1可知,线性判别分析算法模型准确率最高(ACC为0.863),模型泛化能力最好(AUC为0.886),且模型无过拟合现象;其次为逻辑回归算法模型(ACC为0.840,AUC为0.879);再次为最邻近算法模型和随机森林算法模型,ACC分别为0.838 和0.834,AUC分别为0.858和0.849。6种分类算法模型的ACC和AUC均在0.8 以上,高于临界阈值模型(ACC为0.658,AUC为0.693),就测试样本而言,分类算法模型的准确率和泛化能力均优于临界阈值模型。

表1 模型算法测试结果Table 1 Model algorithms test results
4 应 用
根据模型算法评估结果,将线性判别分析(linear discriminant analysis,LDA)、最邻近(k-nearest neighbors,KNN)、逻辑回归(logistic regression,LR)3种分类算法模型用于实例回算,选取2021年5次降雨诱发滑坡个例,根据滑坡点时空分布信息,提取降雨因子信息和下垫面易发度信息,并进行网格单元叠加,分别作为3种分类算法模型输入项,输出5次降雨诱发滑坡的概率。考虑到国家气象中心及省级气象部门的实际业务流程,将滑坡发生前1 d 20:00作为起报时间。5例降雨型滑坡的时空分布信息以及临界阈值模型的预报结果如表2所示,模型对于滑坡个例2、滑坡个例3、滑坡个例4的预报结果为发生滑坡,滑坡个例1和滑坡个例5的预报结果为未发生滑坡。
个例1(福建省宁德市国道104线福安路段滑坡)的起报时间为2021年5月21日20:00,输出1~12 h的逐1 h概率预报以及12~36 h的逐3 h的概率预报,滑坡发生时间为起报时间的未来第8小时,滑坡点及其周边区域的下垫面危险度较高。滑坡发生时间前后的概率预报如图5所示,KNN算法、LDA算法和LR算法的预报落区均包含滑坡点,预报落区范围与滑坡点及其周边区域较为吻合。KNN算法在滑坡点附近的概率预报超过0.8,相对于LDA算法和LR算法,KNN算法的高概率预报落区范围更大。LDA算法的高概率预报落区较为分散,滑坡点及其周边区域的预报强度相对较小,滑坡点的第5小时概率预报达到0.6,第6~第10小时概率预报增大,在雨带覆盖且雨量偏小的区域给出较大范围的低概率预报,这些区域在预报时效内和起报时间前分别出现了一定程度的临滑降雨和前期降雨,但距导致滑坡发生的量级还有较大差距。LR算法的预报落区相对于KNN算法更收敛,在滑坡点及其周边区域的预报强度比LDA算法更大。个例2~个例4关键时段预报中,KNN算法、LDA算法和LR算法对于滑坡发生的时空范围整体较准确,3种分类算法在滑坡点及其周边区域的概率预报特征与个例1类似。个例5(山西省临汾市蒲县蒲城镇荆坡村滑坡)的预报试验(图6),LDA算法和LR算法对滑坡点及其周围区域的概率预报为0.5~0.6,相对于上述4例偏低。回顾诱发滑坡的降雨过程发现,起报时间的前期有效雨量较小,但在滑坡发生前较短时间内出现短时强降雨,预报结果反映LDA算法和LR算法对于激发降雨的敏感性相较于前期降雨更弱。这里因为考虑到前期连续性降雨在诱发滑坡过程中的主导作用[10],降雨因子中前期降雨因子的数量相较于激发降雨更多,导致LDA算法和LR算法对部分短时强降雨进行识别时的局限。

表2 降雨诱发滑坡个例Table 2 Cases of rainfall-induced landslides
通过2021年5次降雨过程的预报试验可以看到,LDA算法的高概率预报落区范围更收敛,对局地降雨信息的提炼较好,但LDA算法在非降雨中心区域输出低概率预报的面积偏大。KNN算法和LR算法的高概率预报落区范围偏大,虚警范围相对较大,但在实际降雨诱发地质灾害预报、预警业务中对于漏警的容错率远小于虚警,分类算法模型在训练过程中确保高(低)召回率(漏报率)是前提,即着重于对滑坡样本的滤取,造成部分非滑坡样本被预测为滑坡样本,进而在实际预报中导致部分非滑坡降雨过程被错误识别,后续需要在保持高召回率的前提下继续增加包含降雨过程的负样本,以提高分类算法模型对于非滑坡降雨过程的识别能力,降低分类算法模型误报率。概率预报模型和临界阈值模型均属于客观算法模型,临界阈值模型在进行大范围预报时出现多区域降雨临界阈值相同的情况不利于分类(滑坡发生与否)过程,概率预报模型在客观描述滑坡发生可能性方面优于临界阈值模型。

图5 2021年5月21日20:00概率预报结果Fig.5 Probability forecast results at 2000 BT 21 May 2021

图6 2021年10月4日20:00概率预报结果Fig.6 Probability forecast results at 2000 BT 4 Oct 2021
5 结论与讨论
本文针对客观描述降雨型滑坡发生可能性的业务需求,基于机器学习分类算法建立降雨诱发滑坡概率预报模型,从训练样本集构建、模型训练、算法评估和回算试验等关键环节,阐述了基于机器学习分类算法的区域降雨诱发滑坡概率预报方法,得到以下主要结论:
1) 利用样本测试集对不同类型机器学习分类算法的评估中,LDA算法准确率最高(ACC为0.863),无过拟合现象,泛化能力最好(AUC为0.886),其次为LR算法,再次为KNN算法。
2) 针对2021年降雨诱发滑坡的概率预报试验中,LDA算法、LR算法和KNN算法能够提取并学习降雨诱发滑坡的条件特征,对诱发滑坡的降雨过程有一定识别能力,概率预报模型在客观描述滑坡发生可能性方面优于临界阈值模型。
3) KNN算法和LR算法的高概率预报落区范围相对于LDA算法更大,易造成虚警,LDA算法的高概率预报落区范围更收敛,对局地降雨信息的提炼较好,但在非降雨中心区域的低概率预报落区面积偏大。
目前,降雨诱发滑坡预报、预警业务中常用的模型是临界阈值模型,该模型具有运行速度快、适用范围广、投入业务快的优点,模型假设预报区域内滑坡的发生只与降雨有关,将临界雨量作为决定性指标,但临界雨量因下垫面条件的不同而不同,过分依赖临界雨量进行滑坡预报具有一定风险。基于机器学习分类算法的降雨诱发滑坡概率预报模型综合考虑下垫面因子和降雨因子的耦合作用,通过严格的统计方法对不同下垫面条件下的滑坡发生概率进行预测,应用结果展示出机器学习分类算法在特征提取、参数优化、预报输出等方面的关键作用,是提升滑坡预报、预警性能的重要途经。模型弥补了现有预报模型中较难反映下垫面环境对滑坡影响的不足,为国家级气象业务平台全国范围的指导性预报提供了技术支持。训练数据集的样本量和质量是影响机器学习模型性能的关键因素,由于大量滑坡事件未被有效监测,同时为保证训练样本准确性,数据清洗过程过滤掉大量不确定的训练样本,制约了预报精度的提高。后续将通过丰富样本、优化数据清洗技术,提高训练样本的完整性和准确性,不断提升数据集的科学和应用价值,在业务时效和客观算力允许的前提下,基于Stacking分层模型集成框架将多种机器学习分类算法(KNN,LDA,LR,XGBoost,LightGBM)进行融合,建立多算法融合概率预报模型,提升预报、预警业务系统算法模块多样性。
猜你喜欢
农业科学研究(2022年2期)2022-08-01
水资源开发与管理(2022年2期)2022-03-12
水利科技与经济(2022年1期)2022-02-13
暖通空调(2021年1期)2021-03-16
水土保持研究(2021年2期)2021-02-05
苏州市职业大学学报(2020年4期)2020-12-31
安徽农学通报(2020年16期)2020-10-30
幼儿100(2019年14期)2019-04-30
热带农业科学(2018年4期)2018-09-26
环球时报(2017-06-14)2017-06-14
