
基于HSV颜色空间特征的视频烟雾检测
2022-05-30 04:29曹灿灿龚声蓉周立凡
计算机技术与发展 2022年5期
曹灿灿,龚声蓉,周立凡,钟 珊
(1.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318;2.常熟理工学院 计算机科学与工程学院,江苏 常熟 215500)
0 引 言
近年来国内火灾事故频发,造成了巨大的经济损失和人员伤亡[1]。火灾造成的损失是巨大的,如何降低火灾损失,提前报警是国内外学者一直思考研究的问题。传统火灾探测主要靠烟雾传感器[2],但是受人为、天气、气流等条件制约,这些传感器检测效率较低,并不能有效提前预警。火灾发生的前置条件一般是烟雾,如果能对烟雾进行有效准确的检测,将会极大降低火灾带来的危害。但是由于烟雾形状不规则、颜色特征多样等原因,造成传统烟雾检测有很大的局限性。随着神经网络的发展,基于视频的烟雾检测开始流行。视频烟雾检测技术具有检测范围广、准确率高等特点,该技术正在被应用于火灾预测等领域。
近年来,国内外很多学者都针对烟雾检测进行了研究。Millan等人[3]首先用颜色特征处理图像,但是因为之前人们对颜色研究较少,所以导致烟雾阈值设定不合理。王涛等人[4]结合PCA降维算法来进行烟雾检测。Zhou等人[5]通过提取烟雾面积变化率和形状特征来检测烟雾。李鹏等人[6]将高斯混合模型和卷积神经网络相结合对烟雾进行识别。张欣欣等人提出了一种改进VGG16模型,通过对LeNet增加相应的层数进行烟雾检测[7]。Jia等人[8]分割了烟雾区域,首次根据烟雾颜色和运动特征来识别烟雾。冯佳璐等人通过构建两层火灾烟雾识别模型,增强了视频抗干扰能力[9]。Ye等人根据颜色空间特征结合小波来实现对烟雾的识别[10]。史劲亭等建立一个较大的数据集,为后面烟雾识别提供了较好的数据集[11]。Foggia等人把运动、颜色、形态三方面相结合来识别烟雾[12-13]。吴章宪等人提出了Gabor小波变换用于识别烟雾[14]。陈俊周等人通过级联卷积神经网络来识别烟雾[15]。袁梅等人通过扩大候选烟雾区域和卷积神经网络相结合进行烟雾检测[16]。然而这些烟雾检测方法还存在一定的局限性:首先是泛化性差,换了不同场景后检测准确率会明显降低;其次检测准确率不高,还有待于进一步提升。目前,计算机在图像识别领域的准确率已经超越人类[17-19]。使用深度学习相关知识进行烟雾识别是主流方法之一。
针对当前视频烟雾检测的问题,在归纳当前视频烟雾检测方法的基础上,从提高烟雾检测准确率这个实际要求出发,该文提出使用HSV颜色空间特征来替代传统RGB颜色空间特征,通过高斯混合模型提取烟雾运动区域。结合烟雾颜色特征和运动特征来提取烟雾候选区域,然后使用卷积神经网络对烟雾候选区域进行自动提取来对烟雾进行检测。最后,对提出的HSV(Hue,Saturation,Brightness,色调,饱和,明亮)颜色空间特征和卷积神经网络相结合的视频烟雾检测方法进行实验论证和分析。实验结果表明,基于HSV颜色空间特征和卷积神经网络相结合的方法对烟雾检测准确率高,烟雾报警响应时间短,可以实现对复杂场景下的烟雾进行实时检测。
视频烟雾检测技术:
烟雾检测技术可以提前预警火灾,给人民群众留下抢救生命财产的时间,目前烟雾检测主要靠烟雾警报器,烟雾警报器在小范围的室内环境下使用效果良好,但是在野外空旷场景中,烟雾警报器效果比较差。
根据国标规定,烟雾警报器的响应时间为20秒以内,但在野外空旷场景下,烟雾警报器常常达不到国标规定。随着现代化的发展,传统的烟雾警报器已无法满足人们的安全要求,基于深度学习的视频烟雾检测速度快、检测范围广,有代替传统烟雾警报器的趋势。
1 烟雾检测算法流程
首先通过摄像机获取烟雾场景视频图像;接着对输入图像按128×96像素进行分块;然后由HSV颜色空间特征判断是否为烟雾运动候选区域,初步提取出烟雾候选区域;最后将候选区域送入训练好的卷积神经网络中判断是否为烟雾。
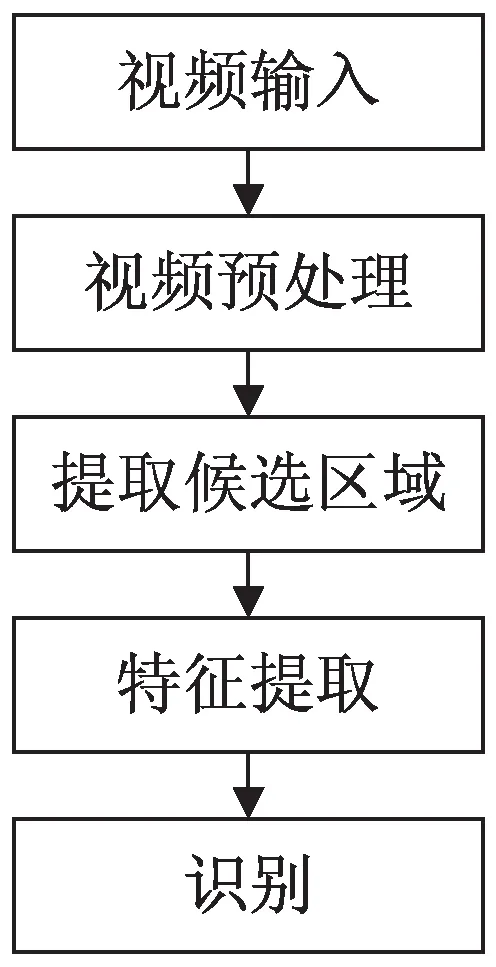
图1 RGB烟雾检测算法流程
图1中每个步骤的目的:
视频预处理:可以抵消除图像中的干扰,增强目标区域,从而提高检测识别的准确率。
提取候选区域:因为整个视频中区域较大,如果每个区域都进行检测,运算量会非常大,因此只搜寻视频中感兴趣的部分,也就是疑似烟雾的运动区域,将极大减少计算量。
特征提取:烟雾有向上运动的特征,提取向上运动的特征作为下一步对烟雾进行分类识别的一个凭证。
1.1 HSV颜色空间特征烟雾颜色特征提取
HSV颜色空间在美术人员中使用的比较广泛,可以通过调整饱和度和亮度来达到特定风格的效果[20]。
图像在计算机中存储和显示都是以RGB颜色空间的形式进行的,将图像从RGB颜色空间转换到HSV颜色空间的转换方式如下[21]:
V=max(R,G,B)
计算出结果后:

最终计算出的结果,H∈[0,360],S∈[0,1],V∈[0,1]。
由于计算机中图像是以24位的方式存储,所以像素值的每个分量应为0到255之间的数值,为了方便计算,再将计算出的H,S,V三分量的值映射到0到255之间,映射公式如下:
S=255×S
V=255×V
1.2 烟雾颜色候选区域的提取
基于两种不同颜色空间中的特征所提取的烟雾区域如图2所示,图2(a)和图2(b)分别为基于RGB颜色空间的特征提取的烟雾区域和基于HSV颜色空间的特征提取的烟雾区域。将找到的目标区域用黑色标注,标注结果如下。

图2 RGB(1)和HSV(2)颜色空间的烟雾区域提取
从这两幅图像中可以看出,基于HSV颜色空间特征提取出的烟雾区域较为准确,而基于RGB颜色空间特征提取出的烟雾区域把很多白色的非烟雾区域也提取出来了,这就会影响烟雾检测的准确率。由此可见,基于HSV颜色空间提取出的烟雾区域比较符合要求。
经过对大量的图片在HSV颜色空间进行分析,最后得出的结论是:
(1)在HSV颜色空间中,烟雾图像区域的饱和度的值S<65;
(2)烟雾出现时,烟雾图像亮度V增加。
设定视频前100帧的平均亮度为阈值,若视频出现饱和度S的值低于60并且亮度V大于阈值则将该区域当做烟雾的候选区域。
1.3 烟雾运动候选区域的提取
经过HSV颜色空间的特征提取后,筛选出了符合烟雾颜色特征的候选区域,将该区域用高斯混合模型的背景减除法进行运动目标提取,如果经高斯混合模型进行判定后为运动区域,则认为该区域为烟雾候选区域,将符合烟雾颜色特征且符合运动特征的区域送入卷积神经网络进行学习。高斯混合模型是目前主流的背景滤除方法。一般来讲,如果是背景图像,像素值会产生变化,但是变化范围小,只会固定在一个区间。像素值变化的主要原因有:
(a)物体运动。物体运动的方式有很多种,像人物走动、风吹动树枝等。
(b)光线的变化。当静止的视频中突然出现一束光也会导致像素值变化,这个光线的变化可能是人为因素造成,也可能是因为阳光的反射等。但是一个物体是背景而非前景的话它的像素值分布往往在多个值附近做变动,比如树枝的晃动。对于在多个值附近变动的背景可以用多个高斯分布来解决。

图3 原始图像(a)和高斯混合模型 背景滤除后的图像(b)
如图3所示,图3(a)和图3(b)分别为原始图像和经过高斯混合模型背景滤除后的图像,经过背景滤除后可以发现,经高斯混合模型背景滤除后,能有效减少无关因素的干扰,从而减少计算量。经过提取烟雾颜色特征和运动特征筛选出的烟雾候选区域能有效减少无关因素的干扰,进而提高烟雾识别的准确率。
2 conv-12网络模型设计
在卷积神经网络中,随着网络深度增加,识别准确率会提升[22]。但是网络深度过高,会导致训练时间过长,出现过拟合等问题。根据烟雾的特点,设计了适合烟雾检测的卷积神经网络conv-12。在实验中发现,当卷积层数继续增加之后,对烟雾检测的准确率并没有明显的提升,只会增加训练时间,所以最后选择了卷积神经网络conv-12。该网络由5个卷积层,5个池化层,1个全连接层,1个输出层组成。输入原始图片大小128×96像素,输出结果为烟雾和非烟雾的二分类。conv-12网络参数配置如表1所示。

表1 conv-12网络参数
其中,FMN代表特征图的数量,KS代表卷积核的大小,OFSM代表输出特征图的大小。
conv-12具体结构如下:
(1)输入层Input。输入层数据图片为128×96像素。
(2)卷积层C1。取卷积核大小为3×3,步长为1,特征图个数为32对输入图像进行卷积,使用ReLU(rectified linear unit,修正线性单元)函数作为激活函数[22],其最终输出结果为128×96×32维数据。ReLU激活函数的公式如下所示[22]:
relu=max(0,x)
当x小于0时,输出为0;当x大于0时,输出为x本身。
(3)池化层S1。使用最大值池化方法对卷积层C1的输出结果进行重采样,输出结果为64×48×32维数据。最大池化公式如下:
l=max(ni),ni∈n
其中,n是特征图的一个区域,ni是该区域中神经元的输出。
(4)卷积层C2、C3、C4、C5的功能和C1相同,卷积核大小为3×3,步长为1,特征图个数分别为64,96,128,160,输出数据的维度分别为64×48×64、32×24×96、16×12×128,8×6×160。
(5)池化层S2,S3,S4,S5的功能和S1相同,输出数据的维度分别为32×24×64,16×12×96,8×6×128,4×3×160。
(6)F1为全连接层,为了避免过拟合,使用了Dropout[22]方法。
(7)F2为输出层,设置2个神经元与F1相连,选用的激活函数为SoftMax[22]来进行二分类。分类的结果用0和1来表示非烟雾与烟雾。
3 实验设计与结果分析
实验所用计算机的CPU型号为Inter Xeon Gold 6230,计算机内存为128 G,显卡为4* Tesla P100,主频2.1 GHz;显存为毎块16 GB,共64 GB。实验程序通过Python和OpenCV编写,在Ubuntu 16.04操作系统下运行。视频烟雾检测卷积神将网络模型的搭建和训练采用Tensorflow[23]实现。
3.1 训练及测试数据集
实验的数据集含正负样本各1.5万张,其中训练数据集各1.2万张,测试数据集各3千张,烟雾测试视频10段,其中5段为烟雾视频,5段为非烟雾视频。该文采用随机组合方式每次从2.4万张训练样本中抽取100张图片放入conv-12中训练,共进行1万次训练。相当于对100万张图片进行了烟雾识别训练。烟雾样本数据来源于广泛,包括实际拍摄、网上搜索及袁非牛教授公开发布的数据集等。部分烟雾图像和非烟雾图像如图4所示。

图4 烟雾图片与非烟雾图片
3.2 烟雾识别结果
经卷积神经网络识别和标注后,最终输出结果如图5所示。

图5 烟雾标注结果
从图5可以看出,烟雾被准确检测出来。经实验认证,该算法烟雾识别效果良好,有实际应用价值。
3.3 评价指标
为了方便实验结果的比较,使用3个指标评估方法的性能,即准确率AR、检测率DR[24]和烟雾报警响应时间TIM,它们的定义为:
其中,烟雾报警响应时间TIM是指烟雾在测试视频中出现到系统发出警报的时间,T表示烟雾正样本中被识别为正样本的视频帧数,F表示烟雾正样本中未被识别为负样本的视频帧数,N表示烟雾负样本中被识别为正样本的视频帧数[24]。
3.4 和其他算法对比实验
为了体现算法的性能,将提出的模型与一些具有代表性的方法进行了比较。例如算法1是李鹏等人提出的高斯混合和卷积神经网络相结合的视频烟雾识别方法,算法2是张欣欣等人提出的改进VGG16网络的视频烟雾识别方法,算法3是陈俊周等人提出的通过提取烟雾的多个特征进行烟雾识别的算法,算法4是袁梅等人提出的通过扩大烟雾候选区域和卷积神经网络相结合的烟雾检测的算法。测量数据对比如表2所示。
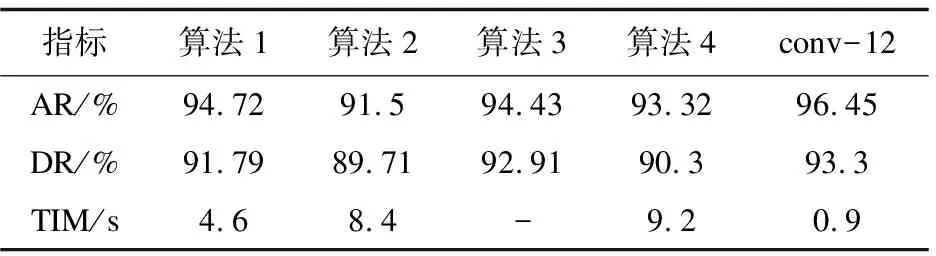
表2 烟雾检测的5种方法对比结果
从表2可知,该文提出的方法的准确率为96.45% ,烟雾报警响应时间只需要0.9 s。在烟雾检测的准确率等几个指标表现上结果都是最好的。提出的HSV+conv-12模型在火灾烟雾识别上具有良好的识别效果,在准确率、检测率和响应时间上都表现非常优异,这主要是因为HSV颜色空间模型能够通过目标区域定位层提取出烟雾目标区域,相对于直接对烟雾数据进行处理,减少了输入数据中无关特征对识别结果的影响,同时使用conv-12自动提取烟雾特征,避免了传统提取特征方法依赖先验知识的缺点。
3.5 实验结果分析
影响烟雾检测准确率的因素有:
(1)用于训练的正负样本有限,数据集过小可能导致烟雾数据不够,造成一些烟雾无法识别;
(2)干扰因素过多,像白云、水汽等物体都有可能对烟雾检测有干扰。
通过增加正负样本数量,可以提高识别准确率。
4 结束语
由于烟雾形状不规律、颜色多样性等原因,导致烟雾特征提取难度较大。该文提出了一种基于HSV颜色空间特征和卷积神经网络相结合的视频烟雾检测方法。利用该模型进行了烟雾识别实验,烟雾识别的准确率为96.45%,烟雾检测平均反应时间为0.9 s。 实验结果表明,conv-12能够减少复杂场景中无关信息对烟雾识别的干扰,有效提高了烟雾识别的准确率和检测率,减少了烟雾报警响应时间,实现了烟雾的实时警报,该方法在多种复杂环境下是可行、有效的。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
小学阅读指南·低年级版(2021年3期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
华人时刊(2019年13期)2019-11-26
学苑创造·C版(2018年7期)2018-08-08
